








路径优化系列文章:
- 1、路径优化历史文章
- 2、物流中心选址问题论文复现丨改进蜘蛛猴算法求解
物流中心选址问题
一般物流中心选址问题是指:在有限的用户(即需求点)中找出一定数量的地点建立配送中心,实现从物流中心到用户之间的配送,使得各配送中心到由它配送用户的需求量与距离的乘积之和最小。
本文假设:
(1)不考虑物流中心的规模及经济问题;
(2)配送中心必须满足所有位置的需求;
(3)不考虑其他费用。
模型
推文的测试模型包括基准函数和中心选择问题,以下是5个基准函数,可以任意增加:

在文件HS:
基准函数纬度n目前设置为20,可修改。
物流中心选址问题的目标函数和约束见参考文献:

数据
论文数据,31个城市选6个中心的数据(复制pdf数据到txt):
1 (1304,2312) 20 17 (3918,2179) 90
2 (3639,1315) 90 18 (4061,2370) 70
3 (4177,2244) 90 19 (3780,2212) 100
4 (3712,1399) 60 20 (3676,2578) 50
5 (3757,1187) 70 21 (4029,2838) 50
6 (3326,1556) 70 22 (4263,2931) 50
7 (3238,1229) 40 23 (3429,1908) 80
8 (4196,1044) 90 24 (3507,2376) 70
9 (4312,790) 90 25 (3394,2643) 80
10 (4386,570) 70 26 (3439,3201) 40
11 (3007,1970) 60 27 (2935,3240) 40
12 (2562,1756) 40 28 (3140,3550) 60
13 (2788,1491) 40 29 (2545,2357) 70
14 (2381,1676) 40 30 (2778,2826) 50
15 (1332,695) 20 31 (2370,2975) 30
16 (3715,1678) 80
按行和空格拆分数据,具体读取在文件read_decode_paint。
编码解码
编码
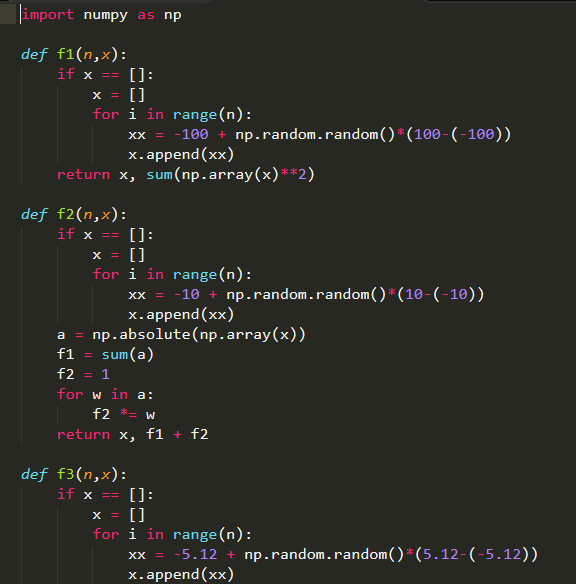
基准函数和选址问题都需要生成指定纬度下的随机初始解,2-16生成方式:
