






R语言中存在两种代码风格:一种是以基础包为代表的原生风格,可称为base R;另外一种风格以tidyverse家族的工具包为代表,可称为tidy R。后者的优点自不必多说,但前者亦仍有可取之处,如速度更快、不需要额外加载工具包、易于理解等。本篇主要介绍一些能使base R的代码更接近tidy R风格的函数,从中可以发现两种风格也并不是完全割裂的。
本篇目录如下:
0 引言
1 with函数
2 within函数
3 transform函数
4 attach和detach函数
5 应用
0 引言
在base R中,对于需要引用的对象,如果是在全局环境中,直接使用对象名称即可,若是在数据环境中,还需使用$符号在对象名称前加上数据集名称,如mtcars$mpg。相比之下,tidy风格要简约得多。
全局环境如下:
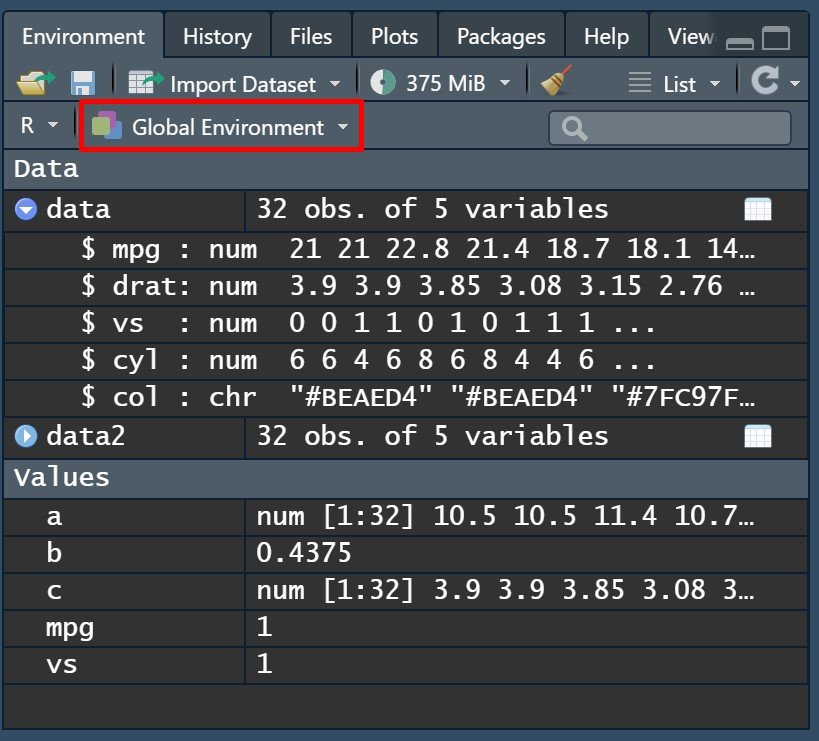
数据环境如下:
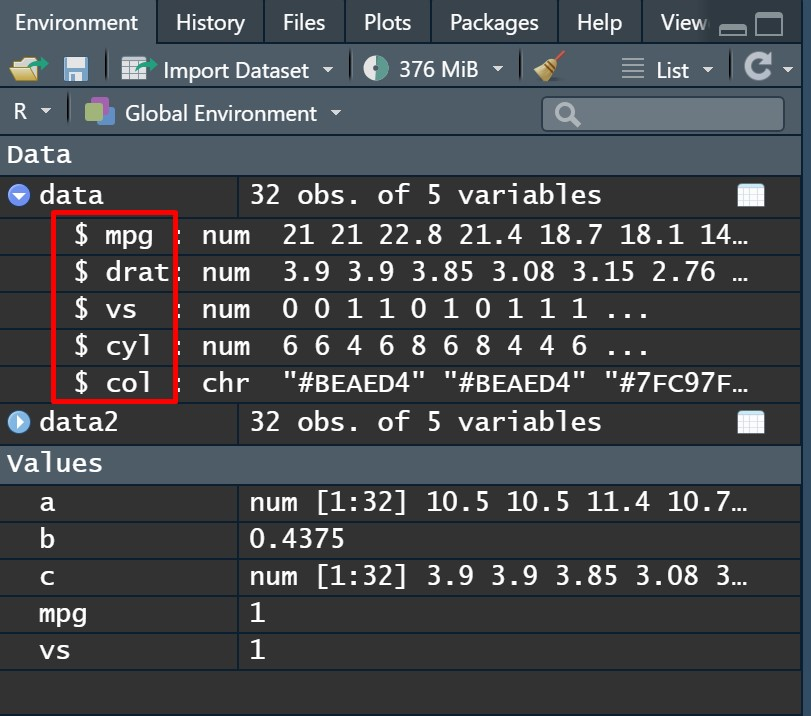
其实在base R中,也有一些函数本身就支持直接引用数据环境中的变量。比如用于分类汇总的aggregate()函数:
aggregate(mpg ~ vs, FUN = "mean",
data = mtcars)
## vs mpg
## 1 0 16.61667
## 2 1 24.55714用于绘图的plot()函数:
plot(mpg ~ drat, data = mtcars)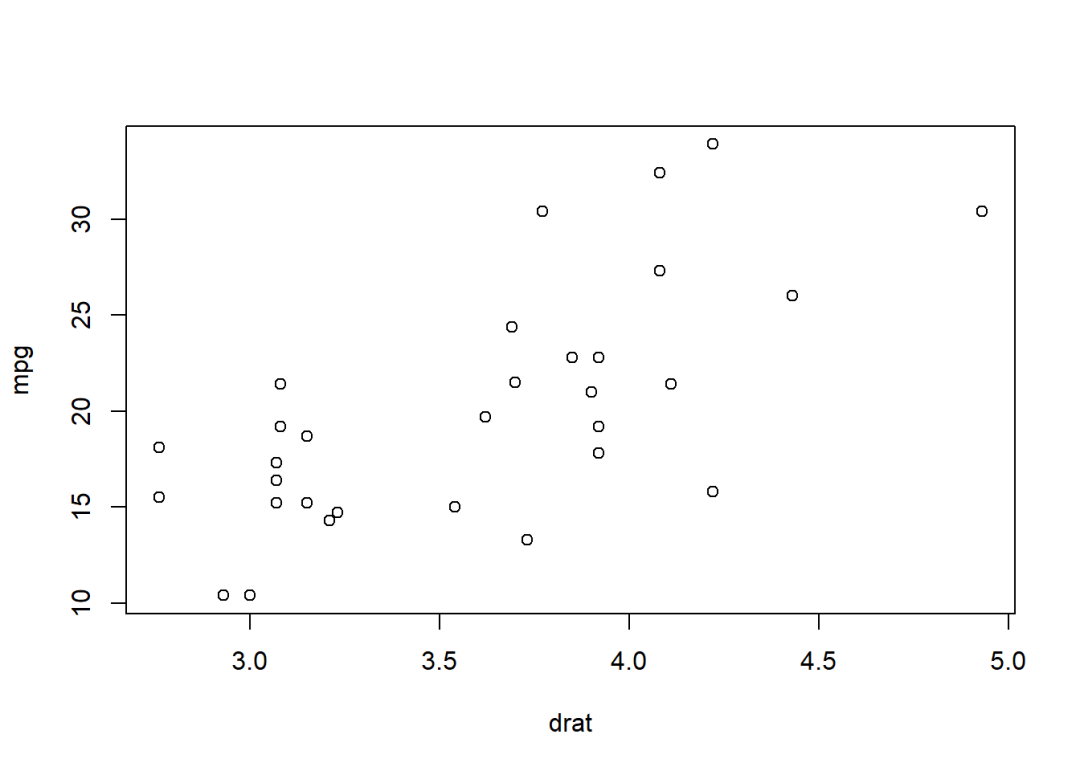
这种方法调用变量时一般需要使用公式形式y ~ x才能奏效。比如下面没有使用这种形式的代码就会报错,此时函数只会在全局环境中搜索对象:
aggregate(x = mpg, by = list(vs), FUN = "mean",
