







案例——中国篮球运动员的基本信息分析
分析目标
1、计算中国男篮、女篮运动员的平均身高与平均体重
2、分析中国篮球运动员的年龄分布
3、计算中国篮球运动员的体质指数
数据获取
先导入可能需要用到的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
读取数据源文件
df_left = pd.read_csv("配套资源/源代码/第6章/运动员信息采集01.csv", encoding="gbk")
df_right = pd.read_excel("配套资源/源代码/第6章/运动员信息采集02.xlsx")
用外连接的方式合并数据
data_df = pd.merge(df_left, df_right, how="outer")
data_df.head()
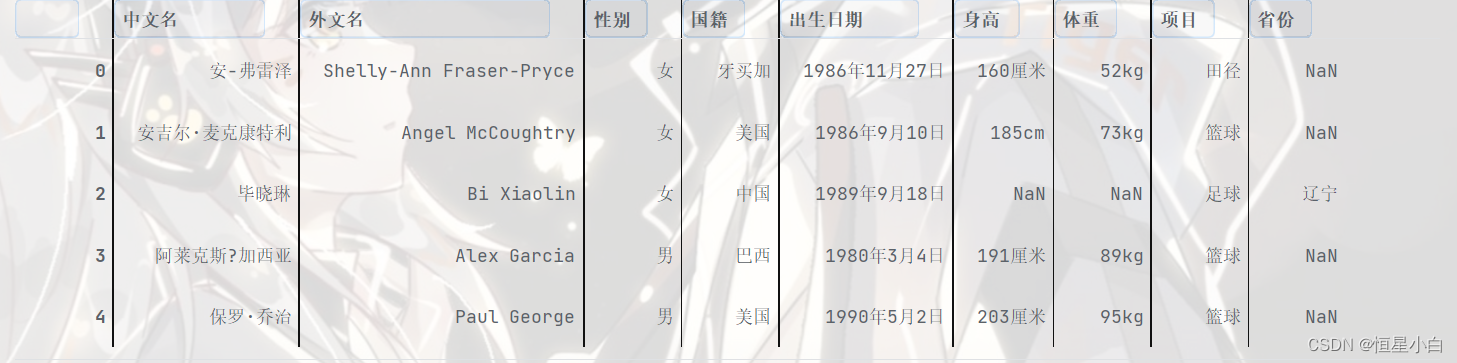
筛选出中国篮球运动员的信息
basketball_data = data_df[data_df['国籍'] == '中国']
basketball_data = basketball_data[basketball_data['项目'] == '篮球']
basketball_data.head()
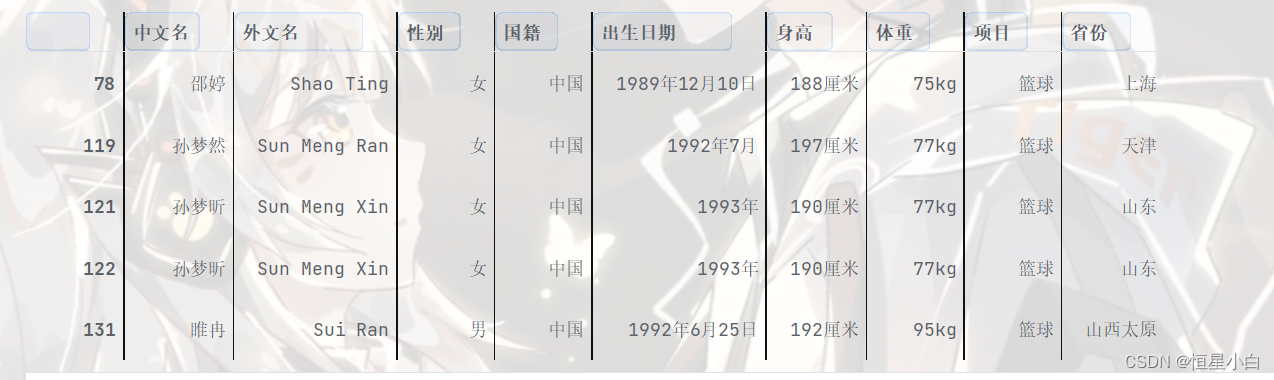
数据清理
检测和处理重复值
检测重复值
basketball_data[basketball_data.duplicated().values == True]

处理重复值
basketball_data.drop_duplicates(ignore_index=True, inplace=True)
basketball_data[basketball_data.duplicated().values == True]

