







前言
在上一章中,我们讨论了回归问题,主要的任务就是拟合出数据集分布的解析式。而这一次的学习中,我们将关注分类问题。
Classification
classification分类有两种:二元分类和多类分类。
二元分类:预测二值目标,在分类问题属于基本问题。
多类分类:预测离散(>2)值目标的二元分类的示例。
分类在实际生活中有什么意义吗?
很多领域都有分类问题,例如,可以根据是否存在各种症状,医生预测患者是否患有疾病;
管理员将电子邮件分类为垃圾邮件或非垃圾邮件;
预测金融交易是否具有欺诈性等。
Binary Linear Classication
二元分类中基础的为二元线性分类。
它的描述如下:
给定D维输入预测离散值目标。
预测二进制目标或
其中y=1的样本称为正样本,y=0或y=-1的样本称为负样本
模型预测是x的线性函数。
我们看下面这样的数据集:
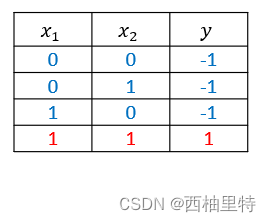
样本有两个维度,y表示样本所属的类别。
在坐标图中绘制出来:
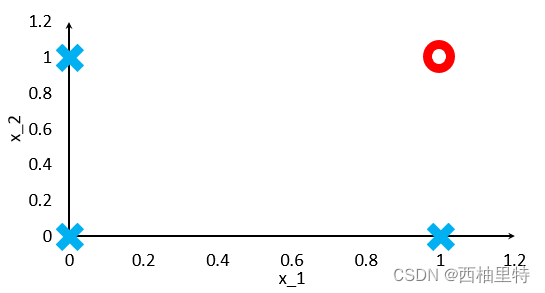
接下来我们的任务就是得到一个预测模型(解析式),对于其他的样本,输入到模型中能够得到它的分类情况。
对于该数据集,我们可以用一条直线将其进行分类,这条直线的解析式可以定义为:
然后计算不同的数据样本到直线的距离
在坐标图中:
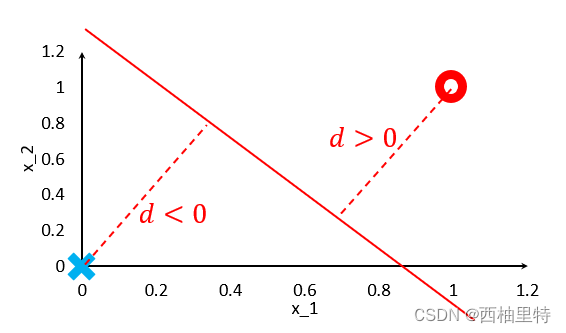
因此在直线下面的距离d<0,在直线上面的d>0,然后定义一个符号函数
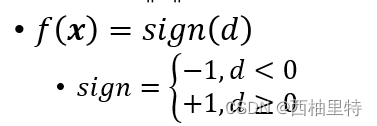
这样我们就能用直线来对数据进行二元分类了。
另外对于上述求距离的公式,其中是一个非负数,而最终我们判断类别仅仅考虑正负号的情况,所以不用精确距离数值,只保留公式中影响正负的式子即可。可以再乘
消掉,这样公式就变为了
那么我们的预测模型就可以这样定义:
根据数据集训练获得参数w和b,然后就可以对新的数据进行预测了,预测结果范围为(-1,1)
这个模型我们就可以称之为感知机(Perceptron)
Cost Function
这样损失函数就很简单了,我们可以用表示模型预测的距离信息,而实际数据的分类信息是y,我们让预测的
与实际的y相乘。
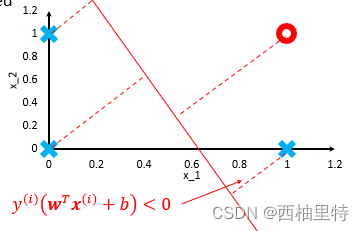
例如这样的示例,其中右下的样本它本身应该属于-1,但是我们的分类线把它划在了上面,即>0,那么相乘后结果<0。只有当预测的结果与实际值一致时,相乘后的结果才是非负数。
因此只要出现负数,就表明目前模型参数有损失,可以进行优化。
Optimization
怎么进行优化呢?
首先我们考虑优化的对象,在上面的分析中,预测值与实际值乘积<0表明预测错误,所以我们只对这部分进行优化即可。
即
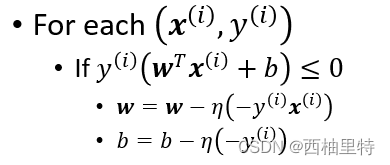
不过,这里有一个问题呀,为什么w的优化公式是
这样的呢?
在上一章《线性回归》中我们也用了这样的梯度下降的优化方法,感觉这样的公式是偏直觉的,好像看着很有道理,但是具体的原理是怎么样的呢?
我们要先明白这里为什么梯度是,前面加负号的原因是什么?
很显然,在该模型中选取的损失函数为

而只有该函数小于0的时候才说明预测结果失败,因此我们选取的都是该损失函数小于0的部分,那么假设损失函数为l(w,b),在优化的时候有l(w,b)<0,一般情况下我们习惯用正数表示损失函数值,所以令L(w,b)=-l(w,b)就有了>0,这样对L函数求w的偏导会得到
至于整个式子,偏导数表示损失函数在 w方向上的局部变化率,即损失函数在当前点w的增长方向。-偏导数则为当前点w的减少方向,所以 这样更新w可以不断地减少损失函数值,从而达到优化的效果。
作业
数据集格式样式为:

共50行3列数据,前两列为横纵坐标,最后一列为该样本所属的类别。
需要完成的任务如图所示:

我们需要在update优化函数中,填写W和J的更新方法。
填写如下:

这里的Z实际上为,即预测的类别,然后让Z矩阵中的元素与实际类别y相乘,对于大于0的部分更改为0(说明该部分预测正确)。剩下的就是预测错误的样本,接着就对这部分样本进行优化。
我们选取的优化策略为梯度优化,由于之前的损失为负数,所以这里-X.T@Y有一个-号。
迭代次数,学习率设置如下:

最后的结果为:



















 1297
1297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









