






 文章介绍了PLSA算法的基本原理,包括E步和M步的推导过程,以及如何用Python实现该算法对包含物理学、计算机科学等领域的文献进行主题分析。实验结果显示,算法能够有效识别各领域特征词,验证了其在内容社区领域的适用性。
文章介绍了PLSA算法的基本原理,包括E步和M步的推导过程,以及如何用Python实现该算法对包含物理学、计算机科学等领域的文献进行主题分析。实验结果显示,算法能够有效识别各领域特征词,验证了其在内容社区领域的适用性。

PLSA又称为概率潜在语义分析,是一种利用概率生成模型对文本集合进行话题分析的无监督学习方法。该模型最大的特点是加入了主题这一隐变量,文本生成主题,主题生成单词,从而得到单词-文本共现矩阵。本文将对包含物理学、计算机科学、统计学、数学四个领域的15000条文献摘要的数据集(保存在Task-Corpus.csv中)使用PLSA算法进行处理。
一、算法推导
1.1 E-steps
设单词集合为 w i ( i = 1 , ⋯ , M ) w_i(i = 1,\cdots,M) wi(i=1,⋯,M),其中 M M M为单词数;文本集合为 d j ( j = 1 , ⋯ , N ) d_j(j = 1,\cdots, N) dj(j=1,⋯,N),其中 N N N为文本数;主题集合为 z k ( k = 1 , ⋯ , K ) z_k(k = 1,\cdots,K) zk(k=1,⋯,K),其中 K K K为主题数。对给定的文本,主题的分布是一个有 K K K个选项的多项分布,因此参数个数为 N × K N\times K N×K,设参数矩阵为 Λ \Lambda Λ。对给定的主题,单词的分布是一个有 M M M个选项的多项分布,因此参数个数为 K × M K\times M K×M,设参数矩阵为 Θ \Theta Θ。一般来说 K ≪ M K \ll M K≪M,这就避免了模型的过拟合。
如果主题未知,根据全概率公式有
p
(
w
i
,
d
j
)
=
p
(
d
j
)
∑
k
=
1
K
p
(
w
i
∣
z
k
)
p
(
z
k
∣
d
j
)
p(w_i, d_j) = p(d_j)\sum_{k = 1}^K p(w_i | z_k)p(z_k | d_j)
p(wi,dj)=p(dj)k=1∑Kp(wi∣zk)p(zk∣dj)
因此非完全数据(主题未知)的似然函数为
L
(
Θ
,
Λ
∣
X
)
=
p
(
X
∣
Θ
)
=
∏
i
=
1
M
∏
j
=
1
N
(
p
(
d
j
)
∑
k
=
1
K
p
(
w
i
∣
z
k
)
p
(
z
k
∣
d
j
)
)
n
(
w
i
,
d
j
)
L(\Theta, \Lambda | X) = p(X | \Theta) = \prod_{i = 1}^M\prod_{j = 1}^N (p(d_j)\sum_{k = 1}^K p(w_i | z_k)p(z_k | d_j))^{n(w_i, d_j)}
L(Θ,Λ∣X)=p(X∣Θ)=i=1∏Mj=1∏N(p(dj)k=1∑Kp(wi∣zk)p(zk∣dj))n(wi,dj)
对数似然为
log
L
(
Θ
,
Λ
∣
X
)
=
∑
i
=
1
M
∑
j
=
1
N
n
(
w
i
,
d
j
)
log
(
p
(
d
j
)
∑
k
=
1
K
p
(
w
i
∣
z
k
)
p
(
z
k
∣
d
j
)
)
\log L(\Theta, \Lambda | X) = \sum_{i = 1}^M \sum_{j = 1}^N n(w_i, d_j)\log(p(d_j)\sum_{k = 1}^K p(w_i | z_k)p(z_k | d_j))
