






论文arxiv地址:https://arxiv.org/abs/2011.07466
论文源码:https://github.com/UBCDingXin/improved_CcGAN
导师有个项目可能需要基于回归标签来做数据生成,所以就找到了这篇文章再看,这篇文章的特点就是不涉及网络结构,而是调整了假设的数据集分布,从而改变cGAN原先传统的训练方式,让其能基于回归标签进行条件样本生成。
目录
1. 前言
CcGAN发表在2021年的ICLR上,它是一种cGAN,但和其他cGAN的不同之处在于,它可以针对回归标签(regression labels)生成高质量的图片。
回归标签和离散标签(通常是类别)对应,是指在一定区间内有无限取值的连续型标签,如角度,温度等。
2. 想要解决的问题
以往的cGAN在将回归标签作为生成条件时,往往只能采用离散化的策略,生成效果很差。
因此这篇文章想要基于回归标签的特点,通过改进目前cGAN的标签处理方式,损失函数和训练方式,来生成高质量的图片。
3. 本文贡献
- 过去的标签嵌入方式可能不适用于回归标签,因为回归标签是标量,并且有无限取值,因此提出了一种新的启发式的标签嵌入方式。
- 不同于过去的经验分布估计,而是利用核密度估计重新估计了数据集分布p(x,y),从而提出了2种新的判别器损失函数hard vicinal discriminator loss (HVDL)和soft vicinal discriminator loss (SVDL)还有相应的生成器损失函数。这是文章的核心贡献,所以之后也会重点介绍。
- 得出了判别器基于HVDL和SVDL的误差界。本文不涉及这一部分的解读。
- 提出了一个新的数据集RC-49,用于对回归标签+cGAN的情况进行性能测试。
4. 模型工作流程
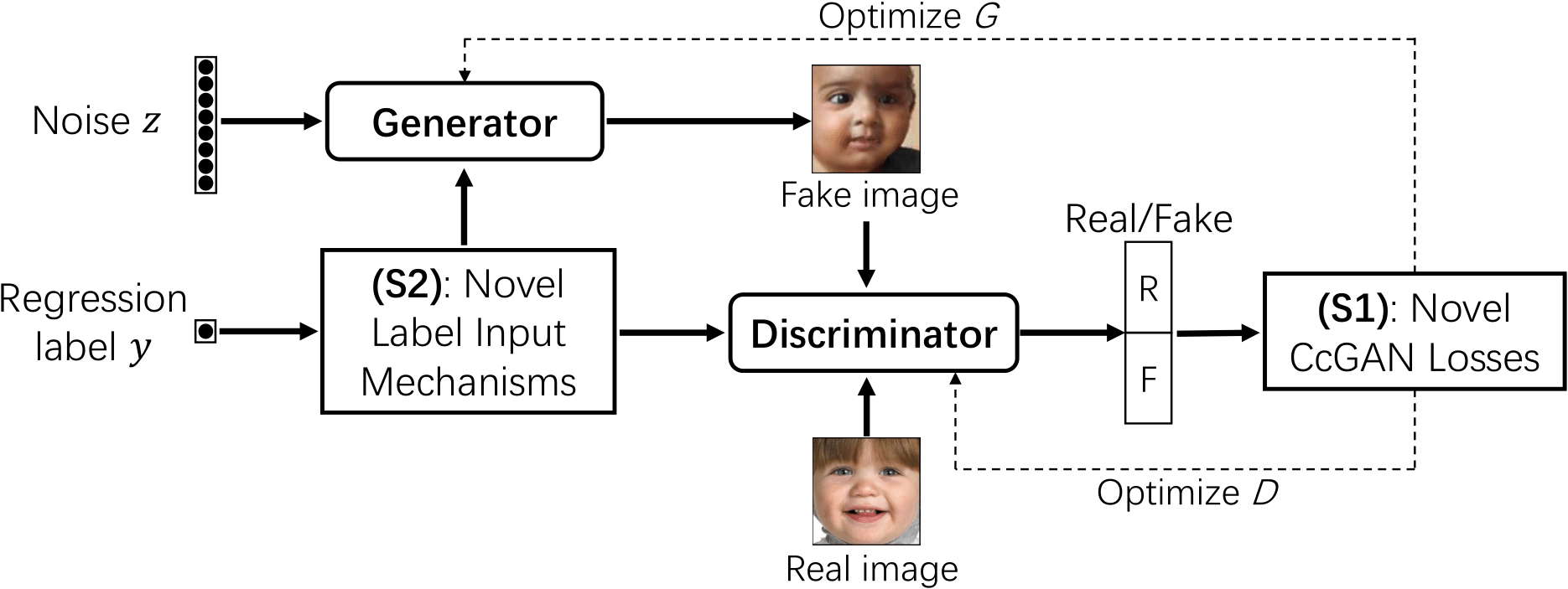
