






版本情况:
Eclipse:Version: Mars.2 Release (4.5.2)
Hadoop: 2.7.1
Ubuntu:16.04
软件资源
网盘地址
mapreduce配置相关软件
链接:https://pan.baidu.com/s/1MyoC7LN8RRWvHgtEGOL_hA
提取码:0830
(三十天有效)
软件作用解释:
hadoop-eclipse插件(把hadoop-eclipse-plugin-2.6.0.jar拷到eclipse目录的plugins目录中)
依赖包2.7.1(导入相关依赖时用到)
Hadoop2.7.1
winutils-master (把windows相关依赖文件拷贝到解压好的hadoop文件夹中的bin目录下)
eclipse软件
一、基于Hadoop平台的eclipse开发环境搭建?
一、 安装jdk1.8,配置系统变量JAVA_HOME
安装完jdk后 右击此电脑点击属性 点击高级系统设置
环境变量
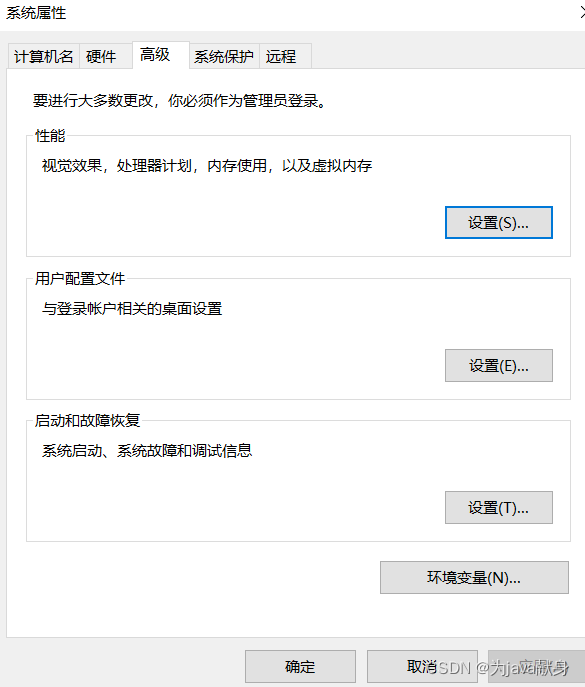
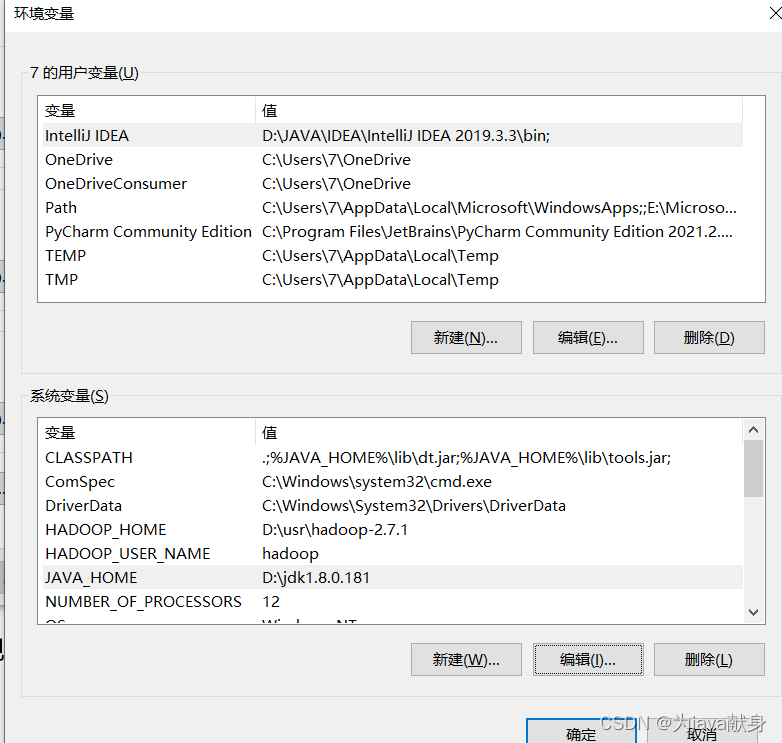 在系统变量 新建JAVA_HOME 路径写相对路径或者绝对路径都可
在系统变量 新建JAVA_HOME 路径写相对路径或者绝对路径都可
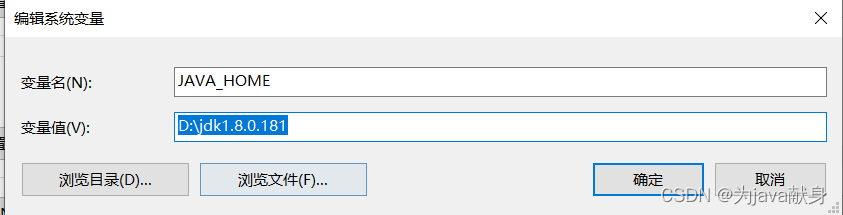
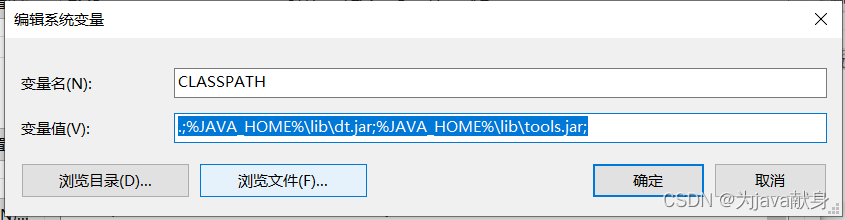
新建CLASSPATH
变量值写入: .;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;
(注意前面的.不要丢,和后面的;号)
在path变量中新建
(jdk安装时的两个路径)

新建HADOOP_HOME,修改path
在这里插入图片描述
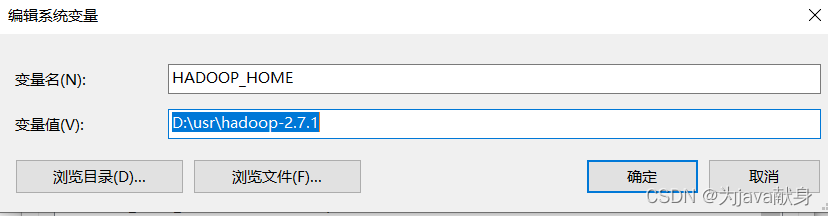
新建HADOOP_USER_NAME
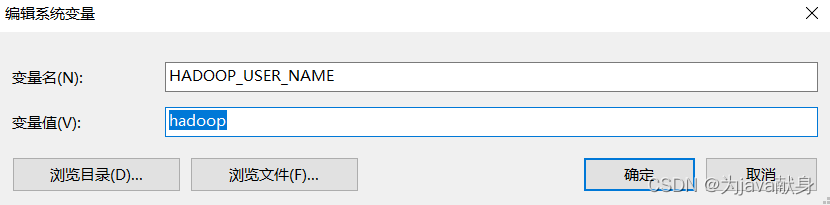

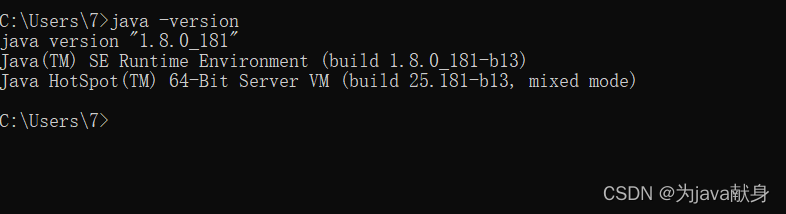
验证
jdk环境安装成功
