







前言
本课程主要介绍RA/SD软件,顾名思义。我们是基于SD的绘画框架整合的RA产品。全称Paragoger。
这个运行于Windows和Linux的离线工具包,具备强大的文生图,图生文,图生图和部分视频功能能力。
我们的AI训练营致力于使用基于这款软件框架系统的基础上,给到大家AIGC领域的强大能力。
知识点
- 基础的AIGC软件系统能力
- 科普基础的SD软件体系来龙去脉
效果图
- 一个美轮美奂的二次元,动漫古风中国美女

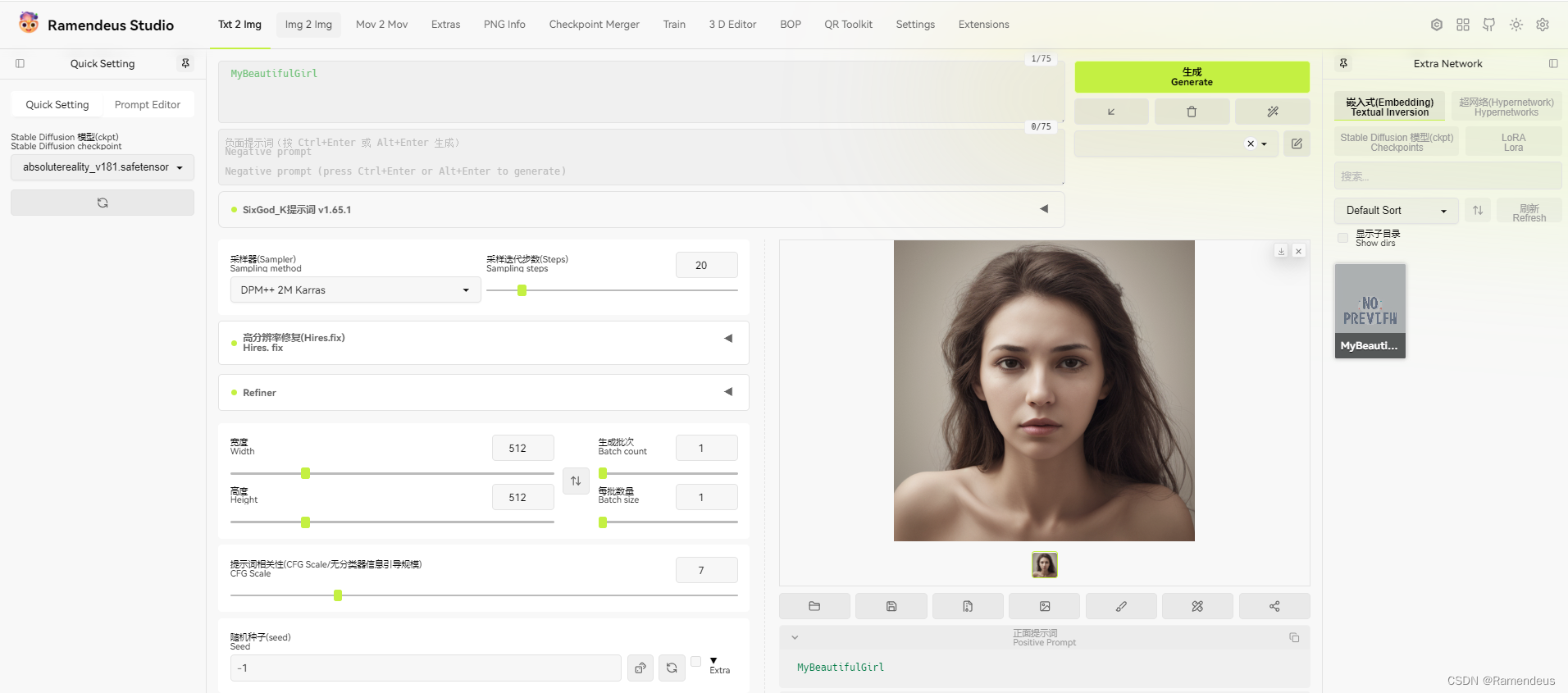
软件主界面
软件正确运行后的主界面如下。
可能在不同的机器上由于显示器分辨率的不同,布局会有所不一样。但是大体是一致的。
基础原理
Stable Diffusion是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像,尽管它也可以应用于其他任务,如内补绘制、外补绘制,以及在提示词指导下产生图生图的转变。
它是一种潜在扩散模型,由慕尼黑大学的CompVis研究团体开发的各种生成性人工神经网络之一。它是由初创公司StabilityAI、CompVis与Runway合作开发,并得到EleutherAI和LAION的支持
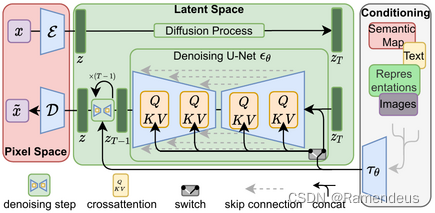
以下是SD的基础架构图。我们的RA/SD 从名字就可以看到是从SD的基础上衍生而来。SD的基本是稳定扩散,而我们RA的基本是稳定持续。
RA的基本内容:
RA大致包含以下一些主要内容和组件:
- 多语言框架和界面,默认中文
- 自定义插件体系,和SD兼容
- 灵活的API能力支持,(此功能基础课程中不会覆盖。)
- 通过内网穿透,FE定制等方式提供云话服务(这个原生SD不同)
- 内置分类整理过的针对性大模型和分级管理评价体系。更方便用于使用。
- 自定义的皮肤,效果,和自定义内容等。RA的界面基本上和SD有很大的差异了。
- 定制的启动器。(QT技术下,我们提供启动器,方便用户一体化更方便高效的管理RA体系)
用法:
Stable Diffusion模型支持通过使用提示词来产生新的图像,描述要包含或省略的元素,以及重新绘制现有的图像,其中包含提示词中描述的新元素(该过程通常被称为“指导性图像合成”(guided image synthesis))通过使用模型的扩散去噪机制(diffusion-denoising mechanism)。 此外,该模型还允许通过提示词在现有的图中进内联补绘制和外补绘制来部分更改,当与支持这种功能的用户界面使用时,其中存在许多不同的开源软件。
Stable Diffusion建议在10GB以上的显存(GDDR或HBM)下运行, 但是显存较少的用户可以选择以float16的精度加载权重,而不是默认的float32,以降低显存使用率。
文生图:
Stable Diffusion中的文生图采样脚本,称为"txt2img",接受一个提示词,以及包括采样器(sampling type),图像尺寸,和随机种子的各种选项参数,并根据模型对提示的解释生成一个图像文件。生成的图像带有不可见的数字水印标签,以允许用户识别由Stable Diffusion生成的图像尽管如果图像被调整大小或旋转,该水印将失去其有效性。 Stable Diffusion模型是在由512×512分辨率图像组成的数据集上训练出来的,这意味着txt2img生成图像的最佳配置也是以512×512的分辨率生成的,偏离这个大小会导致生成输出质量差。Stable Diffusion 2.0版本后来引入了以768×768分辨率图像生成的能力。
