






循环神经网络
)
RNN
RNN(Recurrent Neural Network), 中文称作循环神经网络,它一般以序列数据为输入,通过网络内部的结构设计有效捕捉序列之间的关系特征,一般也是以序列形式进行输出.
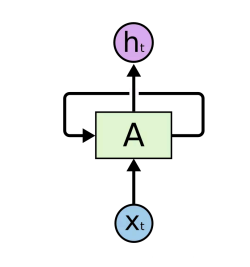
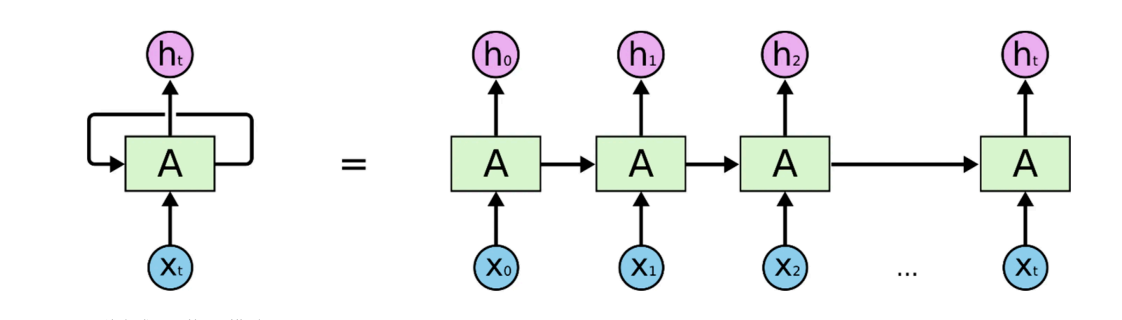
RNN⼯作流程
循环神经⽹络(Recurrent Neural Network, RNN)是⼀类以序列(sequence)数据为输⼊,在序列的演进⽅向进⾏递归(recursion)且所有节点(循环单元)按链式连接的递归神经⽹络(recursive neural network)