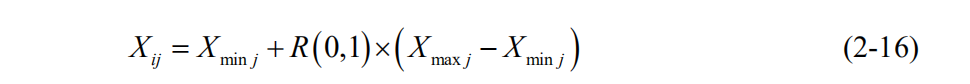
基准的最大最小值见函数定义域,对于选址问题,设置最大值为1,最小值为0。
选址问题的初始解还需转换编码:

这其中会出现问题,候选中心数大于或小于设定值。文献是选择6个点,当编码1的计数大于或者小于6,是非可行解,需要修正解。
修正方法:大于6个点时,排序编码x的所有基因值,更正最大6个以外的1为0;小于6个点时,排序编码x的所有基因值,更正不足6个外的0为1.。
如3个点选择2个中心
x=[0.6,0.55,0.8],转换编码 y=[1,1,1],修正编码为y= [1,0,1],保留最大2个,0.55对应的1修正为0
x=[0.35,0.4,0.8],转换编码 y=[0,0,1],修正编码为y= [0,1,1],补充次大的1个,0.4对应的0修正为1
核心代码:
def f_xuan(n,num,x):
if x==[]: # 为空时生成初始解
x = []
for i in range(n):
xx = np.random.random() # 0到1生成初始解
x.append(xx)
y = []
for xx in x: # 编码转化为0,1
if xx < .5:
y.append(0)
else:
y.append(1)
idx = np.array(x).argsort() # 排序x
y1 = np.array(y)
if sum(y)<num: # 如果1的计数小于候选数,补充1
y1[idx[-num:]] = 1
else: # 否则删除1
y1[idx[:-num]] = 0
return x, y1.tolist()
解码
基准函数解码较为简单,新解传入对应函数就能返回目标。选址问题设计1种贪婪选择策略:对于每个点,计算点到所有候选中心的距离与需求量的乘积,选择乘积最小对应的中心:
代码如下:
def decode(y,inf):
center_idx = [i for i in range(len(y)) if y[i] == 1] # 候选位置读取
center_road = [[] for i in range(len(center_idx))]
f = 0
for w in range(len(y)):
if y[w] == 0:
disdemand = [np.sqrt((inf[w][0]-inf[c][0])**2 + (inf[w][1]-inf[c][1])**2)*inf[w][2] for c in center_idx]
f += min(disdemand) # 目标更新
idx = disdemand.index(min(disdemand)) # 最小目标对应的候选中心
center_road[idx].append(w) # 对应候选中心加入点
改进算法
算法步骤
Step 1. 设置参数。种群规模 P ,最大迭代次数 N ,干扰率 pr ,最大组数 MG ,全局 领导限制 gll,局部领导限制lll ,指引因子最大值cmax 及最小值cmin ,变异概率β。
Step 2. 用公式(2-16)生成群体中所有蜘蛛猴的初始位置。然后对每个蜘蛛猴的适应度值 进行计算并排序,选出局部和全局领导者。
Step 3. 当不满足终止条件时,执行以下步骤:
Step 3.1. 为了寻找最优解,利用(3-2)式产生新的位置;结合每只猴子适应性的大小择 优选出适宜的位置。
Step 3.2. 根据(2-19)式,得出全部组中个体被筛选的可能性;然后利用(3-4)式将选中的 蜘蛛猴进行位置更新。
Step 3.3. 对全部组的猴子筛选,选出局部及全局指引者的位置。
Step 3.4. 如果任何一个局部指引者在指定次数(即局部指引限制lll )没有更新其位置,那 么局部指引者会再次带领该组全部猴子寻找食物,根据扰动率 pr 的大小采取式(2-21)来更 新它们的位置。
Step 3.5. 执行 Cauchy 变异操作,根据式(3-5)更新蜘蛛猴的位置,选出较优的位置。
Step 3.6. 如果全局指引者在指定次数(即全局领导限制 gll )没有更新其位置,且此时没有达到最大组数 MG ,最优指引者会将群体进行分组;否则,最优指引者会把全部小组并 为一组。
3-2更新方式:
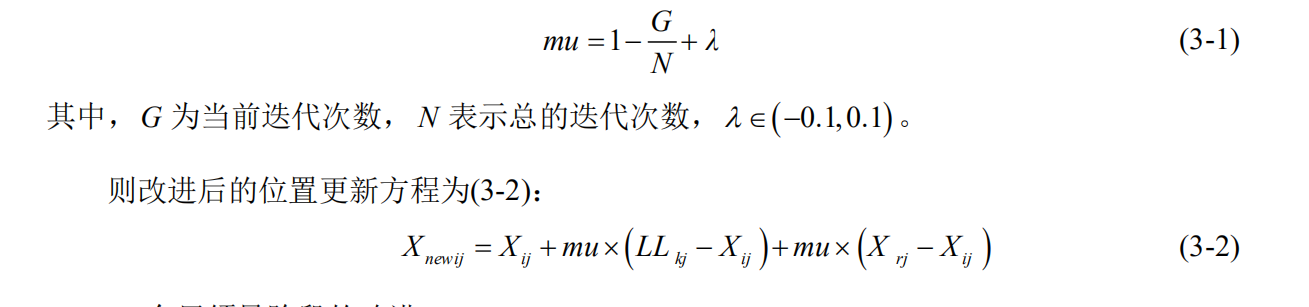
代码没有加λ,可以自行调整。
3-4更新方式:
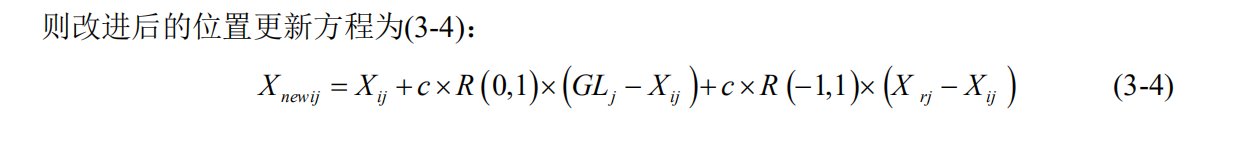
3-5更新方式:

核心代码:
for g in range(self.N):
if g == 0:
Total_x, answer = self.creat(wd, hs) # 2-16生成初始位置
