







机器学习竞赛----初见竞赛
各行各业典型应用场景和数据催生算法解决方案,进行算法研究,竞赛促使初学者得到实战锻炼,机器学习在大多数时候就只是在做数学统计,数据相关的特征工程直接决定了模型的上限,而算法只是不断地去逼近这个上限而已
国内外知名ML算法竞赛平台
1.Kaggle
网站直达链接: link
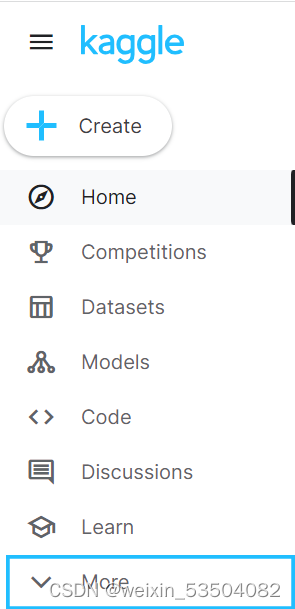
Competitions罗列了历史上所有的竞赛,最上面部分是正在进行的竞赛,点击一个newer的比赛,比如泰坦尼克号的,如下:
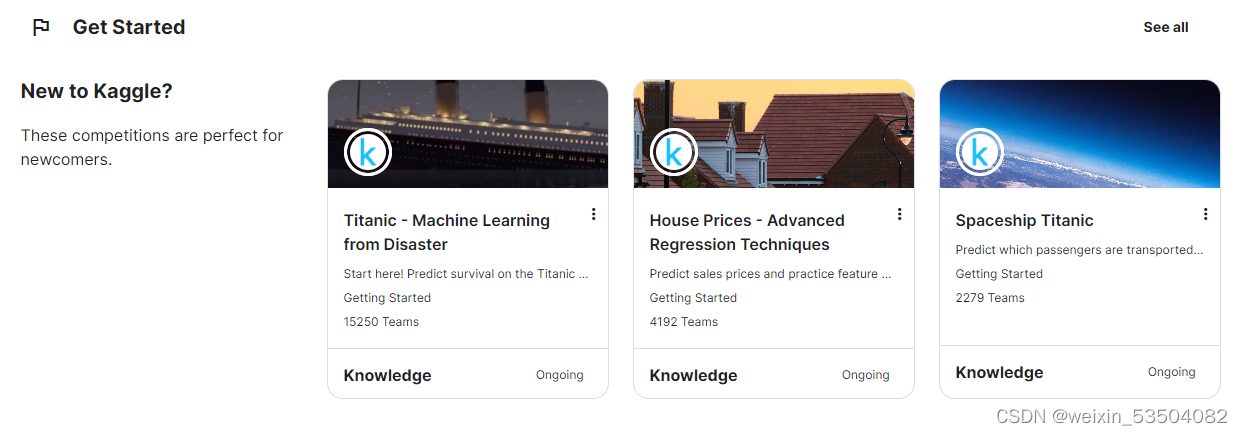 或者搜索一个Microsoft Malware Prediction的比赛,进入比赛后,可以看到有六个菜单栏
或者搜索一个Microsoft Malware Prediction的比赛,进入比赛后,可以看到有六个菜单栏
Overview:赛事的概况,包含描述,评分,奖项,时间轴四项
Description(描述):
The malware industry continues to be a well-organized, well-funded market dedicated to evading traditional security measures. Once a computer is infected by malware, criminals can hurt consumers and enterprises in many ways.
With more than one billion enterprise and consumer customers, Microsoft takes this problem very seriously and is deeply invested in improving security.
As one part of their overall strategy for doing so, Microsoft is challenging the data science community to develop techniques to predict if a machine will soon be hit with malware. As with their previous, Malware Challenge (2015), Microsoft is providing Kagglers with an unprecedented malware dataset to encourage open-source progress on effective techniques for predicting malware occurrences.
Can you help protect more than one billion machines from damage BEFORE it happens?
Evaluation(评分):
Submissions are evaluated on area under the ROC curve between the predicted probability and the observed label.
