







一 Checkpoint定义
模型在训练过程中的中间状态和结果,是大语言模型在训练过程中进行容错的一种关键技术,通过将中间状态和结果作为checkpoint保存到持久化存储,在训练任务由于异常失败时,可以从checkpoint中恢复训练中间状态继续训练,Checkpoint 的主要目的是防止训练过程中因意外中断而导致的训练进度丢失,并提供模型的不同版本以便于选择最佳模型。
断点续训的基本原理是定期保存模型的状态(即检查点),包括模型的权重、优化器的状态、当前的训练轮数等信息。当训练过程中发生中断(如程序崩溃、系统重启或手动停止训练)时,可以通过加载最近的检查点来恢复训练。
二 功能特点
- 训练恢复:在训练过程中断时,可以从最近的 Checkpoint 恢复训练,避免从头开始。
- 模型版本管理:保存不同阶段的模型状态,便于选择和比较不同版本的模型。
- 推理使用:在训练完成后,使用 Checkpoint 文件进行模型推理。
- 调试和验证:在训练过程中保存 Checkpoint,便于调试和验证模型性能。
三 Checkpoint的组成
一个典型的检查点通常包含以下内容:
- 模型权重:模型的所有参数,包括权重和偏置。
- 优化器状态:优化器的状态,包括动量、学习率等。
- 训练状态:当前的训练轮数(epoch)、批次(batch)编号等。
- 其他元数据:如学习率调度器的状态、自定义指标等。
四 底层原理
Checkpoint 的底层原理是将模型的当前状态(包括模型参数、优化器状态等)序列化并保存到文件中。在需要时,可以将这些文件反序列化,恢复模型的状态。具体步骤包括:
- 序列化(Serialization) :将模型的参数和优化器状态转换为可存储的格式(如字典、张量)。
- 反序列化(Deserialization) :将存储的格式转换回模型的参数和优化器状态。
- 文件存储:将序列化后的数据保存到文件中,通常使用特定的文件格式(如 HDF5、Pickle)。
- 文件恢复:从文件中读取数据,并将其转换回模型的参数和优化器状态。
1. 模型参数的序列化
在深度学习模型中,模型的参数通常以张量(Tensor)的形式存储。序列化是将这些张量转换为可存储的格式。以 PyTorch 为例,模型的参数可以通过 state_dict 方法获取,返回一个包含所有参数的字典。
model_state_dict = model.state_dict()
2. 优化器状态的序列化
优化器的状态同样需要保存,以便在恢复训练时继续使用相同的优化器状态。优化器的状态可以通过 state_dict 方法获取,返回一个包含优化器状态的字典。
optimizer_state_dict = optimizer.state_dict()
3. 文件存储
将序列化后的模型参数和优化器状态保存到文件中。常用的文件格式包括 HDF5 和 Pickle。在 PyTorch 中,通常使用 torch.save 方法将数据保存为 .pth 文件。
checkpoint = {
'model_state_dict': model_state_dict,
'optimizer_state_dict': optimizer_state_dict,
'epoch': current_epoch,
'loss': current_loss
}
torch.save(checkpoint, 'checkpoint.pth')
4. 文件恢复
从文件中读取数据,并将其转换回模型的参数和优化器状态。使用 torch.load 方法读取 .pth 文件,并通过 load_state_dict 方法将参数和状态加载到模型和优化器中。
checkpoint = torch.load('checkpoint.pth')
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
五 工作流程
- 初始化模型:定义和初始化深度学习模型。
- 训练模型:在训练过程中定期保存 Checkpoint。
- 保存 Checkpoint:将模型的当前状态(参数、优化器状态等)保存到文件中。
- 恢复 Checkpoint:在训练中断或需要时,从 Checkpoint 文件中恢复模型的状态。
- 推理或继续训练:使用恢复后的模型进行推理或继续训练。