best_idx = answer.index(min(answer))
gbest, pbest = Total_x[best_idx], Total_x[best_idx] # 初始全局和局部领导者
pbidx = [best_idx]
pbcount = [0]
result[0].append(g)
result[1].append(min(answer))
for w in range(self.P):
r = np.random.randint(0, self.P) # 随机选择索引
xr = Total_x[r]
x = Total_x[w]
mu = 1 - g/self.N
xnew = x + mu*(pbest - x) + mu*(xr - x) # 3-2更新方式
prob = .9*(answer[w]/max(answer)) + .1
if np.random.random() < prob: # 2-19方法概率计算,
x = xnew
f = answer[w]
fmin = min(answer)
fave = sum(answer)/len(answer)
if f<= fave:
c = self.cmin + (self.cmax-self.cmin)/(fave - fmin)*(f - fmin) # c值计算方式
else:
c = self.cmax
xnew = x + c*np.random.random()*(gbest - x) + c*np.random.uniform(-1,1)*(xr - x)
# 3-4计算方式
if hs == 'f_xuan':
x, y = rdp.f_xuan(31,6,xnew)
center_road,center_idx,f = rdp.decode(y,inf)
else:
x1, f = eval(f'HS.{hs}({wd},{xnew.tolist()})')
if f < answer[w]: # 新解优于原解时更新
Total_x[w] = xnew
answer[w] = f
best_idx1 = answer.index(min(answer))
if best_idx1 == best_idx: # 全局最优位置不变时,gl加1
