






前言
Hi,各位深度学习玩家.
博主是一个大三学生,去年8月在好奇心的驱使下开始了动手深度学习,一开始真是十分恼火,论文读不懂,实验跑不通,不理解内部原理,也一直苦于没有合适的blog指引。
这篇博客既是我对自己一个科研里程碑的回忆,也希望能帮助读者更快的进入深度学习的大门,2023我们一起努力!
一、图片集增强预处理
transforms.Compose()函数就是将一些transforms组合在一起;每一个transforms都有自己对应的功能。
transform = transforms.Compose([
transforms.Resize(100),
transforms.RandomVerticalFlip(),
transforms.RandomCrop(50),
transforms.RandomResizedCrop(150),
transforms.ColorJitter(brightness=0.5, contrast=0.5, hue=0.5),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
transforms.Compose常见预处理操作:
-
transform.Resize() 为将给定图片重新设置尺寸
-
transform.RandomVerticalFlip() 对传入图像p=0.5的水平翻转,方便后期更好的识别效果
-
transforms.RandomCrop(50) 随即取一块50*50的图片区域,意义同上句
-
transforms.RandomResizedCrop(150) 随即取一块150*150的图片区域,该操作的含义在于:即使只是该物体的一部分,我们也认为这是该类物体
-
transforms.ColorJitter(brightness=0.5, contrast=0.5, hue=0.5) 改变图像的属性:亮度(brightness)、对比度(contrast)、饱和度(saturation)和色调(hue)
-
transforms.ToTensor(): 将shape为(H, W, C)的nump.ndarray或img转为shape为(C, H, W)的tensor,其将每一个数值归一化到[0,1],其归一化方法比较简单,直接除以255即可。
-
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]): 其作用就是先将输入归一化到(0,1),再使用公式"(x-mean)/std",将每个元素分布到(-1,1)
很多代码里面是这样的:
torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
这一组值是怎么来的捏?
这一组值是从Imagenet训练集中抽样算出来的。
二、定义数据读取接口
PyTorch中数据读取的一个重要接口是torch.utils.data.DataLoader,该接口主要用来将自定义的数据读取接口的输出,下面的代码是用来设置我的train set和test set位置
dataset_train = datasets.ImageFolder('train集位置', transform)
print(dataset_train.imgs) #输出经过transform处理的图片
print(dataset_train.class_to_idx) #输出此图片所在位置
dataset_test = datasets.ImageFolder('test集位置', transform)
print(dataset_test.class_to_idx)
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE,
shuffle=True)
torch.utils.data.DataLoader参数:
- dataset (Dataset) – 加载数据的数据集。
- batch_size (int, optional) – 每个batch加载多少个样本(默认: 1)。
- shuffle (bool, optional) – 设置为True时会在每个epoch重新打乱数据(默认: False).
- sampler (Sampler, optional) – 定义从数据集中提取样本的策略,即生成index的方式,可以顺序也可以乱序
- num_workers (int, optional) – 用多少个子进程加载数据。0表示数据将在主进程中加载(默认: 0)
- collate_fn (callable, optional) –将一个batch的数据和标签进行合并操作。
- pin_memory (bool, optional) –设置pin_memory=True,则意味着生成的Tensor数据最开始是属于内存中的锁页内存,这样将内存的Tensor转义到GPU的显存就会更快一些。
- drop_last (bool, optional) – 如果数据集大小不能被batch size整除,则设置为True后可删除最后一个不完整的batch。如果设为False并且数据集的大小不能被batch size整除,则最后一个batch将更小。(默认: False)
- timeout,是用来设置数据读取的超时时间的,但超过这个时间还没读取到数据的话就会报错。
三、数据加载器
torchvision.datasets.ImageFolder是一个通用的数据加载器,其中的图像默认是以这种方式排列的:
root/dog/xxx.png
root/dog/xxy.png
root/dog/[...]/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/[...]/asd932_.png
dataset=torchvision.datasets.ImageFolder(
root, transform=None,
target_transform=None,
loader=<function default_loader>,
is_valid_file=None)
dataset_train = datasets.ImageFolder('\\train', transform)
torchvision.datasets.ImageFolder参数:
- root:图片存储的根目录,即各类别文件夹所在目录的上一级目录。
- transform:对图片进行预处理的操作(函数),原始图片作为输入,返回一个转换后的图片。
- target_transform:对图片类别进行预处理的操作,输入为 target,输出对其的转换。 如果不传该参数,即对 target 不做任何转换,返回的顺序索引 0,1, 2…
- loader:表示数据集加载方式,通常默认加载方式即可。
- is_valid_file:获取图像文件的路径并检查该文件是否为有效文件的函数(用于检查损坏文件)
- 返回的dataset都有以下两种属性:
self.class_to_idx:类别对应的索引,与不做任何转换返回的 target 对应
self.imgs:保存(img-path, class) tuple的 list
四、定义网络backbone
这个部分是我一开始最头痛的,我是先学了python的几个库pandas、matplotlib等,就直接开始读论文,但是python的面向对象我是一点没学,然后看别人的源码就看不懂,现在发现自己曾经的问题还是基础没打牢,导致后面思想走在了实践的前面,夯实基础才是第一步!
