






【Sigcomm’24】压缩KV Cache以通过网络传输
领域:KV Cache复用,压缩算法
读懂本文需要了解:KV Cache,量化
背景和问题:
有时候LLM的输入的前缀有共同部分,有复用以加速的可能。比如系统信息,示例输入输出等。下图是一个简单的例子。

在有些场景下(如①预填充与推理分离的架构,②KV Cache通过网络卸载到专用存储器),KV Cache要通过网络传输。与NVLink相比,网络带宽太低了。另外,KV Cache太大了,Llama-34B的80000个token需要19GB空间。
一句话概括方法:
用算数编码压缩KV Cache为Bitstream,通过网络传输后解压缩。对于波动的带宽,可以动态改变压缩强度。
介绍算数编码:
算数编码将一个字符串压缩成0-1之间的一个小数,这样可以用bit流存储得到的小数。
以AABABCABAB为例,我们统计ABC出现的频率,按照频率将0-1区间瓜分给ABC。
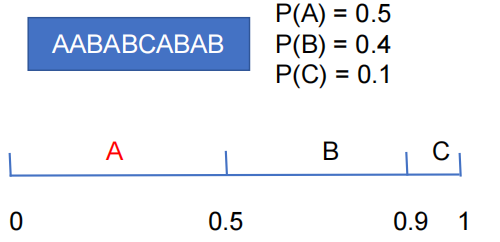
第一个字符是A,所以我们压缩后得到的小数必须在0-0.5之间。(结合区间划分的规则,这样就可以知道第一个字符是A了)
之后,我们将A所在的区间(0,0.5)继续按照频率瓜分给ABC。
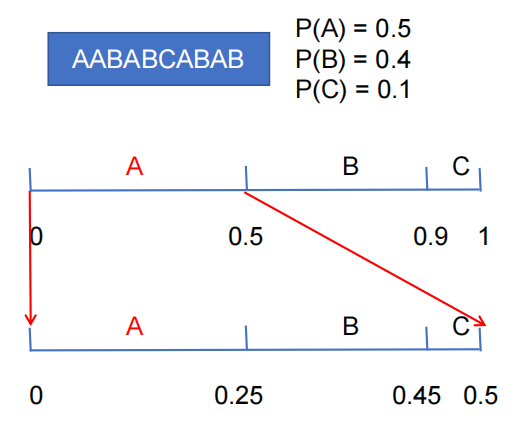
由于第二个字符还是A,所以我们最终的小数应该在0-0.25之间。(此时如果解压缩,因为在0-0.5之间,所以第一个字符是A,因为在0-0.25之间,所以第二个字符是A,后面不再赘述解压缩过程)
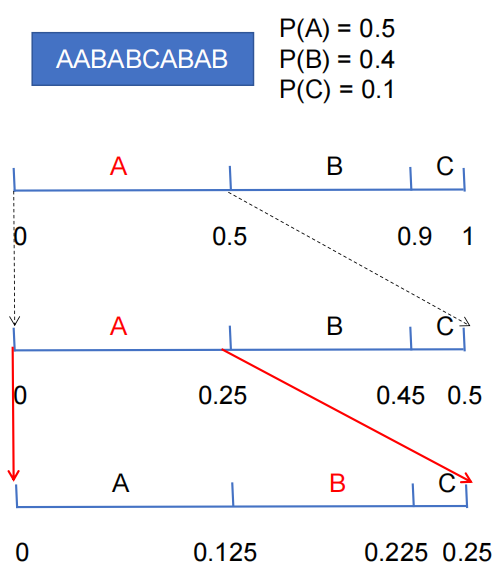
每次都瓜分区间,下一个字符是B,所以选0.125-0.225这个区间。多画几个步骤如下图所示。
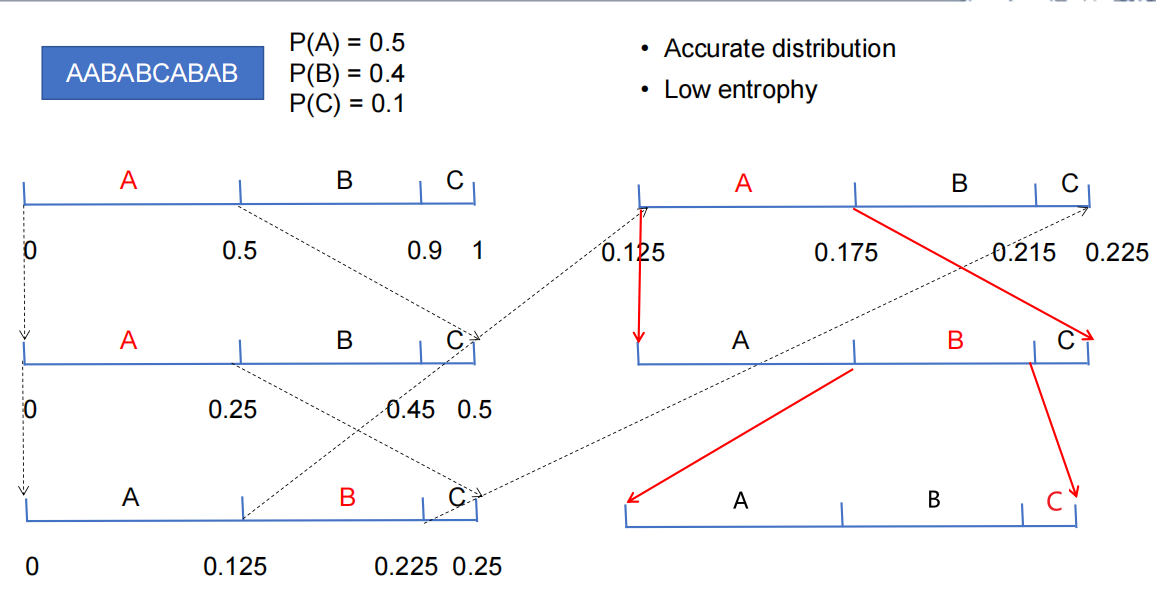
我们最后会得到一个很小的区间,只需选择这个区间中,需要的存储位数最小的小数就行了。
为什么要按频率分区间呢?因为最后的区间越大,区间中选出来的小数占用的位数最少,所以频率高的字符要分得更大的区间。另外,这个方法理论上能让压缩率高于哈夫曼编码(因为哈夫曼编码给字符只能分配整数个比特)。
主要方法:
作者通过观察实验,发现了三个insights:①位置接近的KV更相似。②模型的深层更重要。③模型同一层(或同注意力头)的KV更像。
想用算数编码压缩张量(把张量当做前一章节的字符串),首先要统计张量内各个元素的频率。但张量的元素是浮点类型的!应该很难见到两个一模一样的浮点数吧,所以必须要对KV张量进行量化!量化有一个基础知识:数值越聚集,量化损失越低。