Prizes(奖项):
列出来奖金和注意(reminder)
Timeline(时间轴):
组队截止时间和提交截止时间要注意
Data
数据格式:csv宽表
单独的Dataset Description:
1.采集来源:不同的采样方式:是否会对正样本进行升采样
2.任务说明
3.字段含义
时间序列预测注记
重中之重:熟悉题目与数据,关注细节信息
Code
开源融合的思考:
various数据探索,特征工程,建模方法,代码风格,学习各种工具和代码写法,寻找优雅,简洁,快速的实现,同时将各种建模方法融合, 博采众长
Discussion
QA以及对比赛的理解和发现,讨论交流竞赛的心得,对理论方法的探索和验证;
对理论的探索和验证
Leaderboard
A榜和B榜:(建模的泛化性)模型泛化性能的评估,在未来的预测中保持良好的效果
防止:炼丹练得过拟合;
解释:机器学习算法过拟合的原因以及改进方案—理论的证明和实践的检验
Rules
更多的一些详细的规则
2.阿里天池
网站直达链接: link
面向社会开放高质量脱敏数据集和计算资源
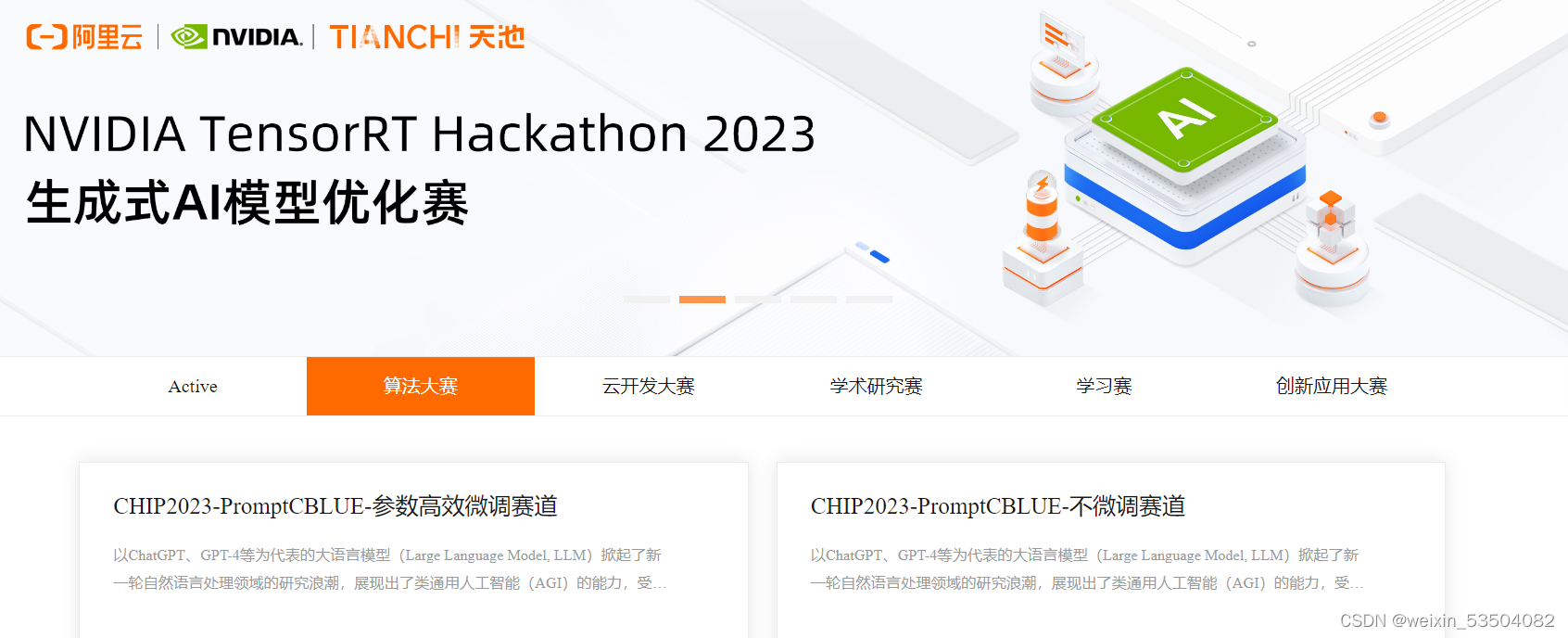
随意选择一个比赛进入:可以看到左侧也有多个菜单栏(报名前只有前面四个)

和上面的kaggle十分类似,不再详述界面内容
注意模型不要过拟合
3.DataFountain
网站直达链接: link
按照技术(数据挖掘,NLP,CV)和行业(金融,医疗,交通…)
对竞赛进行划分,将工业界和学术界联系紧密
对行业的细分理解和落地场景的多样化
4.DataCastle
网站直达链接: link
政企办赛
5.和鲸社区
网站直达链接: link
在线的notebook训练环境:部分要付费
吴恩达老师的机器学习深度学习,台大李宏毅老师的机器学习,李沐老师动手学深度学习,以及斯坦福cs231n的课程实践作业,十分推荐
6.JDATA
京东的,似乎有点难,感兴趣的家人可以自行google一下吧
特点:
1.自定义评价指标
2.拿到csv宽表数据后要仔细考虑建模方案:
自己搭建训练集和测试集;选择什么作为样本标签都需要我们自行考虑
其它网站:
https://www.flyai.com/
https://www.biendata.com/
https://www.biendata.xyz/
https://cocodataset.org/#home
http://challenge.xfyun.cn/
竞赛流程
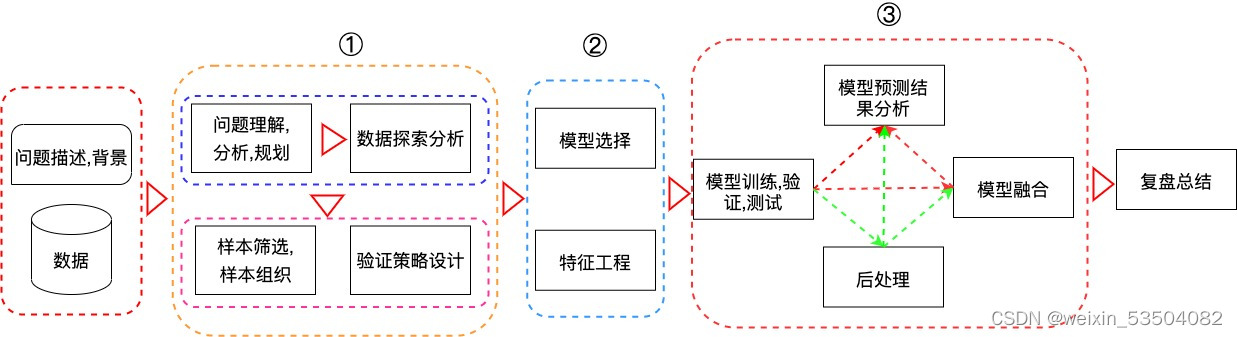
机器学习竞赛套路:
问题建模–>数据探索–>特征工程–>模型训练–>模型融合
问题建模:审题,十分重要
注记:不是所有的数据都是特征加标签这种结构化的数据看可以直接加入模型的训练,很多时候还要分析数据进而抽象出建模的目标与方案,问题建模水平十分重要,问题建模方式的选取几乎决定了此类比赛的成败;依据对赛题的理解和不一般的评价指标和方式来思考
