






 CLIP是OpenAI发布的基于对比学习的多模态模型,用于文本-图像对的预训练。模型包括TextEncoder和ImageEncoder,通过对比学习方法在大规模互联网数据上训练,能进行有效的零样本分类。然而,模型对数据偏见和分布变化的适应性仍有局限。
CLIP是OpenAI发布的基于对比学习的多模态模型,用于文本-图像对的预训练。模型包括TextEncoder和ImageEncoder,通过对比学习方法在大规模互联网数据上训练,能进行有效的零样本分类。然而,模型对数据偏见和分布变化的适应性仍有局限。
简介
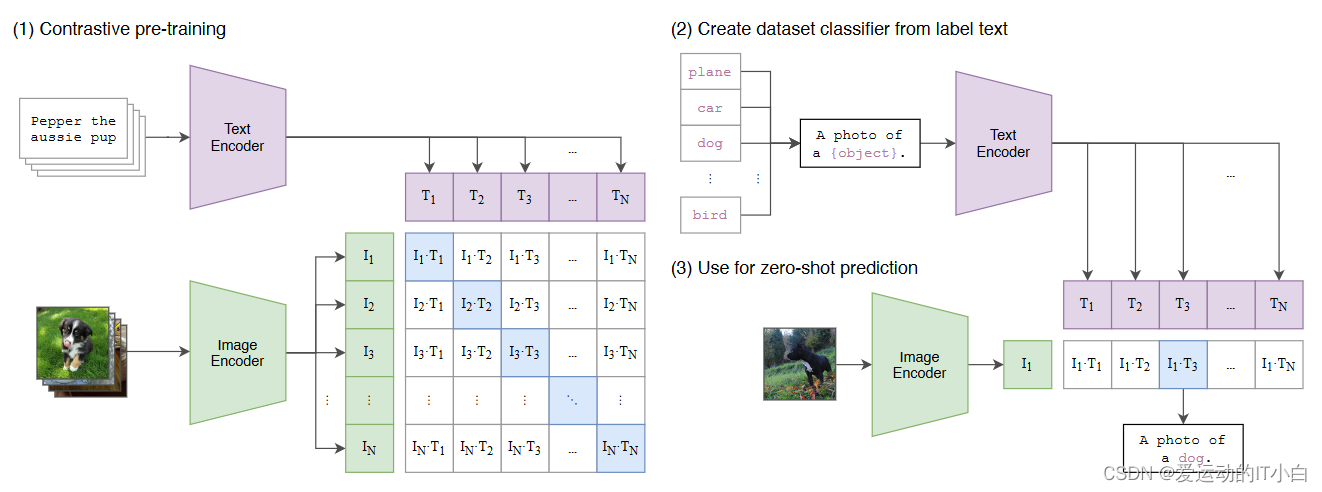
Open AI在2021年1月份发布的DALL-E和CLIP,这两个都属于结合图像和文本的多模态模型,其中DALL-E是基于文本来生成模型的模型,而CLIP是用文本作为监督信号来训练可迁移的视觉模型
CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练方法或者模型。 CLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moco和simclr不同的是, CLIP的训练数据是文本-图像对:一张图像和它对应的文本描述 。
CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。
为了训练CLIP,OpenAI从互联网收集了共4个亿的文本-图像对 (爬虫)每个图像有一个对应的文本标注。
论文:
[2103.00020] Learning Transferable Visual Models From Natural Language Supervision (arxiv.org)
什么是对比学习
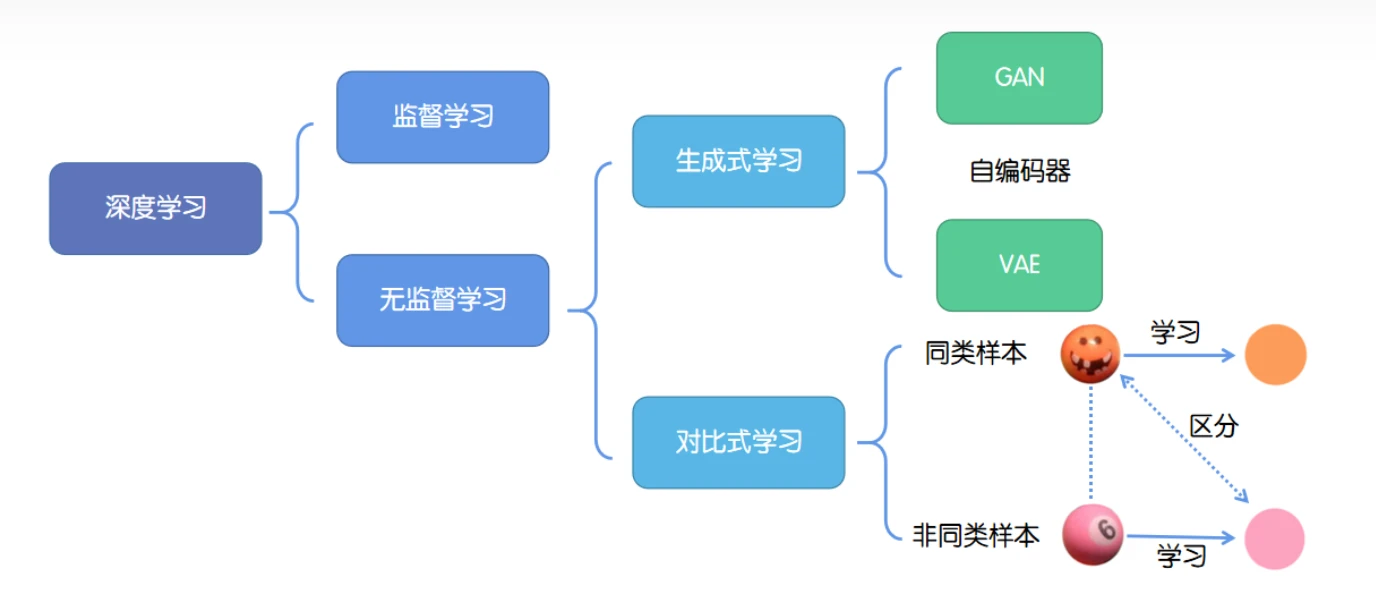