这是CcGAN作者放在github上的工作流程图,可以看到和一般的cGAN训练相比,主要有两点不同1.标签嵌入 2.损失函数。不过因为损失函数不同,所以训练流程也会不太一样,后面在分析训练伪代码的时候会详细介绍。
5. cGAN和CcGAN的区别
这里我们沿着作者的思路,先思考一般cGAN和CcGAN到底有什么本质的区别。
5.1 风险函数和经验风险函数
首先介绍一下风险和经验风险这两个后面要用到的概念。
在机器学习中风险函数(risk function)可以理解为模型关于训练集真实分布的平均损失,因此在表示时都会加上期望E。真实分布是无法求出来的,主要用于理论分析。
经验风险函数(empirical risk function)可以理解为模型关于训练集经验分布的平均损失。梯度下降(GD)算法中用的是这个,但是mini-batch SGD要用的话稍微有点不同。
5.2 cGAN的风险函数和经验风险函数
这里以判别器为例:
先看cGAN判别器的风险函数:
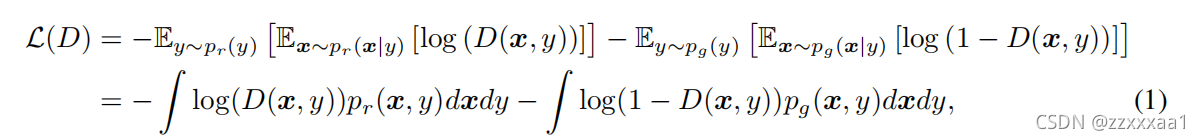
表示真实样本的真实分布,
表示生成样本的真实分布。
这实际上就是一个二分类的交叉熵损失,文字理解就是说希望判别器给真实样本判别1,给生成样本判别0。
第二个等式则是用积分的形式把期望给展开了,便于后续分析和
。
再看cGAN判别器的经验风险函数:
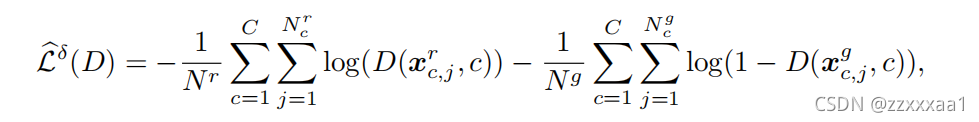
和
分别表示训练集中真实和生成样本的数量。
和
分别表示训练集中标签为c的真实和生成样本的数量。
和
分别表示训练集中标签为c的第j个真实和生成样本。
观察cGAN风险函数到经验风险函数的转换,我们知道这里存在对和
的经验分布估计。
下面是对和
进行经验分布估计的具体形式:
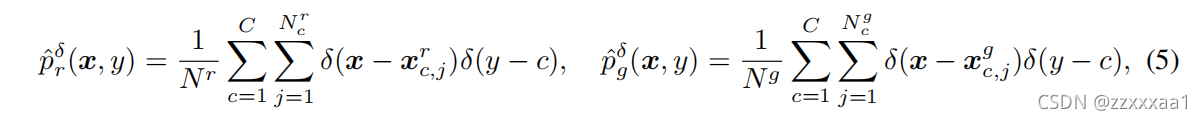
函数:狄拉克函数,也被称为激活函数,脉冲函数等。可以用于表示离散随机变量的概率密度函数。