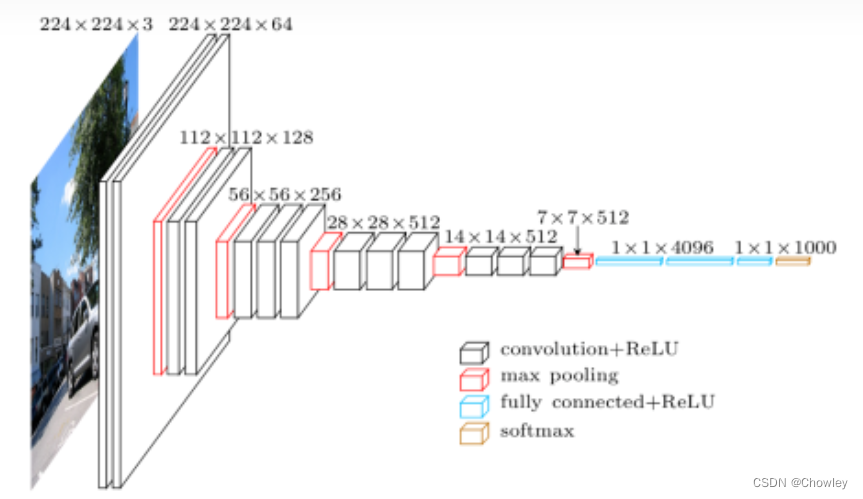
先看下模型图吧,多么经典的形状。
'''
我们的网络将识别图像。我们将使用PyTorch中内置的一个称为卷积的过程。卷积将图像的每个元素添加到它的本地邻居中,由一个内核或一个小矩阵加权,帮助我们从输入图像中提取某些特征(如边缘检测、清晰度、模糊度等)。
定义你的模型的Net类有两个要求。第一个是写一个引用nn.Module的__init__函数。这个函数是你定义神经网络中全连接层的地方。
我们已经完成了对神经网络的定义,现在我们必须定义我们的数据将如何通过它。
指定数据将如何通过你的模型:
当你使用PyTorch建立一个模型时,你只需要定义forward函数,它将把数据传入计算图(即我们的神经网络)。这将代表我们的前馈算法。
你可以在forward函数中使用任何张量操作。
'''
class VGG16(nn.Module):
def __init__(self, num_classes=1000):
super(VGG16, self).__init__()
# 第一段卷积层
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# 第二段卷积层
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# 第三段卷积层
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# 第四段卷积层
self.conv4 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# 第五段卷积层
self.conv5 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# 全连接层
self.fc = nn.Sequential(
nn.Linear(in_features=512*7*7, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(in_features=4096, out_features=num_classes)
)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.fc(x)
return x
我来对上面使用的函数逐个解释
nn.Sequential:一个有顺序的容器。模块将按照构造函数中传递的顺序被添加到其中。或者,可以传入一个模块的OrderedDict。Sequential的forward()方法接受任何输入并将其转发给它所包含的第一个模块。然后,它按顺序将每个后续模块的输出与输入 "串联 "起来,最后返回最后一个模块的输出。
与手动调用模块序列相比,Sequential提供的价值在于它允许将整个容器视为一个单一的模块,这样在Sequential上执行的转换适用于它所存储的每个模块(它们都是Sequential的一个注册子模块)。
Sequential和Torch.nn.ModuleList之间有什么区别?ModuleList正是它听起来的样子——一个用于存储模块的列表!另一方面,Sequential中的各层是以级联的方式连接的。
nn.Conv2d:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=‘zeros’, device=None, dtype=None)
- 输入输出通道数大家应该都能懂
- kernel_size是指卷积核的尺寸
- stride 控制互相关的步幅,单个数字或元组。
- padding 控制应用于输入的填充量。它可以是字符串 {‘valid’, ‘same’} 或 int / 整数元组,给出应用在两侧的隐式填充量。
- dilation 控制内核点之间的间距;也称为 à trous 算法。很难描述,但是这个链接很好地形象化了 dilation 的作用。
- groups 控制输入和输出之间的连接。 in_channels 和 out_channels 都必须能被 groups 整除。
nn.ReLU是非线性激活函数,激活函数是指在多层神经网络中,上层神经元的输出和下层神经元的输入存在一个函数关系,这个函数就是激活函数。上层神经元通过加权求和,得到输出值,然后被作用一个激活函数,得到下一层的输入值。引入激活函数的目的是为了增加神经网络的非线性拟合能力。
nn.MaxPool2d:对邻域内特征点取最大,减小卷积层参数误差造成估计均值的偏移的误差,更多的保留纹理信息。
nn.Linear:用于设置网络中的全连接层的,需要注意在二维图像处理的任务中,全连接层的输入与输出一般都设置为二维张量,形状通常为[batch_size, size],不同于卷积层要求输入输出是四维张量。
nn.Dropout:是为了防止过拟合而设置的,
只能用在训练部分而不能用在测试部分,一般用在全连接神经网络映射层之后
n.Dropout(p = 0.3) 表示每个神经元有0.3的可能性不被激活
