







RT-DETR算法理解
Background
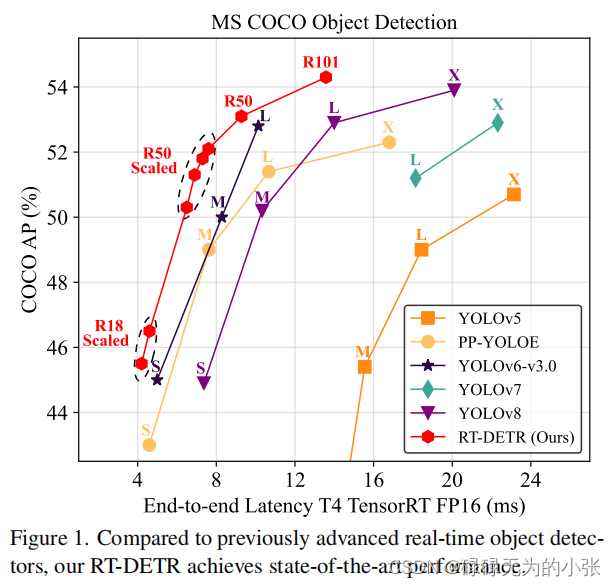
Real-time Detection Transformer(RT-DETR)是一个基于tranformer的实时推理目标检测模型。RT-DETR是2023年百度发布的一个新目标检测模型,它兼顾了速度和精度俩个特性,在速度上超越yolo,同时仍保持不低于yolo模型的精度。其分别从encoder部分、query选择俩个方面进行改进,保持了模型的精度,同时提高了模型的推理速度。
论文地址:https://arxiv.org/pdf/2304.08069
代码地址:https://github.com/lyuwenyu/RT-DETR
Model Architecture
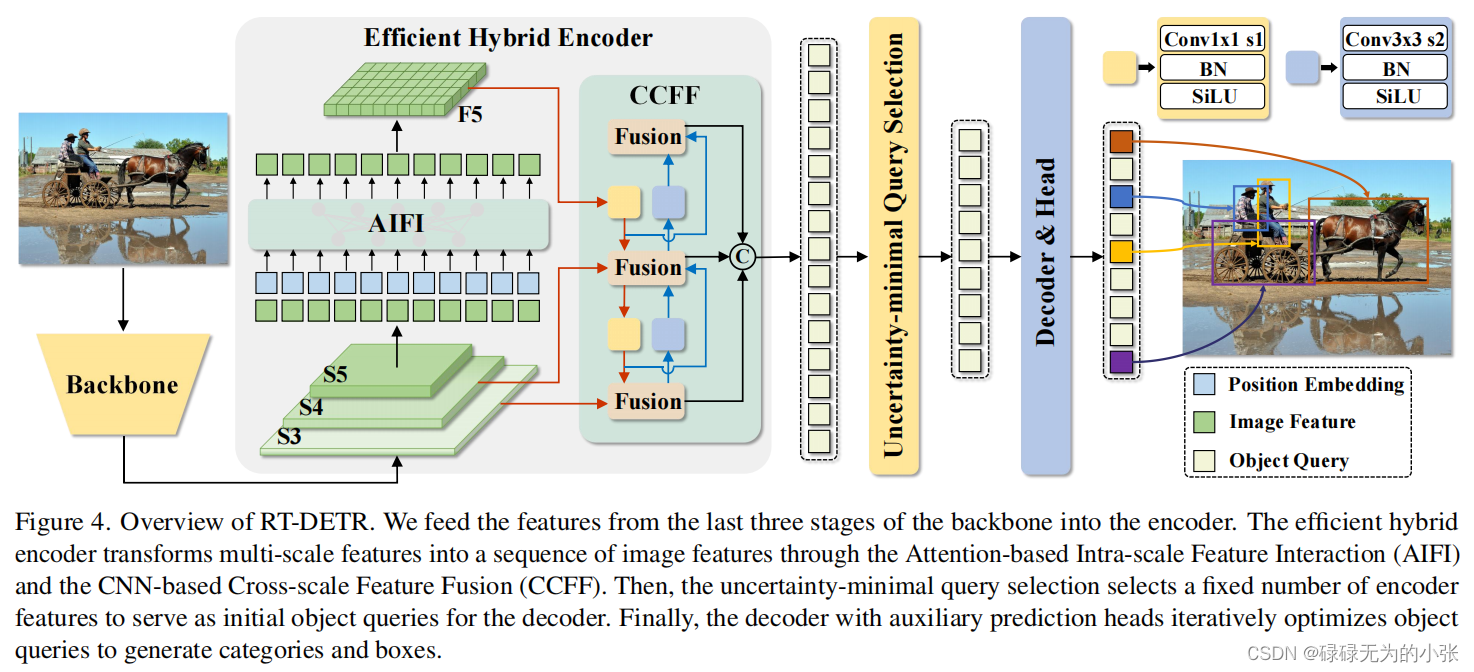
模型的结构如上图所示,输出图片经过Backbone进行特征提取,获取三个特征图 S 3 、 S 4 、 S 5 S_3、S_4、S_5 S3、S4、S5。然后将它们输入Efficient Hybrid Encoder层。Efficient Hybrid Encoder层对特征图 S 5 S_5 S5做AIFI获得特征图 F 5 F_5 F5,然后通过CCFF结合 S 3 、 S 4 、 F 5 S_3、S_4、F_5 S3、S4、F5输出。然后用Uncertainty-minimal Query Selection选取query,再和Encoder的输出一起输入decoder中,最后输出检测结果。
Efficient Hybrid Encoder
作者分析了特征图自交互的情况,认为低级特征具备丰富的图像语义,交互的需求不大。同时通过实验验证了这一观点。这里的出发点是从缩短输入的AIFI的长度出发,由于计算复杂度与长度的平方成正比,由于高级特征的长度较小,所以计算量较少,同时能够验证低级特征交互是不必要,那么就可以较少这一部分的计算。
整个Efficient Hybrid Encoder模块可以用公式表达出来,即 Q = K = V = F l a t t e n ( C 5 ) F 5 = R e s h a p e ( A I F I ( Q , K , V ) ) O = C C F F ( { S 3 , S 4 , F 5 } ) \begin{align*}Q =& K=V = Flatten(C_5)\\F_5 = &Reshape(AIFI(Q,K,V))\\O=&CCFF(\{S_3,S_4,F_5\})\end{align*}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2878
2878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