data = mtcars)
## Error in aggregate(x = mpg, by = list(vs), FUN = "mean", data = mtcars) :
## object 'mpg' not found正确用法需要添加数据集名称,代码因此繁琐了许多:
aggregate(x = mtcars$mpg, by = list(mtcars$vs), FUN = "mean")
## Group.1 x
## 1 0 16.61667
## 2 1 24.55714对于上面的问题,base R是有解决办法的,具体参见以下函数的用法。
1 with函数
with()函数的语法结构如下:
with(data, expr, ...)可以将上节的代码改写成如下形式:
with(mtcars, aggregate(mpg, list(vs),
FUN = "mean"))当数据处理过程较长时,也可以写成“流”的形式,但可能不如tidy R优雅:
with(mtcars, {
a <- mpg/2
b <- mean(vs)
drat -> c
a + b + c
})
b
## Error: object 'b' not found需要注意的有如下几点:
expr参数的内容如果有多行语句,需要使用大括号{};大括号内的赋值符号必须使用
<-或->,不能使用等号=;大括号内语句之间不加逗号
,隔开,直接换行即可;如果有输出结果,是直接输出到全局环境中的,而不是像tidy R那样作为
data的变量。
还需注意的是,大括号内使用<-或->生成的变量都是临时变量,仅在大括号内有效,不属于输出结果;大括号内的输出结果是最后一行未赋值的语句内容(上面代码中的a + b + c)。
