







目录
一.定义
系统聚类法(hierarchjcal cluster method)一译"分层聚类法"。聚类分析的一种方法。其做法是开始时把每个样品作为一类,然后把最靠近的样品(即距离最小的群品)首先聚为小类,再将已聚合的小类按其类间距离再合并,不断继续下去,最后把一切子类都聚合到一个大类。
注:类间距离与样品间距离
下面是我自己的理解:类可以由一个或多个样品组成,那么如果类仅由一个样品组成,类间距离与样品间距离相等;如果类由多个样品组成,那么就要定义类间距离了。主要的定义有以下几个:
1.最短距离法
2.最长距离法
3.组间平均连接法
4.组内平均连接法
5.重心法
6.可变平均法
7.离差平方和法
在这里(系统聚类法)计算类间距离时我们使用最短距离法: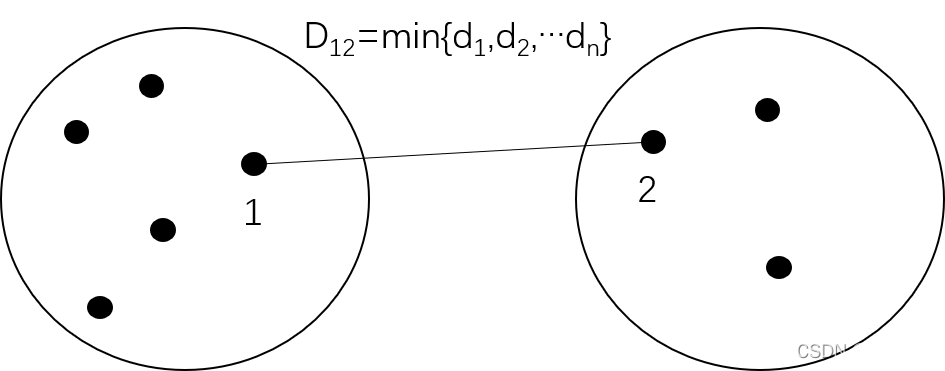
如图所示,左边一类中包含五个点,右边包含三个点,其中1点和2点之间的距离为所有点之间距离最小的,所以1点和2点之间的距离即为这两类的最短距离。
自然地,我们想到,如何计算1点与2点间距离呢?
这就是刚刚提到的样品间距离,最常用的定义即为欧氏距离(EuclideanDistance),源自欧氏空间中两点间的距离公式。
二维空间的欧氏距离公式
如:定义a=[1,5],b=[2,1],求解a与b向量之间的欧氏距离(使用matlab实现)
a=[1,5],b=[2,1];
c=[a;b];
pdist(c,'euclidean')三维空间的欧氏距离公式
n维欧氏空间是一个点集,它的每个点 X 可以表示为 (x[1]x[2]…x[n]),那么设点X1(x[1]x[2]…x[n])与点X2(y[1]y[2]…y[n])之间的距离可以表示为