检测和处理缺失值
检测缺失值
basketball_data[basketball_data.isna().values == True]
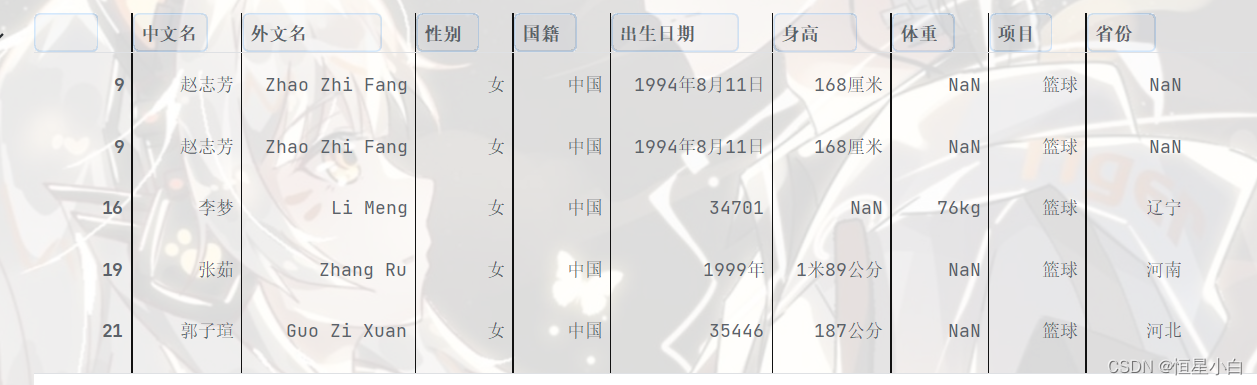
因为省份对分析目的无影响,这里只用处理身高和体重,但是因为男女有差异性,故先分男女两个表。
先处理男表
查看详细信息
male_data = basketball_data[basketball_data['性别'] == '男']
female_data = basketball_data[basketball_data['性别'] == '女']
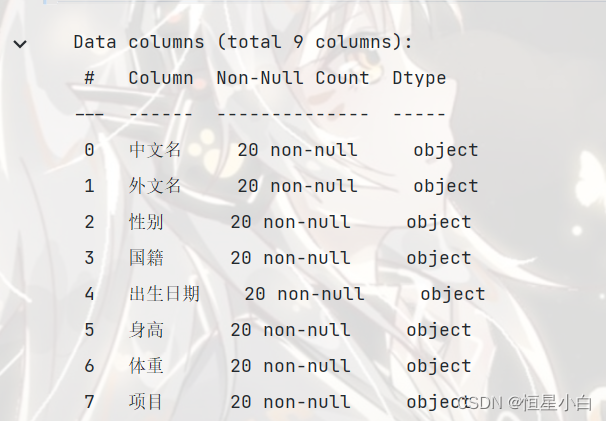
male_data.info()
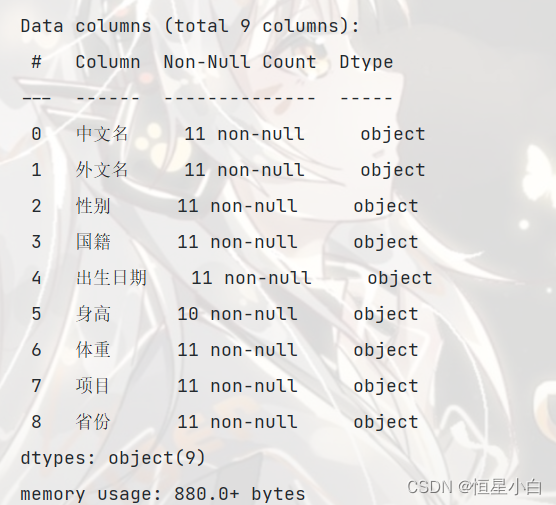
只有身高存在缺失值,查看身高数据
print(male_data['身高'].values)

除了空值,其他都是一样的单位xxx+‘厘米’
开始处理空值,选择用平均值代替
male_heights = male_data['身高'].dropna()
fill_male_height = male_heights.apply(lambda x: x[:-2]).astype(int).mean()
fill_male_height = str(int(fill_male_height)) + '厘米'
male_data.loc[:, '身高'] = male_data.loc[:, '身高'].fillna(fill_male_height)
male_data.info()

男表缺失值处理完成。
开始查看女表信息
female_data.info()