六 使用方法
使用 Checkpoint 通常涉及以下步骤:
- 定义模型和优化器:定义深度学习模型和优化器。
- 保存 Checkpoint:在训练过程中定期保存模型的状态。
- 恢复 Checkpoint:在需要时,从 Checkpoint 文件中恢复模型的状态。
- 推理或继续训练:使用恢复后的模型进行推理或继续训练。
七 使用例子
以下是使用 PyTorch 进行 Checkpoint 保存和恢复的示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义简单的神经网络模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
# 初始化模型和优化器
model = SimpleModel()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 定义保存 Checkpoint 的函数
def save_checkpoint(model, optimizer, epoch, loss, filepath):
checkpoint = {
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss
}
torch.save(checkpoint, filepath)
# 定义恢复 Checkpoint 的函数
def load_checkpoint(filepath, model, optimizer):
checkpoint = torch.load(filepath,weights_only=True)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
return model, optimizer, epoch, loss
# 模拟训练过程
num_epochs = 5
for epoch in range(num_epochs):
# 模拟训练步骤
loss = torch.tensor(0.1 * (num_epochs - epoch)) # 假设损失逐渐减少
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {loss.item()}")
# 保存 Checkpoint
save_checkpoint(model, optimizer, epoch, loss, f'checkpoint_epoch_{epoch+1}.pth')
# 恢复 Checkpoint
model, optimizer, epoch, loss = load_checkpoint('checkpoint_epoch_3.pth', model, optimizer)
print(f"Restored from checkpoint - Epoch: {epoch+1}, Loss: {loss.item()}")
运行结果:
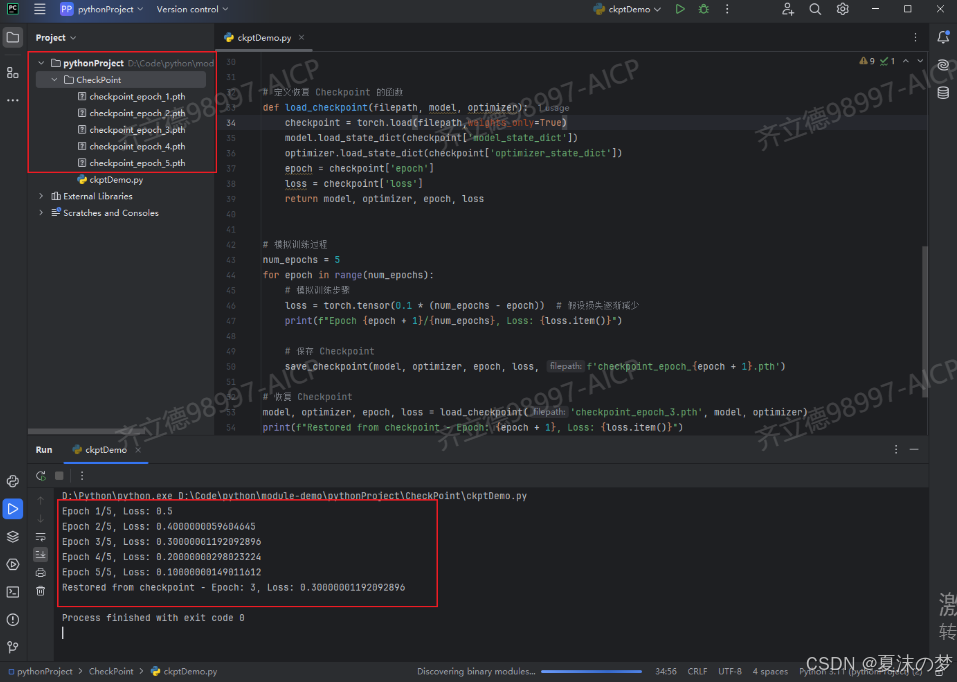
八 优缺点
优点:
- 防止训练进度丢失:在训练过程中断时,可以从最近的 Checkpoint 恢复训练,避免从头开始。
- 模型版本管理:保存不同阶段的模型状态,便于选择和比较不同版本的模型。
- 调试和验证:在训练过程中保存 Checkpoint,便于调试和验证模型性能。
缺点:
- 存储开销:保存 Checkpoint 文件会占用存储空间,特别是对于大型模型和长时间训练。
- 管理复杂性:需要管理多个 Checkpoint 文件,可能会增加管理的复杂性。
- 恢复时间:从 Checkpoint 恢复模型状态可能需要一定的时间,特别是对于大型模型。
九 更多信息
Checkpoint 是深度学习训练过程中非常重要的一部分,通过定期保存模型的当前状态,可以防止训练进度丢失,并提供模型的不同版本以便于选择最佳模型。随着深度学习技术的发展,Checkpoint 方法和工具也在不断改进,未来 Checkpoint 将继续在深度学习训练和应用中发挥重要作用。



















 5956
5956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











