






前言
上一章,我们介绍如何用提示词引导系数和CFG修复插件。
本章,我们介绍如何随机种子
种子是个比较形象的翻译描述,在计算机的系统中有个随机因子的概念,为了确保每一次的生成算法中有不同的表现,加入这个因子,或者种子的操作能力。
在RA/SD的体系中,界面上提供了这样的一个方法去手动控制。一般的我们也会用这个Seed种子来确定生成同一个图片所需要的随机因此,确保能够大概率还原之前生成图片的其余参数的影响范围。
在C站中你可以看到很多图片效果生成中会写上使用的种子的数据。
知识点
- 随机种子
基础知识
“Seed”(种子)是一个用于控制随机数生成过程的初始值。通过设置特定的种子值,可以确保模型在多次运行时生成一致的输出。这在图像生成、机器学习实验和其他需要再现性和一致性的任务中非常重要。
Seed 的作用和重要性
- 再现性(Reproducibility):种子值使得随机过程可以被精确地重复。如果你使用相同的种子值和相同的输入条件(如文本提示),RA/SD 将生成相同的图像。这对于调试和研究非常重要,因为可以确保结果的一致性。
- 实验控制:在对比实验或调优过程中,使用相同的种子值可以确保实验条件一致,仅测试其他变量的影响。这样可以更准确地评估模型参数或条件的影响。