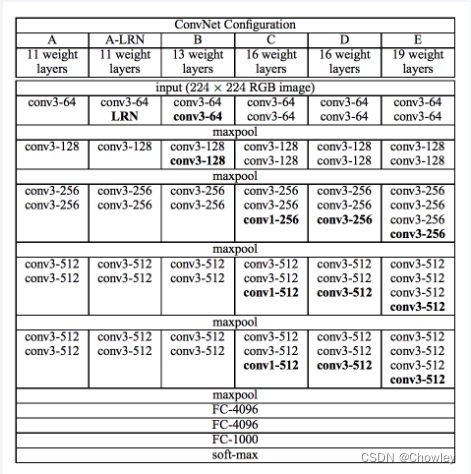
网络结构:参考VGGNet论文,进行了VGG16的复现
五、学习率和优化器
optimizer = optim.Adam(model.parameters(), lr=modellr) #定义优化器
def adjust_learning_rate(optimizer, epoch):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
modellrnew = modellr * (0.1 ** (epoch // 5)) #更新学习率
print("lr:", modellrnew)
for param_group in optimizer.param_groups:
param_group['lr'] = modellrnew #存储学习率
params: 模型里需要被更新的可学习参数
lr: 学习率
Adam:它能够对每个不同的参数调整不同的学习率,对频繁变化的参数以更小的步长进行更新,而稀疏的参数以更大的步长进行更新。
特点:
1、结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点;
2、对内存需求较小;
3、为不同的参数计算不同的自适应学习率;
4、也适用于大多非凸优化-适用于大数据集和高维空间。
六、训练过程
def train(model, device, train_loader, optimizer, epoch):
model.train()#模型训练
for batch_idx, (data, target) in enumerate(train_loader): #循环参数更新
data, target = data.to(device), target.to(device).float().unsqueeze(1)
optimizer.zero_grad()
output = model(data)
# print(output)
loss = F.binary_cross_entropy(output, target)
loss.backward()
optimizer.step()
if (batch_idx + 1) % 10 == 0: #每一个周期后输出训练结果
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader), loss.item()))
loss.backward():
PyTorch的反向传播(即tensor.backward())是通过autograd包来实现的,autograd包会根据tensor进行过的数学运算来自动计算其对应的梯度。
如果没有进行backward()的话,梯度值将会是None,因此loss.backward()要写在optimizer.step()之前。
optimizer.step():
优化器的作用就是针对计算得到的参数梯度对网络参数进行更新,所以要想使得优化器起作用,主要需要两个东西:
优化器需要知道当前的网络模型的参数空间
优化器需要知道反向传播的梯度信息(即backward计算得到的信息)
七、测试过程
def val(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device).float().unsqueeze(1)
output = model(data)
# print(output)
test_loss += F.binary_cross_entropy(output, target, reduction='mean').item()
pred = torch.tensor([[1] if num[0] >= 0.5 else [0] for num in output]).to(device)
correct += pred.eq(target.long()).sum().item()
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
binary_cross_entropy:
这个损失函数非常经典,我的第一个项目实验就使用的它。

在上述公式中,xi代表第i个样本的真实概率分布,yi是模型预测的概率分布,xi表示可能事件的数量,n代表数据集中的事件总数。交叉熵可以分解为两部分:第一部分是xi的熵,代表真实分布的不确定性;第二部分是xi和yi之间的KL离散度,代表两个分布之间的距离。交叉熵越小,说明概率分布越大,这意味着分类结果越好。
结语
重新梳理一下才知道当年的自己写的有多烂,即使是现在也不见得有多清晰,只是字面意义上的懂了,就像炖菜加大料,我也不知道大料是干啥的,只知道别人都加它,可能还是我一个本科生太浅薄了,需要去企业沉淀一下,也许过滤之后才知道现在的杂质在哪里,这篇文章送给过去半年的自己,我们走过了疫情,2023会好起来的!















 5222
5222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











