







pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/1.8.0/Reinforcement/any/mindspore_rl-0.5.0-py3-none-any.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
git checkout r0.5

这样就可以直接跑起来了。
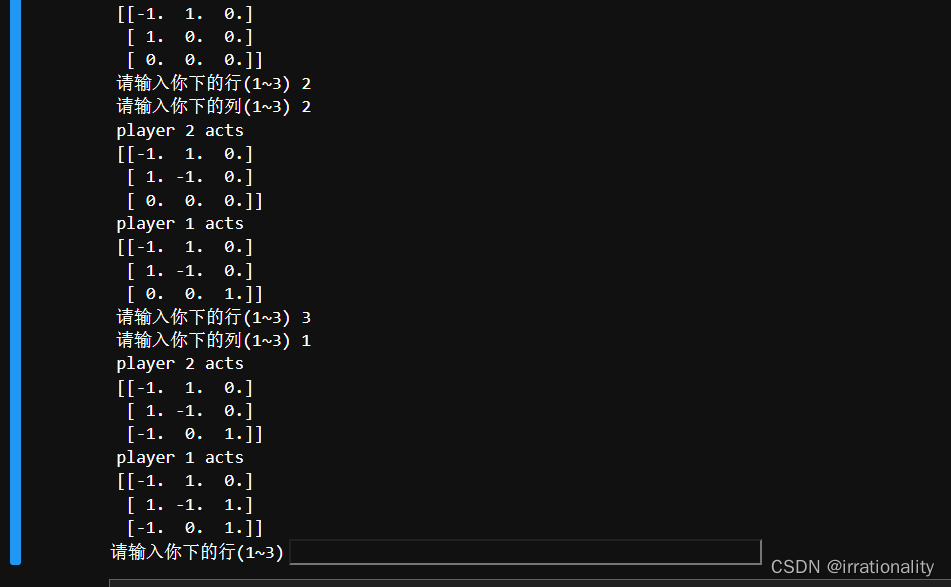
经过非常简单的调整,我们就可以和强化学习下棋了
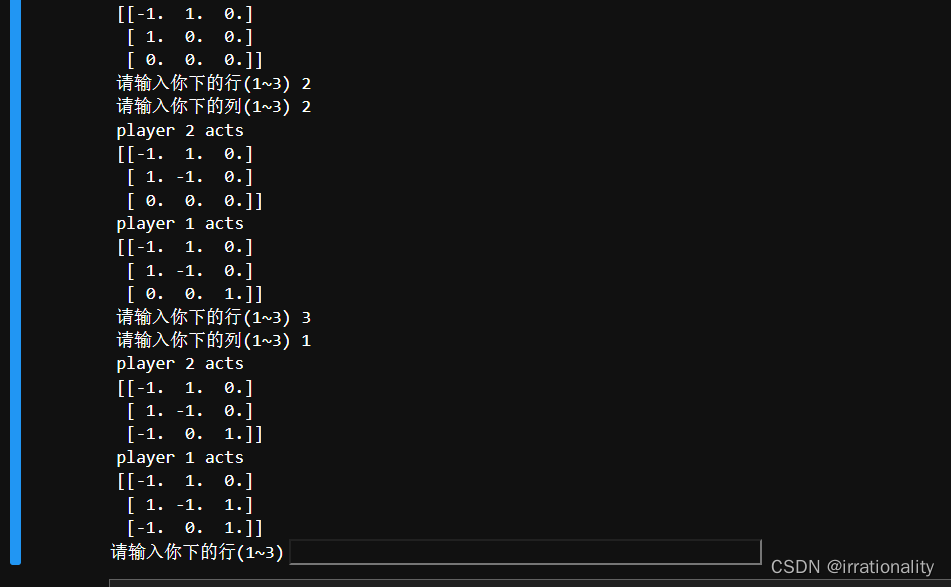

我又一次成功战胜了机器人,真不错。
修改的代码如下
print("player 1 acts")
print(new_state)
if not done:
ckpt = self.env.save()
action = self.mcts.mcts_search(self.uct)
self.env.load(ckpt)
# print(action[0])
a = int(input('请输入你下的行(1~3)'))
b = int(input('请输入你下的列(1~3)'))
x = (a-1)*3+b-1
# print(action[0])
# print(x)
# print(type(action[0]))
action[0] = Tensor(x)
new_state, reward, done = self.env.step(action[0])
print("player 2 acts")
print(new_state)
















 103
103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











