







目录
协同过滤推荐算法主要分为两种,分别是基于用户的UserCF和基于物品的ItemCF,他们的思想可以浓缩为8个字:“物以类聚,人以群分”。这篇博客主要介绍的是基于用户的推荐算法,也就是8个字中的“人以群分”。我们需要做的就是找到一位和待推荐用户相似度高的用户, 也就是志趣相投的人去给他做推荐,那该怎么使用算法去实现呢?
算法步骤
1、相似度矩阵
首先我们需要去找到用户和用户之间的相似度,这里利用欧式距离来计算用户之间的相似性,以下是欧式距离的计算公式d,最终用户间的相似度为1/(1+d)
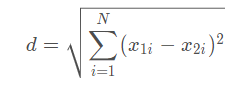
代码实现为:
def similarity(user_v, user2_v):
squares = 0
for v1, v2 in zip(user_v, user2_v):
if np.isnan(v1) or np.isnan(v2):
continue
squares += (v1-v2)**2
similarity = round(1 / (1 + sqrt(squares)), 2)
return similarity函数中的user_v, user2_v分别表示的是两个用户的数据,这里使用的是电影的评分数据,那这两个就分别代表了这两个用户所看电影和他们对电影的评分,数据集如下,对A用户和B用户来说他们共同看过的电影是老炮儿和唐人街探案,那么我们就利用这两个电影的评分来计算相似度,代入欧式距离的计算公式d^2 = (3.5 - 2.5)**2 + (1.0 - 3.5)**2,求得d 约等于2.69,代入相似度计算公式最后得出相似度约为0.27
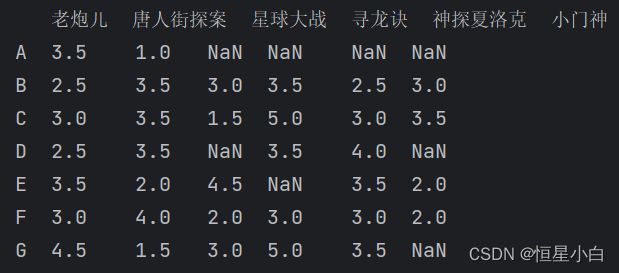
我们也可以计算出完整的相似度矩阵,代码和结果如下:
def similarity_matrix(data_Source):
similarity_matrix = np.zeros((data_Source.shape[0], data_Source.shape[0]))
similarity_matrix = pd.DataFrame(similarity_matrix, columns=data_Source.index, index=data_Source.index)
for i in range(data_Source.shape[0]):
for j in range(i, data_Source.shape[0]):
similarity_matrix.iloc[i, j] = similarity_matrix.iloc[j, i] = similarity(data_Source.iloc[i], data_Source.iloc[j])
return similarity_matrix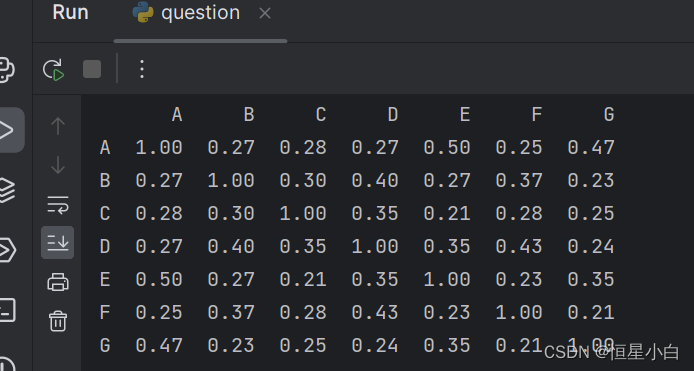
从图中可以看出该矩阵是对称阵,是因为A和B的相似度与B和A的相似度是同一相似度,所以我们只需要关注对称轴左边即可
2、对用户进行推荐
找到用户的相似度矩阵后我们就可以开始对用户做推荐了,首先我们肯定要找到待推荐用户没有看过的电影,这个实现起来也比较简单,这里不过多阐述。然后我们需要分别对待推荐用户没看过的电影做评分,还是以A用户为例,A用户没有看过星球大战,我们需要对它这部影片给A做评分,具体怎么做呢?
