







论文贡献:
这篇论文提出了一种新的深度估计方法,通过结合全局和局部视角的信息来逼近单张图像深度估计。该方法在NYU Depth和KITTI数据集上取得了最先进的性能,并且在评估方面取得了很好的结果。此外,该方法还具有可扩展性,可以在未来的工作中融合其他3D坐标信息,并将深度估计扩展到原始输入分辨率。因此,该论文在深度估计领域的研究和应用方面具有贡献。
Abstract
预测深度是理解场景三维几何形状的一个重要组成部分。对于立体图像的局部对应可以进行估计,但是要从单幅图像中找到深度关系就不那么容易了,需要综合来自各种线索的全局和局部信息。此外,这项任务本质上是模棱两可的,大量的不确定性来自整体规模。在本文中,我们提出了一种新的方法来解决这个问题,使用两个深层网络栈: 一个作出粗略的全局预测基于整个图像,另一个精化这个预测局部。我们还应用尺度不变误差来帮助测量深度关系,而不是尺度。通过利用原始数据集作为训练数据的大量来源,我们的方法在 NYU Depth 和 KITTI 上获得了最先进的结果,并且匹配了详细的深度边界,而不需要超像素化。
Introduction
估计深度是理解场景中几何关系的一个重要组成部分。反过来,这种关系有助于提供更丰富的对象及其环境的表示,通常导致现有识别任务的改进[18] ,以及许多进一步的应用,如3D 建模[16,6] ,物理和支持模型[18] ,机器人学[4,14] ,以及可能的闭塞推理。
虽然在基于立体图像或运动的深度估计方面有很多先前的工作[17] ,但从单幅图像估计深度的工作相对较少。然而,单目的案例经常出现在实践中: 潜在的应用程序包括更好地理解在网络和社会媒体渠道上分发的许多图像、房地产列表和购物网站。这些包括许多室内和室外场景的例子。
可能有几个原因,为什么单目的情况下还没有处理到与立体声一样的程度。提供准确的图像对应,在立体情况下可以确定地恢复深度[5]。因此,立体深度估计可以简化为开发鲁棒的图像点对应————这往往可以利用局部外观特征找到。相比之下,从单幅图像估计深度需要使用单目深度线索,如线角度和透视,物体大小,图像位置和大气效果。此外,场景的全局视图可能需要将这些有效地联系起来,而立体声的局部差异就足够了。