logL(Θ,Λ∣X)=i=1∑Mj=1∑Nn(wi,dj)log(p(dj)k=1∑Kp(wi∣zk)p(zk∣dj))
对数似然中包含求和的对数,因此难以处理。
如果主题已知,文章
d
j
d_j
dj出现单词
w
i
w_i
wi的概率为
p
(
w
i
,
d
j
)
=
p
(
d
j
)
p
(
w
i
∣
z
k
)
p
(
z
k
∣
d
j
)
p(w_i, d_j) = p(d_j)p(w_i | z_k)p(z_k | d_j)
p(wi,dj)=p(dj)p(wi∣zk)p(zk∣dj)
因此完全数据的似然函数为
L
(
Θ
∣
X
)
=
∏
i
=
1
M
∏
j
=
1
N
(
p
(
d
j
)
p
(
w
i
∣
z
k
)
p
(
z
k
∣
d
j
)
)
n
(
w
i
,
d
j
)
L(\Theta | X) = \prod_{i = 1}^M \prod_{j = 1}^N (p(d_j)p(w_i | z_k)p(z_k | d_j))^{n(w_i, d_j)}
L(Θ∣X)=i=1∏Mj=1∏N(p(dj)p(wi∣zk)p(zk∣dj))n(wi,dj)
对数似然为
log
L
(
Θ
∣
X
)
=
∑
j
=
1
N
n
(
w
i
,
d
j
)
log
(
p
(
d
j
)
p
(
w
i
∣
z
k
)
p
(
z
k
∣
d
j
)
)
\log L(\Theta | X) =\sum_{j = 1}^N n(w_i, d_j) \log(p(d_j)p(w_i | z_k)p(z_k | d_j))
logL(Θ∣X)=j=1∑Nn(wi,dj)log(p(dj)p(wi∣zk)p(zk∣dj))
Q函数为对数似然
log
L
(
Θ
∣
X
)
\log L(\Theta | X)
logL(Θ∣X)在后验分布
p
(
z
k
∣
w
i
,
d
j
)
p(z_k | w_i, d_j)
p(zk∣wi,dj)下的期望
Q
=
∑
k
=
1
K
p
(
z
k
∣
w
i
,
d
j
)
∑
i
=
1
M
∑
j
=
1
N
n
(
w
i
,
d
j
)
log
(
p
(
d
j
)
p
(
w
i
∣
z
k
)
p
(
z
k
∣
d
j
)
)
=
∑
i
=
1
M
∑
j
=
1
N
n
(
w
i
,
d
j
)
∑
k
=
1
K
p
(
z
k
∣
w
i
,
d
j
)
log
(
p
(
d
j
)
p
(
w
i
∣
z
k
)
p
(
z
k
∣
d
j
)
)
\begin{aligned}Q &= \sum_{k = 1}^K p(z_k | w_i, d_j) \sum_{i = 1}^M \sum_{j = 1}^N n(w_i, d_j) \log(p(d_j)p(w_i | z_k)p(z_k | d_j)) \\&= \sum_{i = 1}^M \sum_{j = 1}^N n(w_i, d_j)\sum_{k = 1}^K p(z_k | w_i, d_j)\log(p(d_j)p(w_i | z_k)p(z_k | d_j))\end{aligned}
Q=k=1∑Kp(zk∣wi,dj)i=1∑Mj=1∑Nn(wi,dj)log(p(dj)p(wi∣zk)p(zk∣dj))=i=1∑Mj=1∑Nn(wi,dj)k=1∑Kp(zk∣wi,dj)log(p(dj)p(wi∣zk)p(zk∣dj))
其中后验概率
p
(
z
k
∣
w
i
,
d
j
)
=
p
(
w
i
∣
z
k
)
p
(
z
k
∣
d
j
)
∑
k
=
1
K
p
(
w
i
∣
z
k
)
p
(
z
k
∣
d
j
)
(1)
