









前面那几天是在找大数据的门,其实也是在搞一些linux的基本命令,现在终于轮到hadoop了

Hadoop
hadoop的安装方式
单机模式:
就如字面意思,在一台机器上运行,存储是采用本地文件系统,没有采用分布式文件系统~就如我们一开始入门的时候都是从本地开始的;
伪分布式模式
存储采用分布式文件系统,但是HDFS的名称节点和数据节点都在同一台机器上;
简单来说就像我们学习微服务的时候,只有一台机器,只能采用不同的端口号来实现微服务的开发,
分布式模式
存储采用分布式文件系统,HDFS的名称节点和数据节点位于不同的机器上~这才符合分布式的要求;
安装hadoop
下载hadoop
此时是以root用户登陆的系统
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
解压缩文件
tar -zxf hadoop-3.3.4.tar.gz
加压完毕之后将文件的权限授予hadoop用户,以免后续出现什么问题;
授权解压的文件给hadoop用户
[root@node1 local]# sudo chown -R hadoop ./hadoop-3.3.4
#切换用户
[root@node1 local]# su hadoop
[hadoop@node1 local]$
查看hadoop是否可以正常运行
cd hadoop-3.3.4
./bin/hadoop version
结果如下~

hadoop的单机配置
hadoop下载下来之后默认是非分布式模式,无需其他配置即可运行;
非分布式即java的单进程模式,这个我们就很擅长了,拿来直接运行即可;
首先来看官网给的例子(别的例子咱也不会,入门一下,日后在搞复杂的)
- 请听第一题
我们将input文件夹下所有的文件作为输入,筛选出符合正则表达式dfs[a-z.]+的单词并统计出现次数
mkdir ./input #创建一个文件夹
#拷贝hadoop配置文件到 刚刚创建的input文件夹下
cp ./etc/hadoop/*.xml ./input
#执行hadoop命令~
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep ./input ./output 'dfs[a-z.]+'
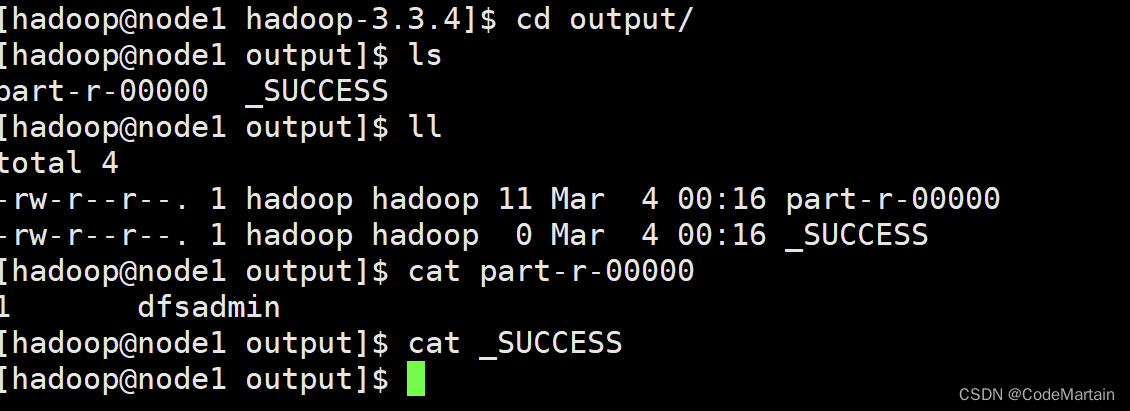
查看output文件夹下的内容
cat ./output/*
我们来看一下我们复制时都复制了些什么
[hadoop@node1 hadoop-3.3.4]$ ls ./input/
capacity-scheduler.xml hadoop-policy.xml hdfs-site.xml kms-acls.xml mapred-site.xml
core-site.xml hdfs-rbf-site.xml httpfs-site.xml kms-site.xml yarn-site.xml
[hadoop@node1 hadoop-3.3.4]$
再来看看 输出的文件中都有什么
[hadoop@node1 hadoop-3.3.4]$ cd output/
[hadoop@node1 output]$ ls
part-r-00000 _SUCCESS
[hadoop@node1 output]$
这是什么?