数据探索:辅助理解问题建模,为特征工程做前期准备
探索性数据分析(EDA):在理解赛题并且大致知道了问题建模的方式之后,结合赛题的业务背景进行EDA,对数据进行清晰的认识:
1.数据长啥样
2.数据是否和描述相符
3.数据的来源,分布
4.数据包含的信息
5.数据的质量
6.csv文件宽表各个字段的含义,范围和组织方式/数据结构
以上都是需要进行考察的对象;
然后进一步要考察
1.结合标签分析特征的分布状态
2.traing_set和test_set的同分布情况
3.特征直接的业务关联以及隐含信息的表征
特征工程:
是花费时间最多的模块,机器学习在大多数时候就只是在做数学统计,数据相关的特征工程直接决定了模型的上限,而算法只是不断地去逼近这个上限而已
模型训练:计算资源的极度依赖
根据问题建立好模型方案–>根据业务理解进行数据探索–>逐步完善特征工程------>得到标准的训练集和测试集–>加入模型训练:
模型训练模块组成:选择合适的模型+超参数调优【调优技巧在比赛上是要关注的】
机器学习模型:梯度提升(GDBT)树模型XGBoost,LightGBM;SVM,LR,RF
深度学习模型:DNN,CNN,RNN及其衍生模型
模型融合:寻觅队友
不同参赛者在问题建模(思路,思考范式),数据探索,特征工程,模型训练都会有很大差异,这就导致不同参赛者之间会有巨大的差异,但差异越大,模型融合效果却是极佳的;故而在项目的后期,可以多和社区的小伙伴们交流和组队
每一种算法都有自身的优势和局限性,我们要综合各个算法的优势
模型融合的方式:
1.Stacking
2.加权投票
对于深度学习方面(cv方向)的模型集成:
》测试阶段的模型集成:
对测试数据做数据增强后得到不同图像,将得到的不同的图像都做正向传播做预测结果,在做加权平均(预测时间会成倍增加)
》多个模型(参数)的集成:
保留在训练过程中多个epoch的权重(精度较好的),一般需要采用余弦退火的学习率跳出局部最优,得到多个局部最优模型(参数不同的意义上)
做k折交叉验证,得到k个模型(也是参数意义上)
注记:对于已经有测试集的,可以将预测置信度大的做伪标签,将测试集中一些样本(置信度高的)和训练集绑在一起进行二次训练
竞赛类型
不同机器学习算法适用于不同的场景和业务需求,各行各业衍生出对AI的不同需求
根据数据类型划分:
1.机器学习/数据挖掘方向:结构化数据/宽表数据
唯一id,特征:
类别特征:离散&&数值特征:连续;有单值特征,还有多值特征
多值特征:是比较特殊的,可能不同id同一多值特征的属性会有不同个数的被包含,
关注:特别的处理技巧
2.计算机视觉方向:图片,视频数据
3.自然语言处理:文本,各种语言的分词,序列
任务类型
分类+回归(主要讨论:based on 有监督学习的机器学习算法)
应用场景
机器学习在各个行业的应用,行业的需求和痛点
AI涉足较多的场景,用户数据的丰富性和多样性
小结与思考
1.完整的机器学习算法竞赛包括哪些流程,每个部分在流程中充当什么样的角色?