大家有兴趣可以基于上面的经验分布推一下cGAN从风险函数到经验风险函数的转换,我这里就不展开了。
5.3 CcGAN的经验函数和经验风险函数
基于上述过程我们知道了,假如我们要用回归标签生成条件样本,其实风险函数是一样的,问题就出在对数据集分布的经验估计上面,原先的经验分布估计假设了标签y是离散的。
5.3.1 估计数据集分布p(x,y)
所以作者提出了用核密度估计的方式对回归标签分布p(y)进行平滑估计。我们看一下他具体是怎么做的。
这里我以文章中对真实样本分布的hard vicinal estimate为例
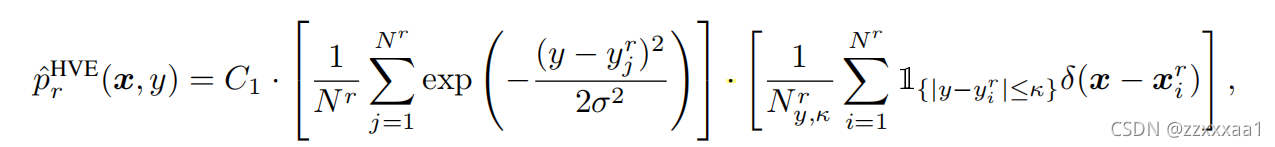
:是一个超参,用来做核密度估计的。直接的意思就是正态分布的方差。
和
:
表示第i个真实样本,
表示
的真实标签。
:I表示指示函数,即y只有满足{}内的不等式才取1,否则取0。
:表示满足
的
的个数,注意这里的
和指示函数里的
不是一个意思。
:能让这个概率密度函数的积分为1的常数,不重要。
接下来分析一下它是如何估计:
基于,我们知道等式右边的第一项是对
进行估计,第二项是对
进行估计。
5.3.1.1 利用核密度估计估计p(y)
先看对的估计
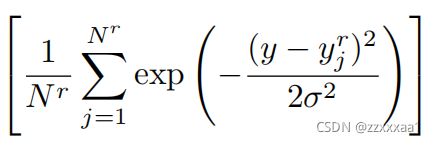
这是一个很典型的用高斯核对进行核密度估计的式子。
我简单阐述一下核密度估计的思想:就是对于每一样本点,都用一个以
为均值的正态分布代替,然后把所有样本点的正态分布累加取平均。这样最终的效果就是越密集的点,由于累加的作用,取值就越大,并且这是平滑的。
5.3.1.2 利用VRM估计p(x|y)
接下来看对的估计
文章上说借鉴了vicinal risk minimization (VRM),但我也不是很懂VRM,所以只能说一下我的看法。
我们先将按照条件概率公式拆成如下的形式:
这里对应
,
对应