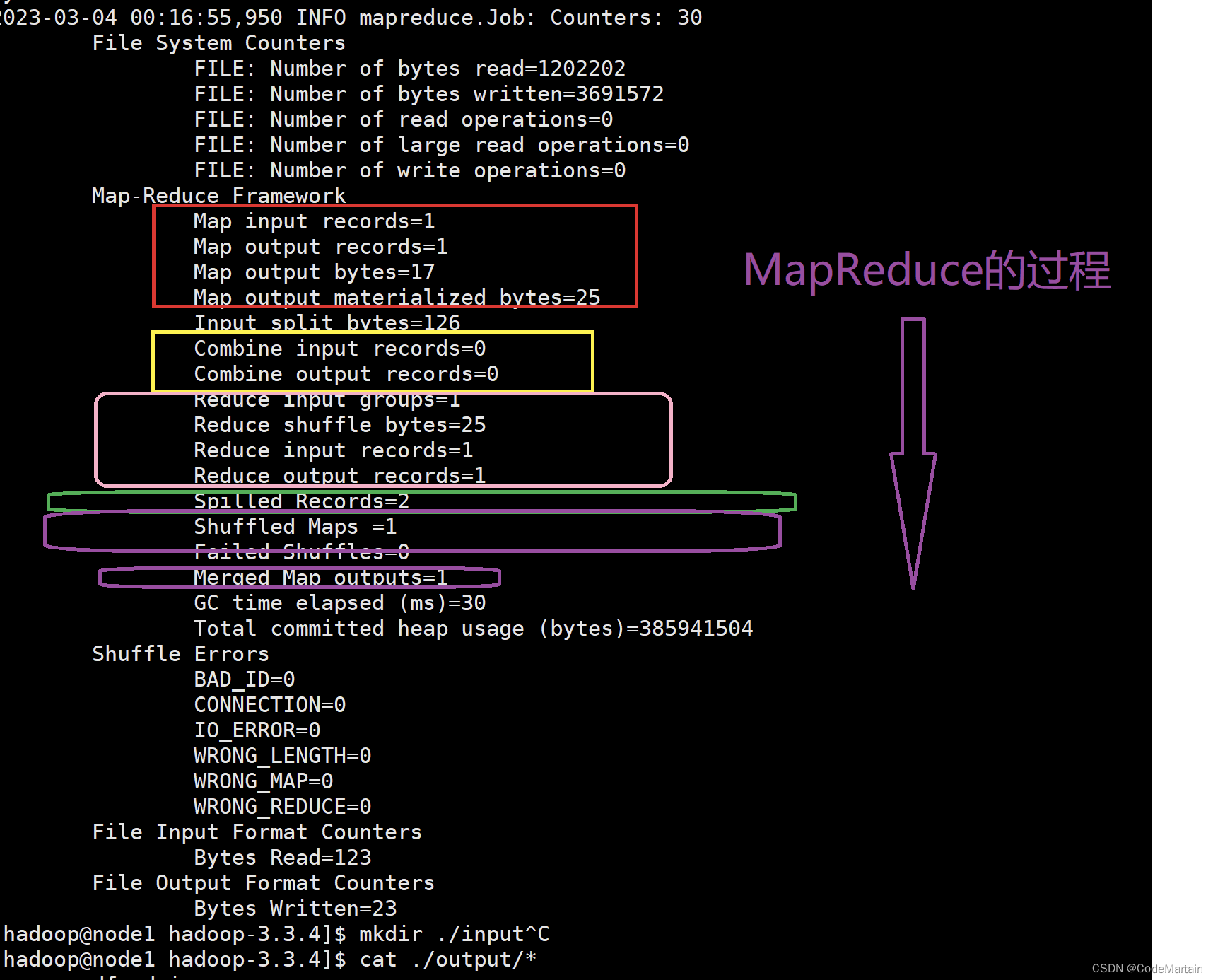
 我们再来看执行成功后的提示~
我们再来看执行成功后的提示~
 回头再来看hadoop执行的命令
回头再来看hadoop执行的命令
#头部命令
./bin/hadoop jar
有些类似于java执行jar 的那个逻辑
java jar
看看hadoop文件中都写了什么…
乌压压一大片(暂且搁置一边)
 源码自取
源码自取
然后就是参数部分
./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar
找到它~可以看到是一些打包好的jar包,就是提前写好的代码去执行一些运算,以后我们也可以写代码打包后交给hadoop运行
**注意,**Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将 ./output 删除。
hadoop伪分布式配置
hadoop可以在单节点上以伪分布式的方式运行,这个由hadoop进程分离的java进程来运行,节点既可以作为namenode也可以作为datanode,同时读取hdfs中的文件.