p(z_k | w_i, d_j) = \frac{p(w_i | z_k) p(z_k | d_j)}{\sum_{k = 1}^K p(w_i | z_k) p(z_k | d_j)}\tag{1}
p(zk∣wi,dj)=∑k=1Kp(wi∣zk)p(zk∣dj)p(wi∣zk)p(zk∣dj)(1)
1.2 M-step
p
(
w
i
∣
z
k
)
,
p
(
z
k
∣
d
j
)
p(w_i | z_k), p(z_k | d_j)
p(wi∣zk),p(zk∣dj)满足约束条件
∑
i
=
1
M
p
(
w
i
∣
z
k
)
=
1
,
k
=
1
,
⋯
,
K
\sum_{i = 1}^M p(w_i | z_k) = 1, k = 1,\cdots,K
i=1∑Mp(wi∣zk)=1,k=1,⋯,K
∑
k
=
1
K
p
(
z
k
∣
d
j
)
=
1
,
j
=
1
,
⋯
,
N
\sum_{k = 1}^K p(z_k | d_j) = 1,j = 1,\cdots,N
k=1∑Kp(zk∣dj)=1,j=1,⋯,N
引入拉格朗日函数
J
=
Q
+
∑
k
=
1
K
r
k
(
1
−
∑
i
=
1
M
p
(
w
i
∣
z
k
)
)
+
∑
j
=
1
N
ρ
j
(
1
−
∑
k
=
1
K
p
(
z
k
∣
d
j
)
)
J = Q + \sum_{k = 1}^K r_k(1 - \sum_{i = 1}^M p(w_i | z_k)) + \sum_{j = 1}^N\rho_j(1 - \sum_{k = 1}^K p(z_k | d_j))
J=Q+k=1∑Krk(1−i=1∑Mp(wi∣zk))+j=1∑Nρj(1−k=1∑Kp(zk∣dj))
∂
J
∂
p
∗
(
w
i
∣
z
k
)
=
∑
j
=
1
N
n
(
w
i
,
d
j
)
p
(
z
k
∣
w
i
,
d
j
)
p
(
w
i
∣
z
k
)
−
r
k
=
0
\frac{\partial J}{\partial p^*(w_i | z_k)} = \sum_{j = 1}^N \frac{n(w_i, d_j) p(z_k | w_i, d_j)}{p(w_i | z_k)} - r_k = 0
∂p∗(wi∣zk)∂J=j=1∑Np(wi∣zk)n(wi,dj)p(zk∣wi,dj)−rk=0
因此
r
k
p
∗
(
w
i
∣
z
k
)
=
∑
j
=
1
N
n
(
w
i
,
d
j
)
p
(
z
k
∣
w
i
,
d
j
)
r_k p^*(w_i | z_k) = \sum_{j = 1}^N n(w_i, d_j) p(z_k | w_i, d_j)
rkp∗(wi∣zk)=j=1∑Nn(wi,dj)p(zk∣wi,dj)
对
i
i
i求和,就有
r
k
=
∑
i
=
1
M
∑
j
=
1
N
n
(
w
i
,
d
j
)
p
(
z
k
∣
w
i
,
d
j
)
r_k = \sum_{i = 1}^M \sum_{j = 1}^N n(w_i, d_j) p(z_k | w_i, d_j)
rk=i=1∑Mj=1∑Nn(wi,dj)p(zk∣wi,dj)
p
∗
(
w
i
∣
z
k
)
=
∑
j
=
1
N
n
(
w
i
,
d
j
)
p
(
z
k
∣
w
i
,
d
j
)
∑
i
=
1
M
∑
j
=
1
N
n
(
w
i
,
d
j
)
p
(
z
k
∣
w
i
,
d
j
)
(
2
)
p^*(w_i | z_k) = \frac{\sum_{j = 1}^N n(w_i, d_j) p(z_k | w_i, d_j)}{\sum_{i = 1}^M \sum_{j = 1}^N n(w_i, d_j) p(z_k | w_i, d_j)} \qquad (2)