深度学习的成功往往依赖于海量数据的支持,其中对于数据的标记与否,可以分为监督学习和无监督学习。
1、 监督学习:技术相对成熟,但是对海量的数据进行标记需要花费大量的时间和资源
2、无监督学习:自主发现数据中潜在的结构,节省时间以及硬件资源。
无监督学习的主要思路: 自主地从大量数据中学习同类数据的相同特性,并将其编码为高级表征,再根据不同任务进行微调即可。
分类:
-
生成式学习:生成式学习以自编码器(例如GAN,VAE等等)这类方法为代表,由数据生成数据,使之在整体或者高级语义上与训练数据相近。
-
对比式学习: 对比式学习着重于学习同类实例之间的共同特征,区分非同类实例之间的不同之处。与生成式学习比较,对比式学习不需要关注实例上繁琐的细节,只需要在抽象语义级别的特征空间上学会对数据的区分即可,因此模型以及其优化变得更加简单,且泛化能力更强。
对比学习的目标是学习一个编码器,此编码器对同类数据进行相似的编码,并使不同类的数据的编码结果尽可能的不同。
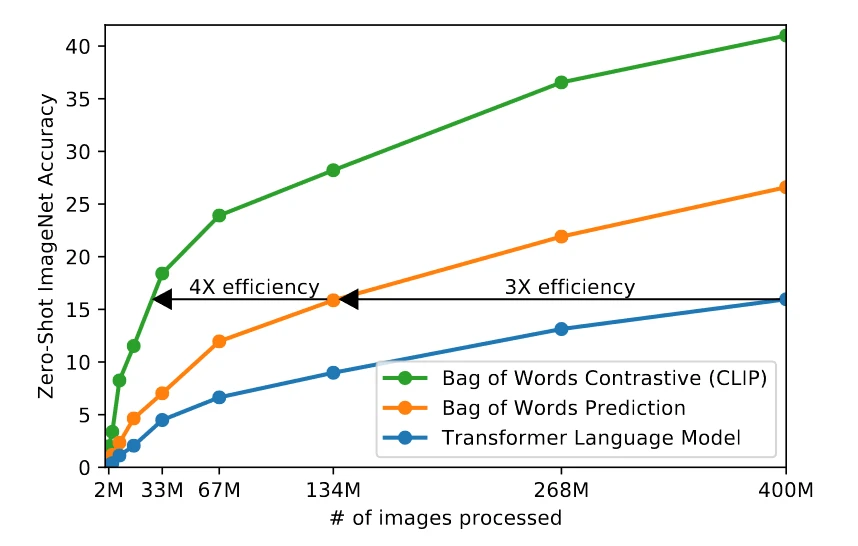
CLIP使用对比学习,不需要预测每一张图片对应的文本,而是判断图片和给定的文本是否匹配,因此效率相对提升很多
论文中的原图原话是:swapped the predictive objective for a contrastive objective and observed a further 4x efficiency improvement in the rate of zero-shot transfer to ImageNet
CILP工作原理
CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练方法或者模型。 CLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moco和simclr不同的是, CLIP的训练数据是文本-图像对:一张图像和它对应的文本描述 。
CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer
为了训练CLIP,OpenAI从互联网收集了共4个亿的文本-图像对 (爬虫)每个图像有一个对应的文本标注
(一)预训练
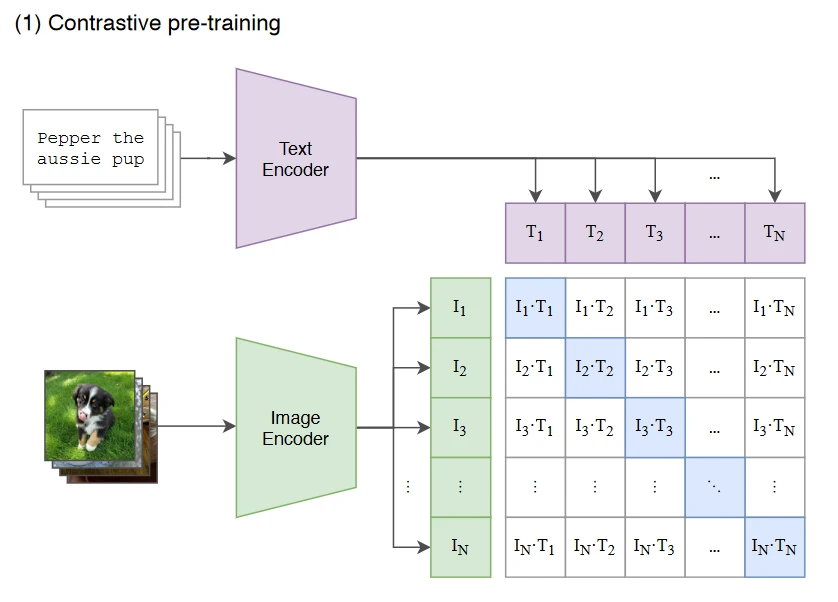
对提取的文本特征和图像特征进行对比学习。对于一个包含N个文本-图像对的训练batch,将N个文本特征和N个图像特征两两组合,CLIP模型会预测出N^2个可能的文本-图像对的相似度,这里的相似度直接计算文本特征和图像特征的余弦相似性(cosine similarity),即上图所示的矩阵。这里共有N个正样本,即真正属于一对的文本和图像(矩阵中的对角线元素),而剩余的N^2−N个文本-图像对为负样本,那么CLIP的训练目标就是最化N个正样本的相似度,同时最小化N^2−N个负样本的相似度 。
为了训练CLIP,OpenAI从互联网收集了共4个亿的文本-图像对,论文称之为WebImageText,如果按照文本的单词量,它和训练GPT-2的WebText规模类似,如果从数量上对比的话,它还比谷歌的JFT-300M数据集多一个亿,所以说这是一个很大规模的数据集。CLIP虽然是多模态模型,但它主要是用来训练可迁移的视觉模型。

在模型训练过程中,我们取到的每个batch由 N个图像-文本对组成。这 N个图像送入到图像编码器中会得到 N个图像特征向量 ,同理将N个文本送入到文本编码器中可以得到 N个文本特征向量 。