根据观察①,作者对连续的token进行分组,每一组的第一个token叫做anchor,之后同组内的token的KV都与anchor的KV做差(为什么不用差分?因为不能并行解码)。这样得到的差值一般都比较小,适合量化。每组都分别独自量化和解码。
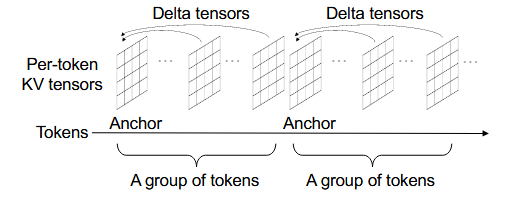
量化强度高能让元素种类变少,这样算数编码的长度也更短,但会损失精度。根据观察②,深层的量化强度低一些,这样精度损失少。(具体来说,作者将层分为了前1/3,后1/3和其他,最低量化强度是INT8)另外,Anchor token永远用INT8。
根据观察③,更详细的分组方法应该是按层分组,并按注意力头分组,然后再按刚才说的方法按位置分组。
现在可以统计分布了,不过统计的不是张量内元素的分布了,而是量化后的Anchor KV的分布,以及差值的分布了。作者是离线统计分布的。
带宽自适应:
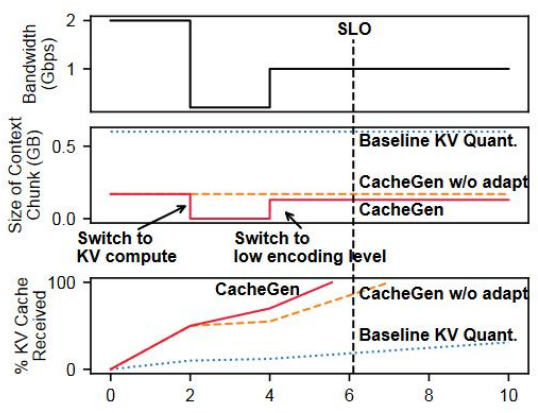
作者进一步将token分chunk,每个chunk1.5k个token。通过传输上一个chunk时的平均带宽来估计下一个chunk时的带宽。带宽如果较低,就增强量化强度以缩短比特位数,如果带宽非常低,甚至可以只传输文本本身,让目标设备重计算KV。下图给出了带宽随时间变化的图像以及不同处理方式的效率:
实验:
Datasets: LongChat, TriviaQA, NarrativeQA, Wikitex
Models: Mistral-7B, Llama-34B, Llama-70B, fine-tuned on long contexts
TTFT(time to first token):
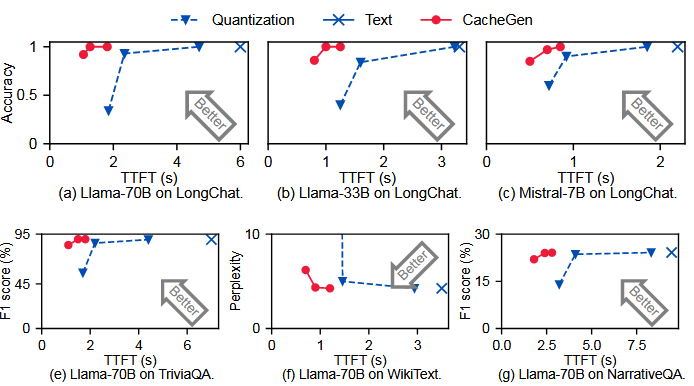
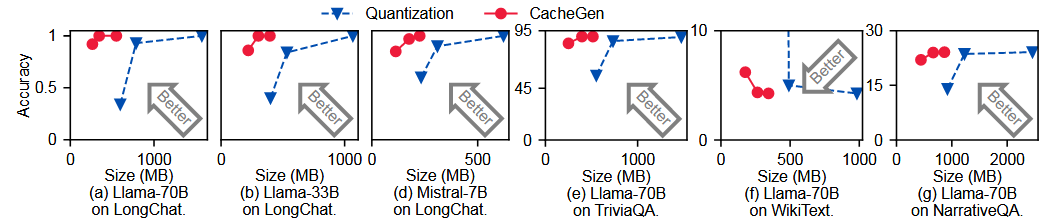
不同KV大小下的精度与普通量化方法对比:
个人思考:
算数编码是个传统的压缩算法。在消融实验中,作者观察了高带宽(与网络相比,I/O已经是高带宽了)情况下的效果,发现算数编码的加速效果还是明显强于传统量化方法。所以,现在量化方法那么多样,为什么很少有人用传统的方法压缩,然后向内存或者磁盘卸载呢?

















 2060
2060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









