






 该文章介绍了如何将Labelme格式的数据转换为COCO数据集,以用于maskrcnn的训练。文章详细展示了数据预处理步骤,包括文件重命名和目录重构,以及使用labelme2coco工具。接着,它说明了如何将转换后的数据集按照COCO标准结构组织,并提供了代码示例。最后,文章提到了在MMDetection框架内训练和测试模型的过程,以及训练过程的可视化和结果保存。
该文章介绍了如何将Labelme格式的数据转换为COCO数据集,以用于maskrcnn的训练。文章详细展示了数据预处理步骤,包括文件重命名和目录重构,以及使用labelme2coco工具。接着,它说明了如何将转换后的数据集按照COCO标准结构组织,并提供了代码示例。最后,文章提到了在MMDetection框架内训练和测试模型的过程,以及训练过程的可视化和结果保存。
上一篇文章,我们已经搭建了MMDetection的环境
这篇文章将以maskrcnn为例,将labelme格式的数据转化为coco数据集,并展示染色体分类的训练测试过程
人体的染色体有24类,1-22号常染色体 23是x染色体 24是y染色体
数据集处理
labelme->COCO
先将所有数据集目录进行重构到一个目录底下并对文件进行重命名
下面的代码是将所有数据对应的png和json数据放到一个目录下
import os
import shutil
this_dir_path = './train_labelme/'
destination_directory = './train_new/'
if not os.path.exists(destination_directory):
os.makedirs(destination_directory)
subdirectories = [] # 存储子目录名称的列表
# 遍历目录
for root, dirs, files in os.walk(this_dir_path):
for dir_name in dirs:
subdirectories.append(dir_name)