每一个txt2img的生成过程都会涉及到一个影响到生成图像的随机种子;用户可以选择随机化种子以探索不同生成结果,或者使用相同的种子来获得与之前生成的图像相同的结果。用户还可以调整采样迭代步数(inference steps);较高的值需要较长的运行时间,但较小的值可能会导致视觉缺陷。 另一个可配置的选项,即无分类指导比例值,允许用户调整提示词的相关性(classifier-free guidance scale value),更具实验性或创造性的用例可以选择较低的值,而旨在获得更具体输出的用例可以使用较高的值。
反向提示词(negative prompt)是包含在Stable Diffusion的一些用户界面软件中的一个功能(包括StabilityAI自己的“Dreamstudio”云端软件即服务模式订阅制服务),它允许用户指定模型在图像生成过程中应该避免的提示,适用于由于用户提供的普通提示词,或者由于模型最初的训练,造成图像输出中出现不良的图像特征,例如畸形手脚。与使用强调符(emphasis marker)相比,使用反向提示词在降低生成不良的图像的频率方面具有高度统计显著的效果;强调符是另一种为提示的部分增加权重的方法,被一些Stable Diffusion的开源实现所利用,在关键词中加入括号以增加或减少强调。
图生图:
Stable Diffusion包括另一个取样脚本,称为"img2img",它接受一个提示词、现有图像的文件路径和0.0到1.0之间的去噪强度,并在原始图像的基础上产生一个新的图像,该图像也具有提示词中提供的元素;去噪强度表示添加到输出图像的噪声量,值越大,图像变化越多,但在语义上可能与提供的提示不一致。 图像升频是img2img的一个潜在用例,除此之外。
2022年11月24日发布的Stable Diffusion 2.0版本包含一个深度引导模型,称为"depth2img",该模型推断所提供的输入图像的深度,并根据提示词和深度信息生成新图像,在新图像中保持原始图像的连贯性和深度。
内补绘制与外补绘制
Stable Diffusion模型的许多不同用户界面软件提供了通过img2img进行图生图的其他用例。内补绘制(inpainting)由用户提供的蒙版描绘的现有图像的一部分,根据所提供的提示词,用新生成的内容填充蒙版的空间。随着Stable Diffusion 2.0版本的发布,StabilityAI同时创建了一个专门针对内补绘制用例的专用模型。相反,外补绘制(outpainting)将图像扩展到其原始尺寸之外,用根据所提供的提示词生成的内容来填补以前的空白空间。
社会影响
由于艺术风格和构图不受著作权保护,因此通常认为使用Stable Diffusion生成艺术品图像的用户不应被视为侵犯视觉相似作品的著作权,绝大部分的画作作者也没有授权允许用他们的作品训练ai,这将导致画师的失业。如果生成的图像中所描述的真人被使用,他们仍然受到人格权的保护,而且诸如可识别的品牌标识等知识产权仍然受到著作权保护。尽管如此,艺术家们表示担心Stable Diffusion等模型的广泛使用最终可能导致人类艺术家以及摄影师、模特、电影摄影师和演员逐渐失去与基于人工智能的竞争对手的商业可行性。
与其他公司的类似机器学习图像合成产品相比,Stable Diffusion在用户可能产生的内容类型方面明显更加宽容,例如暴力或性暴露的图像。
StabilityAI的首席执行官Emad Mostaque解决了该模型可能被用于滥用目的的担忧,他解释说:“人们有责任了解他们在操作这项技术时是否符合道德、道德和法律”,将Stable Diffusion的能力交到公众手中会使该技术在整体上提供净收益,即使有潜在的负面后果。此外,Mostaque认为,Stable Diffusion的开放可用性背后的意图是结束大公司对此类技术的控制和主导地位,他们之前只开发了封闭的人工智能系统进行图像合成。















 404
404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









