








原文信息
Sharma, Nikhilesh, Nicholas Mastronarde, and Jacob Chakareski. “Delay-sensitive energy-harvesting wireless sensors: Optimal scheduling, structural properties, and approximation analysis.” IEEE Transactions on Communications 68.4 (2019): 2509-2524.
关键字:马尔可夫决策过程、能量收集、延迟敏感无线传感、近似动态规划、结构特性
1 问题背景
能量受限 (energy-constrained) 的无线传感器通常运行在动态信道 (dynamic channel) 和对数据传输延迟非常敏感的环境中。这种传感器具备能量收集能力,能利用环境中的能量(例如环境光或射频能量)维持自身能量所需。这种新兴应用的成功关键在于及时传输采集的数据,而成功部署此类系统的关键是理解此类系统在不同运行条件下的基本性能极限,以及有效计算达到该极限的最佳策略。
文章考虑一个在衰落信道上传输延迟敏感数据的能量收集传感器 (energy-harvesting sensor, EHS),并将其构建为延迟敏感能量收集调度 (delay-sensitive energy harvesting scheduling, DSEHS) 问题。尽管EHSs可以在不更换电池的情况下自主运行,但能量收集源中的流量负载、能量收集和信道变化随机性对传感器功率管理、传输功率分配和传输调度提出了新的挑战。截止原文发表,许多研究确定了多种计算最优策略的方法,但它们并没有提供对其结构性质的一般性见解。本文作者在文章中将 DSEHS 问题构建为一个马尔可夫决策过程 (Markov Decision Process, MDP),并分析了其性质,在此基础上量化了在给定能量收集的情况下最小化队列延迟的最优调度策略的长期性能,并提出一种低复杂度的近似值迭代算法来计算近似最优策略,其在近似精度、计算复杂度和内存之间提供了一种可控的权衡。具体而言,文章探讨了以下问题:
- 如何建模时延敏感的能量收集调度问题 (DSEHS) ?
- 最优价值函数关于状态是否有良好的结构性质?(最优价值函数即最优策略下使得目标函数能取得的最小值)
- 如何设计近似值迭代算法?
- 近似值迭代算法的有效性如何?
2 无线传感器模型
考虑一种在衰落信道上传输延迟敏感数据的时隙单输入单输出能量收集传感器,系统模型如图1所示。该系统包括两个缓冲区:大小为 N b N_b Nb的数据包缓冲区和大小为 N e N_e Ne的能量缓冲区(电池)。
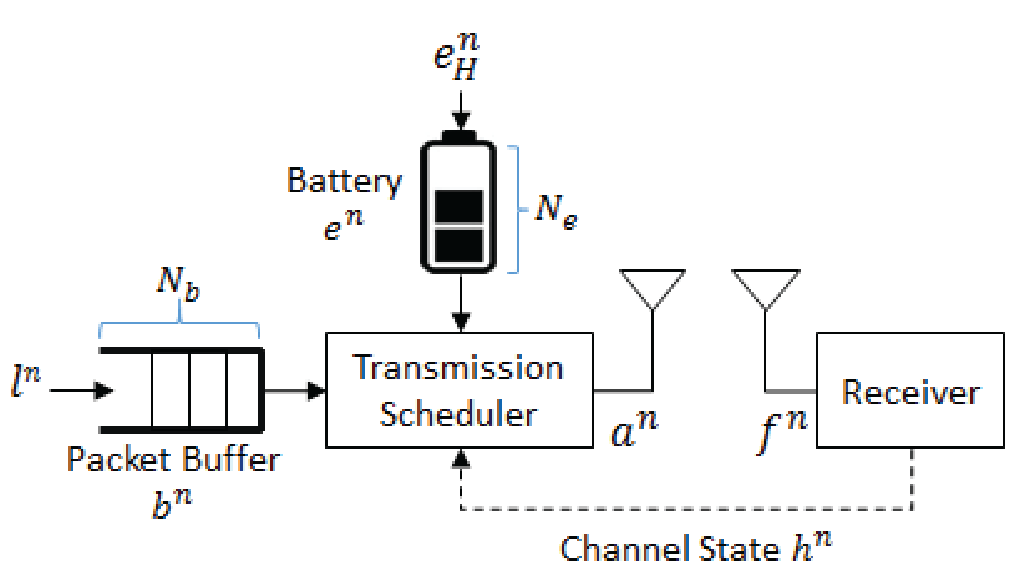
图1:能量收集无线传感器模型
假设时间被划分为长度为 Δ T ( s ) \Delta T(s) ΔT(s)的时隙,系统在第 n n n个时隙的状态表示为 s n = ( b n , e n , h n ) ∈ S s^n=(b^n,e^n,h^n)\in \mathcal{S} sn=(bn,en,hn)∈S, 其中 b n b^n bn为数据包缓冲状态(即积压的数据包数量), e n e^n en为电池状态(即可用能量包数), h n h^n hn为信道衰落状态。在第 n n n个时隙开始时,传输调度器观察系统状态 s n s^n sn,并采取调度动作 a n a^n an.