此外,这个任务本质上是模棱两可的,而且是一个技术上不适定的问题: 给定一个图像,可能有无数种可能的世界场景产生了它。当然,对于真实世界的空间来说,大多数情况在物理上是不可能的,因此深度仍然可以相当准确地预测。不过,至少还有一个主要的模糊之处: 全球规模。虽然数据中不存在极端情况(比如一个普通房间和一个玩偶之家) ,但是房间和家具尺寸存在中等程度的变化。除了更常见的尺度相关误差之外,我们还使用尺度不变误差来解决这个问题。这种方法将注意力集中在场景中的空间关系而不是一般的尺度上,特别适合于诸如3D 建模这样的应用,在后处理过程中模型经常被重新缩放。
本文提出了一种从单幅图像估计深度的新方法。我们使用一个包含两个部分的神经网络直接对深度进行回归: 一个部分首先估计场景的全局结构,然后第二个部分使用局部信息进行细化。网络训练使用的损失,明确说明了像素位置之间的深度关系,除了逐点误差。我们的系统实现了最先进的纽约大学深度和 KITTI 评估率,以及改进的定性输出。
2 Related Work
3 Approach
3.1 Model Architecture
我们的网络由两个组成部分组成,如图1所示。一个粗尺度的网络首先在全局水平上预测场景的深度。然后在局部地区通过一个精细的网络进行改进。这两个堆栈都应用于原始输入,但此外,粗网络的输出作为额外的第一层图像特征传递给细网络。通过这种方式,局域网络可以编辑全局预测,以纳入更细的尺度细节。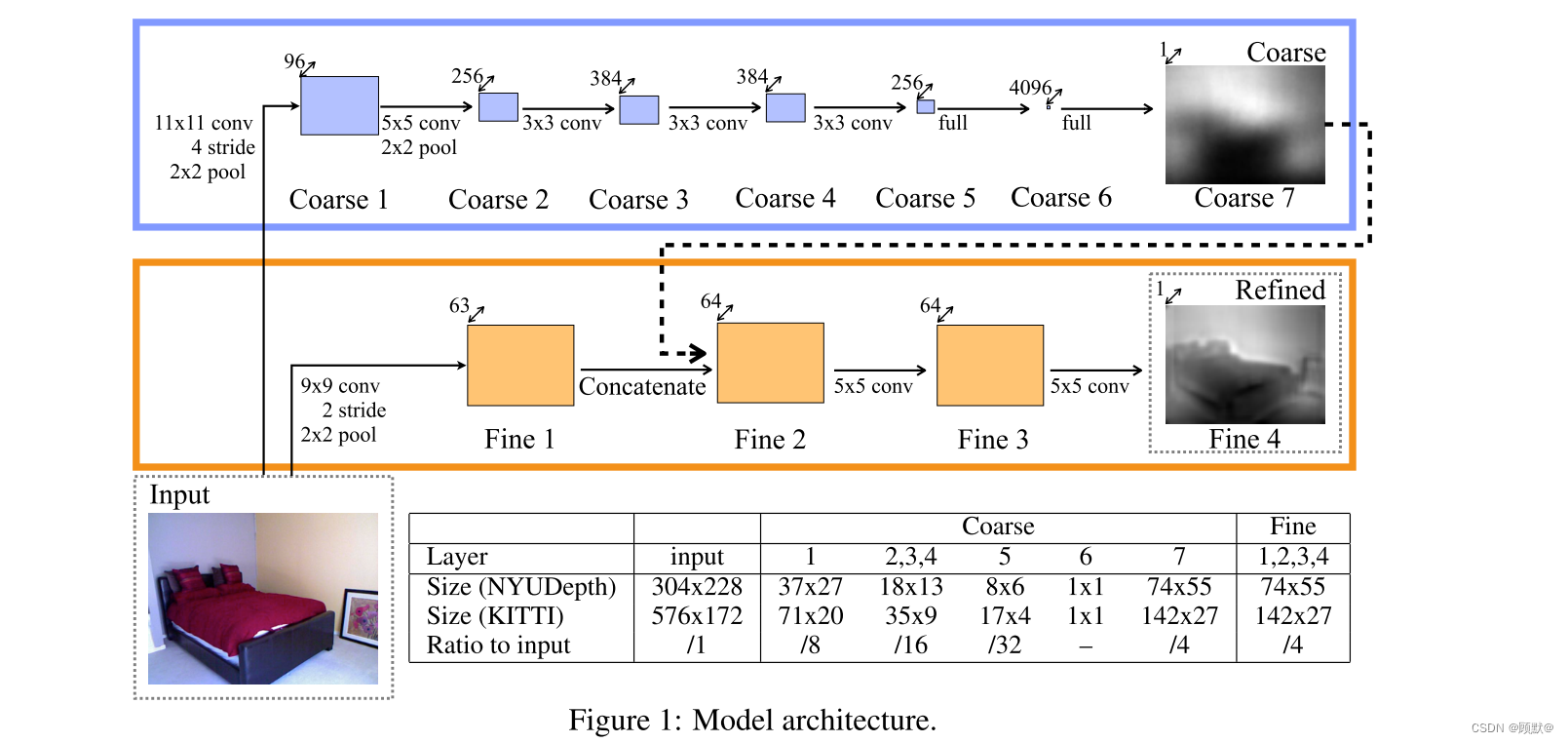
3.1.1 Global Coarse-Scale Network
粗比例网络的任务是利用场景的全局视图来预测整个深度图的结构。这个网络的上层是完全连接的,因此在他们的视野中包含整个图像。类似地,下层和中层被设计成通过最大池操作将来自图像不同部分的信息组合到一个小的空间维度。这样,网络就能够整合全球对全景的了解来预测深度。在单一图像情况下,需要这样的理解来有效地利用线索,如消失点、目标位置和房间对齐。局部视图(通常用于立体匹配)不足以注意到这些重要特征。
