







欢迎收藏Star我的Machine Learning Blog:https://github.com/purepisces/Wenqing-Machine_Learning_Blog。如果收藏star, 有问题可以随时与我交流, 谢谢大家!
逻辑回归概述
逻辑回归类似于线性回归,但预测的是某事物是否为真,而不是像大小这样的连续值。逻辑回归拟合的是“S”形的“逻辑函数”曲线,而不是一条直线。这个曲线从0到1,表示根据预测变量(例如体重),某个结果发生的概率(例如老鼠是否肥胖)。
逻辑回归的工作原理
- 重的老鼠:高概率肥胖。
- 中等体重的老鼠:50%概率肥胖。
- 轻的老鼠:低概率肥胖。
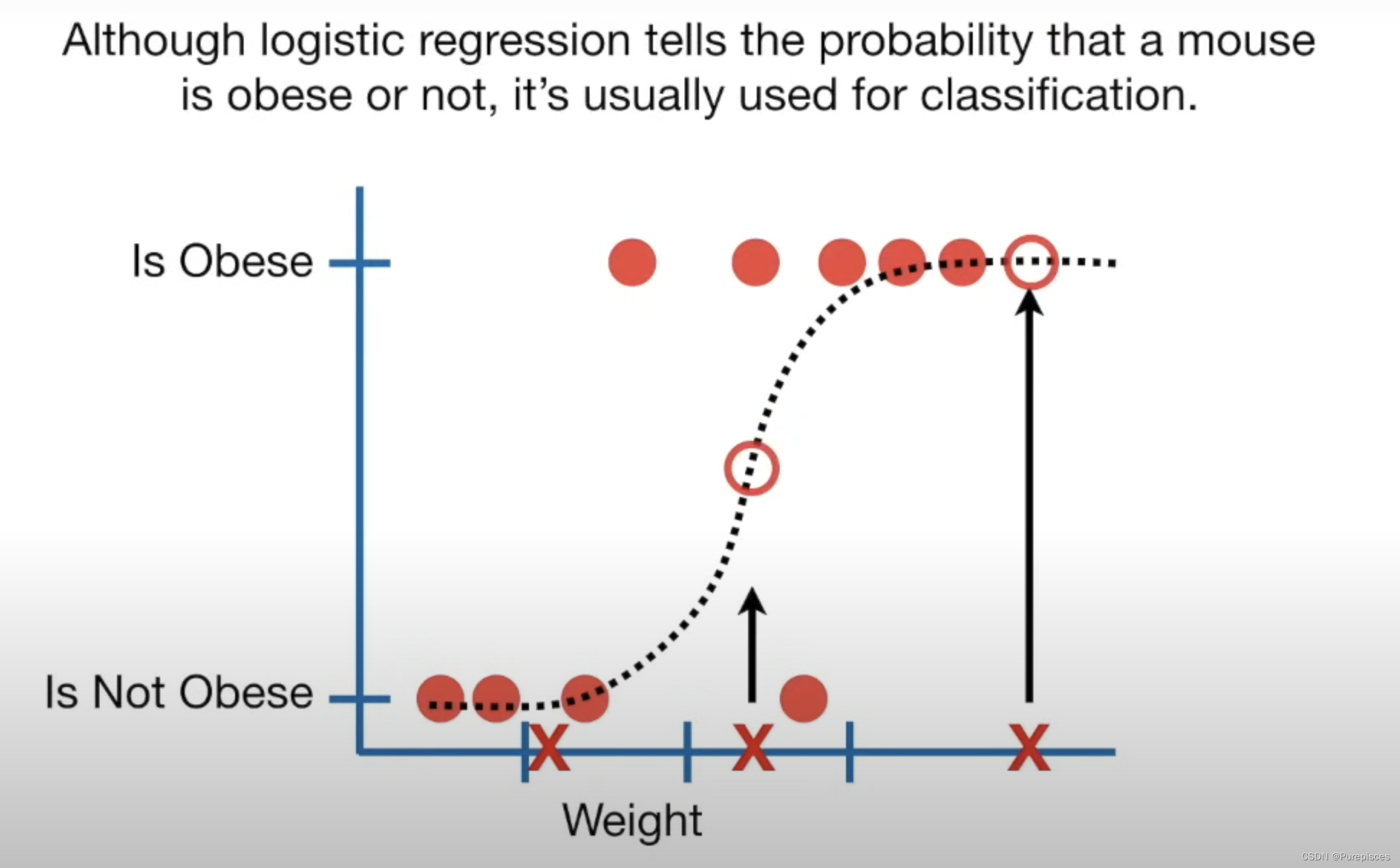
虽然逻辑回归给出了老鼠是否肥胖的概率,但它通常用于分类。例如,如果老鼠肥胖的概率大于50%,我们就将其分类为肥胖,否则分类为“不肥胖”。
逻辑回归中的预测变量
逻辑回归可以处理连续数据(如体重、年龄)和离散数据(如基因型、星座)。我们可以测试每个变量是否对预测肥胖有用。与普通回归不同,我们不能轻易地比较复杂模型和简单模型。相反,我们测试一个变量对预测的影响是否显著不同于0。如果不是,这意味着该变量对预测没有帮助。我们使用沃尔德检验来确定这一点。
例如,如果肥胖是由体重+基因型+年龄+星座预测的,而我们发现星座“完全无用”(统计术语表示“没有帮助”),我们可以从模型中排除它,以节省时间和资源。

逻辑回归能够提供概率并使用连续和离散测量值对新样本进行分类,使其成为一种流行的机器学习方法。
线性回归与逻辑回归的区别
线性回归和逻辑回归的一个主要区别是数据拟合的方法:
- 线性回归:使用“最小二乘法”拟合,最小化残差的平方和。该方法允许计算R²来比较模型。
- 逻辑回归:使用“最大似然法”。它没有残差,因此不能使用最小二乘法或计算R²。
在逻辑回归中,您:
- 选择一个概率,根据体重缩放,观察肥胖老鼠的概率。
- 使用此概率计算观察到的该体重的非肥胖老鼠的可能性。
- 然后计算观察到该老鼠的可能性。
- 对所有老鼠重复此过程并将所有这些可能性相乘。这是给定该曲线的数据的可能性。

然后,您:
- 移动曲线。
- 计算新曲线的数据可能性。
- 重复此过程,直到找到最大可能性的曲线。

总结
逻辑回归可以用于分类样本,并且可以使用不同类型的数据(例如体重、基因型)进行分类。它还帮助评估哪些变量对分类有用(例如在使用体重、基因型、年龄和星座预测肥胖时,星座可能“完全无用”)。
关键概念
逻辑函数
逻辑回归的核心是逻辑函数(也称为S型函数),它将任何实值数映射到[0, 1]范围内:
σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1