首先找到所有看过星球大战的用户,如图所示,他们分别是BCEFG用户,
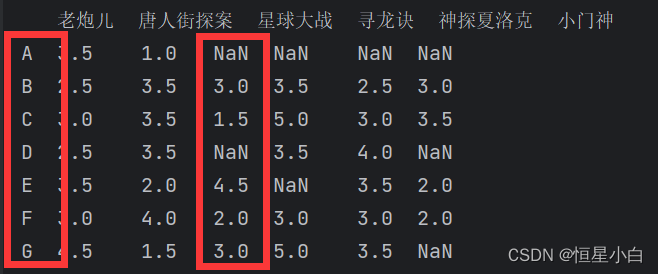
然后我们再找到他们和A用户的相似性,如图所示,他们的相似度分别是AB:0.27, AC:0.28, AE:0.50,AF:0.25,AG:0.47。
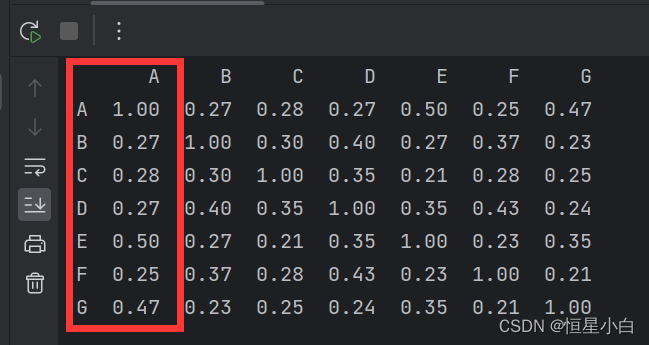
到这里我们需要以他们的相似度作为权重和他们对星球大战的评分作积再求和,即(0.27*3.0+0.28*1.5+0.50*4.5+0.25*2.0+0.47*3.0)=5.39,然后再对权重单独求和,即(0.27+0.28+0.50+0.25+0.47)=1.77,最后再对他们作商得5.39 / 1.77 约等于3.05,这就是我们认为对于A用户来说,他可能会给星球大战打的分数。以下为代码实现:
def recommend(dataSource, user, similarity_matrix, n=None):
recommend_list = []
for col in dataSource.columns:
if np.isnan(dataSource.loc[user, col]):
user_list = []
for index in dataSource.index:
if np.isnan(dataSource.loc[index, col]): continue
user_list.append(index)
recommend_list.append((round(sum(dataSource.loc[user_list, col] * similarity_matrix.loc[user_list, user]) / sum(similarity_matrix.loc[user_list, user]), 2), col))
recommend_list = sorted(recommend_list, reverse=True)
if n:
return recommend_list[:n]
return recommend_list 
函数中的参数分别表示为dataSource:数据来源(DataFrame),user:待推荐用户,similarity_matrix:相似度矩阵,n是可选参数表示输出评分最高的前n部电影,到此基于用户的推荐算法就结束了,下面是完整代码:
import pandas as pd
import numpy as np
from math import sqrt
# 计算相似度
def similarity(user_v, user2_v):
squares = 0
for v1, v2 in zip(user_v, user2_v):
if np.isnan(v1) or np.isnan(v2):
continue
squares += (v1-v2)**2
similarity = round(1 / (1 + sqrt(squares)), 2)
return similarity
# 计算相似度矩阵
def similarity_matrix(data_Source):
similarity_matrix = np.zeros((data_Source.shape[0], data_Source.shape[0]))
similarity_matrix = pd.DataFrame(similarity_matrix, columns=data_Source.index, index=data_Source.index)
for i in range(data_Source.shape[0]):
for j in range(i, data_Source.shape[0]):
similarity_matrix.iloc[i, j] = similarity_matrix.iloc[j, i] = similarity(data_Source.iloc[i], data_Source.iloc[j])
return similarity_matrix
def recommend(dataSource, user, similarity_matrix, n=None):
recommend_list = []
for col in dataSource.columns:
if np.isnan(dataSource.loc[user, col]):
user_list = []
for index in dataSource.index:
if np.isnan(dataSource.loc[index, col]): continue
user_list.append(index)
recommend_list.append((round(sum(dataSource.loc[user_list, col] * similarity_matrix.loc[user_list, user]) / sum(similarity_matrix.loc[user_list, user]), 2), col))
recommend_list = sorted(recommend_list, reverse=True)
if n:
return recommend_list[:n]
return recommend_list
if __name__ == '__main__':
critics = {
'A': {'老炮儿': 3.5, '唐人街探案': 1.0},
'B': {'老炮儿': 2.5, '唐人街探案': 3.5, '星球大战': 3.0, '寻龙诀': 3.5,
'神探夏洛克': 2.5, '小门神': 3.0},
'C': {'老炮儿': 3.0, '唐人街探案': 3.5, '星球大战': 1.5, '寻龙诀': 5.0,
'神探夏洛克': 3.0, '小门神': 3.5},
'D': {'老炮儿': 2.5, '唐人街探案': 3.5, '寻龙诀': 3.5, '神探夏洛克': 4.0},
'E': {'老炮儿': 3.5, '唐人街探案': 2.0, '星球大战': 4.5, '神探夏洛克': 3.5,
'小门神': 2.0},
'F': {'老炮儿': 3.0, '唐人街探案': 4.0, '星球大战': 2.0, '寻龙诀': 3.0,
'神探夏洛克': 3.0, '小门神': 2.0},
'G': {'老炮儿': 4.5, '唐人街探案': 1.5, '星球大战': 3.0, '寻龙诀': 5.0,
'神探夏洛克': 3.5}
}
# 将数据源转换成dataframe/矩阵
data_source = pd.DataFrame(critics).T
recommend_data = recommend(data_source, 'A', similarity_matrix(data_source))
print(recommend_data)总结
最后补充一下基于用户的推荐算法的应用场景,UserCF比较合适用户较多,但是物品较有限,对于本数据集就是电影的情况下比较实用,如果物品种类较多或说物品种类远大于用户情况下,则基于物品的推荐算法ItemCF更为实用,这个后续再介绍。
本小白能力有限,如果哪里解释不清楚或者不正确,欢迎各位大佬在下面评论区提出意见。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