gl += 1
else: # 否则归0
gl = 0
lenth = int(self.P/len(pbidx)) # 目前的组数
for w in range(len(pbidx)):
pbans = answer[lenth*w:lenth*(w+1)] # 截取每个组的目标
pbid = pbans.index(min(pbans)) # 每个组的最优解(局部领导)
if pbid == pbidx[w]: # 局部领导位置不变时,该位置计数加1
pbcount[w] += 1
else: # 否则归零
pbcount[w] = 0
if pbcount[w] == self.lll: # 如果达到局部领导限制
for k in range(lenth):
if np.random.random() < pr: # 一定概率下随机生成初始解
xnew, f = eval(f'HS.{hs}({wd},[])')
else:
r = np.random.randint(0, P) # 否则随机选择索引
xr = Total_x[r]
x = Total_x[w]
xnew = x + np.random.random()*(pbest - x) + np.random.random()*(xr - x) # 2-21更新方式
f = HS.f1c(xnew)
Total_x[lenth*w + k] = xnew
answer[lenth*w + k] = f
for w in range(self.P): # Cauchy 变异操作
x = Total_x[w]
if np.random.random() < self.β:
a = 2*(1- g/self.N)
xnew = x + a*math.tan(np.pi*(np.random.random() - .5)) # 3-5更新方式
else:
xnew = x
if hs == 'f_xuan':
x, y = rdp.f_xuan(31,6,xnew)
center_road,center_idx,f = rdp.decode(y,inf)
else:
x1, f = eval(f'HS.{hs}({wd},{xnew.tolist()})')
if f < answer[w]: # 新解优于原解时更新