如果希望将这些临时变量作为输出结果,需要使用<<-代替<-。但也要注意,它们仍然会直接输出到全局环境中,而不是作为mtcars的变量。
with(mtcars, {
a <<- mpg/2
b <<- mean(vs)
drat -> c
a + b + c
})
b
## [1] 0.4375总的来说,with()函数比较适用于数据处理过程较短的情况,这种情况下生成的变量数较少,是输出到全局环境还是数据变量中差别不大,而使用tidy R就有些“杀鸡用牛刀”了;而在数据处理过程较长的情况下,其代码优雅性不如后者,还要输出一堆变量到全局环境中去,不利于数据管理。
2 within函数
within()函数的用法和with()基本类似,但功能更贴近于tidy R:
输出内容是直接作为
data的变量,而不是输出到全局环境中;在大括号内变量赋值符号使用
=、<-、->均可,但如果没有大括号(单行语句不需要使用大括号)时只能使用<-或->符号。
data <- mtcars[, c("mpg", "vs", "drat")]
within(data, {
a = mpg/2
b <- mean(vs)
drat -> c
})
## mpg vs drat c b a
## Mazda RX4 21.0 0 3.90 3.90 0.4375 10.50
## Mazda RX4 Wag 21.0 0 3.90 3.90 0.4375 10.50
## Datsun 710 22.8 1 3.85 3.85 0.4375 11.40
## Hornet 4 Drive 21.4 1 3.08 3.08 0.4375 10.70
## Hornet Sportabout 18.7 0 3.15 3.15 0.4375 9.35
## Valiant 18.1 1 2.76 2.76 0.4375 9.05