伪分布式需要一些配置,其配置文件在etc/hadoop/ 中,需要修改两个配置文件
- core-site.xml
找到该文件并修改他
vi /usr/local/hadoop-3.3.4/etc/hadoop/core-site.xml
文件中添加如下内容
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop3.3.4/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
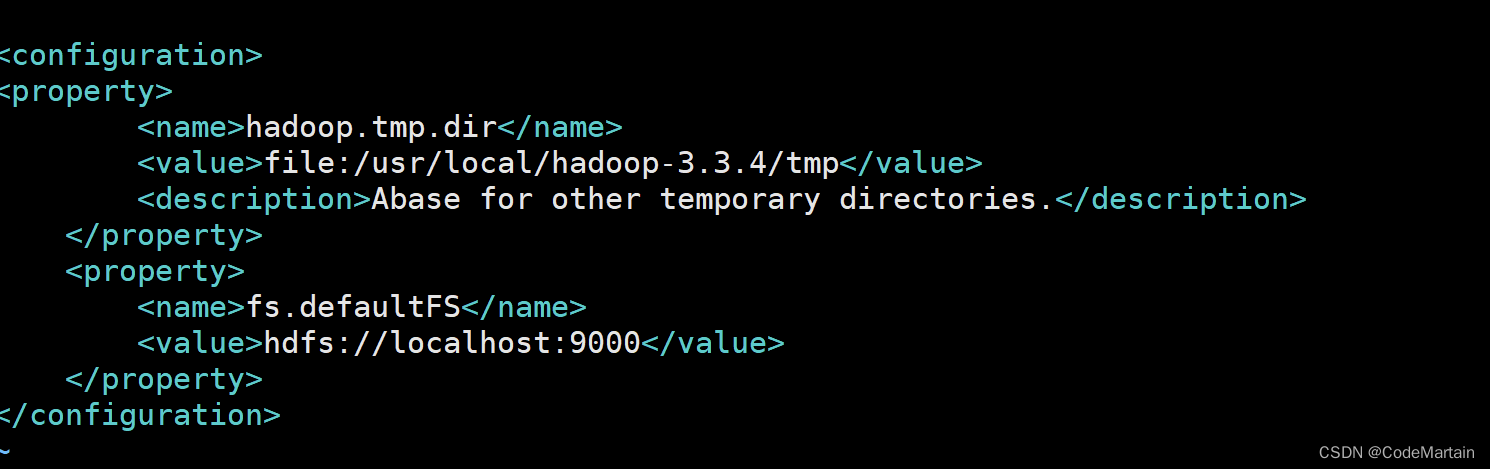
大体是配置了一个临时存储文件夹的地址和一个访问的网址
- hdfs-site.xml
找到配置文件并修改他
vi /usr/local/hadoop-3.3.4/etc/hadoop/hdfs-site.xml
添加如下内容
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
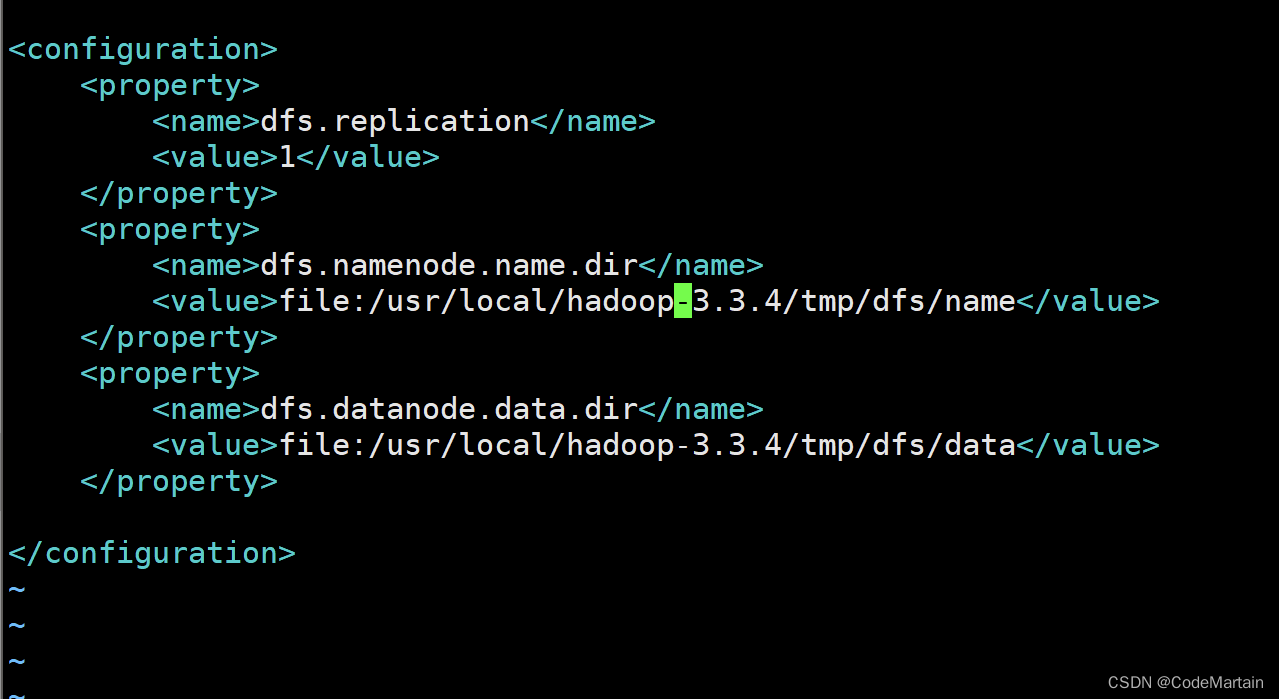