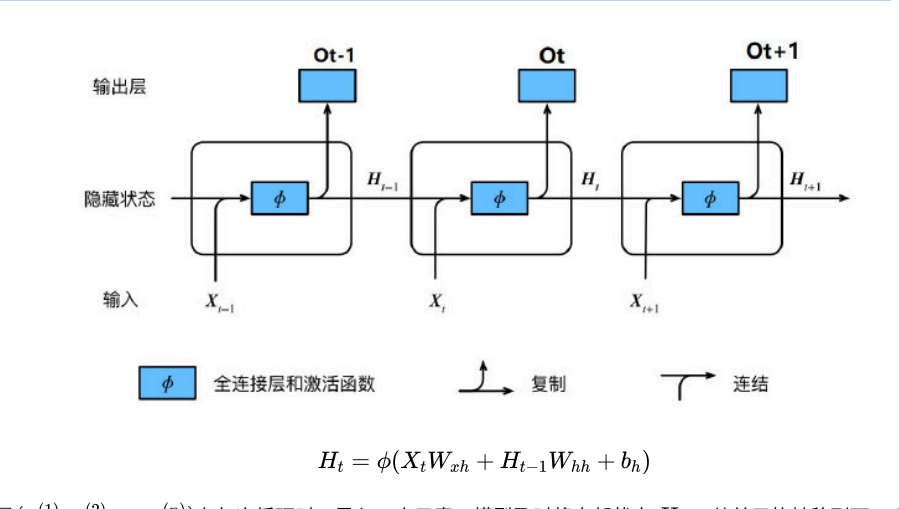



RNN模型的数据输入
RNN还可以理解为时间序列的有向图。这让它表现出更适合处理基于时间序列的动态预测。学习RNN模型的⼯作原理,最好的理解⽅式还是从它的输⼊数据下⼿。
input_data → [sequence_length, feature_size]
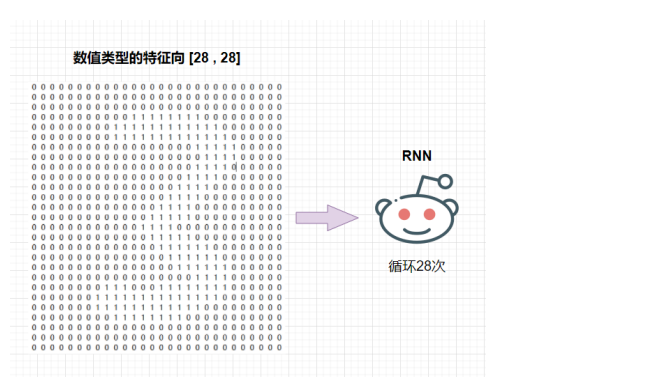
我们再把像素转换为值类型的向量,28个⾏向量依次导⼊RNN模型进⾏训练。
顺序导⼊每⼀⾏,意味着图像中每⼀⾏之间存在着前后间的特征关联。
