






编码是将信息从一种形式或格式转换为另一种形式的过程。在电子计算机、电视、遥控和通讯等领域中,编码被广泛使用。编码通常涉及将文字、数字或其他对象转换为特定的数码或电脉冲信号。例如,在计算机中,字符编码是将字符(如字母、数字、标点符号等)转换为计算机能够理解的二进制代码。常见的字符编码方式有ASCII、Unicode、UTF-8、GBK等。
解码是编码的逆过程,即将编码后的数据还原成原始格式。在接收端,解码器会对接收到的编码数据进行解码,以恢复成原始的数据形式。
ASCII码
ASCII码(American Standard Code for Information Interchange,美国信息交换标准代码)是用于电子通信的标准字符编码系统。它是最早用于计算机编程和文本处理的字符集之一,也是目前计算机中最常用的字符集之一。
ASCII码包含了128个特定的字符,包括英文字母(大写和小写)、数字(0-9)、标点符号和一些控制字符。每个字符都对应一个唯一的数字代码,这些数字代码在计算机内部用来表示和存储字符。
在ASCII码表中,字符按照特定的顺序排列,每个字符都有一个对应的十进制数字代码。例如,大写字母'A'的ASCII码是65,小写字母'a'的ASCII码是97,数字'0'的ASCII码是48。
ASCII码在计算机编程中非常重要,因为它提供了一种标准化的方式来表示和交换文本信息。几乎所有的编程语言和计算机系统都支持ASCII码,使得在不同的系统和平台之间交换文本数据变得简单和可靠。
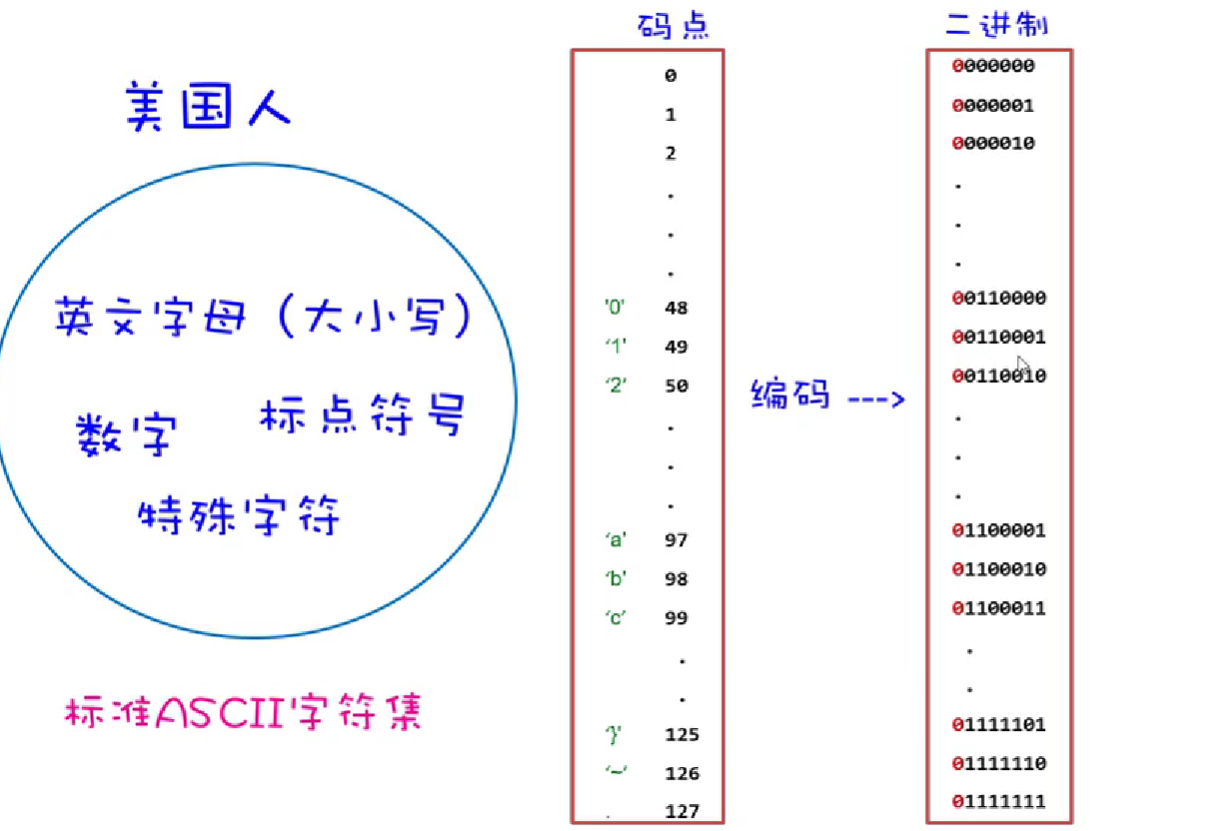
需要注意的是,ASCII码只支持基本的英文字符和数字,对于其他语言的字符集(如中文、日文等)并不适用。
简言之,ASCII编码是一种编码规则,将英文或数字对应的ASCII码转换成计算机可识别的二进制。
解码同样使用ASCII码将计算机字节转换成字符。
GBK码
GBK编码(GBK Chinese Internal Code Specification)是一种针对汉字的字符编码标准,它是对GB2312编码的扩展,全称为《汉字内码扩展规范》。GBK编码包含了GB2312编码中的全部汉字,并对一些生僻汉字和少数民族文字进行了扩充,共收录了21003个中日韩汉字和符号。
GBK编码采用双字节编码方案,其编码范围从8140到FEFE,共23940个码位。在GBK编码中,英文字母、数字、标点等非汉字字符仍然只占用一个字节,其编码值与ASCII码相同。因此,GBK编码既兼容ASCII编码,又能够表示大量的汉字字符。