二.思想
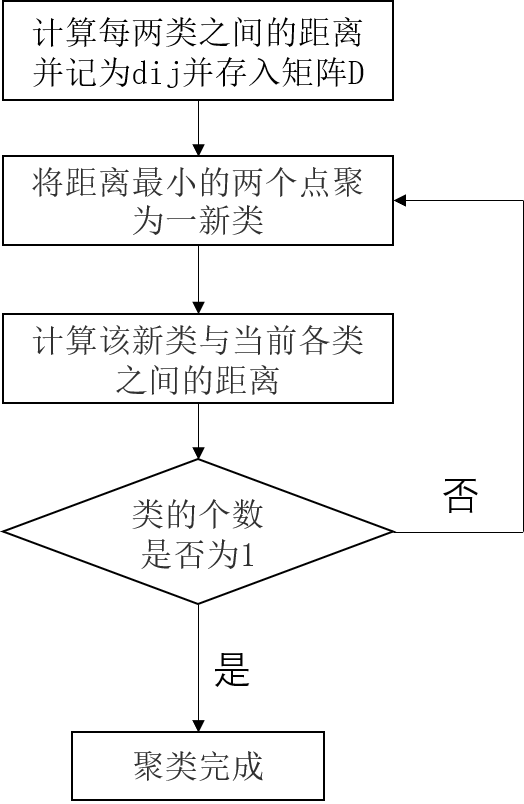
对于系统聚类的思想,我用流程图来表示:
设初始样本有n个,每个样本自成一类。
三.举例
设某地牛奶产量可用质量指标X来衡量,现有五瓶新鲜牛奶,X的值分别为1.5,2.5,5,6.5,8.5。请使用系统聚类法对五瓶牛奶进行分类。
解:设样品间距离使用欧氏距离,类间距离使用最短距离,并记样品分别为X1、X2、X3、X4、X5。
1)计算距离如表所示
| 类 | X1 | X2 | X3 | X4 | X5 |
| X1 | 0 | 1 | 3.5 | 5 | 7 |
| X2 | 0 | 2.5 | 4 | 6 | |
| X3 | 0 | 1.5 | 3.5 | ||
| X4 | 0 | 2 | |||
| X4 | 0 |
2)将X1与X2聚为一类,记为N1
| 类 | N1 | X3 | X4 | X5 |
| N1 | 0 | 2.5 | 4 | 6 |
| X3 | 0 | 1.5 | 2.5 | |
| X4 | 0 | 2 | ||
| X5 | 0 |
3)将X3与X4聚为一类,记为N2
| 类 | N1 | N2 | X5 |
| N1 | 0 | 2.5 | 6 |
| N2 | 0 | 2 | |
| X5 | 0 |
4)将N2与X5聚为一类,记为N3
| 类 | N1 | N3 |
| N1 | 0 | 2.5 |
| N3 | 0 |
5)将N1与N3聚为一类,结束
6)画出谱系结构图(此处自己处理数据并画图较为复杂,我们略去,下一部分使用Spss模拟并画图)
四.系统聚类法的Spss实现
1)数据的导入(此数据不具有实际意义仅为演示需要)