,
对应
为了表述清楚,这里举一个例子,我们要求这个点的在p(x|y)的概率密度值。
在经验分布估计中:
而在现在的分布估计中:
注意这个部分是比较关键的。此时我们对p(y)和p(y|x)依然是经验分布估计,但是我们放宽了条件。对于p(y)我们不止求时的概率密度,而是要求
时的概率密度。
同理对于p(y|x),我们不只求这个点的概率密度,而是要求
这个区间的概率密度。
可以发现当,就会退化到经验分布估计。
总的思想就是说在回归标签中,假如两个标签靠得很近,那么它们对应的样本也不会相差太远,
即假如y=15可以作为x1的标签,那么y=15.1也可以作为x1的标签,这个界限通过控制。
5.3.2 HVE下的经验风险函数
至此对数据集分布进行hard vicinal estimate的流程就分析完了,我们可以根据这个新得到的分布求出相应的经验风险函数
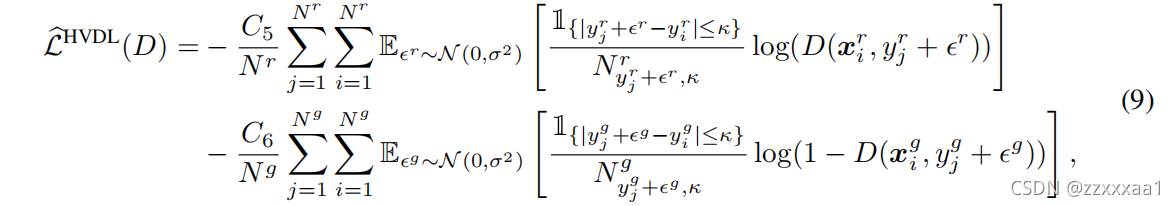
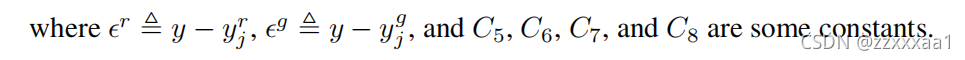
这里文章写的时候似乎有漏掉一个点,就是之所以会有这个正态分布是因为在对标签处理的时候会加上一个噪声。
观察一下这个经验风险函数和之前传统经验风险函数的差别
内层的累加没有变,还是对样本进行累加,但是外层的累加从对标签类型进行累加,改成了直接对所有样本标签累加。
这也很好理解,因为原先必然是对应类别c的,但是回归标签的情况下,只要是在相应标签
旁边都行。所以我们也不能只像原先一样只需要降低
和对应c的损失,只要是和
接近的标签
的损失都需要被降低。
6.CcGAN训练策略
之后考虑一下这样一个经验风险函数要怎么进行实际的训练,因为现在通常采用mini-batch SGD,相当于从训练集中采样B个样本,但是只是采样的话,log前面的系数是算不出来的,我们可以看一下伪代码和源码观察作者具体是怎么做的。

首先是训练判别器:
1、从真实数据集的标签中随机采样个标签