- 多样性生成:通过改变种子值,可以生成不同的图像。虽然输入条件(如文本提示)相同,但不同的种子值会引导模型生成不同的细节和结构。这对于生成多样化的样本和探索模型的生成能力非常有用。
Seed 的工作原理
在计算机中,许多随机数生成器(Random Number Generators, RNG)是伪随机的,它们实际上是确定性算法,生成的数字序列取决于初始种子值。以下是Seed在RA/SD中的典型工作流程:
- 设定种子值:在生成图像之前,用户可以指定一个种子值。例如:seed = 42。
- 初始化随机数生成器:随机数生成器使用指定的种子值初始化,确保后续的随机过程是确定性的。
- 生成过程:模型在生成图像时会依赖于初始化的随机数生成器。每次生成的随机数序列将引导模型生成不同的图像细节。
- 生成图像:结果图像的生成是由指定种子值和输入条件共同决定的。相同的种子值和相同的输入条件会生成相同的图像。
随机种子
在文生图和图生图中都有随机种子(seed)的这个功能,随机种子(seed)有2种使用方法。
1、当随机种子为-1时,则是未使用种子,后续出图都是随机状态;
2、我们也可以填入随机种子(每张通过SD生成的图片都会有一个随机种子seed),填入随机种子后,后续生成的图片都会参考这个种子进行生成。
所以随机种子(seed)的用途就是固定生成图片过程中所产生的随机数,从而在下次生成图片时最大限度的进行还原。