p∗(wi∣zk)=∑i=1M∑j=1Nn(wi,dj)p(zk∣wi,dj)∑j=1Nn(wi,dj)p(zk∣wi,dj)(2)
同理
p
∗
(
z
k
∣
d
j
)
=
∑
j
=
1
N
n
(
w
i
,
d
j
)
p
(
z
k
∣
w
i
,
d
j
)
∑
i
=
1
M
n
(
w
i
,
d
j
)
(
3
)
p^*(z_k | d_j) = \frac{\sum_{j = 1}^N n(w_i, d_j) p(z_k | w_i, d_j)}{\sum_{i = 1}^M n(w_i, d_j)} \qquad (3)
p∗(zk∣dj)=∑i=1Mn(wi,dj)∑j=1Nn(wi,dj)p(zk∣wi,dj)(3)
( 1 ) ( 2 ) ( 3 ) (1)(2)(3) (1)(2)(3)三式共同构成PLSA算法的迭代公式。
二、算法实现
用python实现PLSA算法。首先对数据集先做预处理。对给定的文本进行分词,利用wordnet语料库将同义词进行替换(例如单复数不同的词需要替换成同一个词),并将停用词排除(停用词表在网上下载,参见作业中的stopwords.dic文件)。然后对全体文本构成的单词集合进行词频统计,构建词频矩阵
n
(
w
i
,
d
j
)
n(w_i, d_j)
n(wi,dj)。这一部分用到了python的nltk包。核心代码如下。
words = set()
word_counts = []
for document in documents:
seglist = word_tokenize(document)
wordlist = []
for word in seglist:
synsets = wordnet.synsets(word)
if synsets:
syn_word = synsets[0].lemmas()[0].name()
if syn_word not in stopwords:
wordlist.append(syn_word)
else:
if word not in stopwords:
wordlist.append(word)
words = words.union(wordlist)
word_counts.append(Counter(wordlist))
word2id = {words:id for id, words in enumerate(words)}
id2word = dict(enumerate(words))
N = len(documents) # number of documents
M = len(words) # number of words
X = np.zeros((N, M))
for i in range(N):
for keys in word_counts[i]:
X[i, word2id[keys]] = word_counts[i][keys]
然后根据 ( 1 ) ( 2 ) ( 3 ) (1)(2)(3) (1)(2)(3)三式进行PLSA算法的编写。注意到这三个式子都可以写成矩阵的形式,提高运算效率。同时注意到这三个式子都和分子成正比,因此可以计算出份子再除以归一化常数即可。E-step的代码如下。
def E_step(lam, theta):
# lam: N * K, theta: K * M, p = K * N * M
N = lam.shape[0]
M = theta.shape[1]
lam_reshaped = np.tile(lam, (M, 1, 1)).transpose((2,1,0)) # K * N * M