我们把28个特征向量交给RNN,⽽RNN需要28次循环来完成对特征向量的学习。
RNN通过训练,模型参数中记录的是对于连续特征向量的先后关联性。
计算过程:堆叠RNN的结构,每次输⼊的 经第⼀层RNN的 计算经线性变换、加偏置和激活函数获得输出后,继续传给下⼀层RNN的 。Z_t经相同的计算过程后得到 即最后的输出
多层RNN神经⽹络,最终的输出是多层RNN计算叠加后的结果。通过增加模型参数,起到捕捉序列中更多特征信息的作⽤。
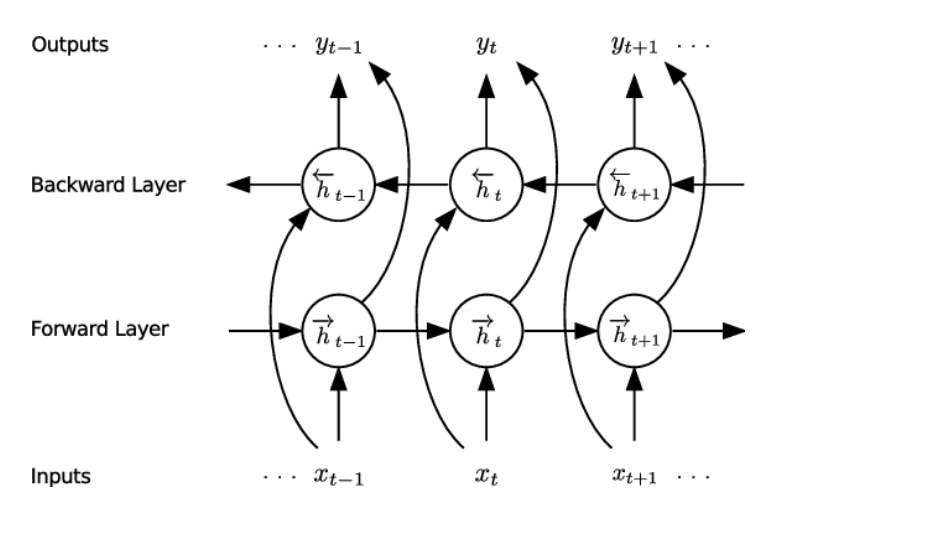
双向RNN

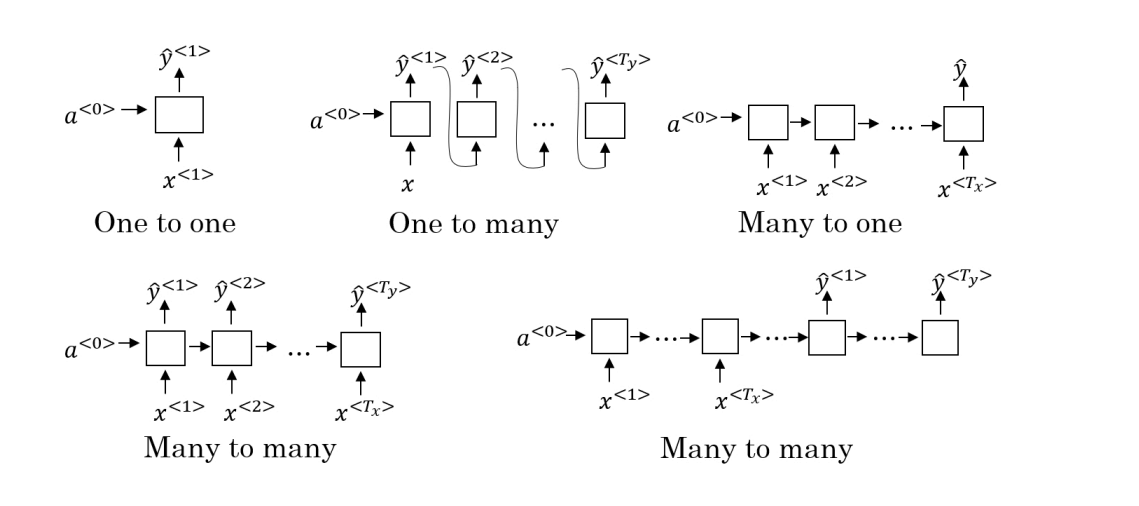