# for directory in os.listdir(this_dir_path):
for directory in subdirectories:
for file in os.listdir(os.path.join(this_dir_path, directory)):
source_file = os.path.join(os.path.join(this_dir_path, directory), file)
if directory == '211029-009C':
# 这四个文件采用的是"line strip"无法转化为coco
if os.path.splitext(file)[0] == '107_1_590_345_0.513' or \
os.path.splitext(file)[0] == '129_3_688_378_0.848' or \
os.path.splitext(file)[0] == '10_1_737_180_0.571' or \
os.path.splitext(file)[0] == '127_2_590_378_0.492':
continue
elif os.path.splitext(source_file)[-1] == '.png':
new_file_path = destination_directory + file
print(source_file + '---->' + new_file_path)
destination_file = os.path.join(destination_directory, file)
shutil.copy2(source_file, destination_file)
elif os.path.splitext(source_file)[-1] == '.json':
new_file_path = destination_directory + file
print(source_file + '---->' + new_file_path)
destination_file = os.path.join(destination_directory, file)
shutil.copy2(source_file, destination_file)
labelme 转化为coco数据集
https://github.com/fcakyon/labelme2coco
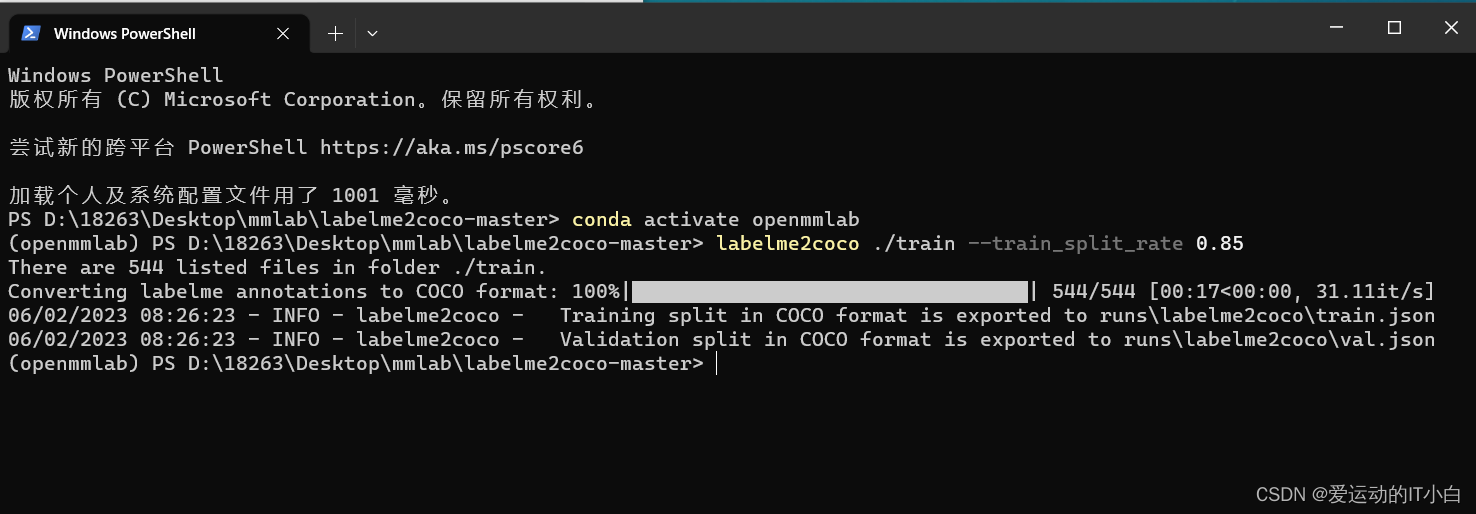
下面这段代码是将json对应的已经划分好的训练集和测试集的图片,移动到对应的coco/train2017和coco/val2017目录下
import json
import cv2
import os
import shutil
def copy2dataset(file_src, annotation, file_dir):
with open(annotation, 'r', encoding='utf-8') as f:
file_json = json.load(f)
for img in file_json['images']:
img_name = img['file_name']
for file in os.listdir(file_src):
if file.endswith(img_name):
img_name = file
break
print(img_name)
shutil.copyfile(os.path.join(file_src, img_name), os.path.join(file_dir, img_name))
if __name__ == '__main__':
# labelme_path = "./train_new"
file_root = './train_new/'
saved_coco_path = "./"
# 创建文件
if not os.path.exists("%scoco/annotations/" % saved_coco_path):
os.makedirs("%scoco/annotations/" % saved_coco_path)
if not os.path.exists("%scoco/train2017/" % saved_coco_path):
