







一、实验目的
- 1)掌握语音信号线性叠加的方法,编写 Python 程序实现非等长语音信号的叠加;
- 2)熟悉语音信号卷积原理,编写 Python 程序实现两语音卷积;
- 3)熟悉语音信号升采样/降采样方法,并编写 Python 程序实现。
二、实验内容
2.1 线性叠加
1)录制或从 wav 文件中读取一段语音,并归一化。然后生成一段随机信号(长度与语音信号相同),归一化后幅度乘以 0.01。最后线性叠加两段语音,并用 plt.plot 函数显示三种信号。要求:横轴和纵轴带有标注。横轴的单位为秒,纵轴显示的为归一化后的数值。
import matplotlib.pyplot as plt
import numpy as np
import random
from scipy import signal
from scipy.io import wavfile
plt.rcParams['font.family'] = ['sans-serif'] #显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
# 读取语音
(fs, sound) = wavfile.read("p232_003.wav")
# 构建横坐标时间 t
t = np.array([i/fs for i in range(sound.size)])
# 语音信号归一化
sound_max = np.absolute(sound).max()
sound11 = sound / sound_max
# 画原始语音信号的图
plt.figure(1)
plt.subplot(311)
plt.plot(t,sound11)
plt.title('原始信号')
plt.ylabel('归一化幅度')
# 生成随机噪声
sound2 = []
for i in range(sound.size):
temp = random.uniform(-100,100)
sound2.append(temp)
sound2_max = np.absolute(sound2).max()
sound12 = sound2 / sound2_max
plt.subplot(312)
plt.plot(t, sound12*0.01)
plt.title('随机序列')
plt.ylabel('归一化幅度')
# 线性相加信号
sound3 = sound + sound2
sound3_max = np.absolute(sound3).max()
sound13 = sound3 / sound3_max
plt.subplot(313)
plt.plot(t,sound13)
plt.title('线性相加信号')
plt.ylabel('归一化幅度')
plt.show()
实验结果:
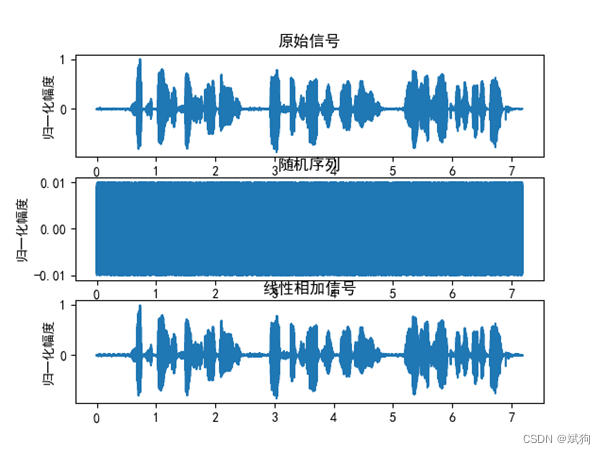
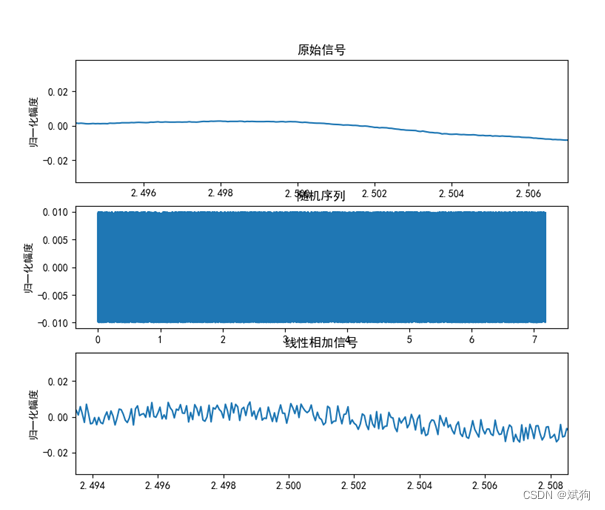
分析:将原始信号与随机噪声线性叠加,得到的相加信号曲线变得粗糙,比如在2.5s左右的语音曲线
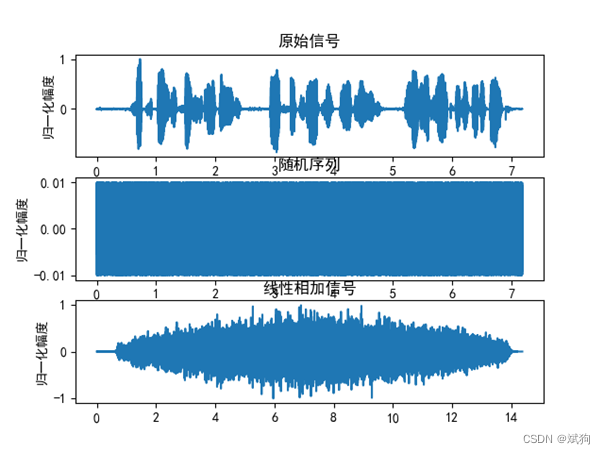
2.2 卷积
2)将录制或读取的语音信号与随机信号进行卷积,并用 plt.plot 函数显示该信号,并对比线性叠加信号的区别。然后播放两种信号,并比较区别
import matplotlib.pyplot as plt
import numpy as np
import random
import scipy.signal
from scipy import signal
from scipy.io import wavfile
plt.rcParams['font.family'] = ['sans-serif'] #显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
# 读取语音
(fs, sound) = wavfile.read("p232_003.wav")
# 构建横坐标时间 t
print(fs,sound.size)
t = np.array([i/fs for i in range(sound.size)])
# 语音信号归一化
print(t.size)
sound_max = np.absolute(sound).max()
sound11 = sound / sound_max
# 画原始语音信号的图
plt.figure(1)
plt.subplot(311)
plt.plot(t,sound11)
plt.title('原始信号')
plt.ylabel('归一化幅度')
# 生成随机噪声
sound2 = []
for i in range(sound.size):
temp = random.uniform(-100,100)
sound2.append(temp)
print(len(sound2))
sound2_max = np.absolute(sound2).max()
sound12 = sound2 / sound2_max
plt.subplot(312)
plt.plot(t, sound12*0.01)
plt.title('随机序列')
plt.ylabel('归一化幅度')