RNN模型的⼏种应⽤形式

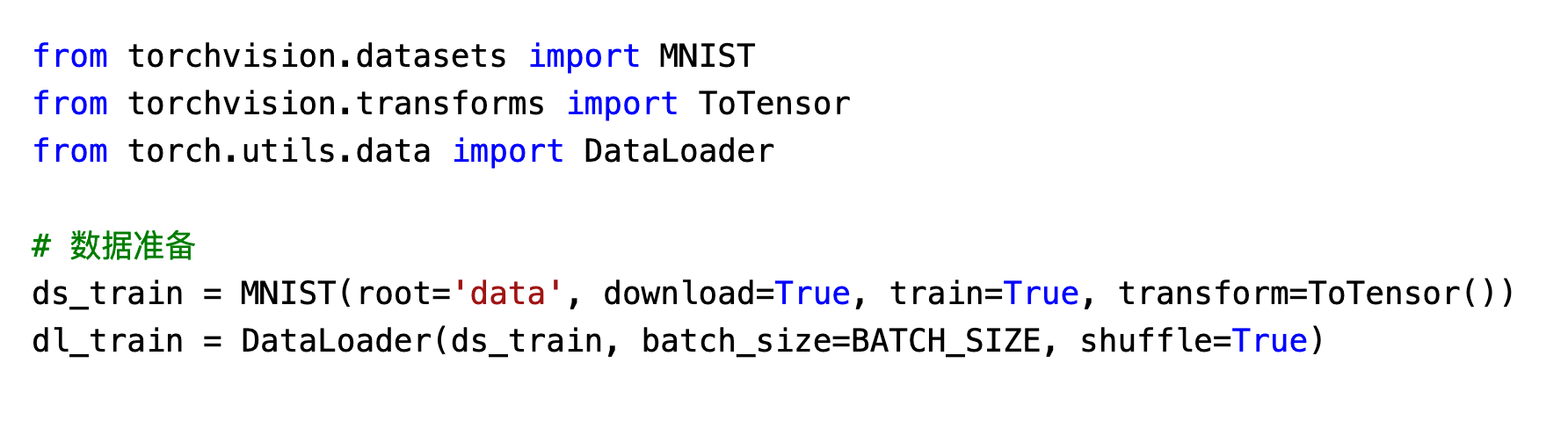
基于RNN的图像分类预测
1.数据准备
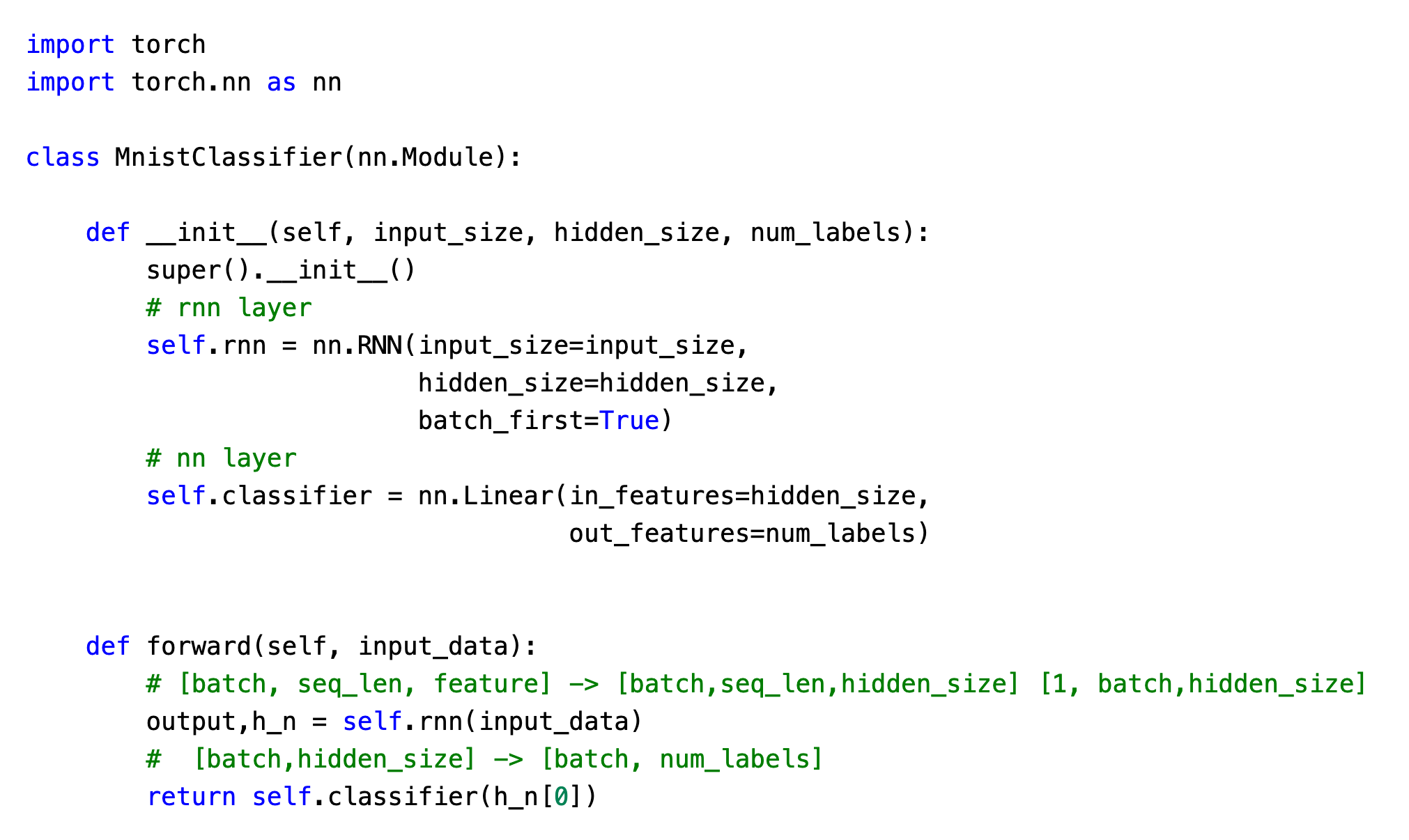
2.模型构建
3.模型训练
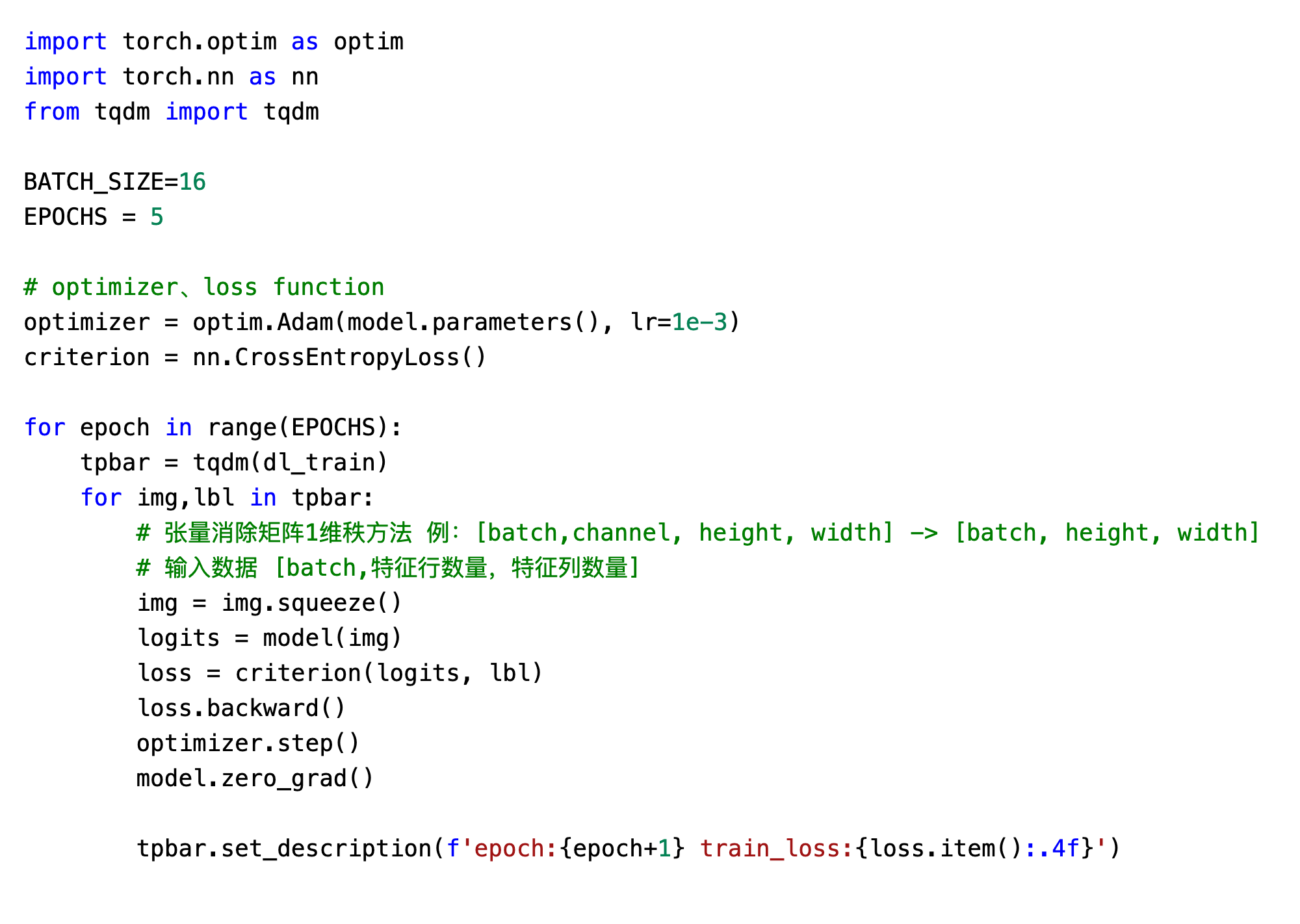
4.模型保存

RNN中的梯度爆炸及梯度消失
在循环神经⽹络(RNN)中,梯度消失或爆炸问题主要是由于在反向传播过程中,梯度在时间步上不断传递和计算。
假设⼀个简单的RNN单元,其隐藏状态的更新公式为:


梯度消失与爆炸的实际影响
梯度消失:早期时间步的参数更新极⼩,模型难以捕捉⻓距离依赖(例如 NLP 中的⻓句⼦)。