Total_x[w] = xnew
answer[w] = f
if gl == self.gll: # 如果到达全局领导限制,组数加1
mg += 1
if mg == self.MG: # 如果组数到达限制,归1,全局领导和局部领导相同
mg = 1
best_idx = answer.index(min(answer))
pbidx = [best_idx]
else: # 没到达组数限制时
pbidx = []
lenth = int(self.P/mg) # 新的组数(+1)对应的组长度
pbcount = []
for mgg in range(mg):
pbans = answer[lenth*mgg:lenth*(mgg+1)] # 组长度对应的目标
bid = pbans.index(min(pbans)) # 局部领导位置
pbidx.append(bid)
pbcount.append(0) # 局部领导位置计数
结果
代码运行环境
windows系统,python3.6.0,第三方库及版本号如下:
matplotlib (3.3.4)
numpy (1.19.5)
pandas (1.1.5)
xlrd (1.2.0)
XlsxWriter (3.0.3)
第三方库需要在安装完python之后,额外安装,以前文章有讲述过安装第三方库的解决办法。
主函数
设计主函数如下:
from cmasmo import CMASMO
import paint
import HS
import read_decode_paint as rdp
import numpy as np
P = 50 # 种群规模
N = 1000 # 迭代次数
pr = .5 # 扰动率
MG = 5 # 最大组数
gll = 50 # 全局领导限制
lll = 1500 # 局部领导限制
cmax = .8 # 最高学习因子
cmin = .3 # 最低学习因子
β = .8 # 变异概率
wd = 20 # 函数纬度,目前是20
hs = 'f1' # 函数:f1到f5 和 f_xuan
if hs == 'f_xuan': # 选址问题视数据而定,目前是31
wd = 31
cm = CMASMO(P, N, pr, MG, gll, lll, cmax, cmin, β)
