







一种典型的用来识别数字的卷积网络是 LeNet-5。
模型结构
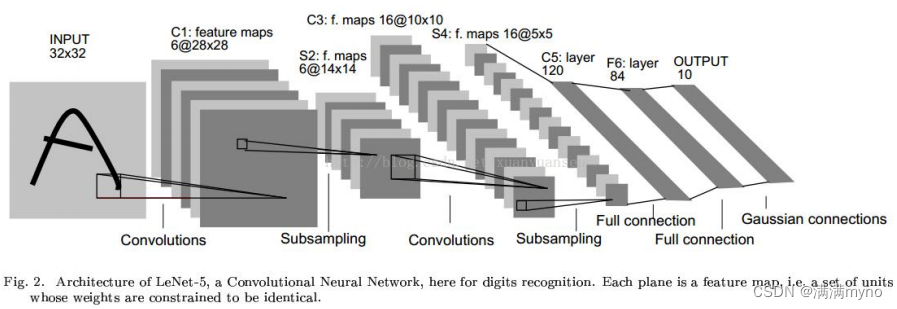
C1
层是一个卷积层
输入图片:32*32;卷积核大小:5*5;卷积核种类:6 ;输出featuremap大小:28*28 (32-5+1)神经元数量:28*28*6 ;可训练参数:(5*5+1)*6(每个滤波器5*5=25 个unit参数和一个bias参数,一共6个滤波器);连接数:(5*5+1)*6*28*28
S2
层是一个下采样层
输入:28*28 ;采样区域:2*2 ;采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过 sigmoid;采样种类:6;输出featureMap大小:14*14(28/2);神经元数量:14*14*6;可训练参数:2*6(和的权+偏置);连接数:(2*2+1)*6*14*14;S2 中每个特征图的大小是 C1 中特征图大小的 1/4
C3
层也是一个卷积层
输入:S2 中所有 6 个或者几个特征 map 组合;卷积核大小:5*5;卷积核种类:16;输出featureMap 大小:10*10;C3中的每个特征 map 是连接到S2中的所有 6个或者几个特征 map 的,表示本层的特征map 是上一层提取到的特征 map 的不同组合;存在的一个方式是:C3 的前 6 个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的 3 个以不相邻的 4 个特征图子集为输入。最后一个将S2中所有特征图为输入。则:可训练参数:6*(3*25+1)+6*(4*25+1)+3*(4*25+1) +(25*6+1)=1516; 连接数10*10*1516=151600
S4
层是一个下采样层
输入:10*10 ;采样区域:2*2 ;采样方式:4 个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过 sigmoid ;采样种类:16 ;输出 featureMap 大小:5*5(10/2) ;神经元数量:5*5*16=400 ;可训练参数:2*16=32(和的权+偏置) ;连接数:16*(2*2+1)*5*5=2000;S4 中每个特征图的大小是 C3 中特征图大小的 1/4
C5
层是一个卷积层
输入:S4 层的全部 16 个单元特征 map(与 s4 全相连) ;卷积核大小:5*5 ;卷积核种类:120 输出 featureMap 大小:1*1(5-5+1) ;可训练参数/连接:120*(16*5*5+1)=48120
F6
层全连接层
输入:c5 120 维向量 ;计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过 sigmoid 函 数 ;可训练参数:84*(120+1)=10164
模型特性
卷积网络使用一个 3 层的序列:卷积、池化、非线性——这可能是自这篇论文以来面向图像的深度学习的关键特性!
使用卷积提取空间特征
使用映射的空间均值进行降采样
tanh 或 sigmoids 非线性
多层神经网络(MLP)作为最终的分类器
层间的稀疏连接矩阵以避免巨大的计算开销
















 3796
3796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