## Duster 360 14.3 0 3.21 3.21 0.4375 7.15
## Merc 240D 24.4 1 3.69 3.69 0.4375 12.20
## Merc 230 22.8 1 3.92 3.92 0.4375 11.40神奇的是,后生成的变量反而在数据中排在前面。
3 transform函数
transform()函数在用法和功能上都接近tidy R:
不需要使用大括号;
语句之间需要使用逗号
,隔开;输出内容直接作为
data中的变量;赋值符号只能使用等号
=。
data <- mtcars[, c("mpg", "vs", "drat")]
transform(data,
a = mpg/2,
b = mean(vs),
c = drat)
## mpg vs drat a b c
## Mazda RX4 21.0 0 3.90 10.50 0.4375 3.90
## Mazda RX4 Wag 21.0 0 3.90 10.50 0.4375 3.90
## Datsun 710 22.8 1 3.85 11.40 0.4375 3.85
## Hornet 4 Drive 21.4 1 3.08 10.70 0.4375 3.08
## Hornet Sportabout 18.7 0 3.15 9.35 0.4375 3.15
## Valiant 18.1 1 2.76 9.05 0.4375 2.76该函数名称较长,又不使用大括号,因此语句在换行时默认会左缩进很多。
4 attach和detach函数
这两个函数是搭配使用的:在语句开始之前,使用attach()函数先“锁定”数据集,然后在语句中就可以直接引用数据集里的变量了,最后在数据处理结束后使用detach()函数“解锁”数据集。
例4.1
