







我们在markdown中进行公式书写时,部分会采取引用站外图片的方式,如下。
str1=r'''
### **4.5 多变量决策树**
### **单变量决策树(univariate decision tree)**
特点:轴平行(axis-parallel):即它的分类边界由若干个与坐标轴平行的分段组成
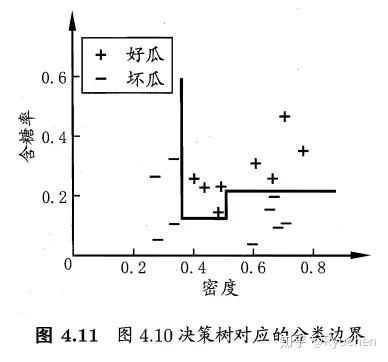
### **多变量决策树(multivariate decision tree)**
特点:非叶结点不再是仅对某个属性进行测试,而是对属性的线性组合进行测试
每一个非叶结点是一个形如  的线性分类器,其中  是属性  的权重
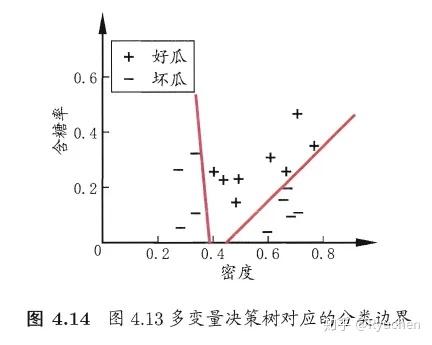
'''
利用下面的代码,可以实现内联公式的标准化。
import re
string=str1.replace(r"[]",'@@')
string = string.replace(r"![",'$')
string = re.sub(r"\]\(https(.+?)\)",'$',string)
string = string.replace(r"@@",'[]')
print(string)
结果输出
### **4.5 多变量决策树**
### **单变量决策树(univariate decision tree)**
特点:轴平行(axis-parallel):即它的分类边界由若干个与坐标轴平行的分段组成
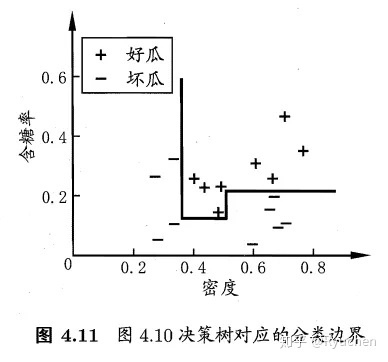
### **多变量决策树(multivariate decision tree)**
特点:非叶结点不再是仅对某个属性进行测试,而是对属性的线性组合进行测试
每一个非叶结点是一个形如 $\sum_{i=1}^dw_ia_i=t$ 的线性分类器,其中 $w_i$ 是属性 $a_i$ 的权重
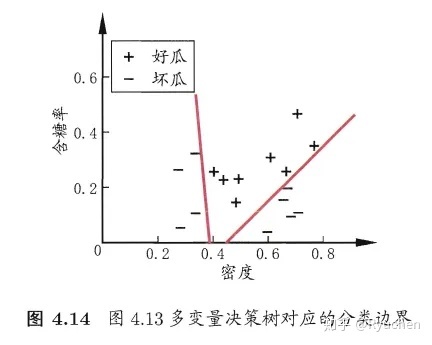

















 371
371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