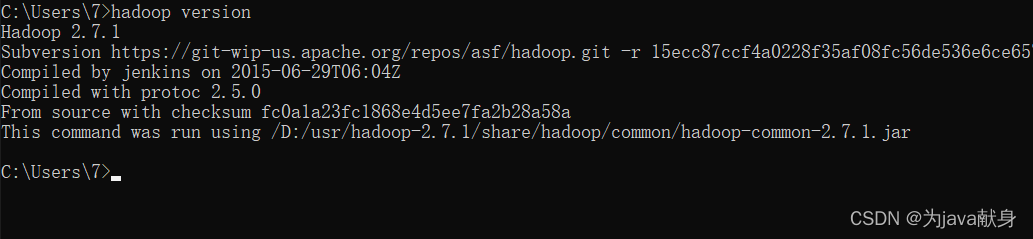
查看Hadoop是否安装成功
把windows相关依赖文件拷贝到解压好的hadoop文件夹中的bin目录下
下载地址:https://github.com/4ttty/winutils
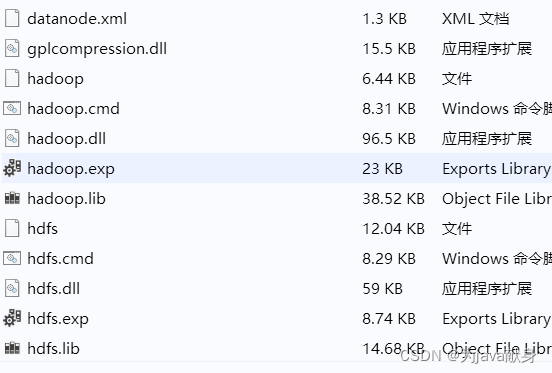
并把其中的hadoop.dll文件拷贝到C:\windows\system32中
把hadoop-eclipse-plugin-2.6.0.jar拷到eclipse目录的plugins目录中
启动eclipse,配置hadoop安装路径

增加Map/Reduce功能区
Eclipse窗口,菜单中选择:windows—>Perspective—>Open Perspective
—>Other
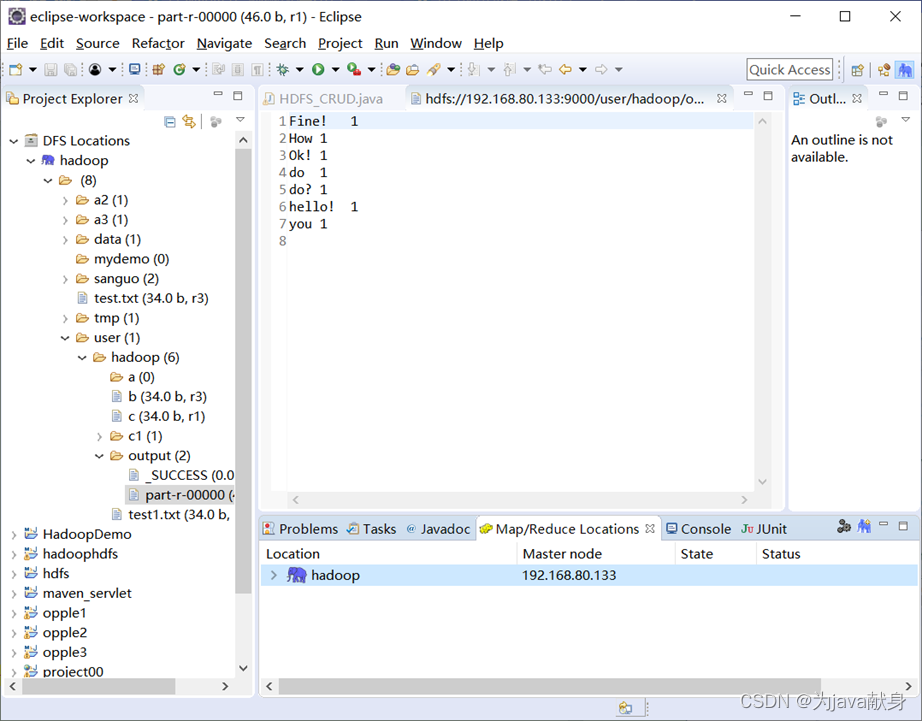
单击界面右下方的蓝色小象图标(其上方有+号)
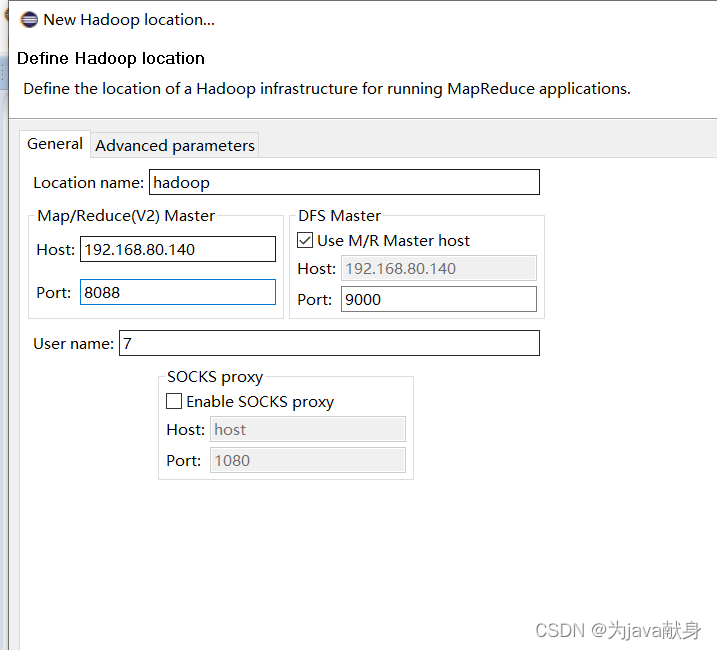
Location name:命名新建的hadoop连接
Map/Reduce(V2) Master:填写ResourceManager的IP地址和端口
DFS Master:填写NameNode的IP地址和端口
*浏览HDFS上的目录及文件*
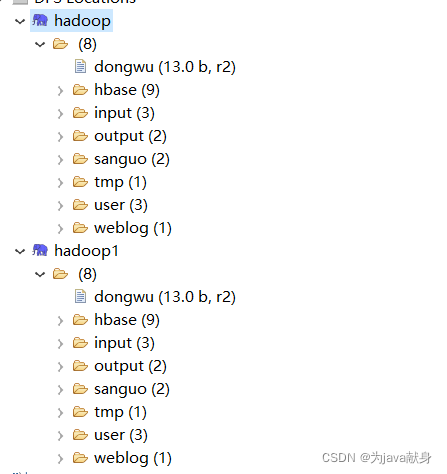
注明:要让windows下的java程序能访问hdfs文件,ubuntu的9866端口要打开
sudo ufw allow 9866

二、countword案例实现
1.任务要求
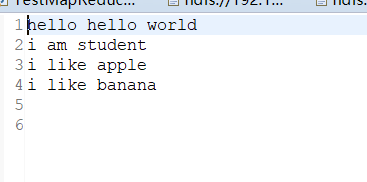
统计指定文件中的词频,并输出到指定目录(该目录不能存在)
在hdfs中的当前用户家目录建input文件夹,现有helloworld.txt文本文件,请把这个文件上传到input目录下,并统计这个文件中单词出现的次数。
程序结构:
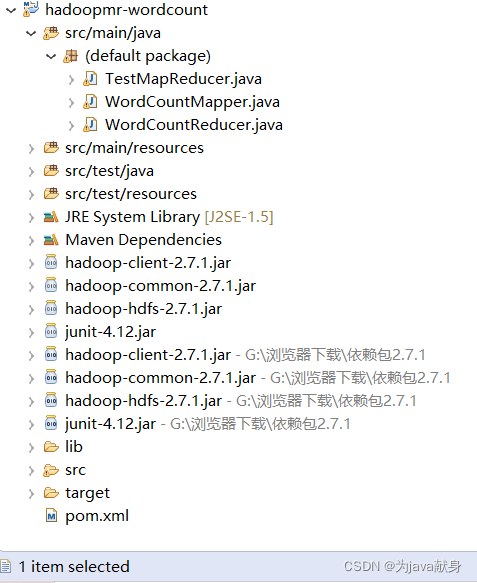
2.MapReduce程序编写方法
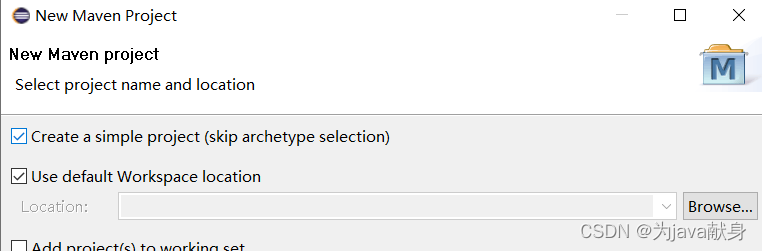