data <- mtcars[, c("mpg", "vs", "drat")]
attach(data)
a = mpg/2
b <- mean(vs)
drat -> c
detach(data)
find("a")
## [1] ".GlobalEnv"新产生的变量直接输出到全局环境中,而不是锁定的数据集中。
例4.2
attach(data)
mpg = 1
vs <- 2
vs
detach(data)
mpg
## [1] 1
vs
## [1] 2如果赋值的变量名在锁定的数据集中已经存在并且使用的赋值符号是
=或<-,效果同例4.1——这些变量仍然是直接输出到全局环境中,而不是更改数据集原有的变量。
例4.3
attach(data)
drat <<- 1
drat
## [1] 1
detach(data)
data$drat
## [1] 3.90 3.90 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 3.92 3.07 3.07 3.07 2.93
## [16] 3.00 3.23 4.08 4.93 4.22 3.70 2.76 3.15 3.73 3.08 4.08 4.43 3.77 4.22 3.62
## [31] 3.54 4.11如果赋值的变量名在锁定的数据集中已经存在并且使用的赋值符号是
<<-,那么会临时更改数据集原有的变量,而不是作为新变量输出到全局环境中;之所以说是临时更改,是因为一旦解锁数据集后,原有变量就会恢复原样。
例4.4
vs <- 3
attach(data)
vs
## The following objects are masked _by_ .GlobalEnv:
##
## mpg, vs
vs
## [1] 3
data$vs
