






[1] Zhou Y , Wang B , He X ,et al.DR-GAN: Conditional Generative Adversarial Network for Fine-Grained Lesion Synthesis on Diabetic Retinopathy Images.[J].IEEE Journal of Biomedical and Health Informatics, 2020.DOI:10.1109/JBHI.2020.3045475.
解决的问题:糖尿病视网膜病变(DR)是一种严重影响眼睛的糖尿病并发症。根据国际协议,它可以分为五个严重程度。然而,优化分级模型使其具有较强的泛化能力需要大量的平衡训练数据,这些数据很难收集,特别是对于高严重级别。
提出了一种数据增强方法:典型的数据增强方法,包括随机翻转和旋转,不能产生高多样性的数据。在本文中,我们提出了一种糖尿病视网膜病变生成对抗网络(DR-GAN)来合成高分辨率眼底图像,该图像可以被任意分级和病变信息操纵。因此,大规模生成的数据可以用于更有意义的增强,以训练DR分级和病变分割模型。所提出的视网膜生成器以结构掩模和病变掩模为条件,以及从潜在的分级空间中采样的自适应分级向量,可以用来控制合成的分级严重程度。
提出了一种网络:此外,设计了多尺度空间和通道注意模块,提高了小细节合成的生成能力。设计了从大到小的多尺度判别器,并采用联合对抗损失以端到端方式优化整个网络。
创新点:
1. 提出了一种条件高分辨率图像发生器,用于合成具有可控病变和分级信息的视网膜图像。在常规编解码器设计的基础上,采用多尺度空间和通道关注和递进生成设计,旨在合成更真实的局部细节。同时利用对抗损失、特征匹配损失和分级分类损失对多尺度判别器进行优化。
2. 采用具有分级标注的真实DR图像,学习随机采样自适应分级向量的不同潜在分级空间。这些向量可以被视为分级嵌入,有助于操作多尺度合成块以更有效地生成。
3.进行了定性和定量实验来评估我们的模型。生成的样本不仅具有良好的保真度和多样性,而且我们还发现合成的图像可以用于数据增强,以训练更好的DR分级和病变分割模型。在Kaggle EyePACS[15]和FGADR[21]数据集上进行的大量烧蚀研究和对比实验证明了我们方法的有效性和优越性。
与以往的工作相比,本文做了五个主要的扩展
1)在合成块中提出了多尺度空间和通道注意(SCA)模块,以更好地提高精细细节的生成质量。这样也可以提高分级性能。
2)我们介绍了两个更重要的病变:激光标记和增殖膜,它们与3级和4级DR图像的识别特别相关。我们使用弱监督训练的激活图作为这两个病变的病变掩模输入,因为我们没有它们的注释基础事实。
3)我们以前的DR-GAN模型合成的眼底图像中视盘的轮廓通常是模糊的。在这个版本中,增加了一个视盘掩模来解决这个问题,使生成的图像更加逼真。
4)采用新提出的大像素级标注数据集(FGADR[21])对DR-GAN进行训练。性能进一步提高。
5)增加了更多可靠的评价实验和结果,包括人的评价,合成保真度的Frechet inception distance (FID)和Sliced wasserstein distance (SWD),以及DR分级的每类真阳性率。
方法
1.高分辨率DR图像生成
我们设计了一个两级编码器-解码器模型来合成1280×1280图像。如图1所示,视网膜生成器的蓝色构建块,表示为Gm,目标是生成640 × 640的分辨率。然后,用黄色表示的Gl块可以进一步合成更真实的局部细节,将分辨率提高到1280 × 1280。
