numpy属性
import numpy as np
array = np.array([[1, 2, 3],
[2, 3, 4]])
print(array)
print(array.ndim)
print(array.shape)
print(array.size)

numpy的创建 array
import numpy as np
a = np.array([1, 2, 3], dtype=np.int_)
print(a.dtype)
import numpy as np
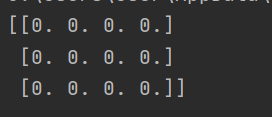
a = np.zeros((3, 4))
print(a)
import numpy as np
a = np.arange(1, 12, 2)
print(a)

import numpy as np
a = np.arange(12).reshape((3, 4))
print(a)

import numpy as np
a = np.linspace(1, 10, 6).reshape((3, 2))
print(a)

numpy的基础运算(1)
import numpy as np
a = np.array([12, 32, 13, 21])
b = np.arange(4)
c = a-b
print(c)
c = a+b
print(c)
c = b**2
print(c)
c = np.sin(a)
print(c)
print(b < 3)
import numpy as np
m = np.array([[1, 2],
[2, 3]])
n = np.arange(4).reshape((2, 2))
c = m*n
print(c)
'''[[0 2]
[4 9]]
'''
c_dot = np.dot(m, n)
print(c_dot)
'''[[ 4 7]
[ 6 11]]
'''
import numpy as np
a = np.random.random((2, 4))
print(a)
'''
[[0.67842665 0.05748582 0.20033281 0.15301078]
[0.29284424 0.70485296 0.45562099 0.08003088]]
'''
print(np.sum(a, axis=1))
numpy的基础运算(2)
import numpy as np
A = np.arange(14, 2, -1).reshape((4, 3))
print(np.nanargmin(A))
print(np.nanargmax(A))
print(np.nanmean(A))
print(np.median(A))
print(np.cumsum(A))
print(np.diff(A))
print(np.nonzero(A))
print(np.sort(A))
print(np.transpose(A))
'''
[[14 11 8 5]
[13 10 7 4]
[12 9 6 3]]
'''
print(np.clip(A, 5, 9))
'''
[[9 9 9]
[9 9 9]
[8 7 6]
[5 5 5]]
'''
print(np.mean(A, axis=0))
print(np.mean(A, axis=1))
pandas 的选择数据
import pandas as pd
import numpy as np
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.arange(24).reshape((6, 4)), index=dates, columns=['A', 'B', 'C', 'D'])
print(df)
'''
A B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
'''
print(df['A'])
'''
2013-01-01 0
2013-01-02 4
2013-01-03 8
2013-01-04 12
2013-01-05 16
2013-01-06 20
Freq: D, Name: A, dtype: int32
'''
print(df[0:3])
'''
A B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11
'''
print(df['20130102':'20130104'])
'''
A B C D
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11
2013-01-04 12 13 14 15
'''
print(df.loc['20130101'])
'''
A 0
B 1
C 2
D 3
Name: 2013-01-01 00:00:00, dtype: int32
'''
print(df.loc[:, ['A', 'B']])
'''
A B
2013-01-01 0 1
2013-01-02 4 5
2013-01-03 8 9
2013-01-04 12 13
2013-01-05 16 17
2013-01-06 20 21
'''
print(df.loc['20130101', ['A', 'B']])
'''
A 0
B 1
Name: 2013-01-01 00:00:00, dtype: int32
'''
print(df.iloc[3])
'''
A 12
B 13
C 14
D 15
Name: 2013-01-04 00:00:00, dtype: int32
'''
print(df.iloc[3, 1])
'''
13
'''
print(df.iloc[3:5, 1:3])
'''
B C
2013-01-04 13 14
2013-01-05 17 18
# '''
pandas的导入导出
import pandas as pd
date = pd.read_csv('../数据/城市数据_加盐.csv')
print(date)
'''
Unnamed: 0 year_id month_id cty_cd 旅客量 客座率
0 0 2016 11 SSS 1537975 0.833608
1 1 2015 7 AAA 3603737 0.842056
2 2 2016 6 SSS 1405626 0.847005
3 3 2015 5 CCC 632758 0.853672
4 4 2017 8 HHH 771068 0.895236
.. ... ... ... ... ... ...
715 715 2017 2 UUU 866150 0.830707
716 716 2015 4 AAA 3502777 0.835406
717 717 2015 3 RRR 1621762 0.831659
718 718 2015 2 WWW 2685700 0.801839
719 719 2017 2 MMM 749305 0.843860
[720 rows x 6 columns]
'''
date.to_pickle('city.pickle')
pandas合并concat























 347
347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