## [1] 0 0 1 1 0 1 0 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 0 0 0 1 0 1 0 0 0 1
detach(data)当变量名同时存在于全局环境和锁定数据集的环境中时,全局环境中的变量的优先级更高,而数据环境中的同名变量会被覆盖(
masked _by_ .GlobalEnv)。
例4.5
在attach()函数的语法结构中,有一个pos参数,默认值为2,表示数据环境的优先级是2,而优先级为1的正是全局环境。
attach(what, pos = 2L, ...)并且,系统是不允许将数据环境优先级提为1的,因此全局环境优先级高于数据环境这一设定是不可更改的:
attach(data, pos = 1)
# Error in attach(data, pos = 1) :
# 'pos=1' is not possible and has been warned about for years默认情况下,后锁定的数据集的优先级高于先锁定的优先级:
data2 = data
attach(data)
attach(data2)
find("mpg")
## [1] ".GlobalEnv" "data2" "data"
detach(data)
detach(data2)
find()函数输出结果中,越靠前的环境优先级越高。
但也可通过pos参数更改它们之间的优先级:
data2 = data
attach(data)
attach(data2, pos = 3)
find("mpg")
## [1] ".GlobalEnv" "data" "data2"
detach(data)
detach(data2)5 应用
下面使用within()函数举个可视化方面的例子。