当然即使我们使用了随机种子也不能做到100%的还原,最多算是一种参考,因为随机种子虽然固定了随机数,但是算法本身就有随机性,就算使用了随机种子还是会因为随机性带来生成图片的偏差,所以随机种子只能最大限度的降低随机性。
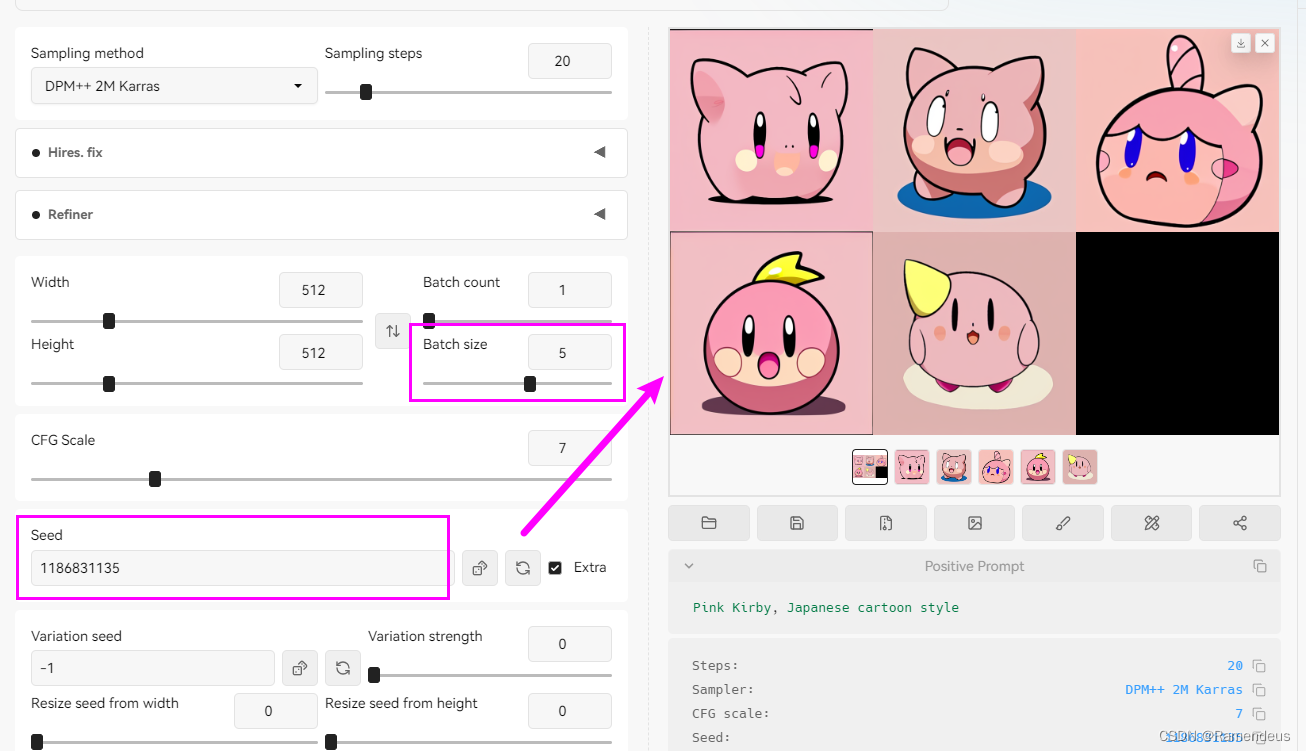
可以再CFG Scale下面看到随机种子(seed),当我们未填写随机种子时为-1,右侧骰子点击后能快速恢复到-1状态;
绿色图标点击后能获取到右侧已生成图片的随机种子(若右侧无图片,点击后则获得到-1)。
点开勾选项后,能看到一个使用频次相对较低的功能:差异随机种子,差异随机种子种可以再填写一个种子,与随机种子共同进行图片生成。
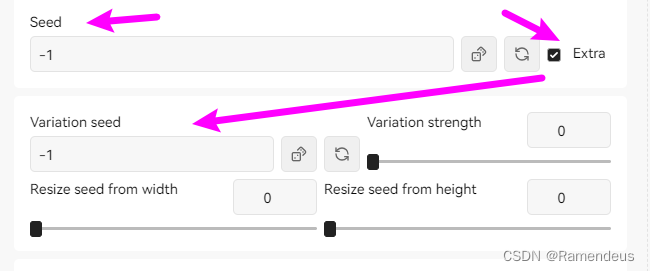
差异随机种子,其实就是提供了另外一个参考,
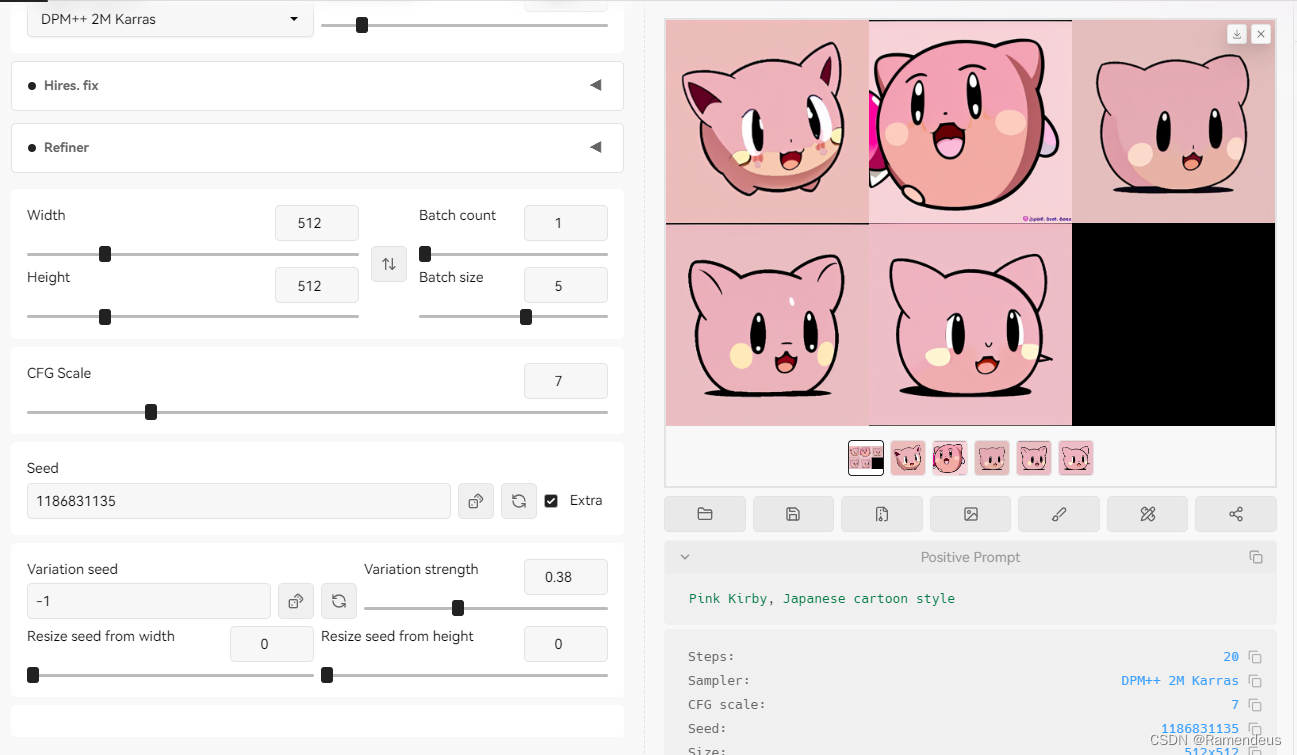
通过差异随机种子可以让生成的图片有更多变化。我们把随机种子标注为1,差异随机种子标注为2,差异强度越靠近左侧生成的图片越像1,差异强度调整到右侧就越像2;
下图中我们调整到0.38查看效果。看上去很相似。
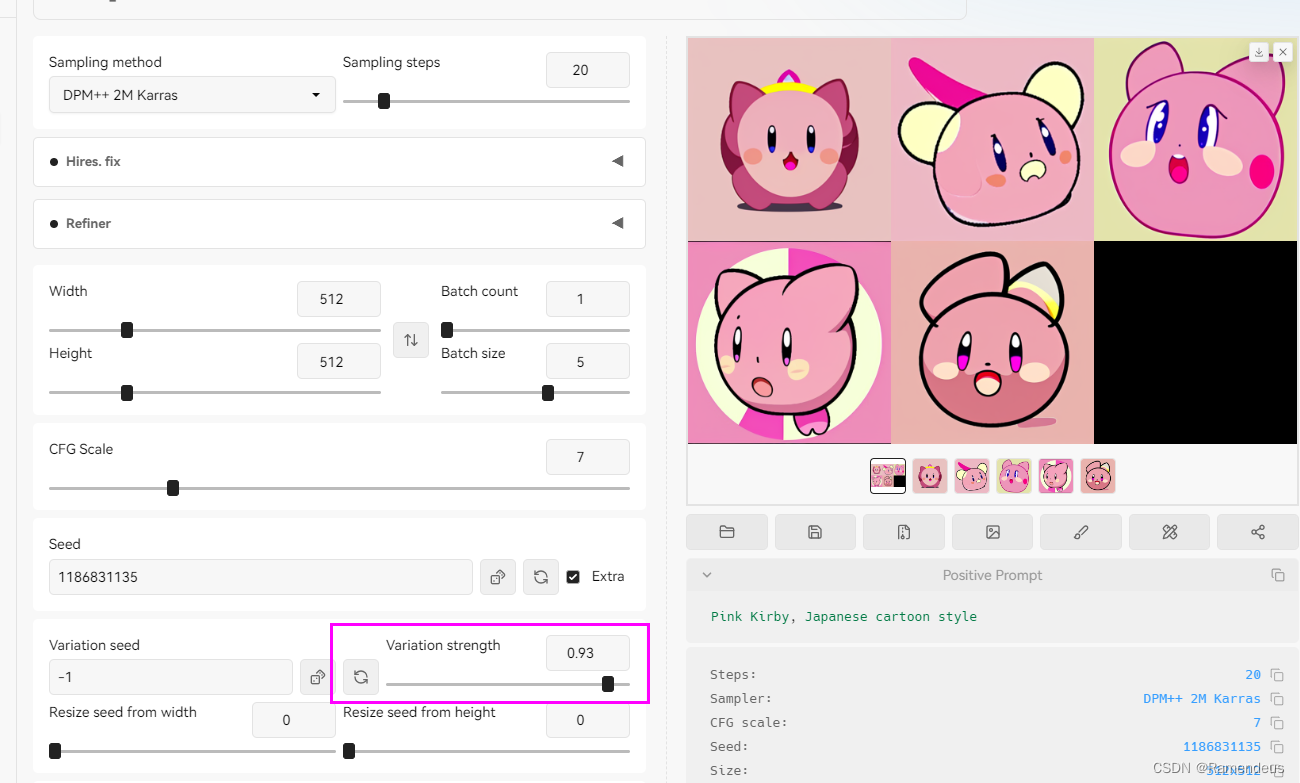
调整大该值,发现越来越不相似了。
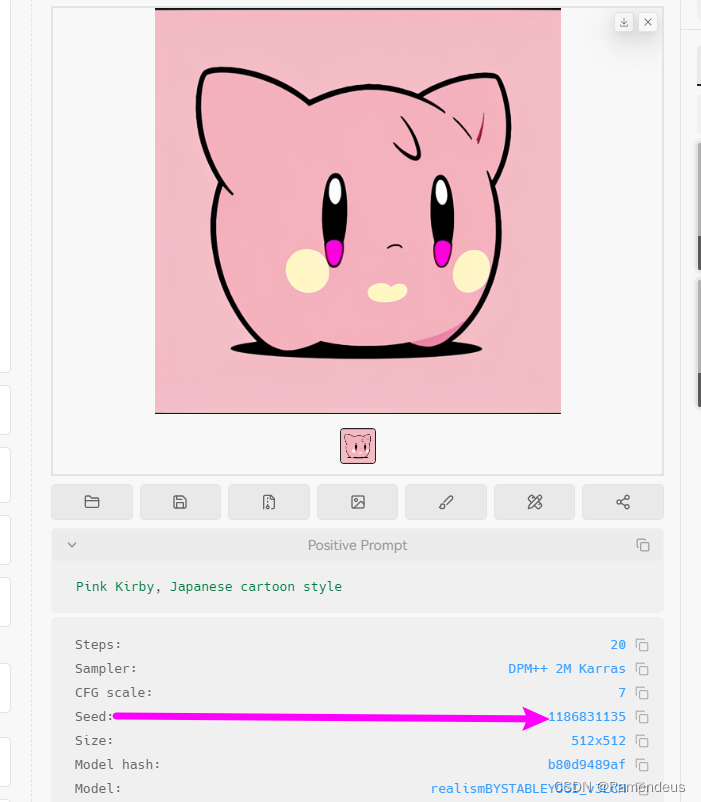
我们实际操作一下,使用一段Prompt来生成一个图片,生成图片后,我们在下方图片信息中可以看到,其中有一段文字,其中就有Seed: 69691308,这就是这个图片的随机种子。
填入随机种子后,我们再进行图片生成就可以发现,后续的图片整体风格、造型上都已随机种子应对的图片相接近,但也不是100%相同。
基于这个原理,一旦我们生成了一张较为满意的图片后,可以使用这个图片的随机种子快速生成一批图片,从中挑选出最满意的一张。
如何取得图片的随机种子
只要是通过SD生成的图片,我们只需要使用Stable-Diffusion-webui中图片信息功能,也可以读取到图片对应的随机种子(seed),我们复制这个随机种子:1904432137,
我们可以把随机种子填入到差异随机种子中,跳转差异强度值(数值越高参考差异随机种子越多!)
此外差异随机种子中的宽度和高度,若修改后会改变原尺寸的设定,这里建议不做调整,设置为0即可。
总结
随机种子,是我们在生成具体内容的重要一个参数,虽然没有很大的意义,但是给了我们一种随机操作最终生成物的能力。非常简单,但非常有用。
创作不易,觉得不错的话,点个赞吧!!!

















 493
493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