theta_reshaped = np.tile(theta, (N, 1, 1)).transpose((1,0,2)) # K * N * M
temp = lam @ theta
p = lam_reshaped * theta_reshaped / temp
return p
M-step的代码如下。
def M_step(p, X):
# p: K * N * M, X: N * M, lam: N * K, theta: K * M
# update lam
lam = np.sum(p * X, axis=2) # K * N
lam = lam / np.sum(lam, axis=0) # normalization for each column
lam = lam.transpose((1,0)) # N * K
# update theta
theta = np.sum(p * X, axis=1) # K * M
theta = theta / np.sum(theta, axis=1)[:, np.newaxis] # normalization for each row
return lam, theta
计算对数似然的代码如下。
def LogLikelihood(p, X, lam, theta):
# p: K * N * M, X: N * M, lam: N * K, theta: K * M
res = np.sum(X * np.log(lam @ theta)) # N * M
return res
用随机数初始化 Θ , Λ \Theta,\Lambda Θ,Λ以避免落入局部最优。设定最大迭代次数为200。对数似然的阈值为10。当相邻两次对数似然的差小于阈值或者达到最大迭代次数时停止迭代。如果计算对数似然时报错,说明某个参数被舍入到0,此时也需要停止迭代。
三、结果分析
由于笔记本电脑的内存有限,从所给数据集中随机抽取1000篇文本进行实验。设定主题数为4。某次实验的结果如下。构建的字典中包含11342个单词。字典保存在dictionary.json文件中。
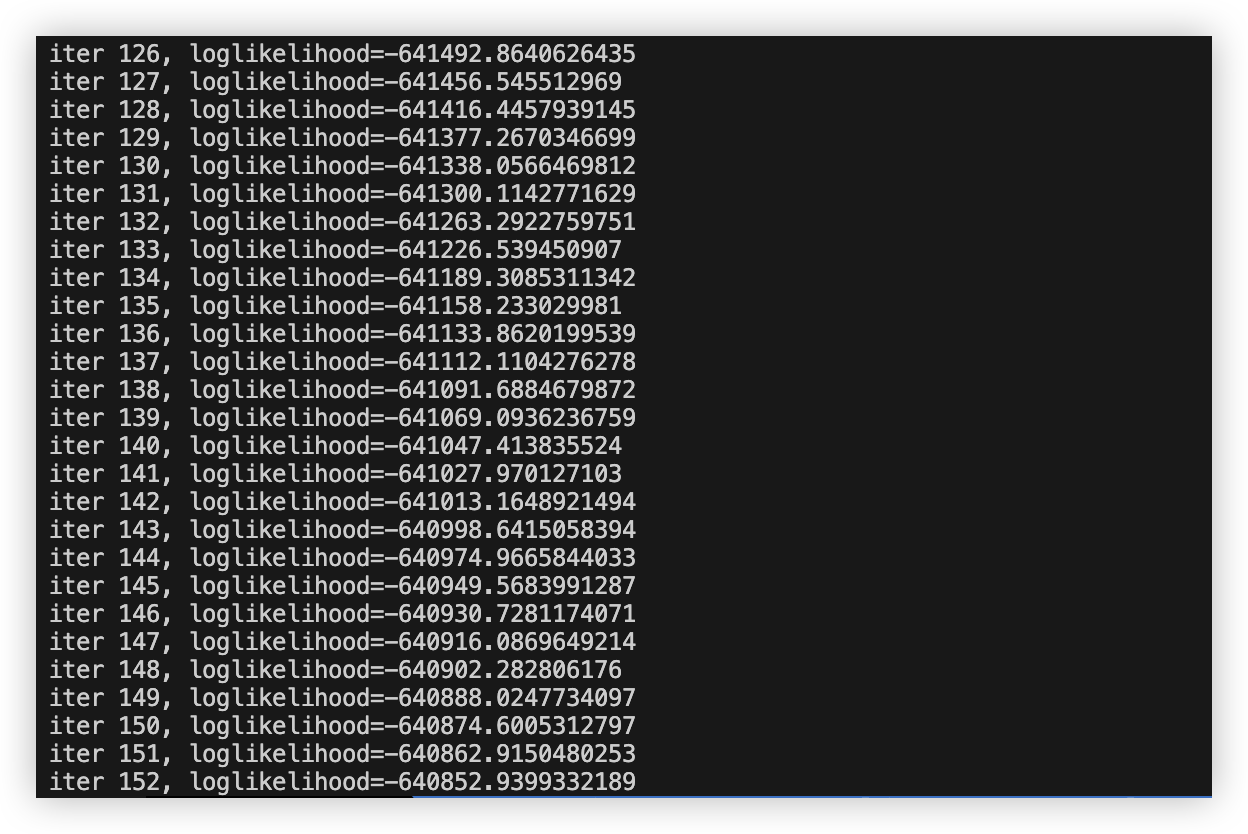
程序在迭代152次后停止。可以看到对数似然确实在不断上升。
每个文本的主题分布保存在DocTopicDistribution.csv文件中。每个主题的单词分布保存在TopicWordDistribution.csv文件中。每个主题中出现概率最高的9个单词保存在topics.txt文件中,如下图所示。可以看到出现概率最高的单词分别为astatine, network, Associate_in_Nursing, algorithm,分别对应了物理学、计算机科学、统计学、数学四个领域。这证明了PLSA方法的有效性。

项目开源
本项目开源在kungfu-crab/PLSA: A python implementation for PLSA(Probabilistic Latent Semantic Analysis) using EM algorithm. (github.com),仅作为学习交流使用,禁止转载与抄袭。
参考文献
[1] Hofmann, T. (1999). Probabilistic Latent Semantic Analysis. In Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence (pp. 289-296). Morgan Kaufmann Publishers Inc.

















 224
224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