2、给标签集合添加噪声
3、遍历标签集合中的每一个元素
3.1、选择一个图像-标签对(x,y),能够满足,之后用
替换原先的标签y,组成一个新的图像-标签对
放入集合
。我们希望判别器对这个样本判别为真实。
3.2 从的范围内选择一个新的标签
,这个标签对应的x'通过生成器生成
,但是将图像-标签对
放入集合
中。
4、基于集合和
,用判别器的经验风险函数更新判别器。
可以发现在生成图像标签对的时候我们并不将真实标签用于训练,而是用另一个和真实标签比较接近的邻近标签代替。
4是比较重要的但是作者一句话就带过去了,所以我们再去看一下源码。
训练代码在train_ccgan.py这个文件,我这里只截取步骤4的这一部分。
## weight vector
if threshold_type == "soft":
real_weights = torch.exp(-kappa*(batch_real_labels-batch_target_labels)**2).to(device)
fake_weights = torch.exp(-kappa*(batch_fake_labels-batch_target_labels)**2).to(device)
else:
real_weights = torch.ones(batch_size_disc, dtype=torch.float).to(device)
fake_weights = torch.ones(batch_size_disc, dtype=torch.float).to(device)
#end if threshold type
# forward pass
real_dis_out = netD(batch_real_images, batch_target_labels)
fake_dis_out = netD(batch_fake_images.detach(), batch_target_labels)