如图1所示,全局粗尺度网络包含五个特征提取层的卷积和最大池,其次是两个完全连接的层。输入、特征映射和输出尺寸也在图1中给出。与输入相比,最终输出的分辨率为1/4(其本身从原始数据集向下采样2倍) ,并且对应于包含大部分输入的中心作物(正如我们后面所描述的,由于第一层网络和图像转换,我们失去了一个小的边界区域)。
注意输出的空间维数大于最上面的卷积特征映射的空间维数。与其将输出限制在特征映射大小上,并在将预测传递到良好网络之前依赖于硬编码的上采样,我们允许顶层完整的层在更大的区域(NYU Depth 为74x55)学习模板。这些预计将是模糊的,但将更好的上采样输出的8x6预测(顶部功能地图大小) ; 本质上,我们允许网络学习自己的上采样基于功能。样品输出权重如图2所示
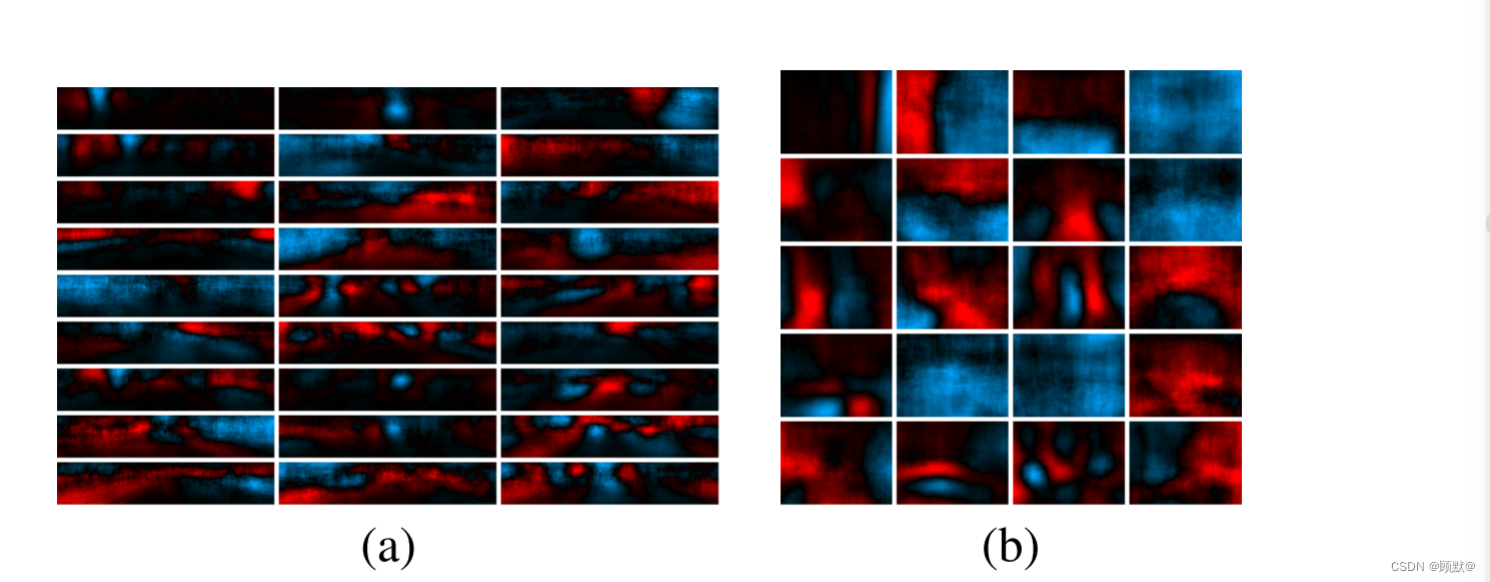
图2: (a) KITTI 和(b) NYUDepth 的粗7层(粗输出)的权重向量。红色是正数(更远) ,蓝色是负数(更近) ; 黑色是零。权重均匀选取,按照L2范数降序显示。KITTI 重量经常显示深度的变化,在道路的任何一边。NYUDepth 砝码通常显示墙的位置和门道。
除了粗输出层7是线性的外,所有隐藏层都使用整流的线性单位进行激活。退出应用于完全连接的隐藏层6。粗尺度网络的卷积层(1-5)在 ImageNet 分类任务中进行预训练[1]ーー在开发模型时,我们发现在 ImageNet 上进行预训练比随机初始化效果更好,尽管差异不是很大
3.1.2 local Fine-Scale Network
3.2 Scale-Invariant Error(尺度不变误差)
场景的全局尺度是深度预测中的一个基本模糊问题。**事实上,使用当前的元素度量方法产生的大部分误差可以简单地解释为平均深度预测得多好。**例如,在 NYUDepth 上进行培训的 Make3D 使用日志空间中的 RMSE 获得0.41错误(参见表1)。然而,**使用Oracle来用相应地面真值的平均值替代每个预测的平均对数深度则减少误差到0.33,20% 的相对改进。**同样,对于我们的系统,这些误差率分别为0.28和0.22。因此,只要找到场景的平均尺度就可以解释总误差的很大一部分。