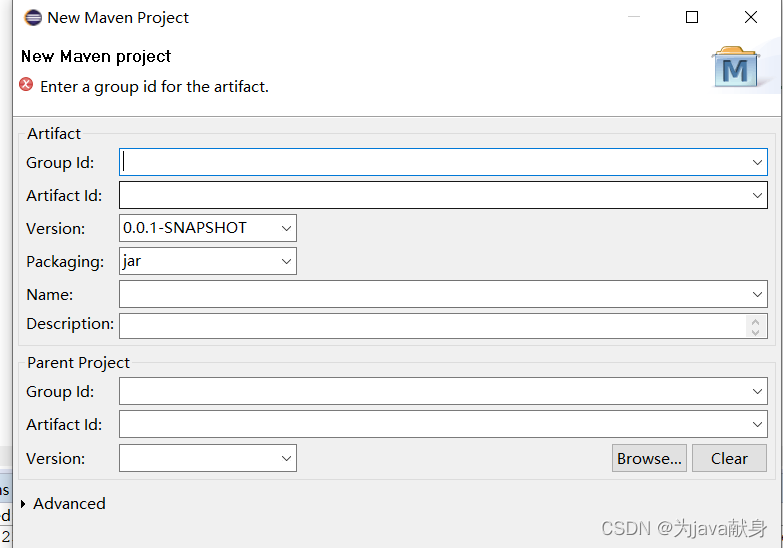
(1)创建maven工程

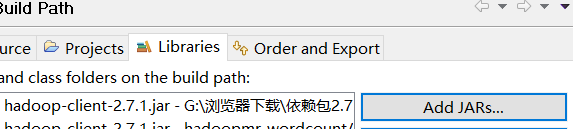
(2)Eclipse导入相关jar包
创建一个文件夹


点击Add JARs 选择我们所要的jar包把jar包导入
(3)在pom.xml文件中添加如下依赖
<dependencies>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- hadoop-common依赖系统上的tools.jar -->
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
</dependencies>
(3)在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
2.编写程序
(1)编写Map处理逻辑- WordCountMapper.java
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
// 拿到传入进来的一行内容,把数据类型转换为String
String valueString = value.toString();
// 将这行内容按照分隔符切割
String wArr[] = valueString.split(" ");
// 遍历数组,每出现一个单词就标记一个数组1 例如:<单词,1>
for(int i=0;i<wArr.length;i++){
// 使用MR上下文context,把Map阶段处理的数据发送给Reduce阶段作为输入数据
context.write(new Text(wArr[i]), new LongWritable(1));
//第一行Hello Hello World. 发送出去的是<Hello,1><Hello,1><World.,1>
}
}
}
(2)Reduce处理逻辑- WordCountReducer.java
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.IdGenerator;