os.makedirs("%scoco/train2017" % saved_coco_path)
if not os.path.exists("%scoco/val2017/" % saved_coco_path):
os.makedirs("%scoco/val2017" % saved_coco_path)
annotation_train = './runs/labelme2coco/train.json'
annotation_val = './runs/labelme2coco/val.json'
file_dest_train = './coco/train2017/'
file_dest_val = 'coco/val2017/'
shutil.copyfile(annotation_train, os.path.join("%scoco/annotations/instances_train2017.json" % saved_coco_path))
shutil.copyfile(annotation_val, os.path.join("%scoco/annotations/instances_val2017.json" % saved_coco_path))
copy2dataset(file_root, annotation_train, file_dest_train)
copy2dataset(file_root, annotation_val, file_dest_val)
COCO 数据集格式 和 windows 下 pycocotools - 知乎 (zhihu.com)
可视化预览处理好的COCO数据集
from pycocotools.coco import COCO
import numpy as np
from matplotlib import pyplot as plt
import cv2 as cv
# 加载COCO格式的标注文件
coco = COCO('./runs/labelme2coco/train.json')
imgIds = coco.getImgIds() # 获取所有的image id,可以选择参数 coco.getImgIds(imgIds=[], catIds=[])
imgIds = coco.getImgIds(imgIds=[0, 1, 2]) # 获得image id 为 0,1,2的图像的id
imgIds = coco.getImgIds(catIds=[0, 1, 2]) # 获得包含类别 id 为0,1,2的图像
annIds = coco.getAnnIds(catIds=[0, 1, 2]) # 获得类别id为0,1,2的标签
annIds = coco.getAnnIds(imgIds=imgIds[0]) # 获得和image id对应的标签
catIds = coco.getCatIds(catNms=['0']) # 通过类别名筛选
catIds = coco.getCatIds(catIds=[0, 1, 2]) # 通过id筛选
catIds = coco.getCatIds(supNms=[]) # 通过父类的名筛选
print('类别信息')
cats_name = coco.loadCats(ids=catIds)
print(cats_name)
print('\n标签信息:')
anns = coco.loadAnns(annIds)
bboxes = np.array([i['bbox'] for i in anns]).astype(np.int32)
cats = np.array([i['category_id'] for i in anns])
print(anns)
print('\n从标签中提取的Bounding box:')
print(bboxes)
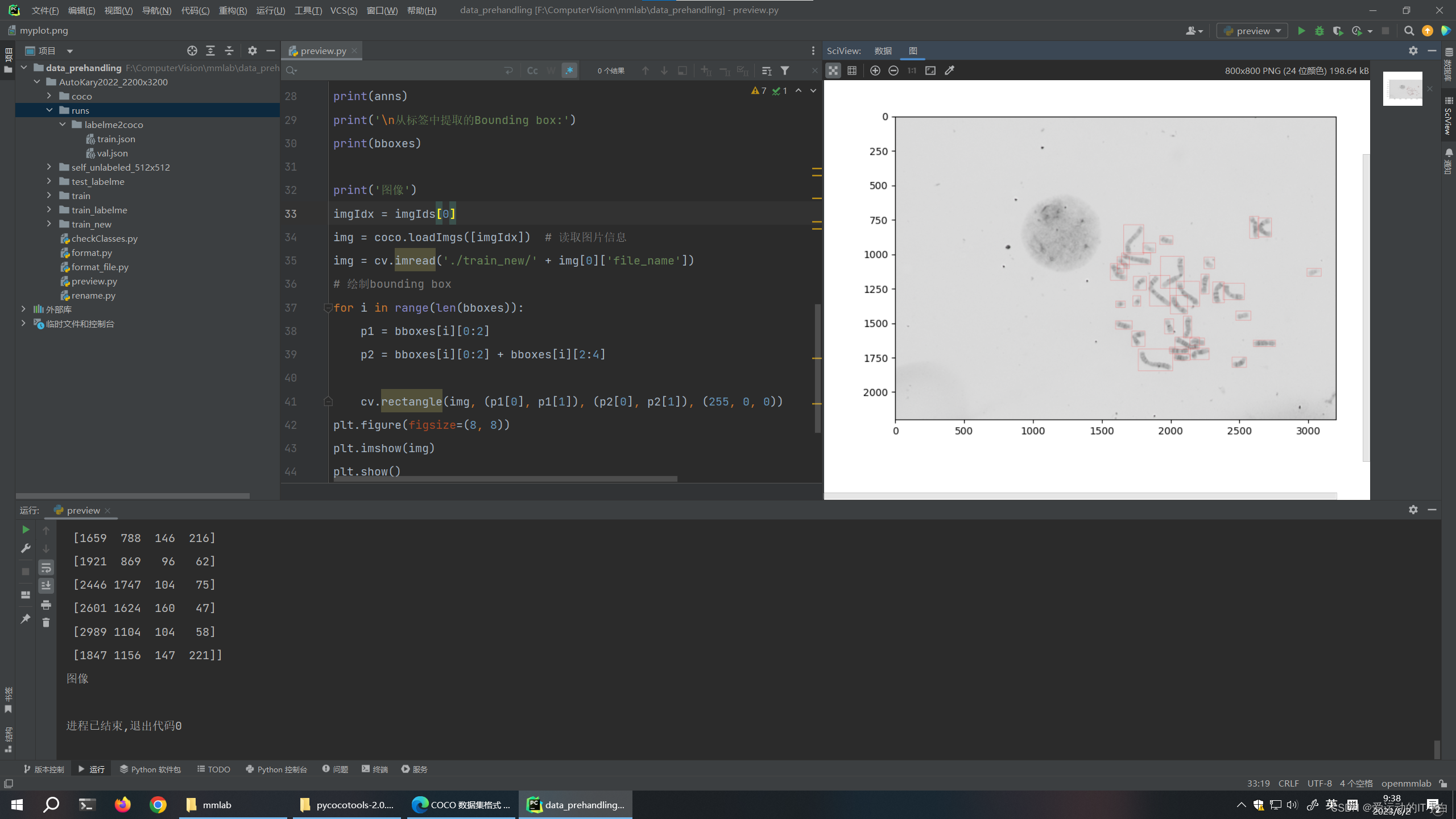
print('图像')
imgIdx = imgIds[0]
img = coco.loadImgs([imgIdx]) # 读取图片信息
img = cv.imread('./train_new/' + img[0]['file_name'])