大体就是配置了namenode节点和datanode节点
hadoop的配置文件说明
hadoop的运行方式是由配置文件决定的(hadoop在运行时会读取配置文件)
由于一开始并没有配置任何内容,所以是单机模式;
按照hadoop的与运行方式来说,伪分布式子需要配置fs.defaultFS 和 dfs.replication 就可以了,但是若没有配置hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop, 而这个目录会在机器重启时可能会被删掉,导致必须重新执行format才行;
我们也指定了namenode节点跟datanode节点
配置完成后
初始化namenode
cd /usr/local/hadoop
./bin/hdfs namenode -format
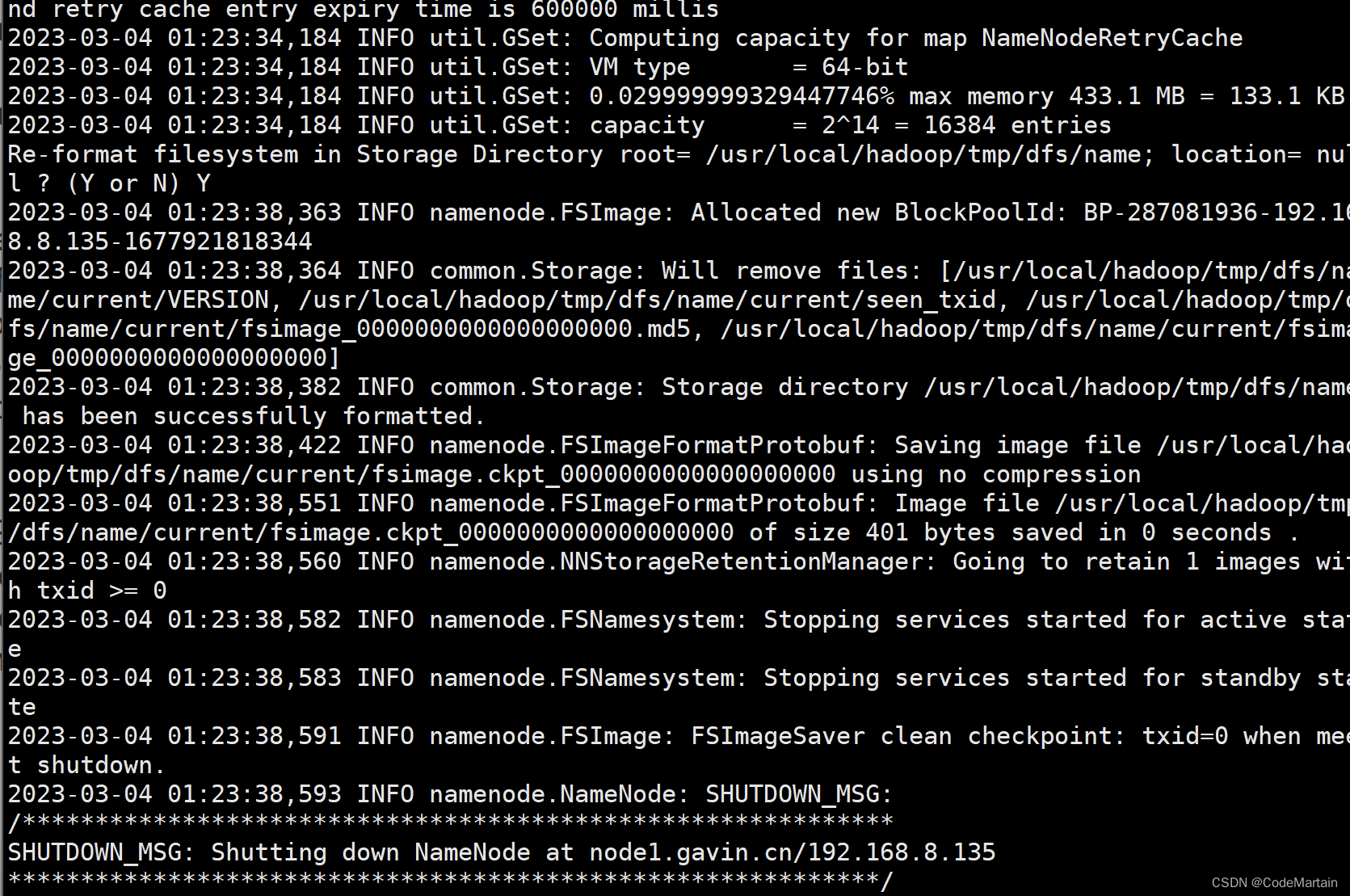 看到success就表示执行成功了;
看到success就表示执行成功了;
啥?没看到?这就尴尬了,截个图给你看看

再去文件夹下看看有没有对应的文件建立