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> v2s,
Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
Iterator<LongWritable> it = v2s.iterator();
//定义一个计数器
long sum = 0;
//遍历一组迭代器,把每一个数量1累加起来就构成了单词的总次数
while(it.hasNext()){
sum += it.next().get();
}
context.write(key, new LongWritable(sum));
}
}
(3)驱动模块TestMapReducer.java
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.junit.Test;
public class TestMapReducer {
public static void main(String[] args) throws Exception{
// 通过如下的方式进行客户端身份的设置,可访问hadoop的用户
System.setProperty("HADOOP_USER_NAME", "hadoop");
Configuration conf = new Configuration();
// 这里指定使用的是HDFS文件系统
conf.set("fs.default.name", "hdfs://192.168.80.140:9000");
//conf.set("fs.defaultFS", "hdfs://192.168.80.140:9000"); //在有设置地址映射情况下可用机器名代替IP地址
// 这里指定使用的是本地文件系统
//conf.set("mapreduce.framework.name", "local");
//通过Job来封装本次MR的相关信息
Job job = Job.getInstance(conf);
// 指定MR Job jar包运行主类
job.setJarByClass(TestMapReducer.class);
// 指定本次MR所有的Mapper Reducer类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 设置我们的业务逻辑 Mapper类的输出 key和 value的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 设置我们的业务逻辑 Reducer类的输出 key和 value的数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 指定要处理的数据所在的位置
FileInputFormat.setInputPaths(job, new Path("/user/hadoop/input/helloworld.txt")); //可以是目录或文件
//FileInputFormat.setInputPaths(job, "D:/mr/input");
// 指定处理完成之后的结果所保存的位置
FileOutputFormat.setOutputPath(job, new Path("/user/hadoop/output"));
//FileOutputFormat.setOutputPath(job, new Path("D:/mr/output"));
// 提交程序并且监控打印程序执行情况
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}
3、测试
(1)本地测试
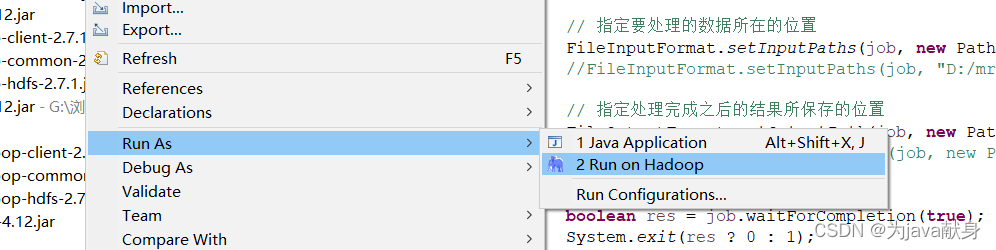
如果在控制台出现权限不够,就在虚拟机用shell命令修改报错路径文件的权限 -chmod 777
在eclipse中查看执行结果
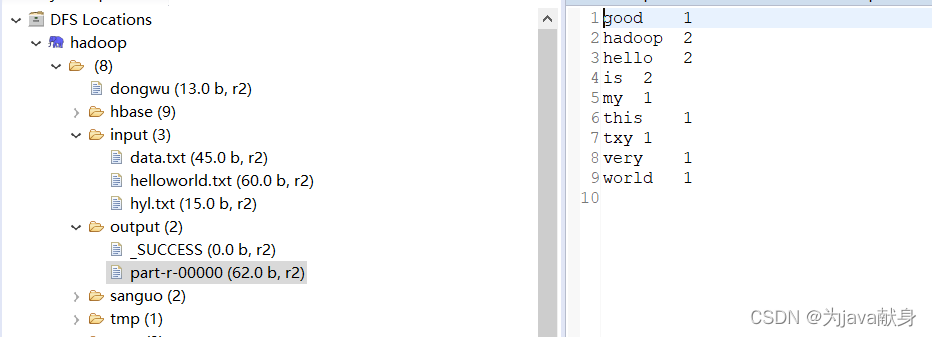

在集群上查看结果

报错解决
问题:xml出现红色波浪号
解决:拼写检查忽视去掉红色下划波浪线的方法:
Windows->Preferences->General->Editors->Text Editors->Spelling将Enable spell checking取消即可.
问题:导入项目的时候,运行时出现了 Bug – 错误: 找不到或无法加载主类 xxxx