# 绘制bounding box
for i in range(len(bboxes)):
p1 = bboxes[i][0:2]
p2 = bboxes[i][0:2] + bboxes[i][2:4]
cv.rectangle(img, (p1[0], p1[1]), (p2[0], p2[1]), (255, 0, 0))
plt.figure(figsize=(8, 8))
plt.imshow(img)
plt.show()
参考:
将Labelme标注的数据做成COCO格式的数据集(实例分割的数据集)labelme2coco一直开心的博客-CSDN博客
使用labelme标注数据集并转化为CoCo数据集labelmetococo啊~小 l i的博客-CSDN博客
B站视频:
由labelme数据集转化为coco数据集哔哩哔哩bilibili
GitHub - MrSupW/datasetapi: 规范化管理labelme数据集并生成coco数据集
修改文件中的配置参数
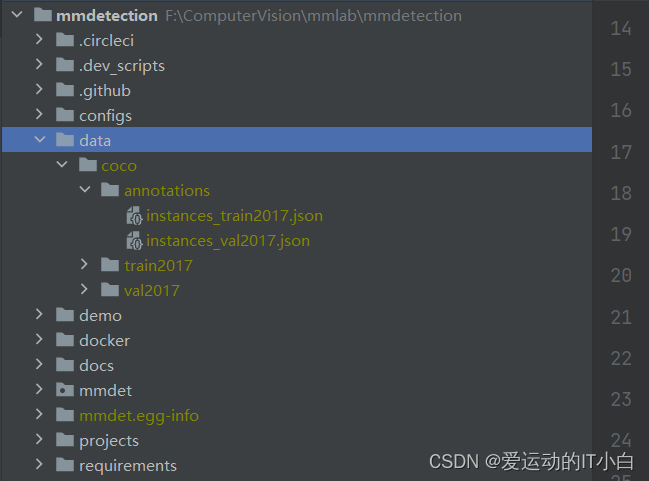
1、先在detection中创建data目录,然后将coco数据集导入到data目录下
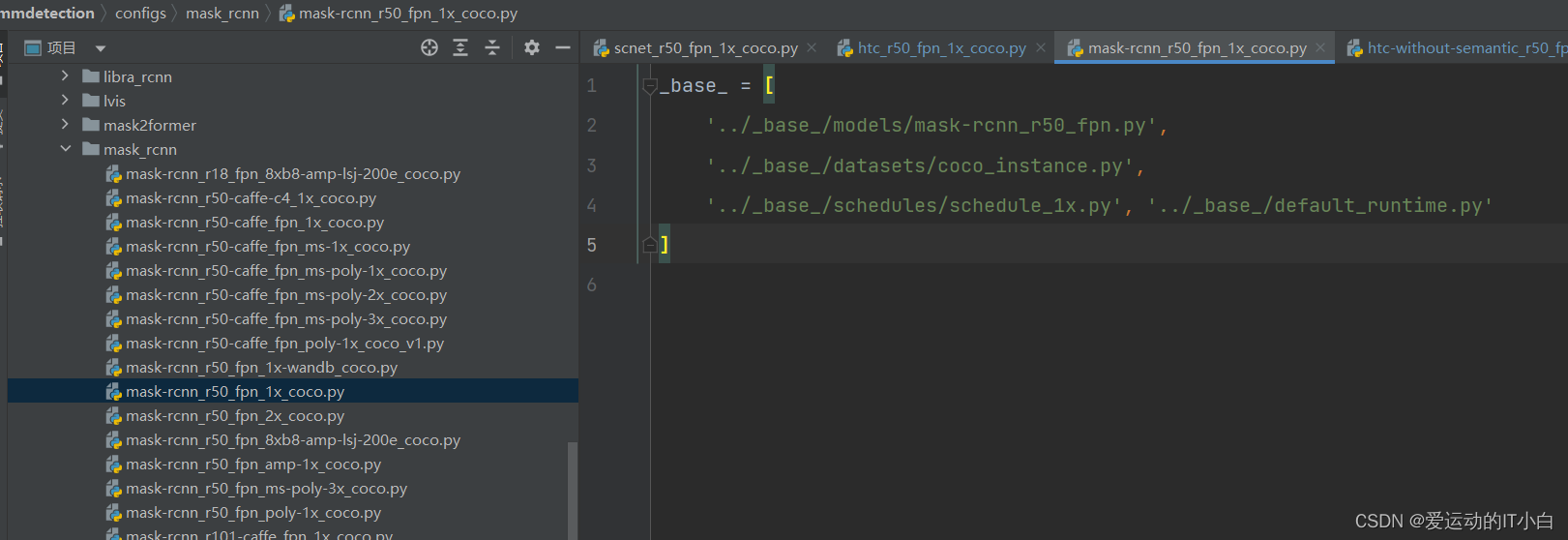
2、进入自己需要训练的模型的目录底下,查看对应需要的哪些配置文件 ,依次进入对应文件修改里面的默认的配置
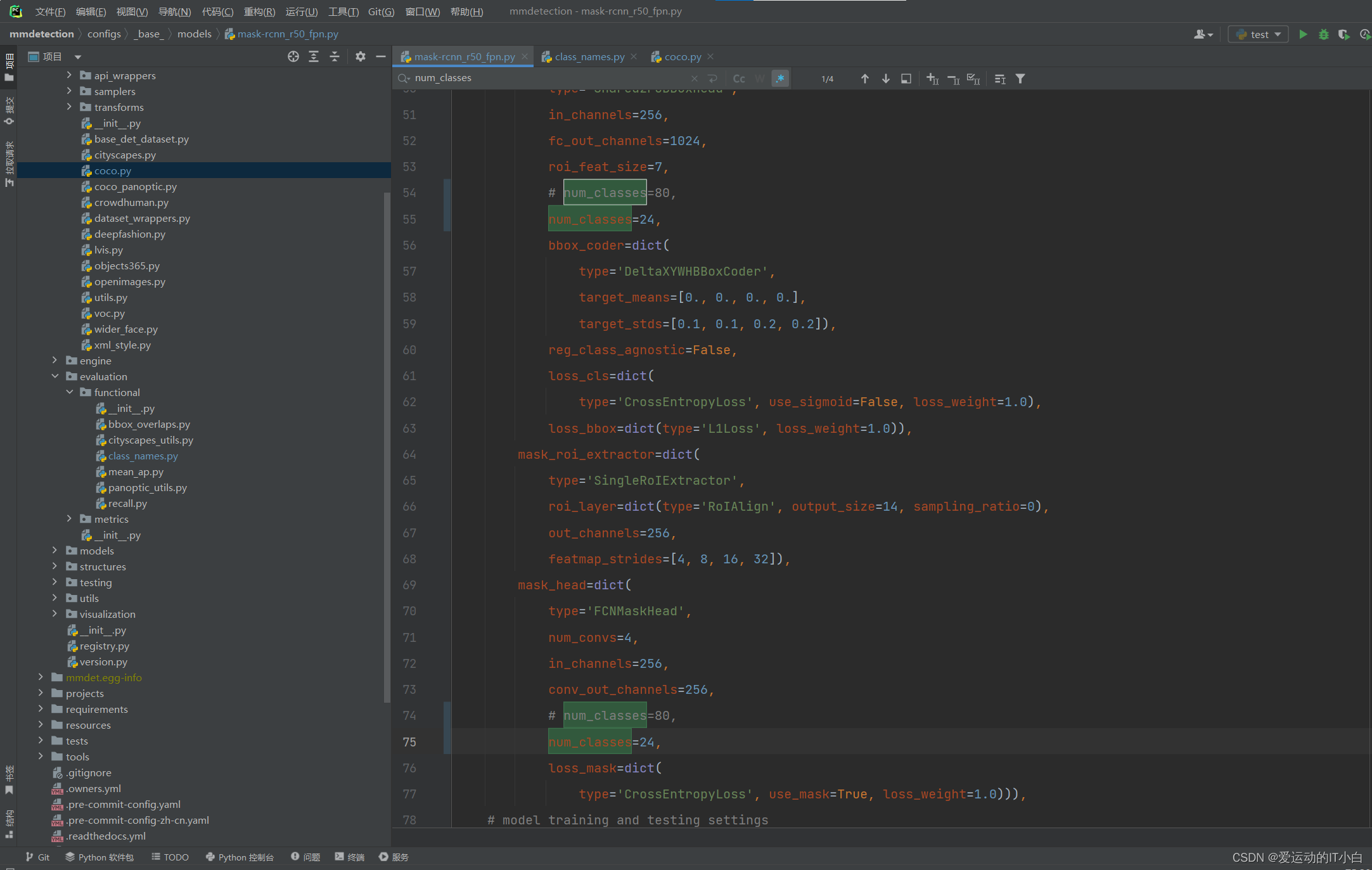
 3、这里只需要修改configs/_base_/models/mask-rcnn_r50_fpn.py修改num_classes的值为分类的数量,默认是80,染色体是24类,因此将num_classes改为24
3、这里只需要修改configs/_base_/models/mask-rcnn_r50_fpn.py修改num_classes的值为分类的数量,默认是80,染色体是24类,因此将num_classes改为24
小心遗漏,可能不只一处需要修改
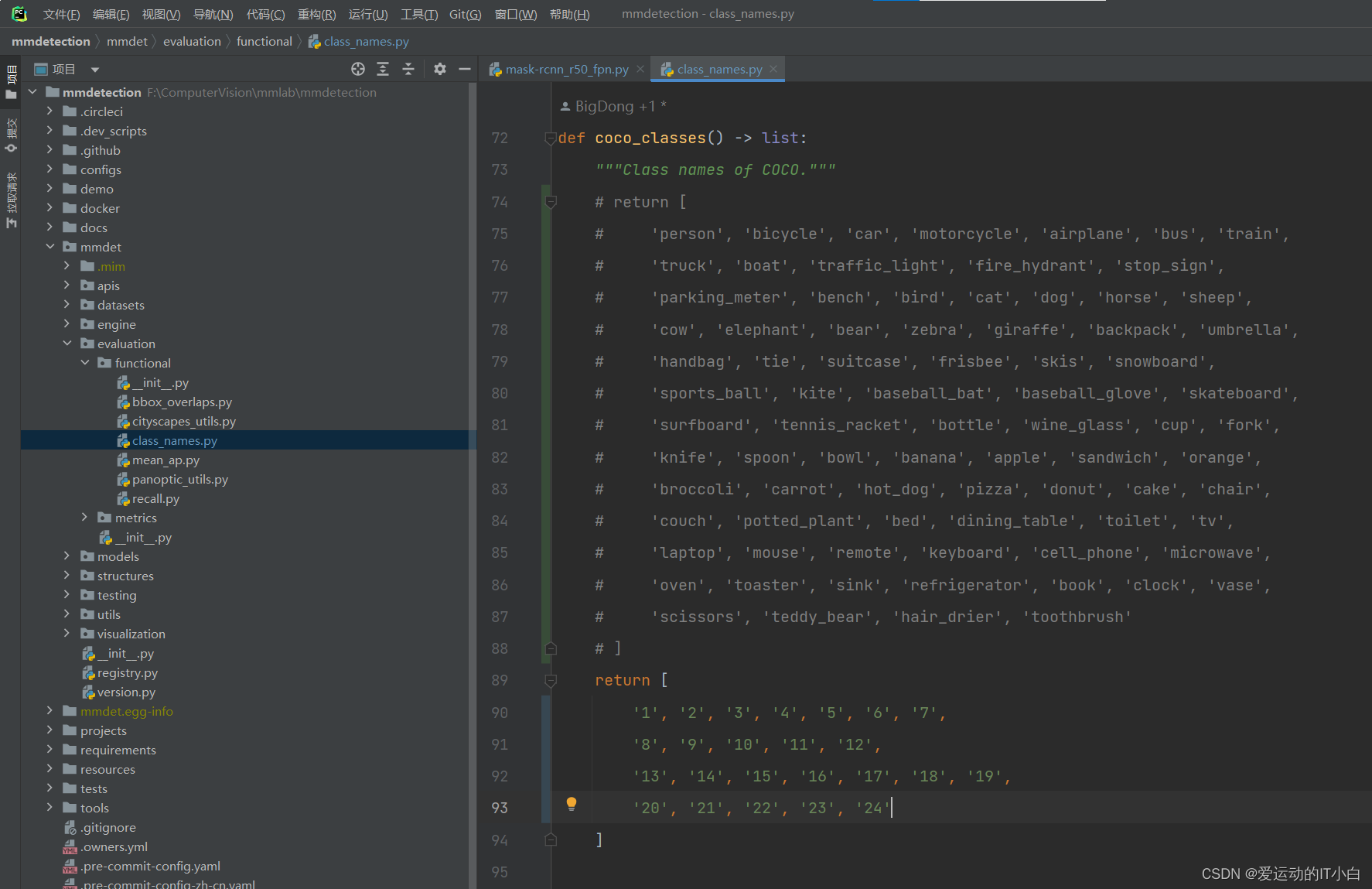