这里, z z z是输入特征的线性组合。对于二分类,逻辑函数输出给定输入点属于正类的概率。
决策边界
决策边界是我们分类输出的阈值。对于二分类,一个常见的阈值是0.5:
- 如果输出概率 ≥ 0.5 \geq 0.5 ≥0.5,则分类为类别1。
- 如果输出概率 < 0.5 < 0.5 <0.5,则分类为类别0。
模型表示
假设
在逻辑回归中,假设定义为:
h θ ( x ) = σ ( θ T x ) h_\theta(x) = \sigma(\theta^T x) hθ(x)=σ(θTx)
其中, θ \theta θ是权重向量, x x x是输入特征向量, σ \sigma σ是S型函数。
代价函数
逻辑回归的代价函数是对数损失(也称为二元交叉熵):
J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) log ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ] J(\theta) = -\frac{1}{m} \sum_{i=1}^{m} \left[ y^{(i)} \log(h_\theta(x^{(i)})) + (1 - y^{(i)}) \log(1 - h_\theta(x^{(i)})) \right] J(θ)=−m1i=1∑m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
其中, m m m是训练样本的数量, y y y是实际标签, h θ ( x ) h_\theta(x) hθ(x)是预测概率。
优化
目标是找到使代价函数 J ( θ ) J(\theta) J(θ)最小化的参数 θ \theta θ。这通常使用梯度下降等优化算法来完成。
稀疏特征
在许多现实世界的应用中,特征空间是稀疏的,意味着大多数特征值为零。逻辑回归在这些场景中特别有效,因为:
- 它可以高效地处理高维数据。
- 模型复杂度与特征数量线性相关,使其在计算上可行。
使用稀疏数据进行逻辑回归时,我们通常使用稀疏矩阵表示(如压缩稀疏行(CSR)或压缩稀疏列(CSC)格式)来存储输入特征。
这些数据结构仅存储非零元素及其索引,与密集矩阵相比显著减少了内存使用。
逻辑回归涉及矩阵乘法和其他线性代数操作。当数据存储在稀疏矩阵中时,这些操作可以优化以忽略零元素,从而加快计算速度。
当使用正则化技术时,特别是L1正则化(也称为套索正则化),逻辑回归被认为是稀疏线性分类器。这种正则化技术可以迫使模型的一些系数正好为零,有效地忽略某些特征,从而导致稀疏模型。
该模型是线性的,因为它将对数几率建模为输入特征的线性组合。