解决:通过 eclipse 上的 Problem 描述 ,找到对应项目的 errors 描述发现错误描述为
Description Resource Path Location TypeArchive for required library: ‘C:\Users\xxx.m2\repository\commons-lang\commons-lang\2.6’ cannot be read or load in project xxxx
解决:
在经过eclipse的alt+F5强制更新无效后,根据提示找到maven仓库报错的目录,回到目录找到地址 C:\Users\xxx.m2\repository\commons-lang\commons-lang\2.6 并删除 commons-lang 将该目录下的所有文件删除,重新更新项目,会自动重新下载对应的 maven 文件
(如果你显示的不是这个文件,就删除你显示的那个文件然后再更新项目)
问题:org.apache.hadoop.security.AccessControlException: org.apache.hadoop.security .AccessControlException: Permission denied: user=Administrator, access=WRITE, inode=“hadoop”: hadoop:supergroup:rwxr-xr-x
其实这个错误的原因很容易看出来,用户Administator在hadoop上执行写操作时被权限系统拒绝.
解决:
1、在hdfs的配置文件中,将dfs.permissions修改为False
2、执行这样的操作 hadoop fs -chmod 777 /user/hadoop
(指定的处理的数据所在的位置要根据自身情况修改,不能直接抄上面的代码)
问题:hadoopt 在cmd的时候显示java_home路径没有设置正确
解决:可能是安装jdk的时候路径实在prom file 下 出现了空间
可以改成PROGRA~1
















 2784
2784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