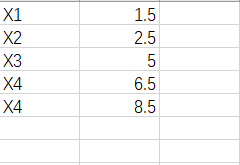
这是我们excel表里的数据,文件名为“milk.xlsx"
接着我们打开Spss24(版本过低可能有些功能无法实现)
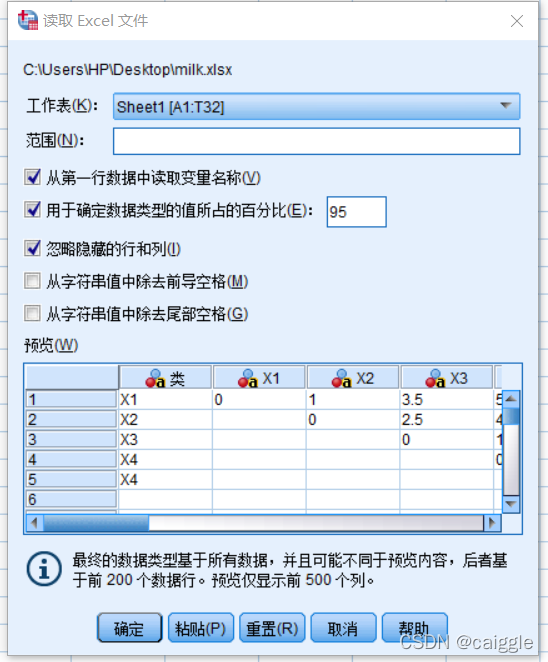
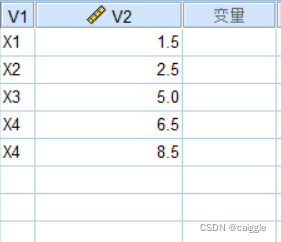
现在我们成功地导入了数据,可以进行下一步了。
2)可以开始聚类分析了
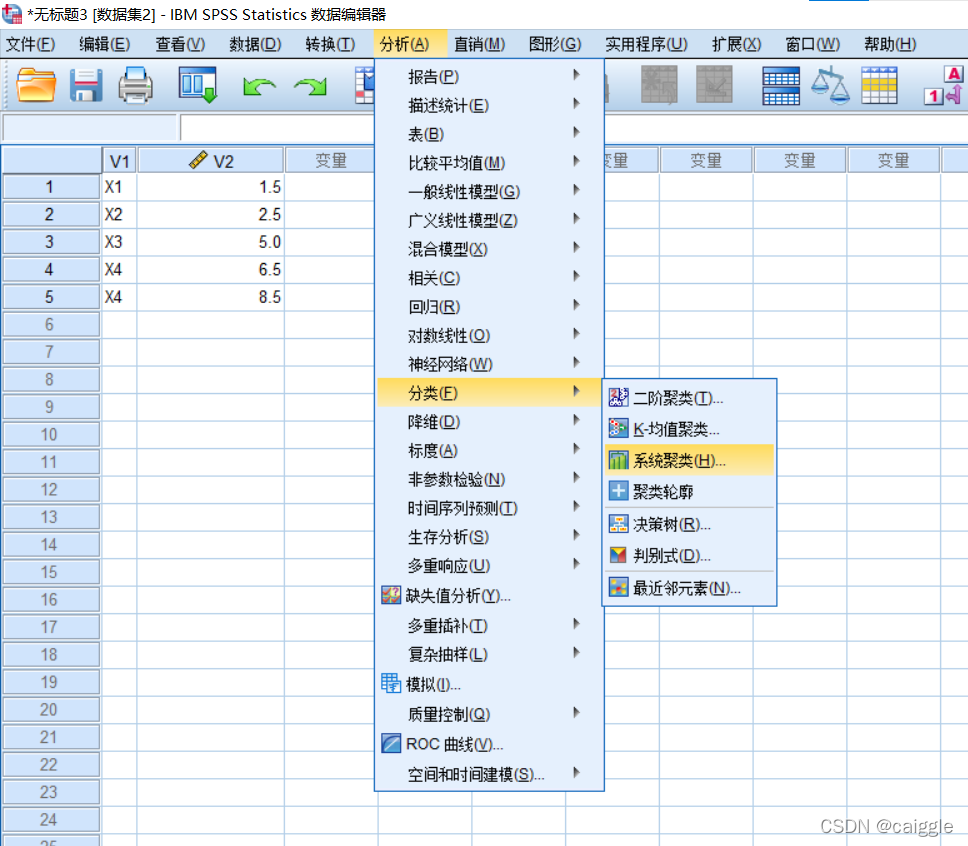
本处冒昧纠正一点小问题,Spss把我们的几种聚类设置在了分类栏目下,但实际上我们知道聚类和分类完全是两个不同的概念。
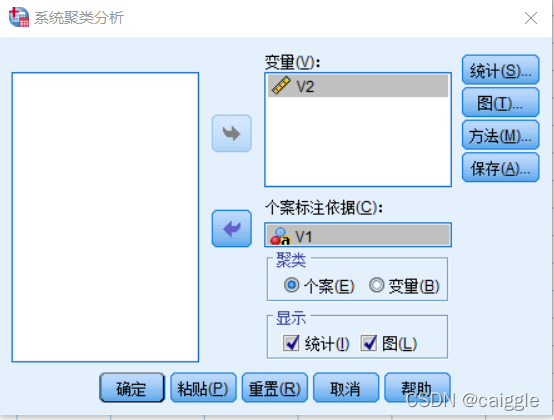
选择V2为变量,V1为个案标注依据。
在”图“地栏目下勾选“谱系图”
3)生成分析结果
| 个案处理摘要a,b | |||||
| 个案 | |||||
| 有效 | 缺失 | 总计 | |||
| 个案数 | 百分比 | 个案数 | 百分比 | 个案数 | 百分比 |
| 5 | 100.0 | 0 | .0 | 5 | 100.0 |
| a. 平方欧氏距离 使用中 |
| b. 平均联接(组间) |
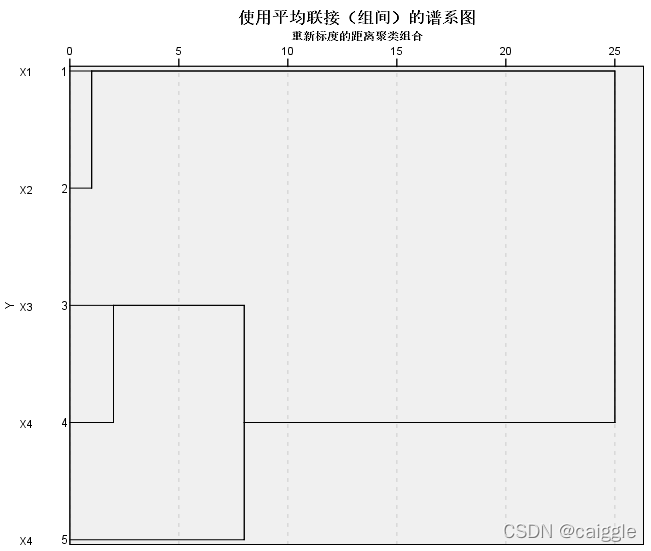
此处还默认生成垂直冰柱图,但一般情况下参考意义不大。
五.结语
到这里系统聚类法的分享就结束了。
祝:岁岁常欢愉。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