log ( p 1 − p ) = β 0 + β 1 x 1 + β 2 x 2 + … + β n x n \log \left( \frac{p}{1-p} \right) = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \ldots + \beta_n x_n log(1−pp)=β0+β1x1+β2x2+…+βnxn
在逻辑回归的上下文中,“计算上可行”意味着:
训练和预测的时间和内存需求随着数据规模(特征和样本数量)线性增长。
分布式训练
为什么要分布式训练?
随着数据量的增加,在单台机器上训练模型会变得缓慢且不切实际。分布式训练允许并行处理,使得能够高效地处理大数据集。因此,在数据量大的情况下,我们需要使用分布式训练:Spark中的逻辑回归或交替方向乘子法(ADMM)。
Apache Spark
Apache Spark是一个强大的分布式数据处理工具。它可以用于在集群上的多台机器上并行训练逻辑回归模型。
交替方向乘子法(ADMM)
ADMM是一种优化技术,它将问题分解为可以并行解决的较小子问题。这对于需要机器之间协调的分布式环境特别有用。
结论
逻辑回归是一种强大且高效的二分类方法,特别适用于稀疏特征和大数据集。通过利用如Apache Spark的分布式训练框架和ADMM等优化技术,逻辑回归可以扩展以应对现代数据科学应用的需求。
逻辑回归与对数几率
概率与几率
-
概率 §:事件发生的可能性。
-
几率:事件发生的概率与其不发生的概率之比。
几率 = P 1 − P \text{几率} = \frac{P}{1 - P} 几率=1−PP
对数几率(Logit)
-
对数几率是几率的自然对数。
对数几率 = log ( P 1 − P ) \text{对数几率} = \log \left( \frac{P}{1 - P} \right) 对数几率=log(1−PP)
逻辑回归模型
-
在逻辑回归中,事件发生概率的对数几率(例如点击的概率)被建模为输入特征的线性组合。
-
模型方程为:
log ( P 1 − P ) = θ 0 + θ 1 x 1 + θ 2 x 2 + … + θ n x n \log \left( \frac{P}{1 - P} \right) = \theta_0 + \theta_1 x_1 + \theta_2 x_2 + \ldots + \theta_n x_n log(1−PP)=θ0+θ1x1+θ2x2+…+θnxn
-
这里, θ 0 + θ 1 x 1 + θ 2 x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7548
7548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