Gm由编码块、残差块和合成块三部分组成。编码块采用具有四个卷积层的全卷积模块。差块增加了网络的深度,并提出使用更深的感知器学习更好的变换函数和表示。最后,合成块是最重要的组成部分,其基本单元采用转置卷积运算。在这些块中嵌入自适应分级操作操作。合成块的超参数设置类似于编码块。在这项扩展工作中,在合成块中设计了一个多尺度空间和通道注意力(SCA)模块,以更好地提高精细细节的生成质量。
Gl的设计要简单得多,只包括两个Conv层和两个相应的转置Conv层。第一个转置的Conv层的输入是Gl的最后一个Conv层的特征映射和Gm的最后一个转置的Conv层的特征映射的元素求和。这样的设计使得Gl直接继承了Gm学习到的全局特征,并进一步基于掩模输入逐步合成局部细节,具有更高的分辨率。请注意,Gm首先是预训练的,然后添加Gl来微调整个生成器。
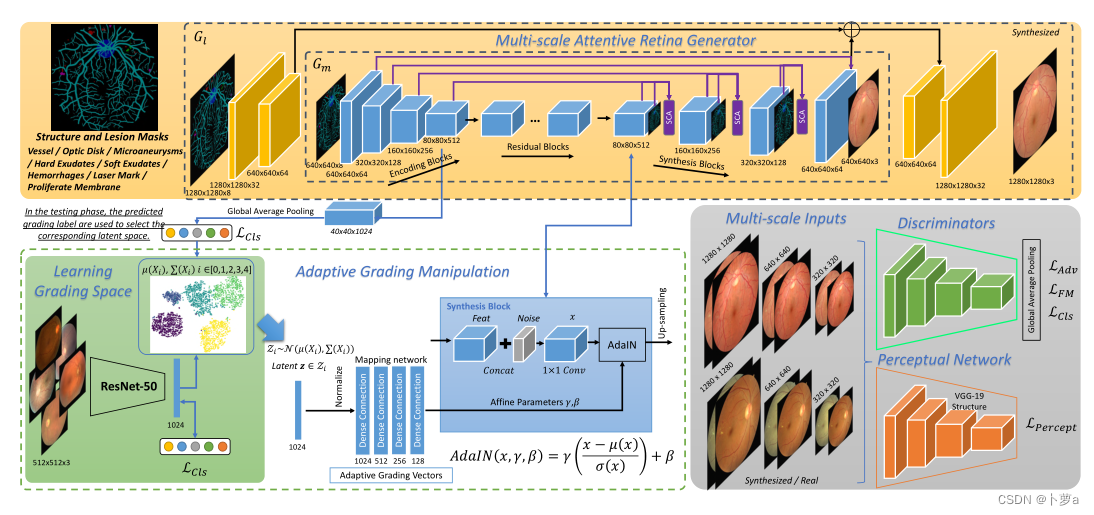
图1 DR-GAN管道。多尺度关注发生器的主干(黄色)是基于结构和病变掩模的输入。一个自适应分级操作模块被设计成与合成块集成。灰框表示用于多任务优化的多尺度判别器。绿色的部分被用来学习潜在的分级空间,用于采样分级嵌入。
2.多尺度空间和通道注意模块
编码器-解码器框架不能有效地保留输入的掩模图像中的微小病变和细小血管等细节,并在输出的眼底图像中清晰地综合出来。因此,在这项扩展工作中,在多尺度合成块中提出了一个空间和通道注意模块,如图1中紫色部分所示。在每个合成块(将在下一节中解释)中进行自适应分级操作后,将编码和合成块的相应特征映射与调整大小的结构和病变蒙版输入连接在一起。将组合的特征进一步通过一个卷积层,该卷积层作为空间和通道注意模块的输入。然后对下一个合成块进行上采样。
空间和通道注意(SCA)模块的网络如图2所示。它由空间注意力和通道注意力两部分组成。使用这种自注意机制背后的动机是在空间上为更丰富的上下文表示建模,并增强特定的语义,如输入掩码,以改善通道映射之间的依赖性。因此,小细节可以更好地合成。
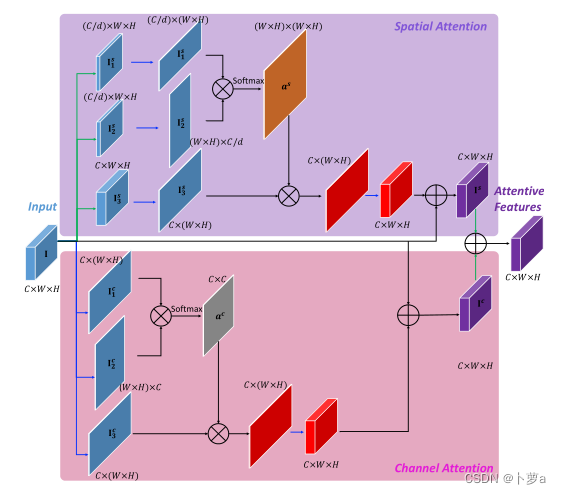
图2所示。空间和通道注意(SCA)的细节。绿色箭头表示卷积操作。蓝色表示重塑操作。
3.多任务优化的多尺度判别器
为了更好地优化高分辨率图像生成器,鉴别器需要具有不同尺度的接受域来区分真实图像和合成图像。最有效的方法是设计具有相同网络结构的多尺度鉴别器。在这项工作中,我们采用原始尺寸1280 × 1280,并将其降采样到640×640和320×320两个尺度。将图像的三个尺度向前传递给三个鉴别器Dn, n∈{1,2,3}。应用于最小尺度的鉴别器提供了最大的接受野,以聚焦眼底整体图像结构和一些大的病变模式。相比之下,应用于最大尺度的一个提供最小的接受野来产生更多的局部细节,特别是对于小的病变区域。最后采用全球平均池化方法拟合不同尺度。
在这项工作中,精心设计了一个多任务损失,用于在对抗性学习架构中训练生成器和鉴别器。除了采用标准对抗损失LAdv,使鉴别器对生成数据的输出最大化,我们还采用特征匹配损失LF - eat match[40]来优化生成器,匹配鉴别器中间层特征的统计量。特征匹配损失是为了解决训练gan的不稳定性,防止生成器在鉴别器上过度训练。此外,我们还加入了一个辅助分类损失LCls(由于数据分布不平衡,采用focal loss Lf local[41]),使判别器能够在合成数据和真实数据上学习DR分级的判别表示。对于最大规模的输入,集成了一个基于VGG-19主干的附加感知网络F,以促进LP感知的训练。















 172
172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