忽略省份,还有身高和体重存在缺失值,先查看身高数据
print(female_data['身高'].values)

存在不一致的数据结构,所以需要先统一将数据变成xxx + “厘米”
data = {'191cm':'191厘米','1米89公分':'189厘米','2.01米':'201厘米',
'187公分':'187厘米','1.97M':'197厘米','1.98米':'198厘米',
'192cm':'192厘米'}
female_data.loc[:, '身高'].replace(data, inplace=True)
print(female_data['身高'].values)

继续处理缺失值,采用平均值来填充
female_heights = female_data['身高'].dropna()
fill_female_height = female_heights.apply(lambda x: x[:-2]).astype(int).mean()
fill_female_height = str(int(fill_female_height)) + '厘米'
female_data.loc[:, '身高'] = female_data.loc[:, '身高'].fillna(fill_female_height)
female_data.info()
身高的缺失值处理完成
开始处理体重缺失值,先查看数据
print(female_data['体重'].values)

发现一个明显的异常数值8kg,决定采用向前填充的方式替换
female_data['体重'].replace(to_replace='8kg', method='pad', inplace=True)
print(female_data['体重'].values)

开始用平均值填充缺失值
female_weights = female_data['体重'].dropna()
fill_female_weight = female_weights.apply(lambda x: x[:-2]).astype(int).mean()
fill_female_weight = str(int(fill_female_weight)) + '厘米'
female_data.loc[:, '体重'] = female_data.loc[:, '体重'].fillna(fill_female_weight)
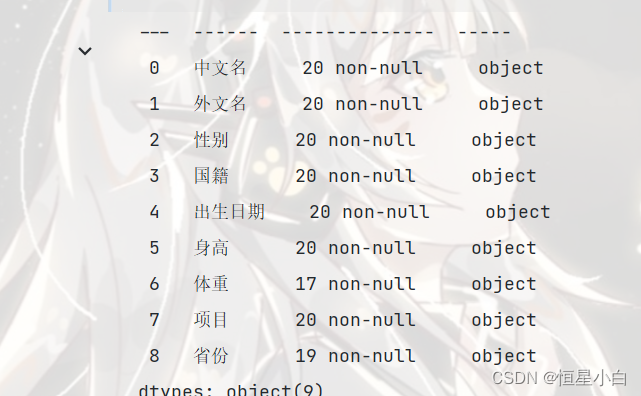
female_data.info()
检测和处理异常值
为了方便计算等操作,选择将身高和体重两列变为int类型,并重新命名列表
male_data['身高'] = male_data['身高'].apply(lambda x: x[:-2]).astype(int)
male_data.rename(columns={'身高': '身高/cm'}, inplace=True)
male_data['体重'] = male_data['体重'].apply(lambda x: x[:-2]).astype(int)
male_data.rename(columns={'体重': '体重/kg'}, inplace=True)
female_data['身高'] = female_data['身高'].apply(lambda x: x[:-2]).astype(int)
female_data.rename(columns={'身高': '身高/cm'}, inplace=True)