3、 mmdet/evaluation/functional/class_names.py 找到coco_classes修改成自己的分类,如下图
4、 mmdet/datasets/coco.py修改成自己的分类,如下图,只有一个分类的时候别忘了逗号 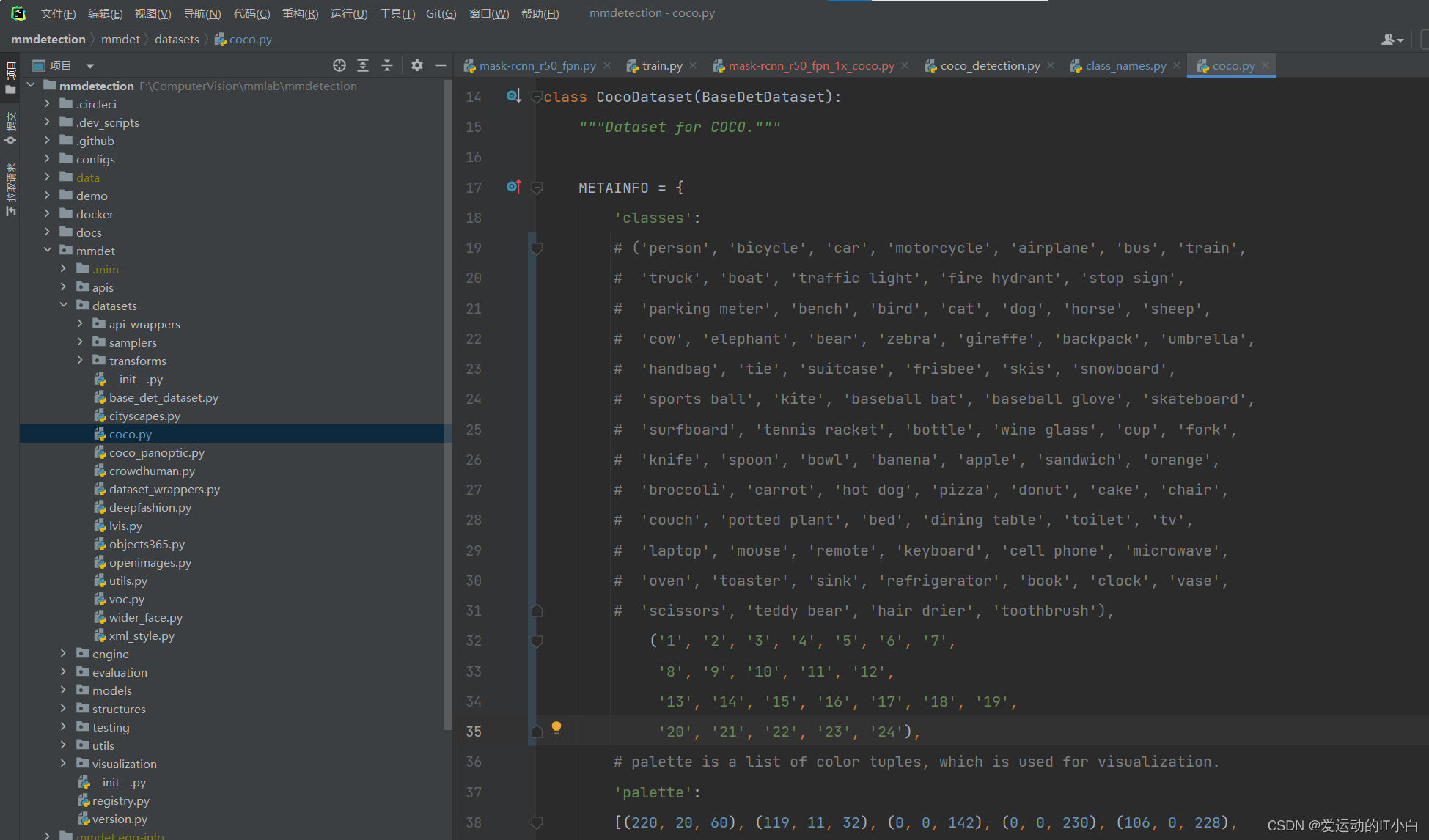
第一次运行需要指定目录 work-dir
python tools/train.py configs/mask_rcnn/mask-rcnn_r50_fpn_1x_coco.py --work-dir run_workstation运行后会在指定的work-dir目录下生成对应的mask-rcnn_r50_fpn_1x_coco.py,里面包含各种训练参数,可以直接修改(比如学习率lr等参数),下次训练时直接运行这个文件
如果电脑配置不行,CUDA内存不足,可能需要resize图片尺寸或者修改batch_size。默认的图片尺寸是(1333,800)训练集默认的batch_size=2。如下图所示,打开run_workstation/mask-rcnn_r50_fpn_1x_coco.py文件进行修改。
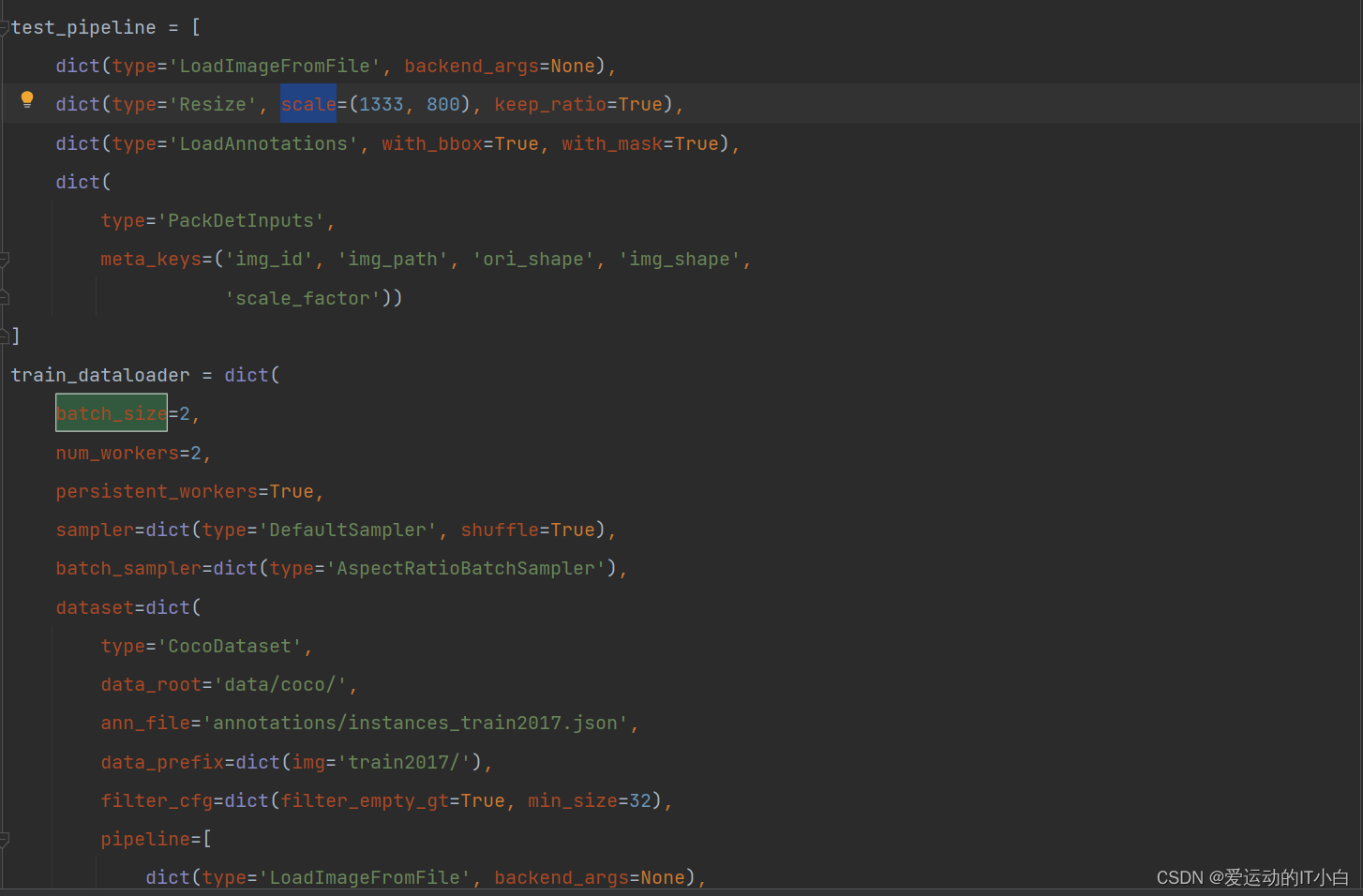
5、对生成的run_workstation/mask-rcnn_r50_fpn_1x_coco.py文件参数进行修改,将checkpoint改为4轮一次,loggerHook改为5轮一次,还可以调整学习率等超参数这个根据自己的需求修改
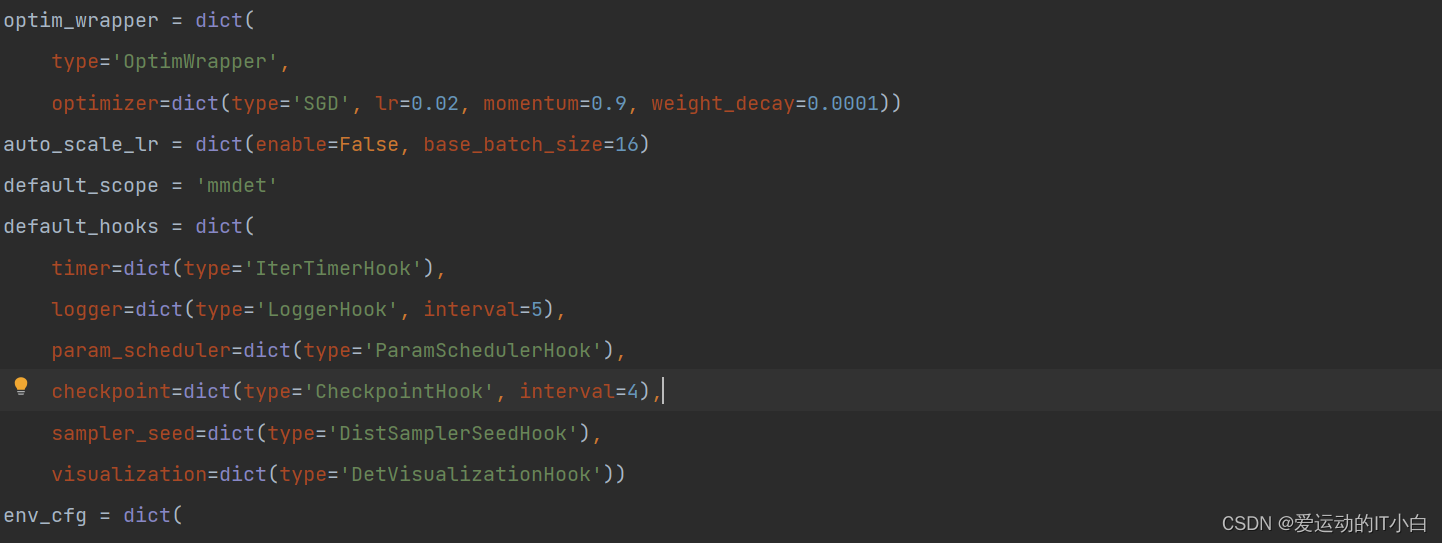
之后训练可以直接运行这个配置文件,不需要再指定--work-dir目录,执行下面的命令
python tools/train.py run_workstation/mask-rcnn_r50_fpn_1x_coco.py训练
python tools/train.py run_workstation/mask-rcnn_r50_fpn_1x_coco.py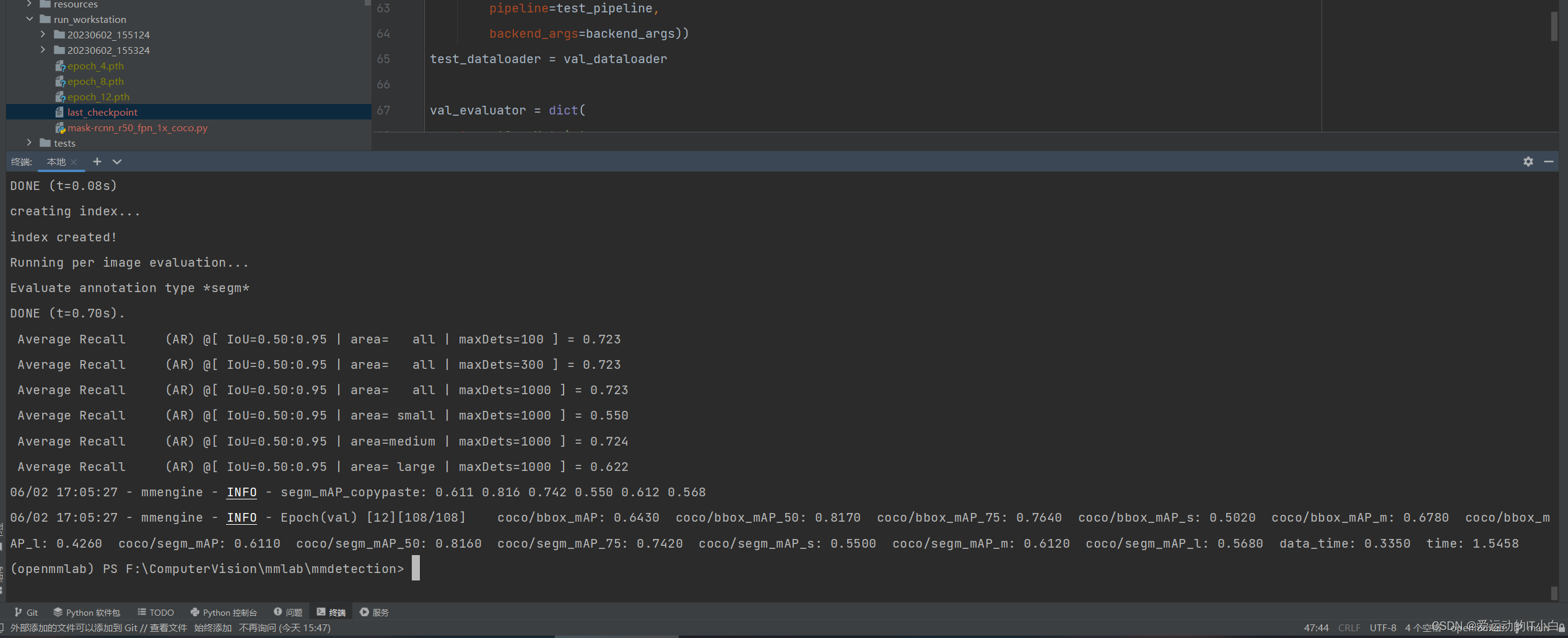