ll ./tmp/dfs/name/current/

如果出现错误:
1.JAVA_HOME 错误,那就去配置一下 hadoop-env.sh文件 ,重新配置一下JAVA_HOME
2.文件夹创建失败,可能是当前用户没有权限,给当前用户授权
sudo chown -R hadoop /usr/local/hadoop-3.3.4
开启namenode和datanode节点
./sbin/start-dfs.sh
 开启之后访问一下配置文件中的那个网址:
开启之后访问一下配置文件中的那个网址:
注:这里用虚拟机的ip地址;
 datanode节点的信息
datanode节点的信息
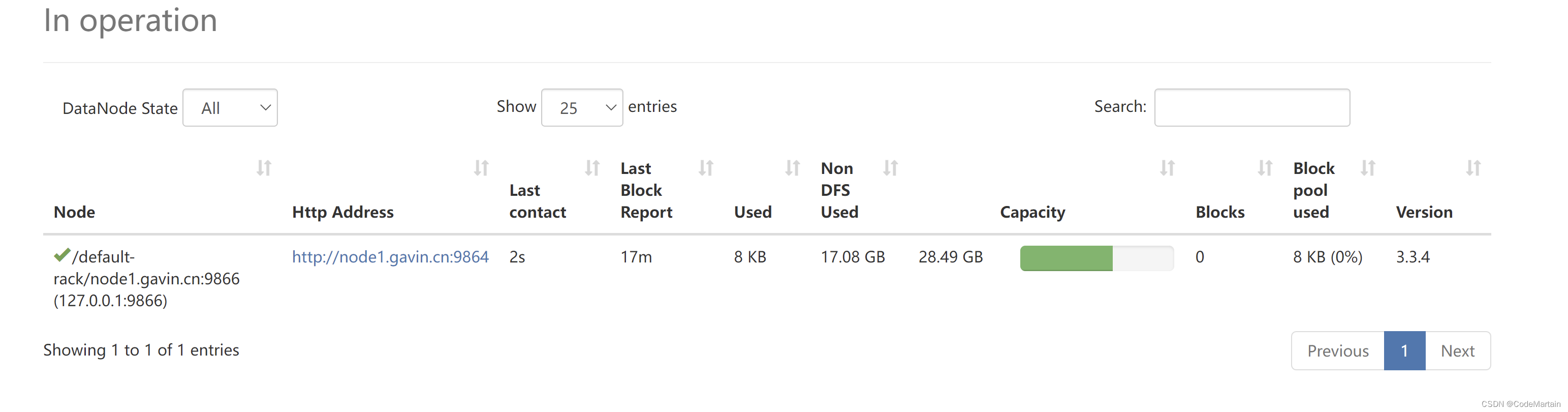
启动hadoop时遇到的一些问题集锦:
专门从网上找的,虽然现在还没有遇到,说不定以后会遇到,这样也能快速知道如何解决;
速度自取
接下来就是回顾时刻,这几天我们通过学习 了解到hadoop 的一些知识
首先是:
1,hadoop的环境-配置jdk
2,hadoop各个节点之间的交流通过ssh加密 --配置ssh
3,hadoop的运行三种方式:
- 单体模式
- 伪分布式
- 分布式
4,hadoop的运行命令
首先在hadoop文件下的bin目录有很多可以运行的命令文件
目前接触到了
启动hadoop ~ ~
./bin/hadoop jar 写好的打包程序 其他的运行配置
5,配置伪分布式的关键配置文件:
core-site.xml ~配置了临时文件夹
hdfs-site.xml ~配置了namenode节点和datanode节点以及一个访问html的地址
6,配置结束后 格式化namenode
./bin/hdfs namenode -format
7,启动namenode以及datanode守护进程
./sbin/start-dfs.sh
 未完待续~ 另一台机器操作一遍在熟悉一下啊!
未完待续~ 另一台机器操作一遍在熟悉一下啊!
hadoop集群的安装请看下一篇文章
















 386
386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