d_loss = - torch.mean(real_weights.view(-1) * torch.log(real_dis_out.view(-1)+1e-20)) - torch.mean(fake_weights.view(-1) * torch.log(1 - fake_dis_out.view(-1)+1e-20))
optimizerD.zero_grad()
d_loss.backward()
optimizerD.step()
然后你会发现假如threshold_type=="hard",那么除了图像标签对处理部分,d_loss的计算是和传统cGAN的loss的计算是一样。
所以作者的想法就是既然不好算那就不算了,权重都一致就好了。
6.1 SVDL下的权重计算
不过soft还是会算一下系数的,所以之后介绍一下SVDL的思想。
前面我们已经把整个流程都分析过了,我们可以直接看SVDL对应的p(x,y)。
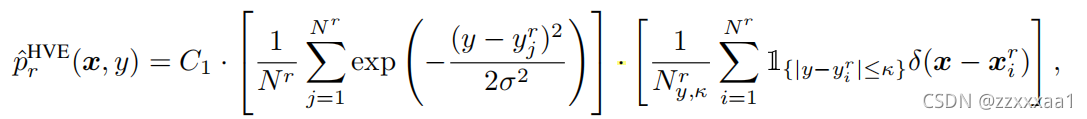
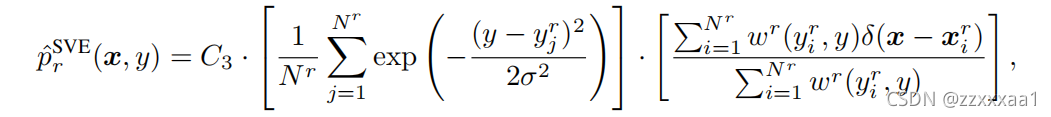
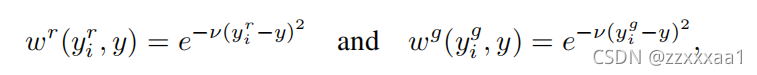
比较一下, 和HVE的差别主要还是前面的系数,想要像核密度估计那样平滑处理,而不是用硬间隔进行隔断。
是一个计算权重的函数,我们观察一下
的含义,当
越接近
,权重越接近1;当
越远离
,权重越接近0。
之后就是SVDL相应的经验风险函数部分。
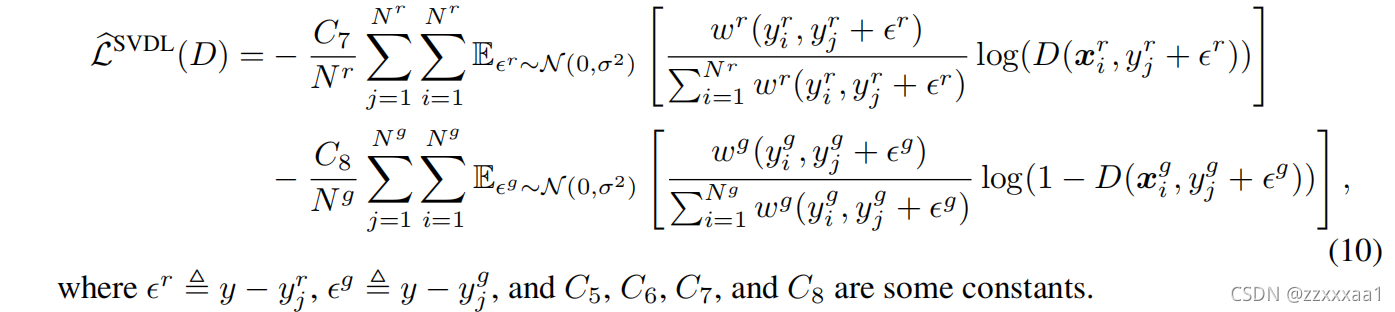
但是我们会发现即使可以算出来,似乎也会比较麻烦,因为这个累加的权重由于y的不同,其实还是需要每个样本都算一遍。
所以观察上面训练代码我们会发现作者对于soft情况,也是直接假设是相同的。只计算了
部分。