训练过程可视化
python tools/analysis_tools/analyze_logs.py plot_curve run_workstation/20230602_155324/vis_data/20230602_155324.json --keys acc 
如果要输出多个数据
python tools/analysis_tools/analyze_logs.py plot_curve run_workstation/20230602_155324/vis_data/20230602_155324.json --keys loss_cls loss_bbox loss_mask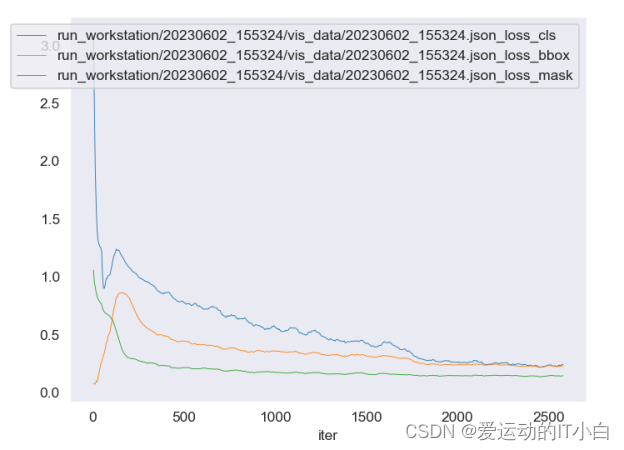
保存图片为out.pdf
python tools/analysis_tools/analyze_logs.py plot_curve run_workstation/20230602_155324/vis_data/20230602_155324.json --keys acc --out out.pdf测试
python tools/test.py run_workstation/mask-rcnn_r50_fpn_1x_coco.py run_workstation/epoch_12.pth --out=results.pkl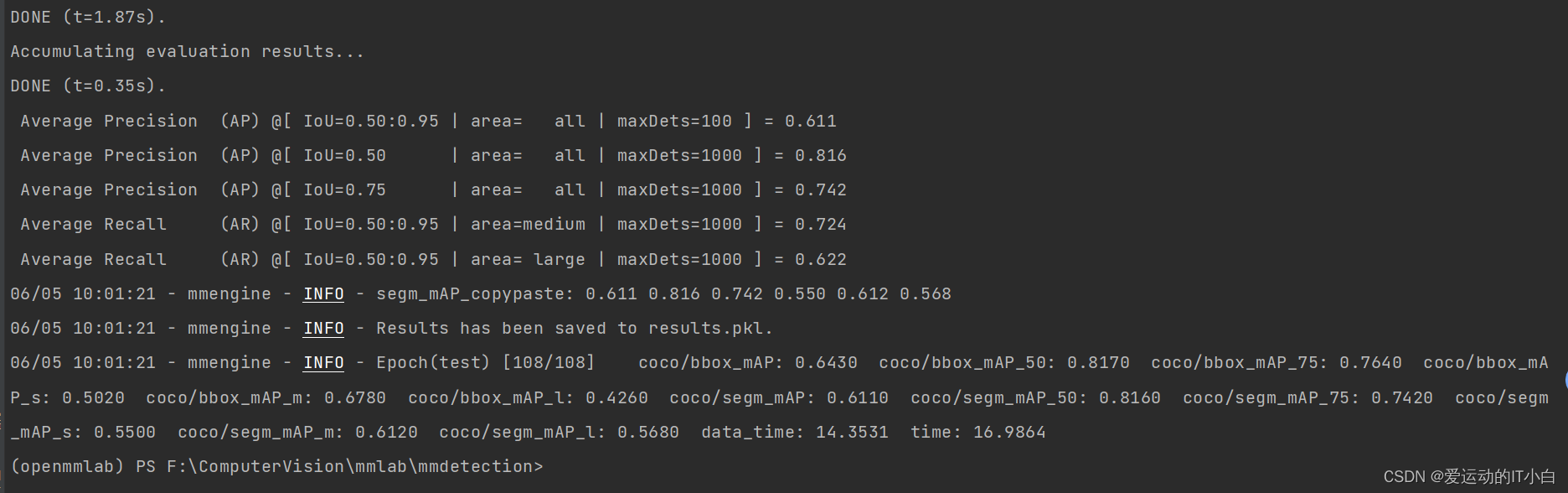
python tools/test.py run_workstation/mask-rcnn_r50_fpn_1x_coco.py run_workstation/epoch_12.pth --show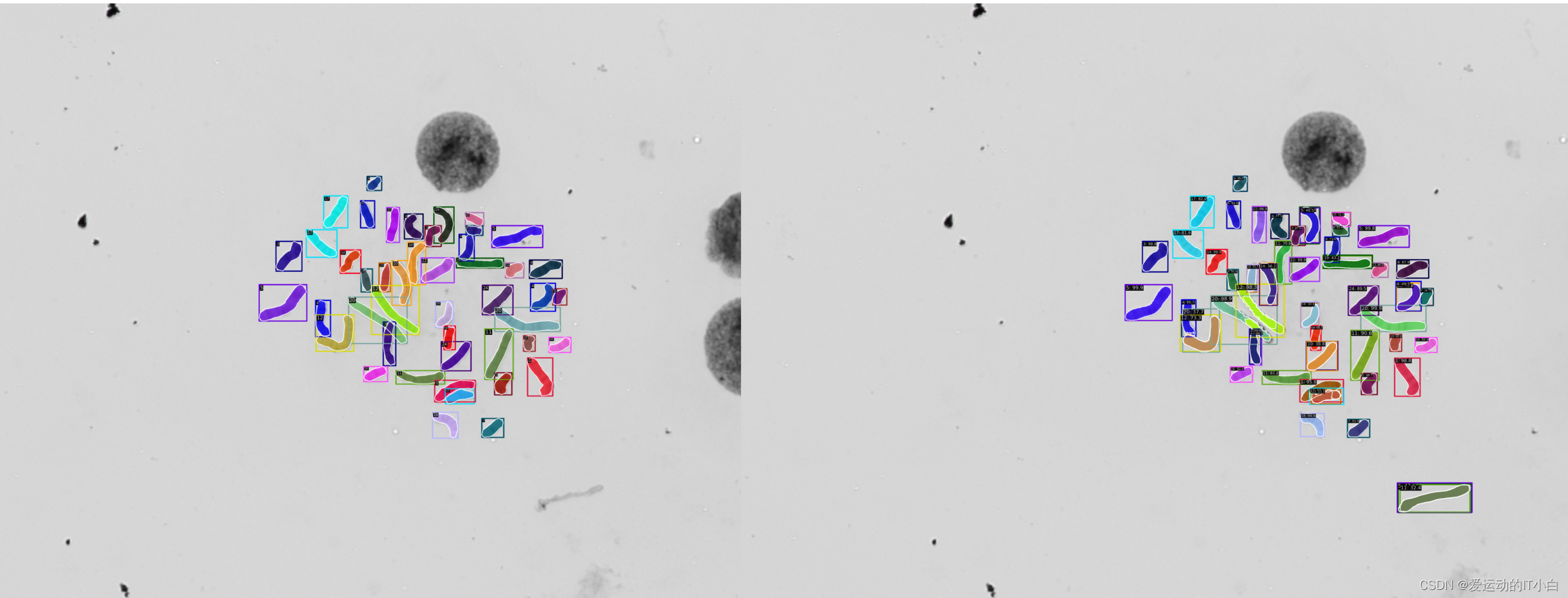
参考文献:

















 4311
4311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