问题定义和理解:
在这个阶段,你需要清楚地定义竞赛的问题是什么,并确保你对问题有深刻的理解。这包括确定问题的类型(分类、回归、聚类等),理解输入数据和目标变量,以及评估指标(如精度、F1分数、均方误差等)的选择。你需要明确问题的背景、目标和约束。
数据获取与探索:
在这个阶段,你需要获取竞赛所提供的训练数据和测试数据。然后,你会对数据进行初步的探索性数据分析(EDA),以了解数据的特征、分布、缺失值等情况。这有助于你建立对数据的直觉,并可能启发特征工程的想法。
数据预处理和特征工程:
在这一步中,你会对数据进行清洗、处理缺失值、处理异常值,并进行特征工程,以提取出更有用的特征。特征工程可以包括特征选择、特征变换、生成新的特征等。一个好的特征工程过程可以显著提升模型的性能。
模型选择和训练:
在这个阶段,你需要选择合适的机器学习算法或模型架构,并使用训练数据对模型进行训练。你可以尝试多种模型,并调整它们的超参数以达到更好的性能。交叉验证和模型选择技巧有助于避免过拟合并选择最佳模型。
模型调优:
一旦你训练出一个基本的模型,接下来就是对模型进行调优。这可能涉及到超参数调整、模型集成(如堆叠、投票、融合等)以及针对特定模型的优化策略。目标是进一步提升模型的性能。
模型验证和评估:
使用验证集或交叉验证来评估你的模型在未见过的数据上的性能。这可以帮助你了解模型的泛化能力以及是否需要进一步改进。
提交和测试:
一旦你对模型满意,你可以将其应用于竞赛的测试数据,并生成预测结果。然后将预测结果提交给竞赛平台进行评估。
反馈和迭代:
根据竞赛结果,你可以得到模型在测试集上的表现。根据这些结果,你可以进一步调整模型、特征工程方法等,然后重新训练和验证,以实现更好的性能。这个迭代过程可能会进行多次,以逐步改进你的模型。
2.以日常生活接触到的场景为例,列举一些可能使用机器学习算法的应用?
社交媒体推荐系统:
社交媒体平台使用机器学习算法来分析用户的行为、兴趣和互动,以推荐他们可能感兴趣的内容,如帖子、视频、广告等。这种个性化推荐系统可以提高用户满意度,增加平台的活跃度。
语音助手和语音识别:
语音助手(如Siri、Alexa、Google Assistant)使用机器学习算法来识别和理解用户的语音指令,并回应相应的操作。语音识别技术可以在手机、智能音箱和汽车等设备中实现,使人机交互更加便捷。
金融欺诈检测:
银行和金融机构利用机器学习算法来检测信用卡欺诈、网络钓鱼等金融欺诈行为。通过分析交易模式、用户行为等数据,算法能够快速识别异常活动并采取相应措施,保护用户的财产安全。
医疗诊断辅助:
在医疗领域,机器学习算法可以分析医学图像(如X射线、MRI、CT扫描)以辅助医生进行疾病诊断。算法可以帮助识别病灶、异常和模式,提高诊断的准确性。
智能家居控制:
智能家居系统利用机器学习算法来学习家庭成员的生活习惯和喜好,以自动化控制家居设备。例如,根据居住者的活动模式和时间表,智能家居可以自动调节温度、照明等,提供更加智能化的居住体验。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