信道模型 P h ( h ′ ∣ h ) P^h(h'|h) Ph(h′∣h):假设信道是一个块衰落信道,在每个时隙内信道是恒定的,但在不同时隙之间信道可能发生变化。假设发射机在每个时隙开始时就已知信道状态 h n h^n hn,因此信道状态变化可以建模为具有转移概率函数 P h ( h ′ ∣ h ) P^h(h'|h) Ph(h′∣h)的马尔可夫链。
物理层模型 P TX n = P TX ( h n , a n ; B E P t a r g e t ) P_{\text{TX}}^n=P_{\text{TX}}(h^n,a^n;BEP_{target}) PTXn=PTX(hn,an;BEPtarget),其中为所有传输设置一个目标比特错误概率(bit error probability, BEP). 假设给定信道状态和目标BEP,发射功率是调度动作 a n a^n an的非减函数。
能量收集模型: e n + 1 = min ( e n − e TX n + e H n , N e ) e^{n+1}=\min(e^n-e_{\text {TX}}^n+e^n_{H},N_e) en+1=min(en−eTXn+eHn,Ne),其中 e h n e^n_h ehn表示第 n n n个时隙可收集的能量包数量,在第 n n n个时隙到达的能量包可以用于未来的时隙, e T X n = e T X ( h n , a n ; B E P t a r g e t ) e^n_{TX}= e_{TX}(h^n, a^n;BEP_{target}) eTXn=eTX(hn,an;BEPtarget)表示在时隙 n n n消耗的能量包数,并假设传输能量 e T X n e^n_{TX} eTXn是能量包的整数倍。
流量模型 b n + 1 = min ( b n − f n + l n , N b ) b^{n+1}=\min(b^n-f^n+l^n,N_b) bn+1=min(bn−fn+ln,Nb),其中 I n I^n In表示传感器在第 n n n个时隙中产生的数据包数量, f n = f ( a n ; B E P t a r g e t ) f^n = f(a^n;BEP_{target}) fn=f(an;BEPtarget)为 n n n个时隙中成功发送 (goodput) 的数据量。需要注意的是,新到的数据和未成功接收的数据必须在未来的一个时隙中重新发送。
3 延迟敏感能量收集调度问题
DSEHS 问题的目标是在给定可用能量的情况下,确定使平均分组排队延迟最小化的最优策略 π ∗ \pi^* π∗, 但这并不意味着只要有足够的能量,该策略就会无限地地发送分组——相反,避免在坏信道状态下发送分组,系统倾向于等待在好的信道状态下发送分组,以节省有限的能量收集。另一方面,如果电池 (几乎) 满了,通过传输数据包来消耗能量将为更多收集的能量腾出空间,否则这些能量将因电池大小有限而丢失。
问题表述
现定义一个缓冲区成本来量化大的队列积压。形式上,将缓冲区成本 (buffer cost) 定义为数据队列的积压长度和数据溢出成本之和
c ( [ b , h ] , a ) = b + E f , l [ η max { b − f + l − N b , 0 } ] , c([b,h],a)=b+\mathbb{E}_{f,l}[\eta\max\{b-f+l-N_b,0\}], c([b,h],a)=b+Ef,l[ηmax{
b−f+l−Nb,0}],
值函数 V π ( s ) V^π (s) Vπ(s)
V π ( s ) = E [ ∑ n = 0 ∞
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