7.实验部分
作者基于理论数据集Circular 2-D Gaussians和图片数据集RC-49 and UTKFace都做了实验,对比对象为传统的cGAN。这里就只介绍RC-49的实验部分。
7.1 RC-49数据集
该数据集中的样本为椅子的图像。
标签为椅子的偏转角度。共有49张椅子,每张椅子的共有899张不同偏转角度的图片。偏转角度从0.1°到89.9°,以0.1°为步长。
总样本数为49×899。
7.1.1 实验设置
从偏转角度为奇数的49张椅子中选择25张作为训练集。所以训练集样本总数为25*450。
7.1.2 实验结果
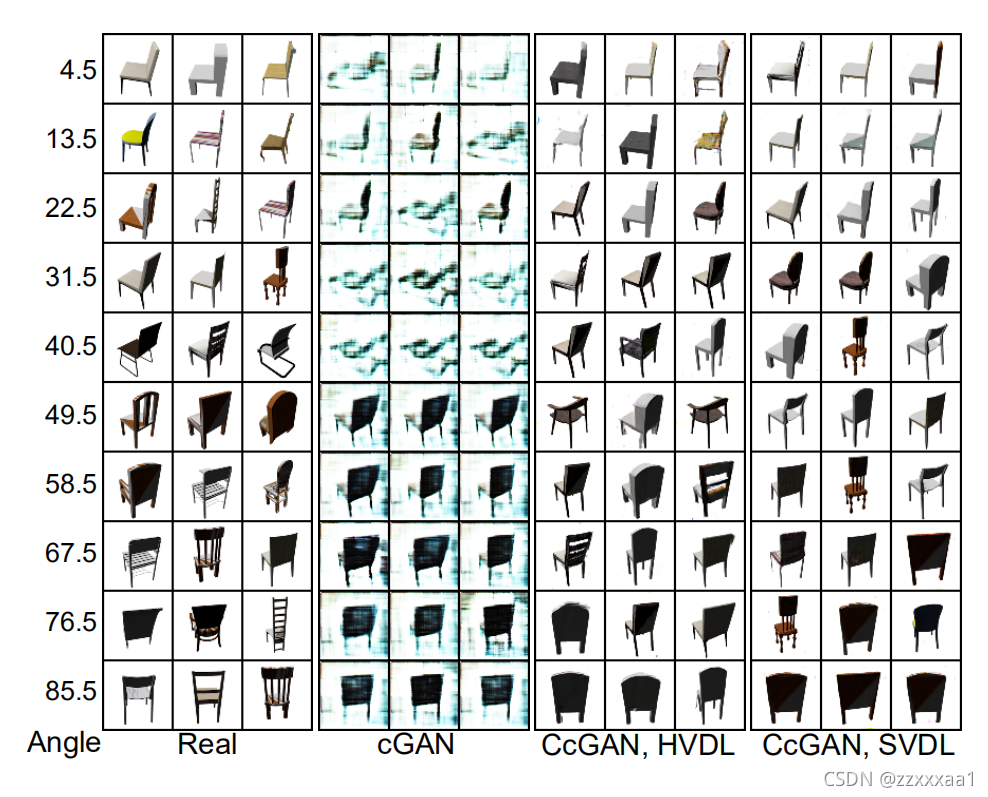
纵坐标为偏转角度。
图片的话就比较直观,cGAN生成的还是比较模糊,CcGAN在两种损失下表现都正常。
8.回归标签的嵌入方式
这里作者也引入了一些启发式的回归标签嵌入方式,放在了附录和github上,我列一下。
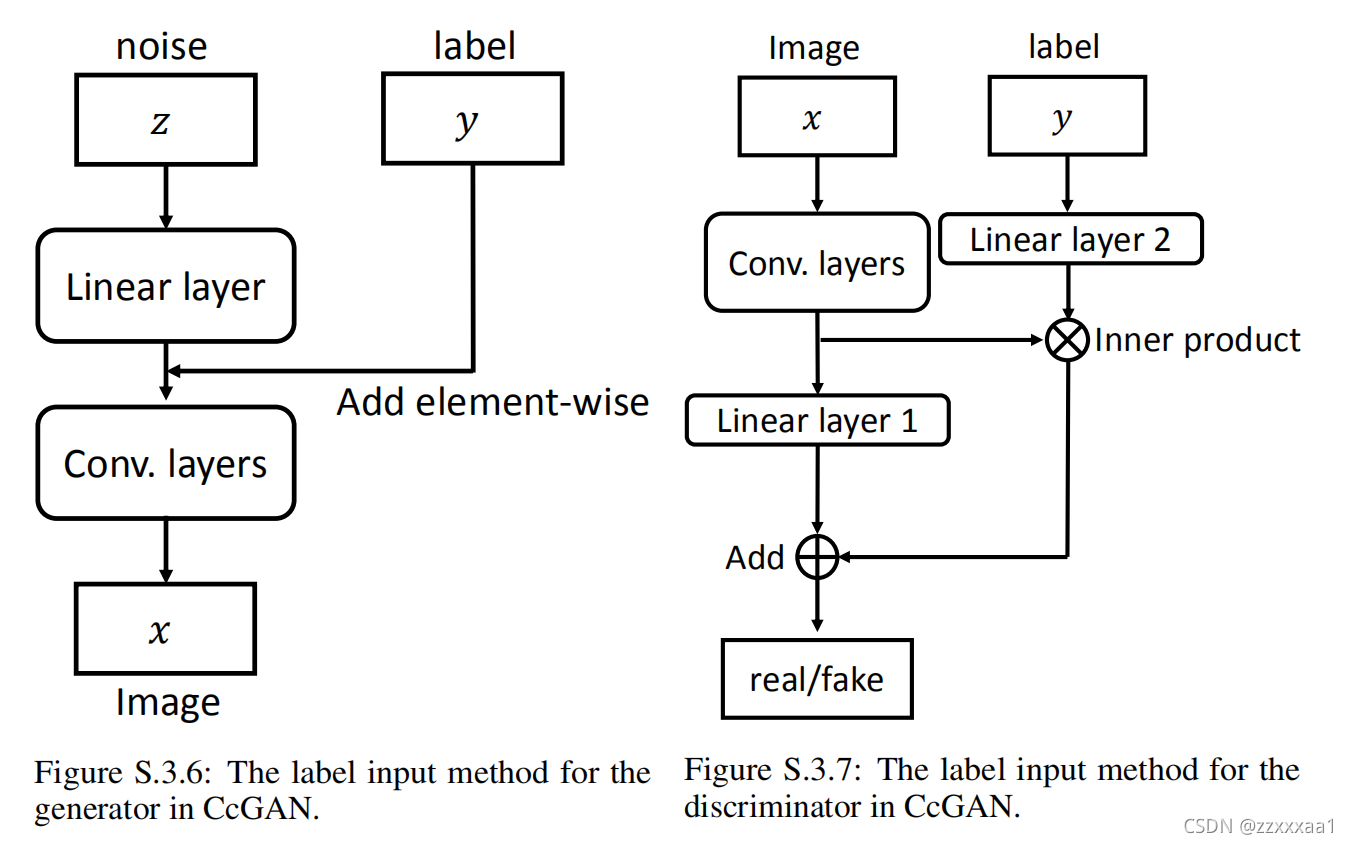
github上改进了嵌入方式,主要就是利用条件批归一化嵌入到网络的多层。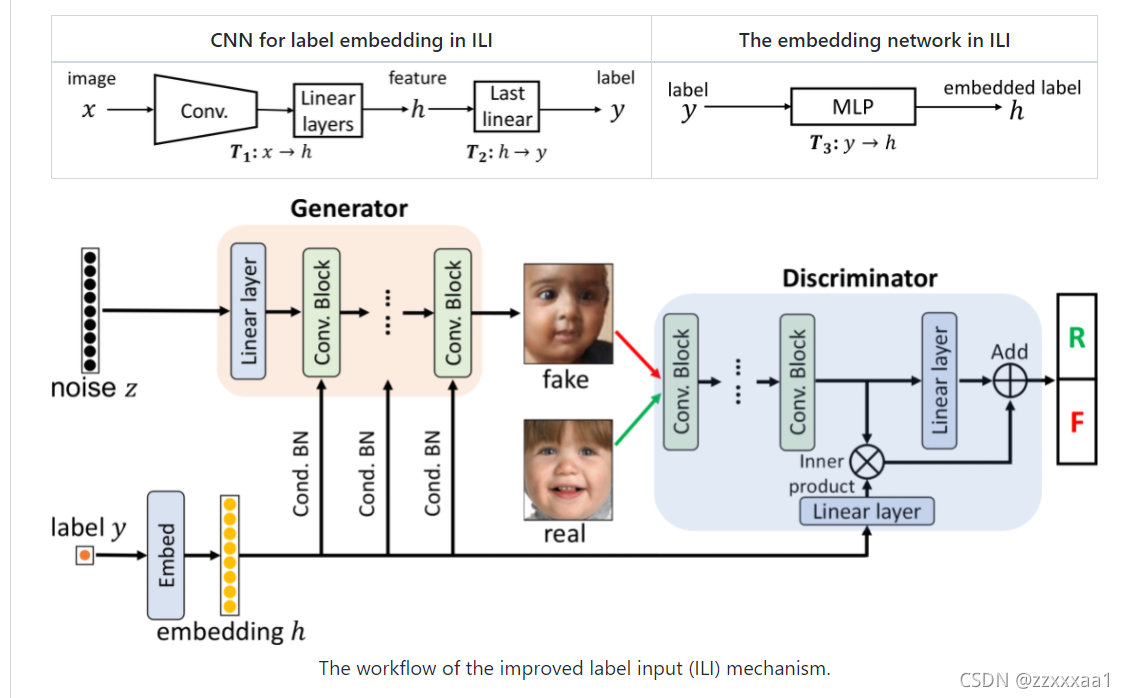
总的来看,标签嵌入其实没有什么理论基础,怎么做都可以,至于好不好还是看实际训练效果。
9.总结
由于涉及到概率以及很多数学公式,假如数学功底不够,CcGAN这篇文章是很难一遍就读懂的,所以假如想读懂,还是建议读者要多读几遍原文。
但是如果只是应用CcGAN其实是比较简单的,只需要在传统cGAN的基础上改变一下标签嵌入方式和训练方式就可以实现HVDL形式的训练。如果在这个基础上再给样本损失算一下权重,就是SVDL了。

















 3177
3177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