基于此,我们使用一个尺度不变的误差来测量场景中各点之间的关系,而与绝对全局尺度无关。对于一个预测的深度映射 y 和地面真值 y * ,每一个都有 n 个像素被 i 索引,我们将尺度不变的均方差(在对数空间中)定义为
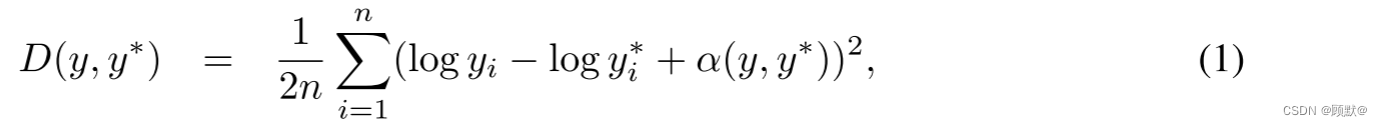
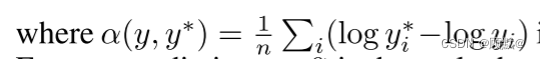
是使给定(y,y *)的误差最小的 α 值
对于任何预测 y 来说,e^α 是与地面真相最匹配的尺度。y的所有标量倍数都有相同的误差,因此就有了尺度不变性。
以下等效表单提供了查看此度量的另外两种方式。设置 di = log yi-log yi* 为像素点 i 的预测值和地面真值的差值,有:
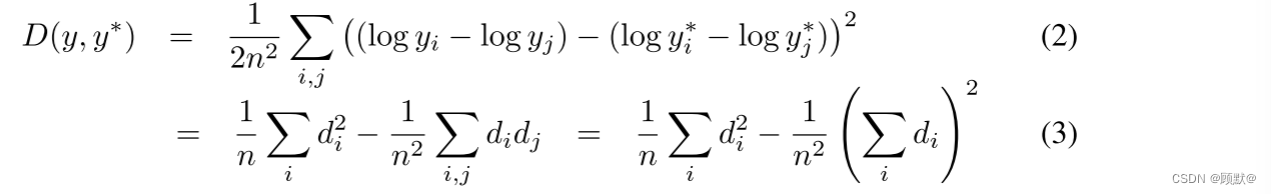
除了尺度不变误差之外,我们还根据以前的工作中提出的几个误差度量来度量我们的方法的性能,如第4节所述。
3.3 Training Loss
3.4 Data Augmentation
4 Experiments
6 Discussion
从单幅图像预测深度估计是一项具有挑战性的任务。然而,通过结合来自全局和局部视图的信息,它可以执行得相当好。我们的系统通过使用两个深度网络来实现这一点,一个用于估计全球深度结构,另一个用于在局部地区以更高的分辨率对其进行细化。通过有效地利用完整的原始数据分布,我们为 NYU Depth 和 KITTI 数据集实现了一个新的最先进的任务。
在未来的工作中,我们计划扩展我们的方法,以纳入进一步的三维几何信息,如表面法线。Fouhey 等人已经在法向地图预测方面取得了有希望的结果,并且将它们与深度地图结合起来可以提高整体性能[16]。我们还希望通过重复使用连续的更精细的局部网络,将深度映射扩展到完全原始的输入分辨率。















 3173
3173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