female_data['体重'] = female_data['体重'].apply(lambda x: x[:-2]).astype(int)
female_data.rename(columns={'体重': '体重/kg'}, inplace=True)
male_data.head()
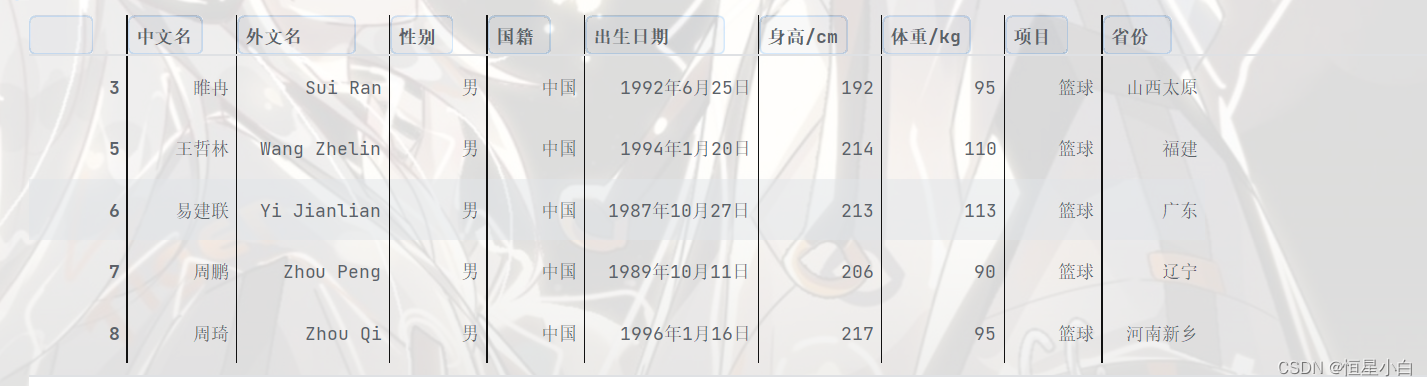
female_data.head()
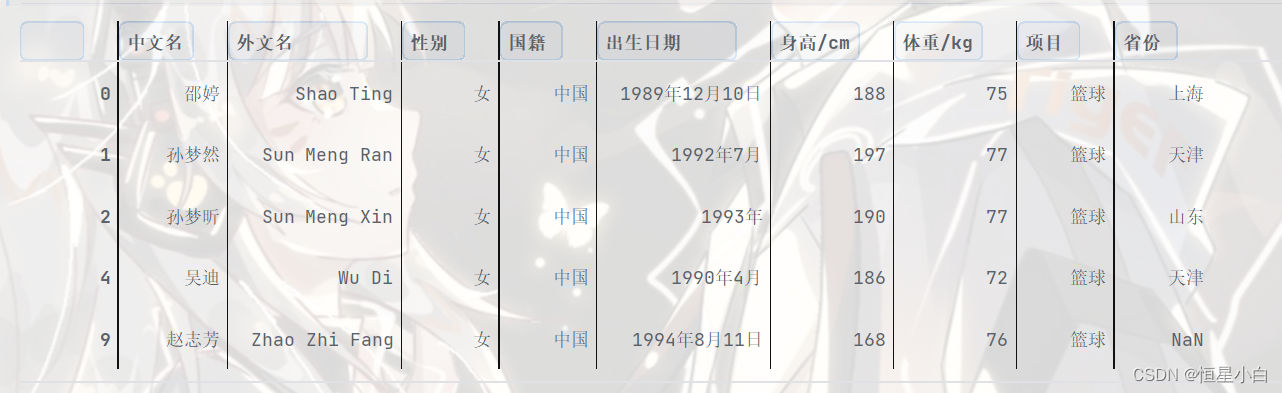
利用箱型图查看男表的身高和体重是否存在异常值
plt.rcParams['font.sans-serif'] = ['SimHei']
male_data.boxplot(column='身高/cm')
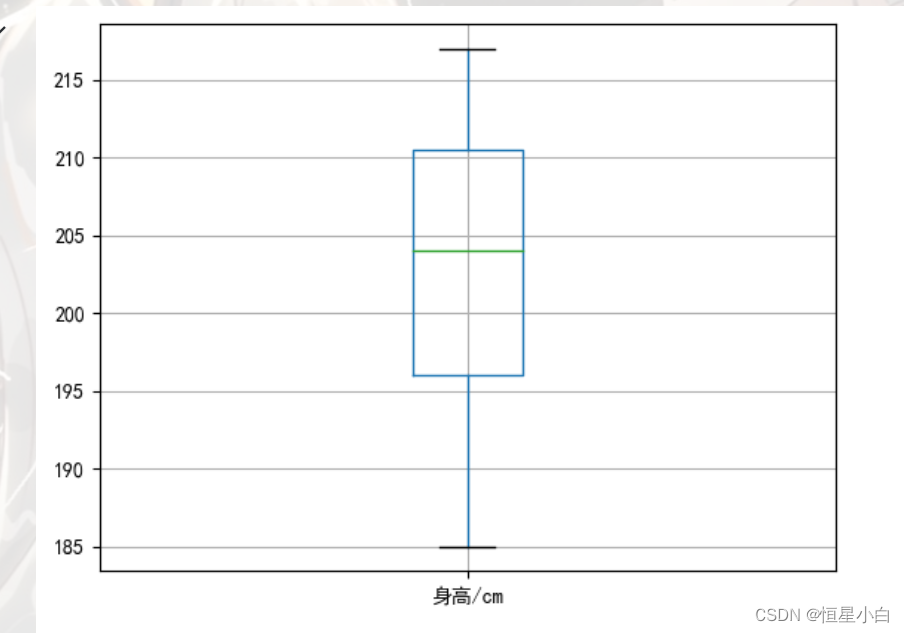
身高不存在异常值
plt.rcParams['font.sans-serif'] = ['SimHei']
male_data.boxplot(column='体重/kg')
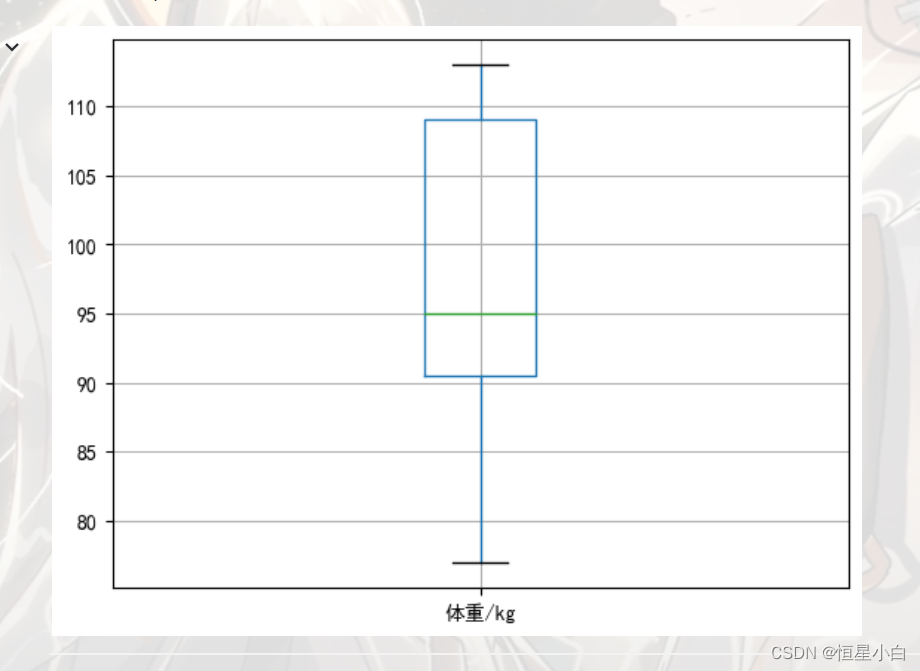
体重也不存在异常值,说明男表数据正常
接下来查看女表数据
plt.rcParams['font.sans-serif'] = ['SimHei']
female_data.boxplot(column='身高/cm')
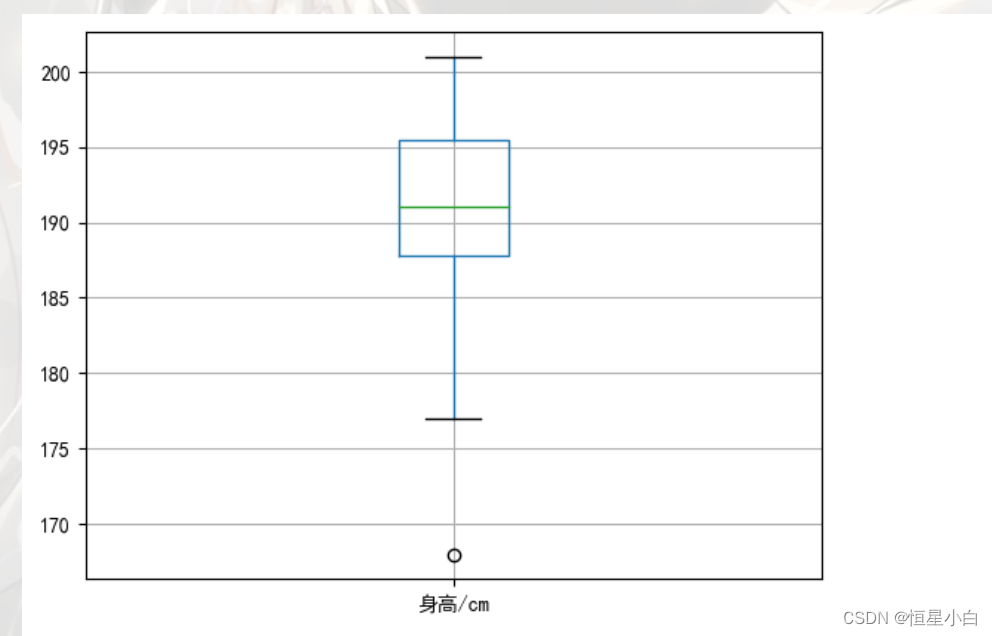
出现一个异常值,但经核实,是真实值
查看体重数据
plt.rcParams['font.sans-serif'] = ['SimHei']
female_data.boxplot(column='体重/kg')
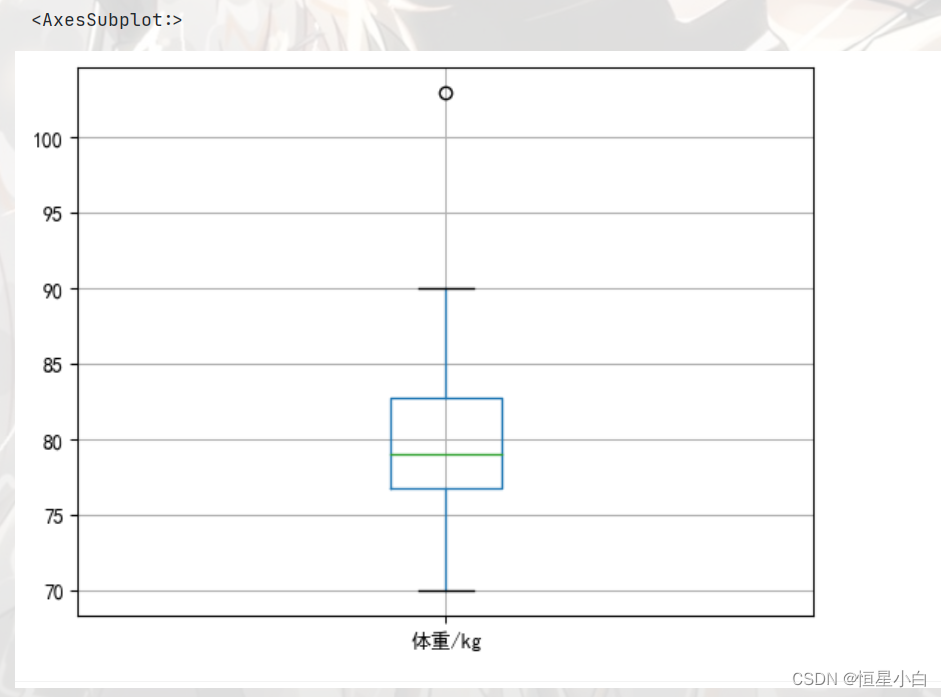