梯度爆炸:参数更新过⼤导致数值不稳定,模型⽆法收敛(weight 最终变为 NaN )。
缓解梯度消失与爆炸的⽅法
梯度裁剪:限制梯度范数(如 L2 范数)以防⽌爆炸。
⻔控机制:LSTM/GRU 通过⻔控结构控制梯度流动,缓解消失问题。
激活函数选择:使⽤ Leaky ReLU、Swish 等改进激活函数。
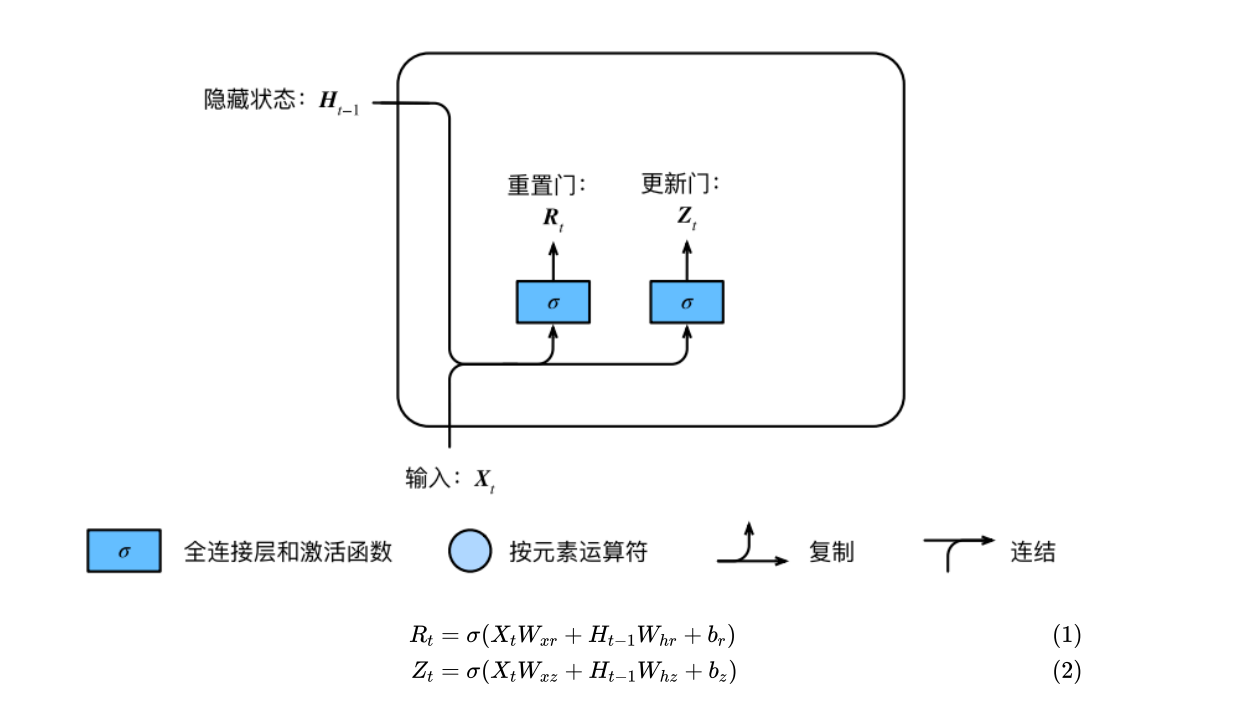
GRU
在循环神经⽹络中的梯度计算⽅法中,我们发现,当时间步数较⼤或者时间步较⼩时,循环神经⽹络的梯度较容易出现衰减或爆炸。虽然裁剪梯度可以应对梯度爆炸,但⽆法解决梯度衰减的问题。通常由于这个原因,循环神经⽹络在实际中较难捕捉时间序列中时间步距离较⼤的依赖关系。