因为只有在对角线上的图像和文本是一对,标记为正样本,所以CLIP的训练目标是让是正样本的特征向量相似度尽可能高,而负样本的相似度尽可能低,这里相似度的计算使用的是向量内积。通过这个方式,CLIP构建了一个由 N个正样本和 N个负样本组成的对比损失函数。另外,因为不同编码器的输出的特征向量长度不一样,CLIP使用了一个线性映射将两个编码器生成的特征向量映射到统一长度(多模态特征的联合表示),CLIP的计算过程伪代码如上图
(二)推理
如何用CLIP实现zero-shot分类
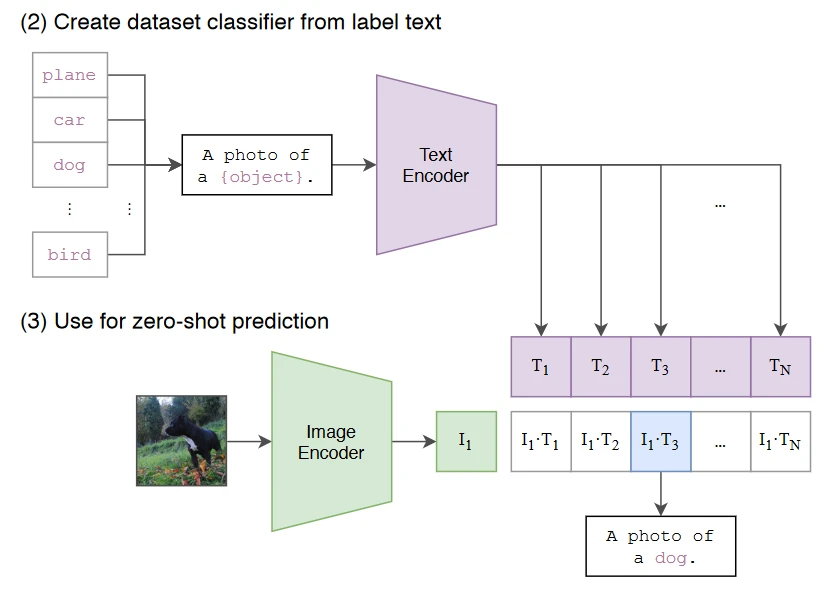
1. 根据任务的分类标签构建每个类别的描述文本:A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征,如果类别数目为N,那么将得到N个文本特征;
2. 将要预测的图像送入Image Encoder得到图像特征,然后与N个文本特征计算缩放的余弦相似度(和训练过程一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果,进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率。
Prompt engineering and Prompt Ensembling
CLIP中的Prompt Engineering和Prompt Ensembling - 知乎 (zhihu.com)
使用prompt template A photo of {label},如果提前知道一些图片的信息,有利于zero-shot迁移。多用一些提示样本,有利于提高模型准确率。
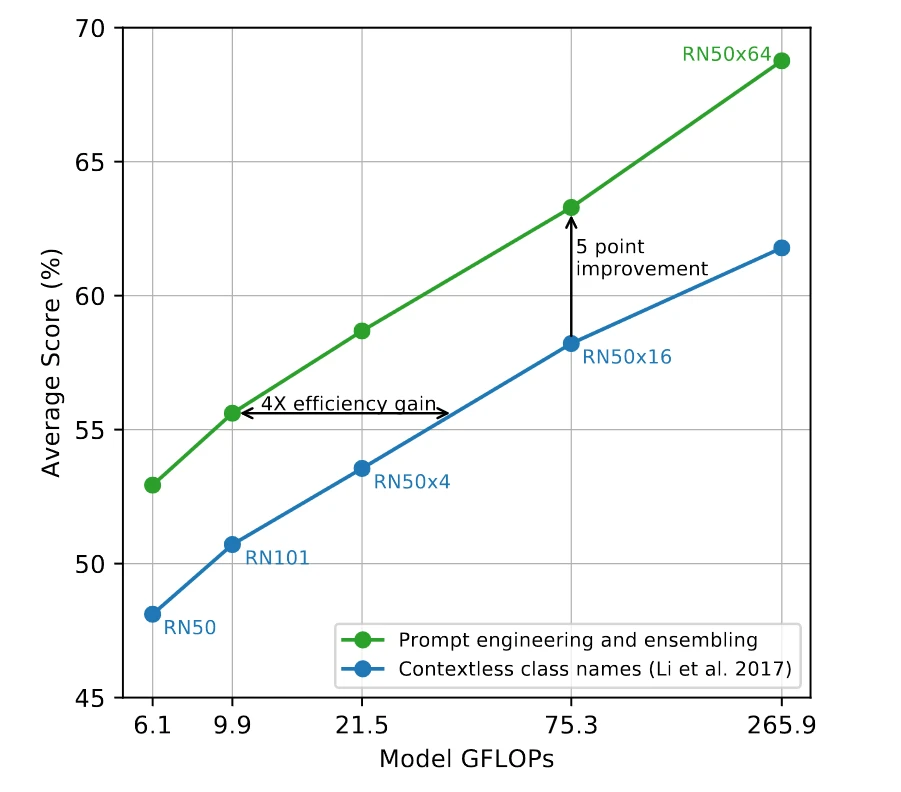
对于比较难的训练样本(比如给肿瘤做分类),需要采用Few-shot模型训练
linear probe
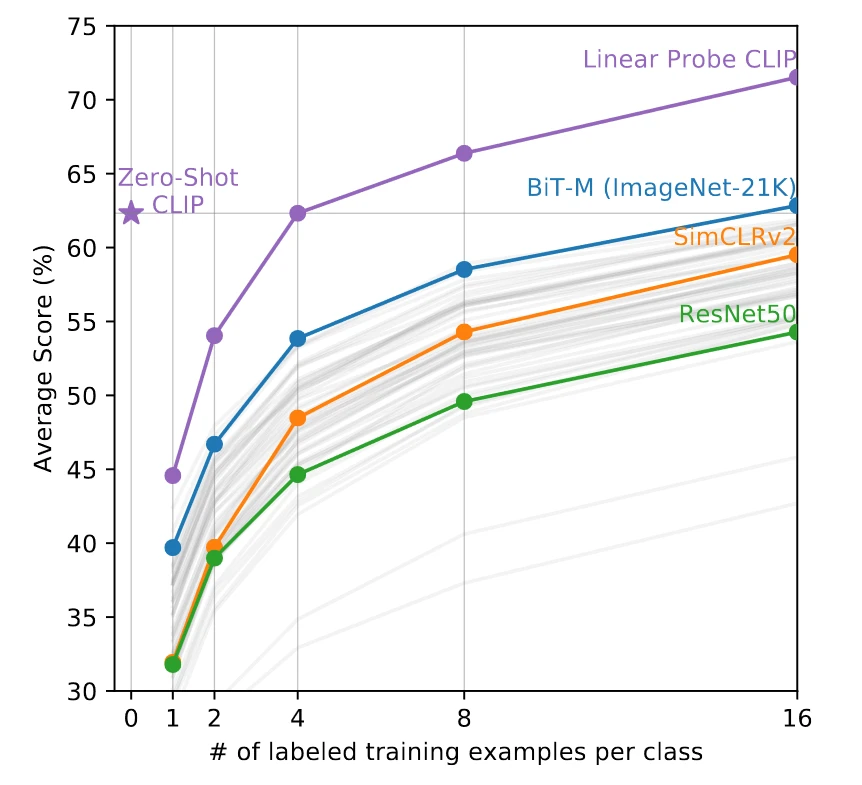
论文中提到的下游采用两种方式
linear probe:Fitting a linear classifier on a representation extracted from the model and measuring its performance on various datasets is a common approach
fine-tune: An alternative is measuring the performance of end-to-end fine-tuning of the model. This increases flexibility, and prior work has convincingly demonstrated that fine-tuning outperforms linear classification on most image classification datasets
论文作者推荐使用linear probe:主要两个原因,使用lineaar probe 可以比较好反映预训练模型的好坏,另一方面使用fine-tune端到端微调模型的参数,需要调整合适的超参数
局限性
1、和先进模型相比还是有比较大的差距,通过直接扩大训练量来弥补不现实
2、很多领域,clip方法不行
3、虽然clip泛化能力很强,对于很多自然图片的分布偏移模型相对稳健,但是在推理过程中,对于如果训练数据和给定的数据集相差很大(out-of-distribution),模型的泛化能力照样很差。MNIST
4、图片来自网上,没有清洗,存在偏见
5、clip对数据的利用不是很高效,使用了大量的数据集训练——》数据增强(自监督,伪标签)
6、有些分类任务,给定图片,反而效果更差

















 2618
2618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