通过首位可以区分汉字和英文字母数字及标点,使得编码和解码不会出现乱码。
Unicode码
Unicode(统一码、万国码、单一码)是一种计算机科学领域里的业界标准,用于字符编码。它解决了传统字符编码方案的局限,为世界上几乎所有的字符(包括汉字、阿拉伯字母、希腊字母、英文字母、数字、标点符号等)都设定了统一并且唯一的二进制编码,从而实现了跨语言、跨平台的文本转换和处理。
Unicode 的主要特点包括:
- 统一编码:Unicode 为每个字符分配了一个唯一的数字编号,即码位(code point)。这些码位从 0 到 0x10FFFF,总共可以容纳 1114112 个字符。这意味着无论是哪种语言的字符,只要它们被 Unicode 收录,都可以使用同一个编码表示。
- 兼容性:Unicode 编码兼容 ASCII 编码,即 ASCII 编码中的字符在 Unicode 编码中的码位与 ASCII 码相同。这样,在处理只包含 ASCII 字符的文本时,可以直接使用 Unicode 编码,无需进行转换。
- 可扩展性:Unicode 编码的设计允许随时增加新的字符。随着新字符和语言的加入,Unicode 标准会不断更新和扩展。
- 多种实现方式:虽然 Unicode 定义了字符的码位,但如何将这些码位转换为实际存储在计算机中的二进制代码则有多种实现方式。目前常用的 Unicode 编码方式有 UTF-8、UTF-16 和 UTF-32。这些编码方式各有特点,适用于不同的场景和需求。
-
- UTF-8:是一种可变长度的 Unicode 字符编码,它用 1 到 4 个字节来表示一个 Unicode 码位。UTF-8 编码方式在互联网上得到了广泛应用,因为它兼容 ASCII 编码,并且可以表示任意 Unicode 码位。
- UTF-16:是一种固定长度的 Unicode 字符编码,它用 2 个或 4 个字节来表示一个 Unicode 码位。UTF-16 编码方式在 Windows 操作系统中得到了广泛应用。
- UTF-32:也是一种固定长度的 Unicode 字符编码,它始终用 4 个字节来表示一个 Unicode 码位。UTF-32 编码方式在处理 Unicode 字符时比较简单,但会占用较多的存储空间。
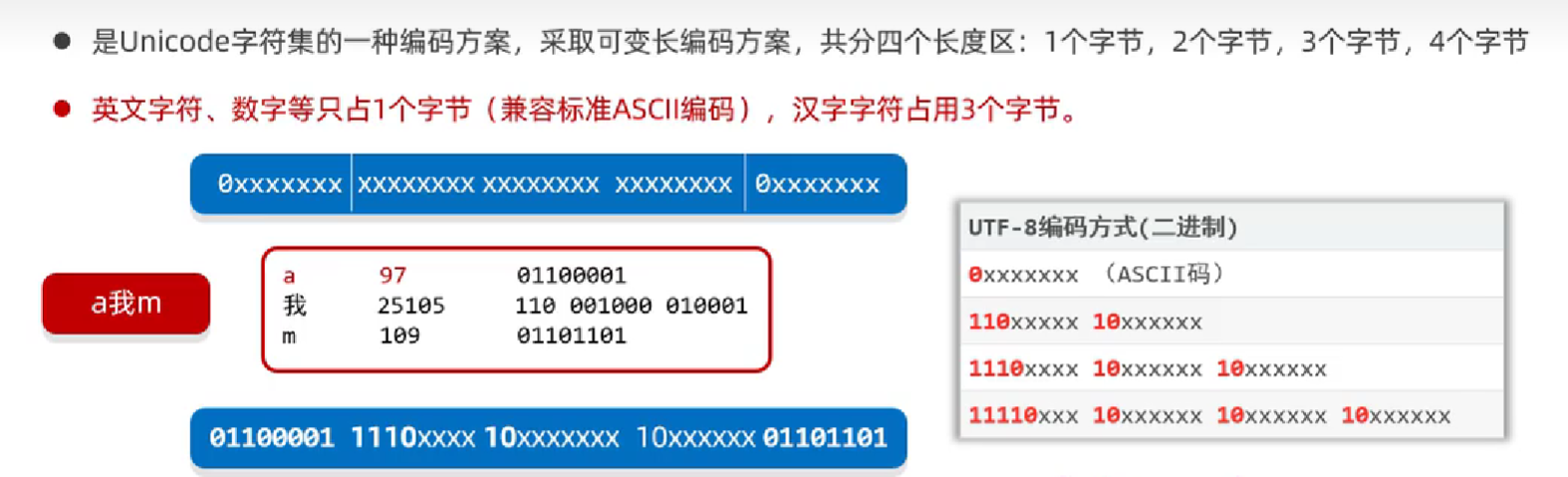
使用java代码完成编码与解码

public class FileLearn4 {
public static void main(String[] args) throws UnsupportedEncodingException {
byte[] bytes = "a我e".getBytes("GBK");
System.out.println(new String(bytes,"GBK"));
}
}执行结果:




















 6720
6720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