经核实,这个离群点也属于非异常值
如果我们通过箱型图发现了异常值,可以使用下面的函数来找到这个异常值
def box_outliers(ser):
new_ser = ser.sort_values()
if new_ser.count() % 2 == 0:
Q3 = new_ser[int(len(new_ser) / 2):].median()
Q1 = new_ser[:int(len(new_ser) / 2)].median()
elif new_ser.count() % 2 == 1:
Q3 = new_ser[int((len(new_ser) + 1) / 2):].median()
Q1 = new_ser[:int((len(new_ser) + 1) / 2)].median()
IQR = round(Q3 - Q1, 1)
rule = (ser < round(Q1 - 1.5 * IQR, 1)) | (ser > round(Q3 + 1.5 * IQR, 1))
index = np.arange(ser.shape[0])[rule]
outliers = ser.iloc[index]
return outliers
除了通过箱型图,我们也可以通过3sigma原则来验证,
函数实现如下
def three_sigma(ser):
# 计算平均数
mean_data = ser.mean()
# 计算标准差
std_data = ser.std()
# 根据数值小于μ-3σ或大于μ+3σ均为异常值
rule = (mean_data-3*std_data>ser) | (mean_data+3*std_data<ser)
# 返回异常值的位置索引
index = np.arange(ser.shape[0])[rule]