我们知道,ggplot2绘图系统可以很方便地建立变量对属性的映射关系:
data <- mtcars[, c("mpg", "drat", "vs", "cyl")]
library(ggplot2)
ggplot(data) +
geom_point(aes(drat, mpg, col = factor(vs)))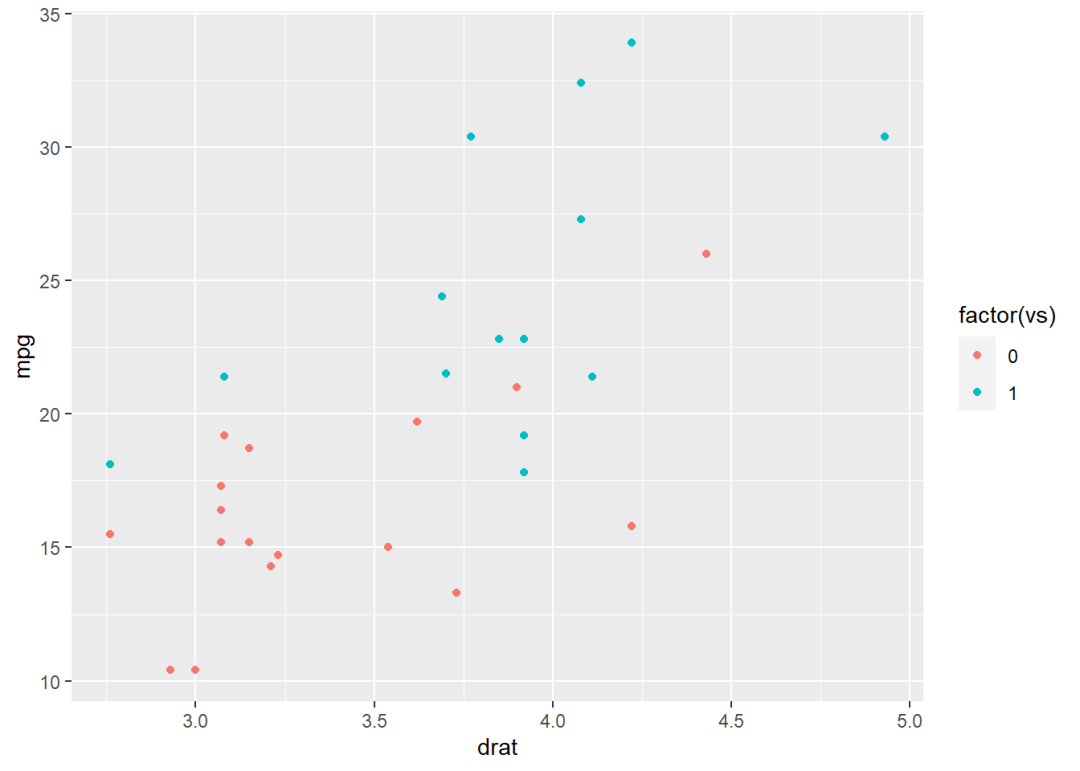
其实,base R也能很快实现这个功能:
data <- within(data, col <- c("red", "blue")[factor(vs)])
plot(mpg ~ drat, col = col, data = data)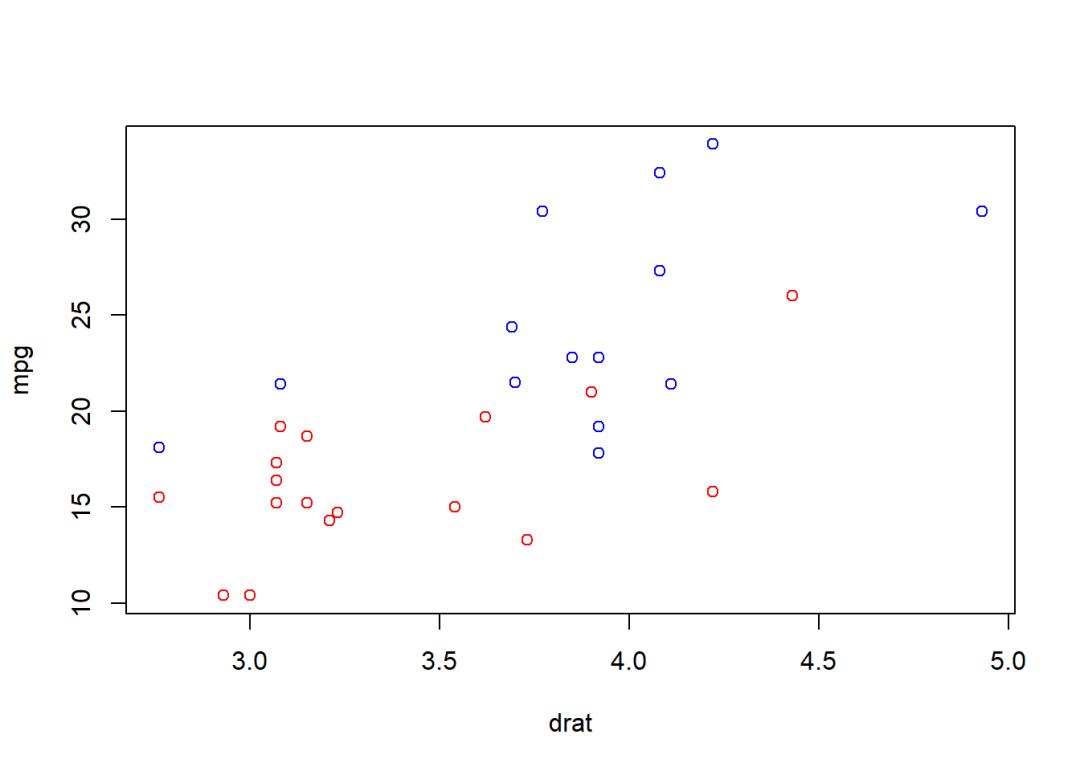
使用专门的工具包提供颜色:
library(RColorBrewer)
data <- within(data, col <- palette.colors(3, "Accent")[factor(cyl)])
plot(mpg ~ drat, col = col, data = data)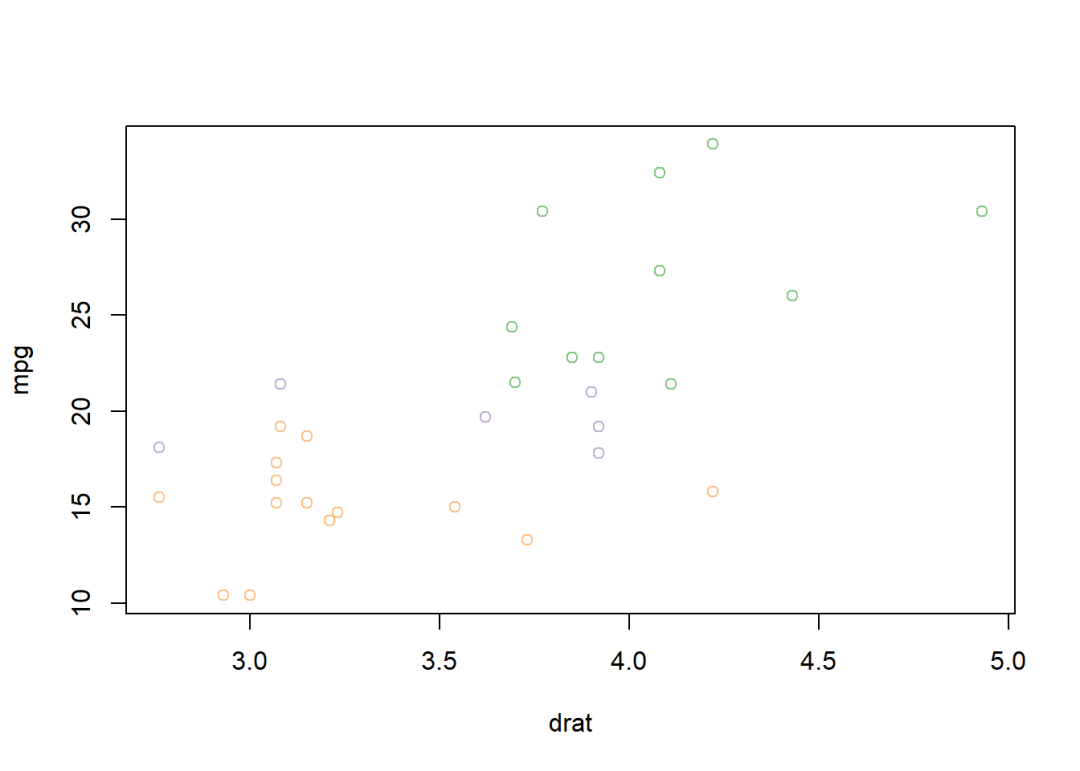
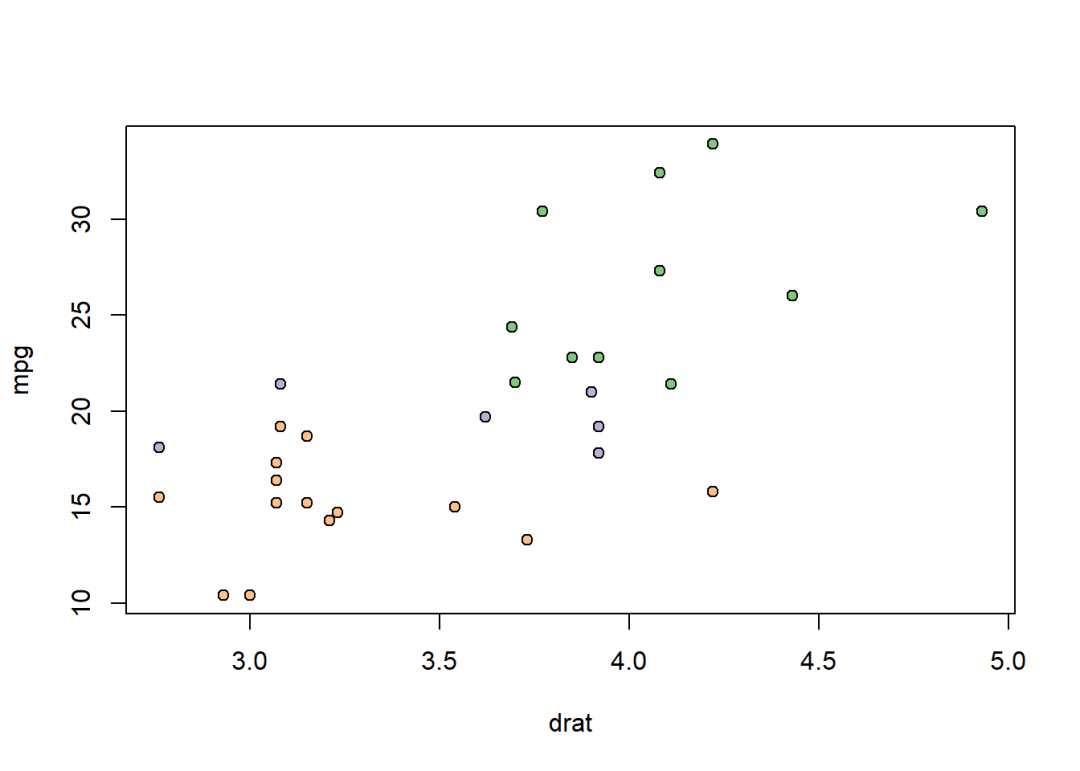
还可以写的更像tidy风格一些:
within(data, {
col <- palette.colors(3, "Accent")[factor(cyl)]
plot(mpg ~ drat, pch = 21, bg = col)
})
















 3190
3190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