# 线性相加信号
sound3 = scipy.signal.convolve(sound,sound2)
sound3_max = np.absolute(sound3).max()
sound13 = sound3 / sound3_max
t3 = np.array([i/fs for i in range(sound13.size)])
plt.subplot(313)
plt.plot(t3,sound13)
plt.title('线性相加信号')
plt.ylabel('归一化幅度')
plt.show()
#----------------------------------------
import pyaudio # 导入 Pyaudio 库
import wave # 导入 wave 库
CHUNK = 1024 # 设定缓存区帧数为 1024
FORMAT = pyaudio.paInt16 # 设定数据流采样深度为 16 位
CHANNELS = 1 # 设置声卡通道为 2
#RECORD_SECONDS = 5 # 设置记录秒数
pa = pyaudio.PyAudio() # 实例化一个 Pyaudio 对象
print('Duration:', round(len(sound2)/ float(fs), 3),'seconds')
k = len(sound2)/ float(fs)
RATE = sound.shape[0]/k # 设置采样率
print(RATE)
frames = np.round(sound2)
#frames = sound
WAVE_OUTPUT_FILENAME = "C2_1_y_1.wav"
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(pa.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
# 只读模式打开需要播放的文件
#wf = wave.open(WAVE_OUTPUT_FILENAME, 'rb')
print(sound)
print(np.round(sound2))
#print(np.round(sound3))
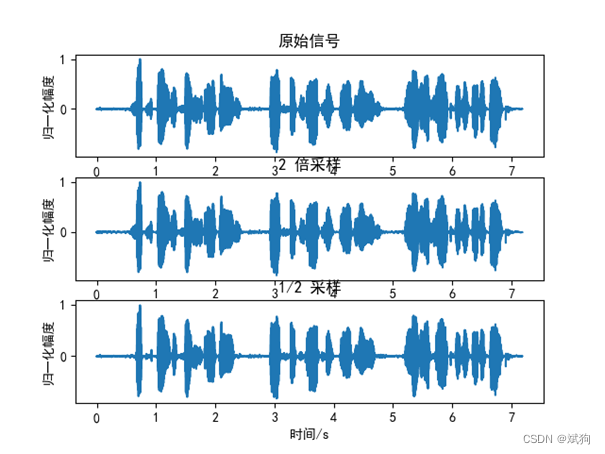
2.3 升/降采样
3)改变录制或读取的语音信号的采样频率,使用 plt.plot 函数进行显示,然后播放,比较采样频率改变对语音信号的影响。
import matplotlib.pyplot as plt
import numpy as np
from scipy import signal
from scipy.io import wavfile
plt.rcParams['font.family'] = ['sans-serif'] #显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
(fs, sound) = wavfile.read("p232_003.wav")
# 构建横坐标时间 t
t = np.array([i/fs for i in range(sound.size)])
# 语音信号归一化
sound_max = np.absolute(sound).max()
sound = sound / sound_max
# 画原始语音信号的图
plt.figure(1)
plt.subplot(311)
plt.plot(t,sound)
plt.title('原始信号')
plt.ylabel('归一化幅度')
# 将采样点变为原来的两倍
sound2 = signal.resample(sound,2*sound.size)
# 两倍采样率信号的归一化
sound2_max = np.absolute(sound2).max()
sound2 = sound2 / sound2_max
# 构建横坐标时间 t2
f2 = 2 * fs
t2 = np.array([i/f2 for i in range(sound2.size)])
# 画 2 倍采样率信号的图
plt.subplot(312)
plt.plot(t2,sound2)
plt.title('2 倍采样')
plt.ylabel('归一化幅度')
# 将采样点变为原来的 1/2
sound3 = signal.resample(sound,int(sound.size/2))
# 1/2 被采样率信号的归一化
sound3_max = np.absolute(sound3).max()
sound3 = sound3 / sound3_max
# 构建横坐标时间 t3
f3 = fs / 2
t3 = np.array([i/f3 for i in range(sound3.size)])
# 画 1/2 倍采样率信号的图
plt.subplot(313)
plt.plot(t3,sound3)
plt.title('1/2 采样')
plt.ylabel('归一化幅度')
plt.xlabel('时间/s')
plt.show()
















 4517
4517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