# 获取异常值数据
outliers = ser.iloc[index]
return outliers
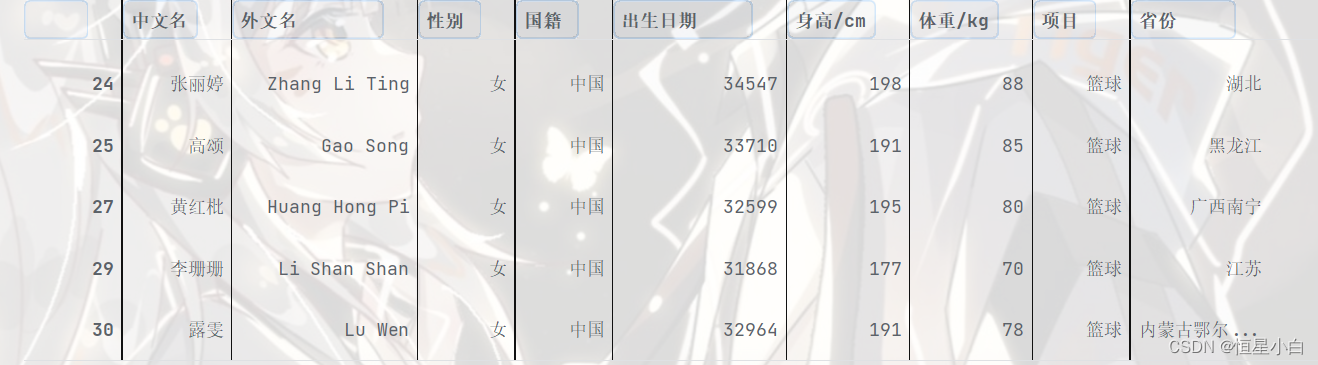
异常值处理完毕,重新将男女两个表合并
basketball_data = pd.concat([male_data, female_data])
basketball_data
实现分析要求
计算中国男篮、女篮的平均身高体重
mean_male_height = basketball_data[basketball_data['性别'] == '男']['身高/cm'].mean()
print(f'中国男篮的平均身高为{int(mean_male_height)}厘米')
mean_male_weight = basketball_data[basketball_data['性别'] == '男']['体重/kg'].mean()
print(f'中国男篮的平均体重为{int(mean_male_weight)}kg')
mean_female_height = basketball_data[basketball_data['性别'] == '女']['身高/cm'].mean()
print(f'中国女篮的平均身高为{int(mean_female_height)}厘米')
mean_female_weight = basketball_data[basketball_data['性别'] == '女']['体重/kg'].mean()
print(f'中国女篮的平均身高为{int(mean_female_weight)}kg')

分析中国篮球运动员的年龄分布
print(basketball_data['出生日期'].values)

先处理数据不一致问题,全部转为年份