⻔控循环神经⽹络(gated recurrent neural network)的提出,正是为了更好地捕捉时间序列中时间步距离较⼤的依赖关系。它通过可以学习的⻔来控制信息的流动。其中,⻔控循环单元(gatedrecurrent unit,GRU)是⼀种常⽤的⻔控循环神经⽹络。
LSTM
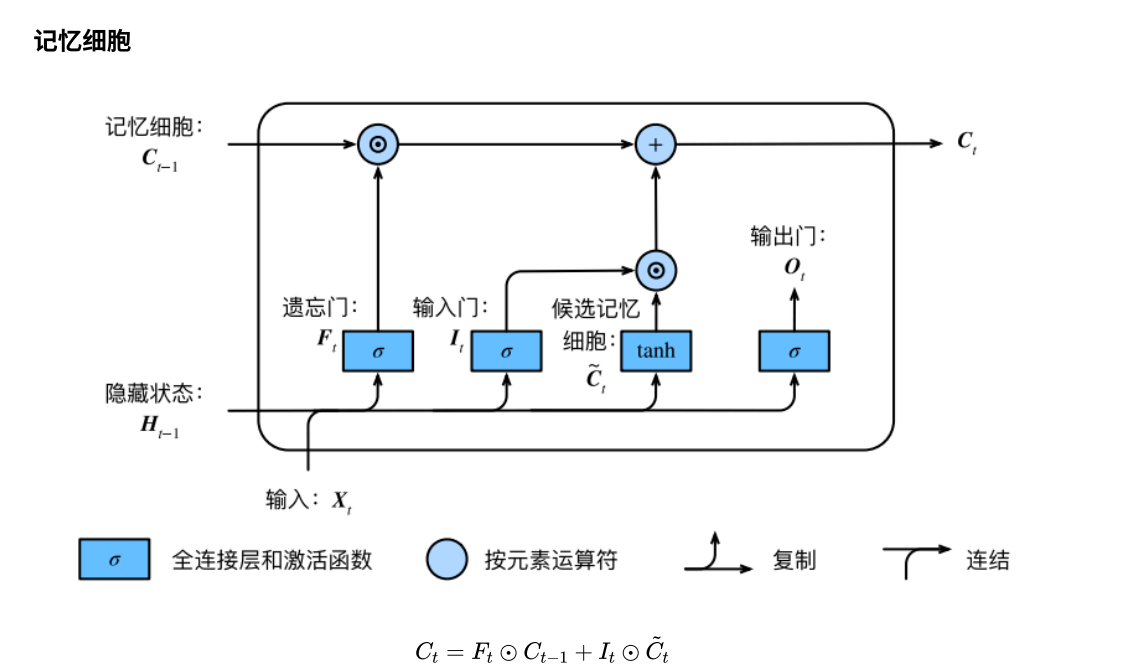
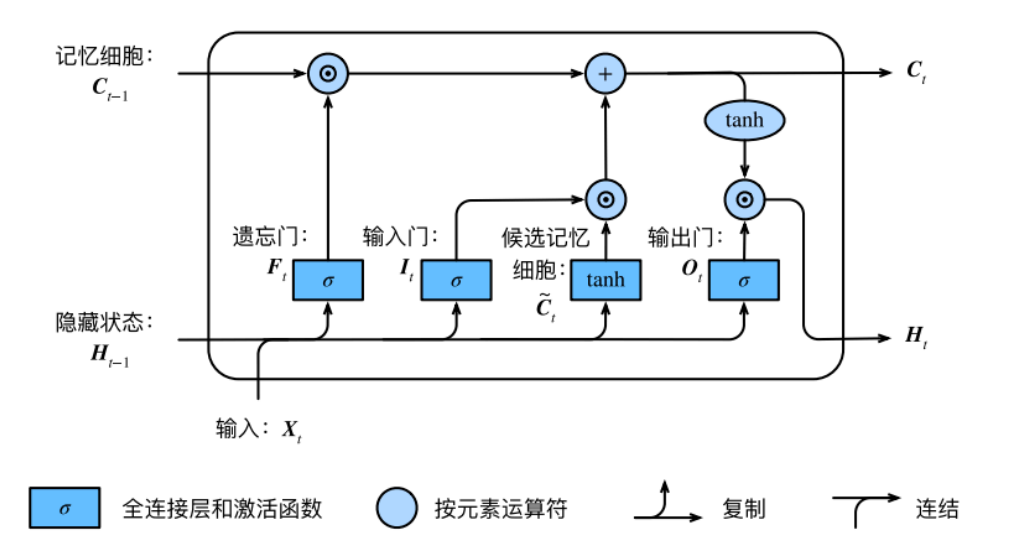
LSTM 中引⼊了3个⻔,即输⼊⻔(input gate)、遗忘⻔(forget