x,result = cm.total(wd, hs)
print('*'*20)
if hs == 'f_xuan':
inf = rdp.get()
x, y = rdp.f_xuan(31,6,x) # 目前是31点选择6个中心,修正时cmasmo对应行也修正
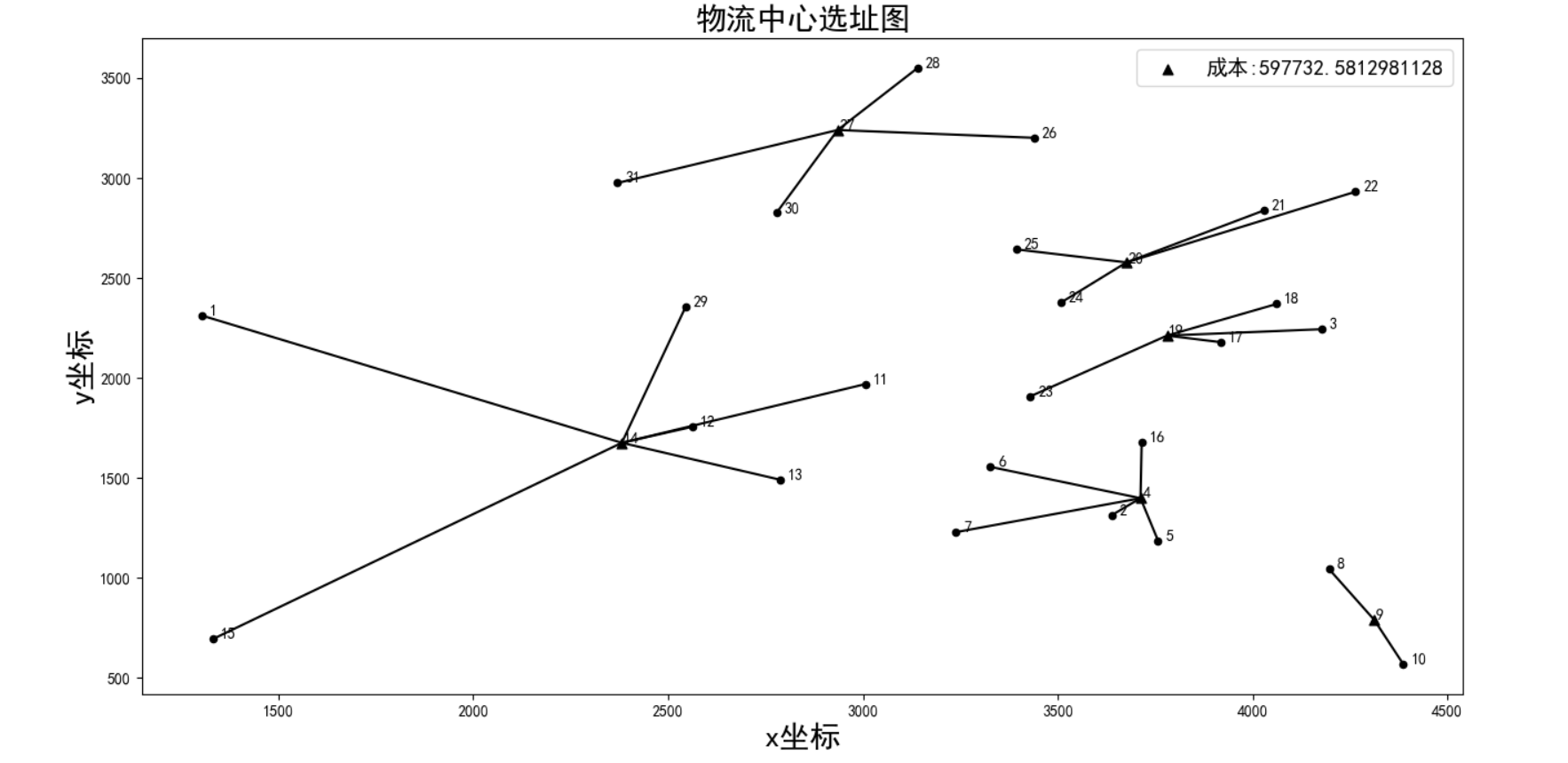
center_road,center_idx,f = rdp.decode(y,inf)
print('选择中心编码:',y)
print('对应点:',np.array(center_idx)+1)
print('目标:',f)
rdp.draw(center_road,center_idx,f,inf)
else:
x1, f = eval(f'HS.{hs}({wd},{x})')
print('函数解:',x)
print('目标:',f)
rdp.draw_change(result)
运行结果
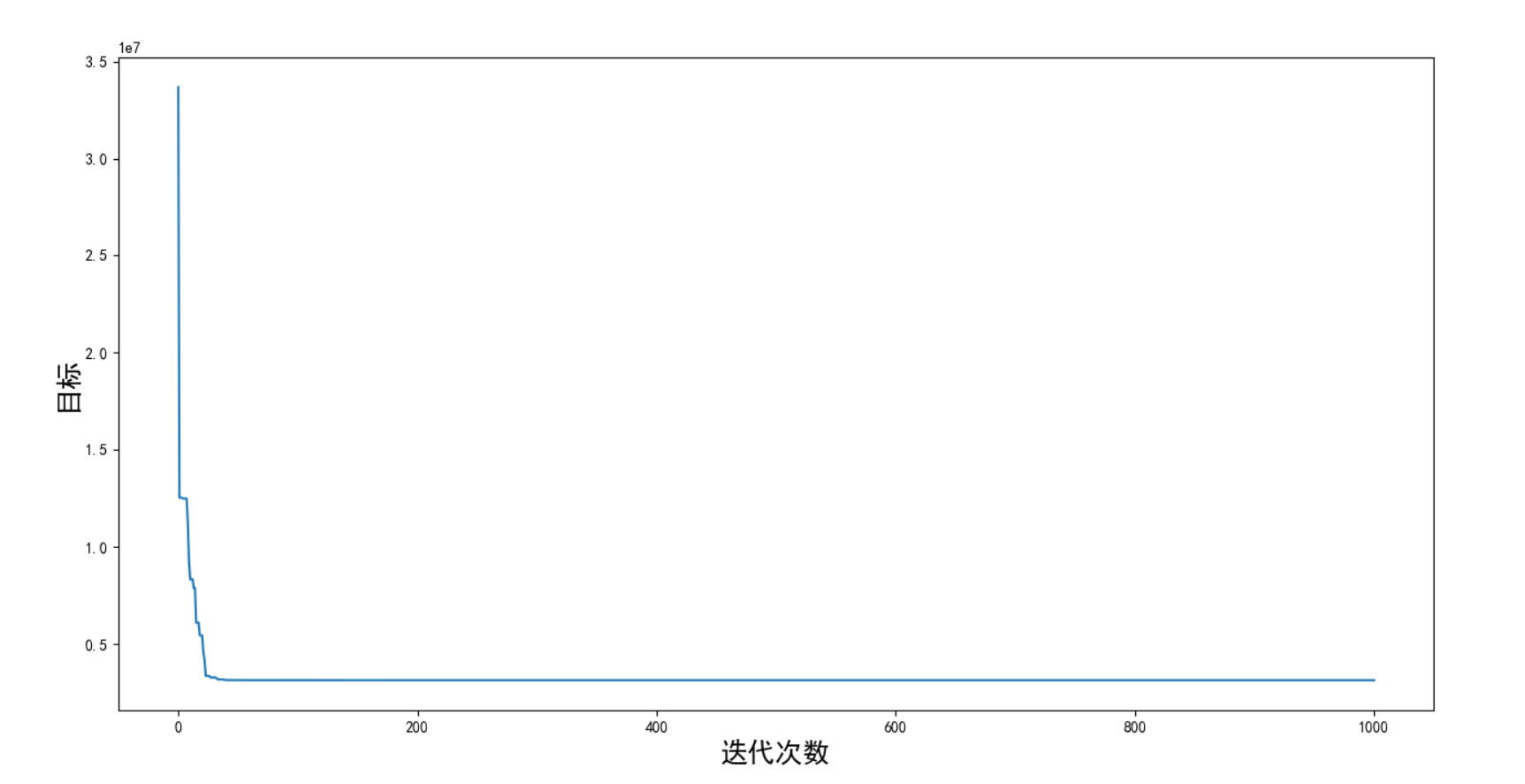
f1结果如下:
f1目标随迭代次数的变化图如下:
f2目标随迭代次数的变化图如下:

f3目标随迭代次数的变化图如下:
f4目标随迭代次数的变化图如下:
f5目标随迭代次数的变化图如下:
f_xuan结果如下:
选址图
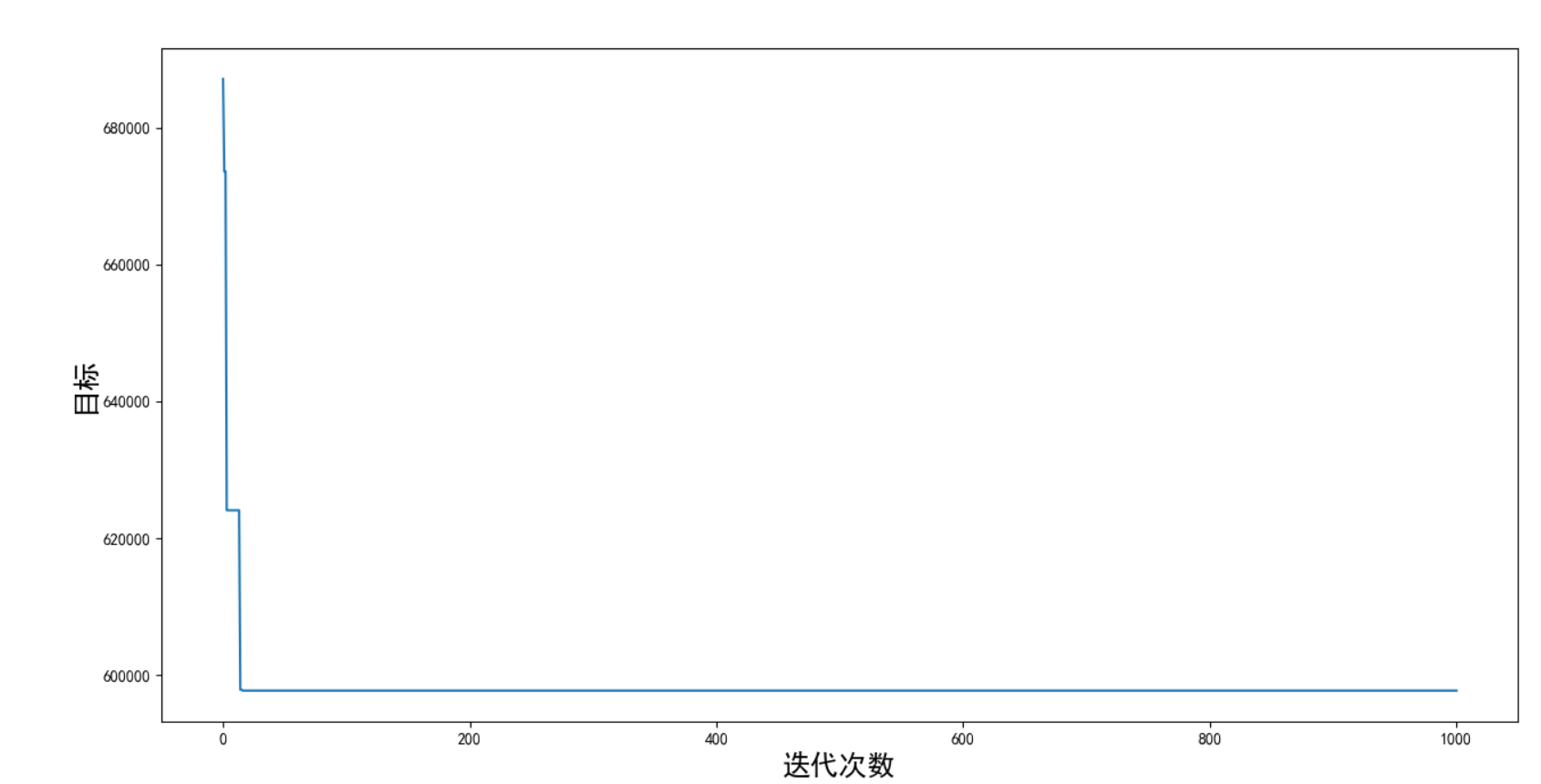
f_xuan目标随迭代次数的变化图如下:
结论
-
本推文主要是对参考论文进行复现,为了解可行设计了选址中心的编码修正方式,为了求解效率设计了贪婪的中心选择方式。其中基准函数容易陷入局部最优,可从算法参数、算法流程、初始解或者函数定义域等进行优化,基准函数目前是5个,其余的可自行在HS添加。
-
数据和算法皆可修改(修改选址数据时,其一行包含1个或者2个点的相关数据,否则报错,中心点和选择个数在main和cmasmo都需修改)。
-
参考文献:蜘蛛猴算法的改进及其在物流中心选址问题中的应用_杨转(第3章)
代码
为了方便和便于修改和测试,把代码在4个py文件里。
演示视频:
论文复现丨物流中心选址问题:蜘蛛猴算法求解















 6103
6103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









