







主要内容
对于分类任务和回归任务来说,机器学习的大体流程都是数据准备、提取特征和标签、划分训练集和测试集、模型选择、模型训练、预测、评估,数据准备会有一个预处理的阶段,这里不过多描述,下面分类任务会以鸢尾花数据集为例,回归任务以波士顿房价为例。
数据准备
鸢尾花和波士顿都是sklearn库内置的数据集,直接使用即可
from sklearn.datasets import load_iris
from sklearn.datasets import load_boston
iris_dataset = load_iris()
boston_dataset = load_boston()我们通过查看数据可知,数据集以字典形式存在,其中data对应的是特征向量,target对应的是标签,feature_names对应的是特征的名称,将数据转换为DataFrame的操作如下:
import pandas as pd
iris_df = pd.DataFrame(iris_dataset.data, columns=iris_dataset.feature_names)
iris_df['target'] = iris_dataset.target
boston_df = pd.DataFrame(boston_dataset.data, columns=boston_dataset.feature_names)
boston_df['prices'] = boston_dataset.target提取特征和标签
数据准备完毕后,我们需要提取数据的特征和标签,操作如下:
iris_feature= iris_df.iloc[:, :-1]
iris_target = iris_df.target
boston_feature = boston_df.iloc[:, :-1]
boston_prices = boston_df.prices对于鸢尾花数据集来说,其特征数比较少,我们可以通过可视化的方式查看特征和标签的关系强度,操作如下:
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure()
sns.pairplot(data=iris_df, hue='target')
plt.show()输出图为:

在图中我们可以看出petal length和petal width这两个特征,对标签的分类效果比较突出,说明这两个特征对于鸢尾花的分类来说比较有价值,但是鸢尾花的特征数比较少,为了保证机器学习的训练效果,我们也对其他特征进行了保留。
对于波士顿房价来说,它的特征数量比较多,我们可以通过可视化的方式来分别查看特征和标签的关系强度,操作如下:
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(4, 3))
for feature in boston_dataset.feature_names:
sns.scatterplot(boston_df[feature], boston_df.prices)
plt.title(feature)
plt.show()输出图如下:





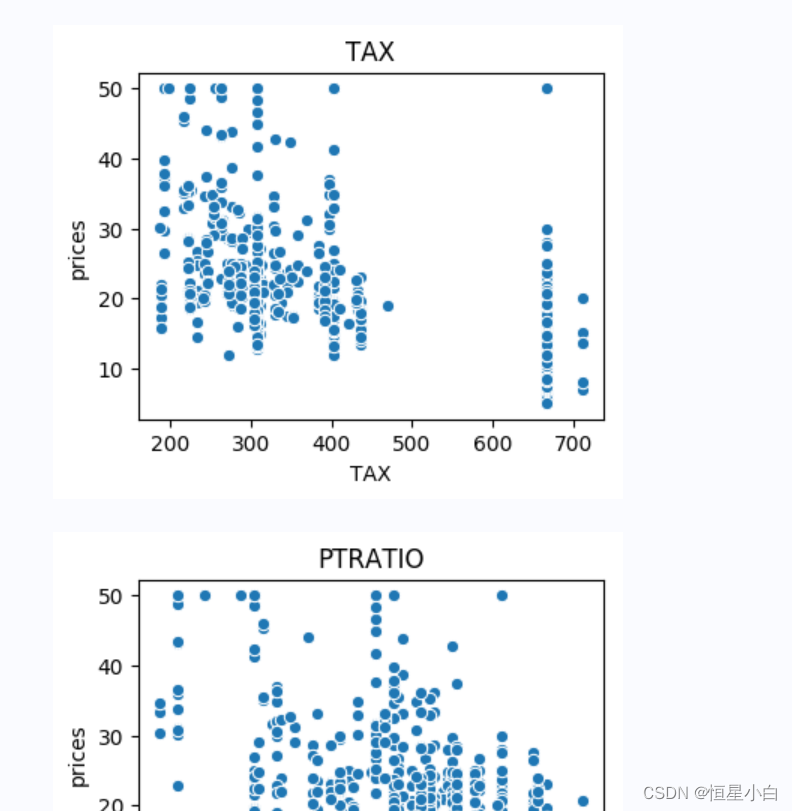

从输出图可以看出LSTAT和RM这两个特征和房价的相关性比较高,为了保证训练的效果,我们再添加2个特征值,操作如下:
boston_feature_select = boston_feature[['RM', 'LSTAT', 'PTRATIO', 'INDUS']]拆分训练集和测试集
训练集主要用于模型的训练,测试集则是为了评价模型的好坏,划分数据集前我们需要打乱原本的数据集,这样可以有效提高模型训练的准确率,比较推荐的方式是直接使用sklearn库里自带的方法,它只需要一行代码就可以同时完成数据的打乱和拆分,操作如下:
from sklearn.model_selection import train_test_split
X_iris_train, X_iris_test, y_iris_train, y_iris_test = train_test_split(iris_feature, iris_target, test_size=0.2, random_state=11)
X_boston_train, X_boston_test, y_boston_train, y_boston_test = train_test_split(boston_feature, boston_prices, test_size=0.2, random_state=12)模型选择
划分训练集和测试集后我们就需要进行模型的选择了,我们也可以同时选择多个模型进行训练,从而选择效果较好的模型
鸢尾花
对于鸢尾花数据集来说,它是个分类任务,对于分类任务我们常用的模型有:逻辑回归、高斯朴素贝叶斯、k近邻、支持向量机、决策树等,操作如下:
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
model_iris_dir = {
'逻辑回归':LogisticRegression(),
'高斯朴素贝叶斯':GaussianNB(),
'K近邻':KNeighborsClassifier(),
'支持向量机':SVC(),
'决策树':DecisionTreeClassifier()
}波士顿房价
对于波士顿房价来说,它是个回归任务,对于回归任务常见的模型有:线性回归、k近邻、支持向量机、决策树、随机森林等
from sklearn.linear_model import LinearRegression
from sklearn.neighbors import KNeighborsRegressor
from sklearn.svm import SVR
from sklearn.tree import DecisionTreeRegressor, ExtraTreeRegressor
model_boston_dir = {
'线性回归':LinearRegression(),
'K近邻回归':KNeighborsRegressor(),
'支持向量机回归':SVR(),
'决策树回归':DecisionTreeRegressor(),
'随机森林回归':ExtraTreeRegressor()
}模型训练、预测和评估
对于训练部分,无论是分类还是回归都是把训练集的特征和标签交给模型去训练,而在预测部分则有一些不同,对于分类任务来说,它的目标十分明确就是分类,预测出来的是类别,而回归任务,以波士顿房价为例,它预测的是房价是一个具体的值,也正是因为这样在评估阶段,分类任务和回归任务的评估方式也有所区别,具体操作如下:
鸢尾花
from sklearn.metrics import accuracy_score
for model in model_iris_dir.items():
model[1].fit(X_iris_train, y_iris_train)
y_pre = model[1].predict(X_iris_test)
acc = accuracy_score(y_true=y_iris_test, y_pred=y_pre)
print(f'{model[0]}的准确率为{acc}')输出如下:
从输出看来,对于这个数据集来讲,k近邻的准确率是最高的100%,如果最后的准确率我们不够满意,我们也可以提高调参或者重新打乱数据集重新进行训练来提高准确率,这里就不过多描述了
波士顿房价
对于房价预测我们不仅拥有多种模型还拥有多种评估指标,例如均方误差MSA、平均绝对误差MAE、R2分数,其中R2分数也被称为拟合优度,R2越大模型的效果越好,其余都是值越小越好,
一般用的最广的就是MAE、MSE,当然我们也可以同时利用多种评估指标,具体操作如下:
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import r2_score
assess_list = []
for model in model_boston_dir.items():
model[1].fit(X_boston_train, y_boston_train)
y_pre = model[1].predict(X_boston_test)
MSE = mean_squared_error(y_true=y_boston_test, y_pred=y_pre)
MAE = mean_absolute_error(y_true=y_boston_test, y_pred=y_pre)
r2 = r2_score(y_true=y_boston_test, y_pred=y_pre)
assess_list.append([MSE, MAE, r2])
assess_df = pd.DataFrame(assess_list, columns=['MSE', 'MAE', 'R2'], index=model_boston_dir.keys())
assess_df输出如下:

从输出我们也可以看出无论是哪个评估指标决策数对这个数据集来讲都是最优解,和分类模型一样如果最后效果有待改善,我们也可以提高调参的方式,如果我们不知道模型的参数我们可以提过
.get_params()查看模型的参数,这里以逻辑回归模型为例,具体操作如下:
LogisticRegression().get_params()输出为:

这样我们就可以知道模型的参数了,如何去调参这里也不过多描述了
总结
无论是分类任务还是回归任务,毫无疑问他们都属于机器学习中的监督学习,因为他们都含有标签,但是只要他们是机器学习任务我们都可以将他们分为7步走,数据准备->提取特征和标签->划分训练集和测试集->模型选择->训练->预测->评估,如果有需要后面也会有调参和模型保存两步骤,以上就是我对监督学习流程的总结,希望对大家有所帮助。















 109
109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