gate)和输出⻔(output gate),以及与隐藏状态形状相同的记忆细胞(某些⽂献把记忆细胞当成⼀种特殊的隐藏状态),从⽽记录额外的信息。
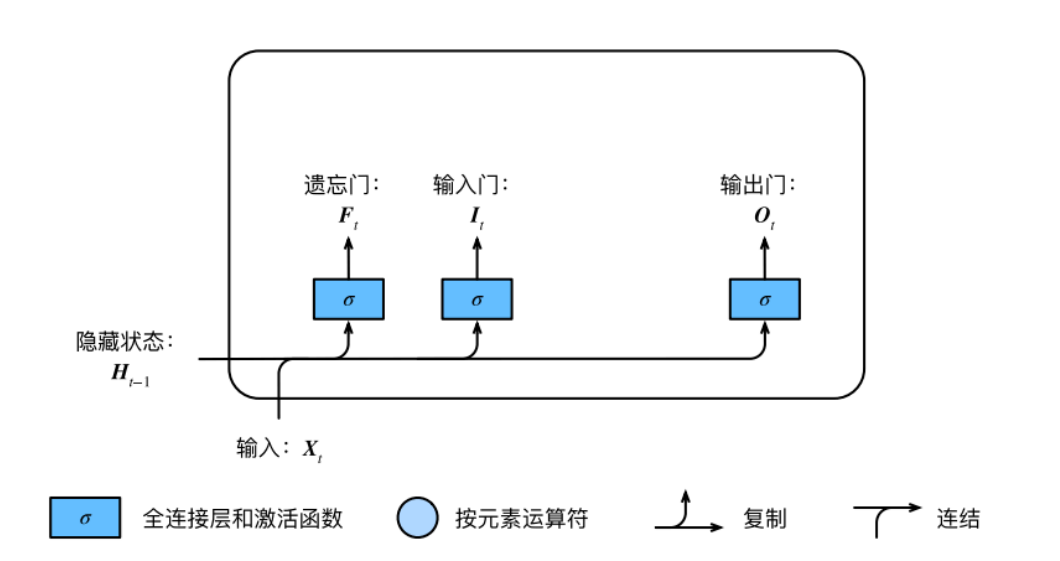
具体来说,假设隐藏单元个数为 , 给定时间步 的⼩批量输⼊ (样本数为 , 输⼊个数为 )和上⼀时间步隐藏状态

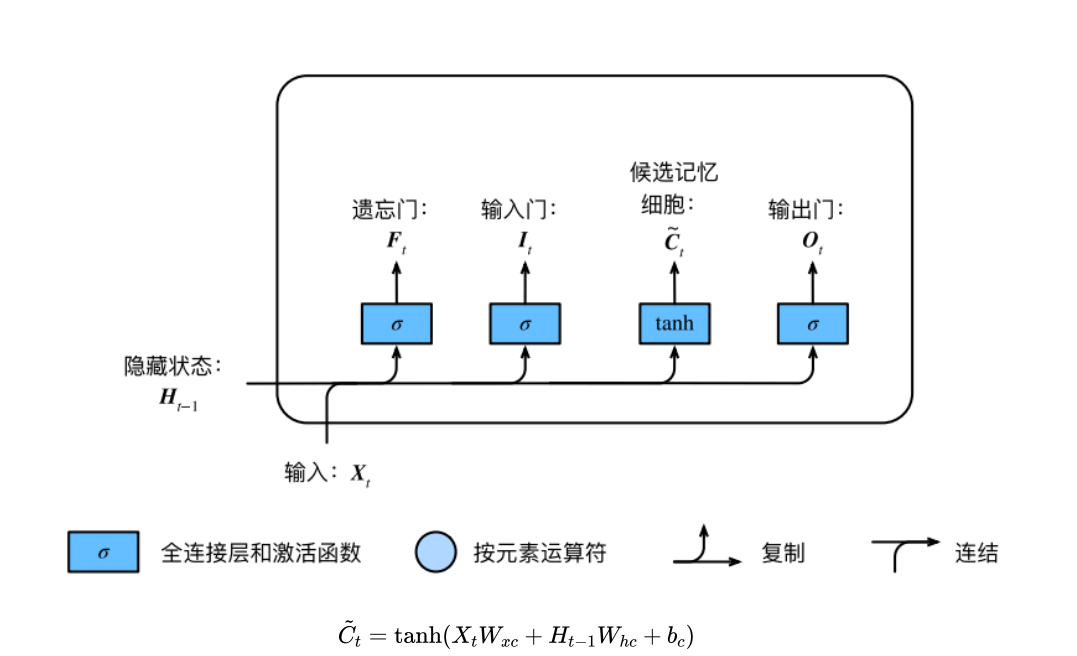

LSTM与GRU的区别
LSTM与GRU⼆者结构⼗分相似,不同在于:
1.新的记忆都是根据之前状态及输⼊进⾏计算,但是GRU中有⼀个重置⻔控制之前状态的进⼊量,⽽在LSTM⾥没
有类似⻔;
2.产⽣新的状态⽅式不同,LSTM有两个不同的⻔,分别是遗忘⻔(forget gate)和输⼊⻔(input gate),⽽GRU只有
⼀种更新⻔(update gate);
3.对新产⽣的状态可以通过输出⻔(output gate)进⾏调节,⽽GRU对输出⽆任何调节。
4.的优点是这是个更加简单的模型,所以更容易创建⼀个更⼤的⽹络,⽽且它只有两个⻔,在计算性上也运⾏
得更快,然后它可以扩⼤模型的规模。
5.更加强⼤和灵活,因为它有三个⻔⽽不是两个。

















 2936
2936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