import datetime
basketball_data2 = basketball_data.copy()
initial_time = datetime.datetime.strptime('1900-01-01', '%Y-%m-%d')
for i in basketball_data2['出生日期']:
if type(i) == int:
new_time = (initial_time + datetime.timedelta(days=i)).strftime("%Y{y}%m{m}%d{d}").format(y='年', m='月', d='日')
basketball_data2.loc[:, '出生日期'] = basketball_data2.loc[:, '出生日期'].replace(i, new_time)
basketball_data2['出生日期'] = basketball_data2['出生日期'].apply(lambda x: x[:5])
print(basketball_data2['出生日期'].values)

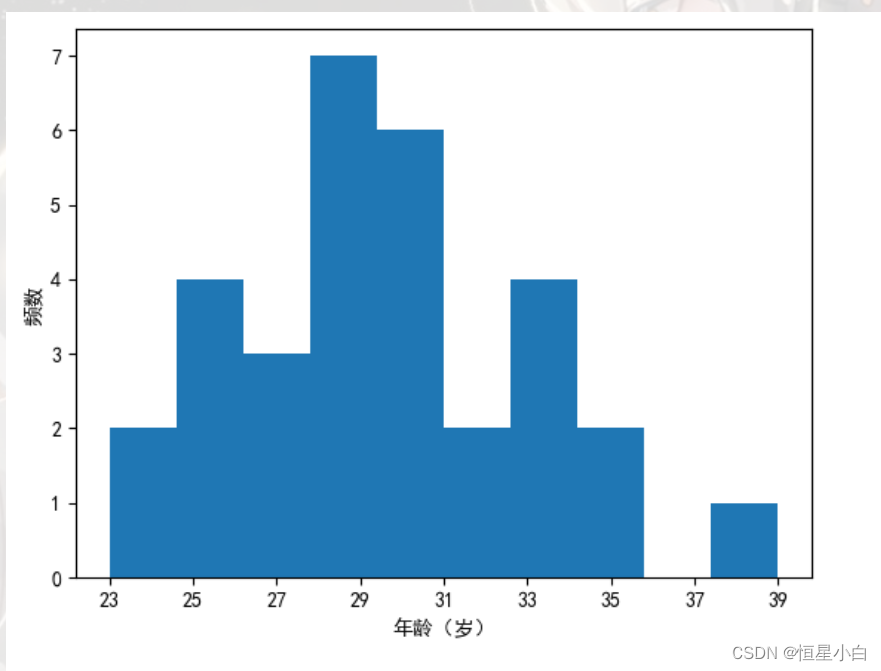
分析中国篮球运动员的年龄分布
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
ages = 2022 - basketball_data2['出生日期'].apply(lambda x: x[:-1]).astype(int)
ax = ages.plot(kind='hist')
ax.set_xlabel('年龄(岁)')
ax.set_ylabel('频数')
ax.set_xticks(range(ages.min(), ages.max() + 1, 2))
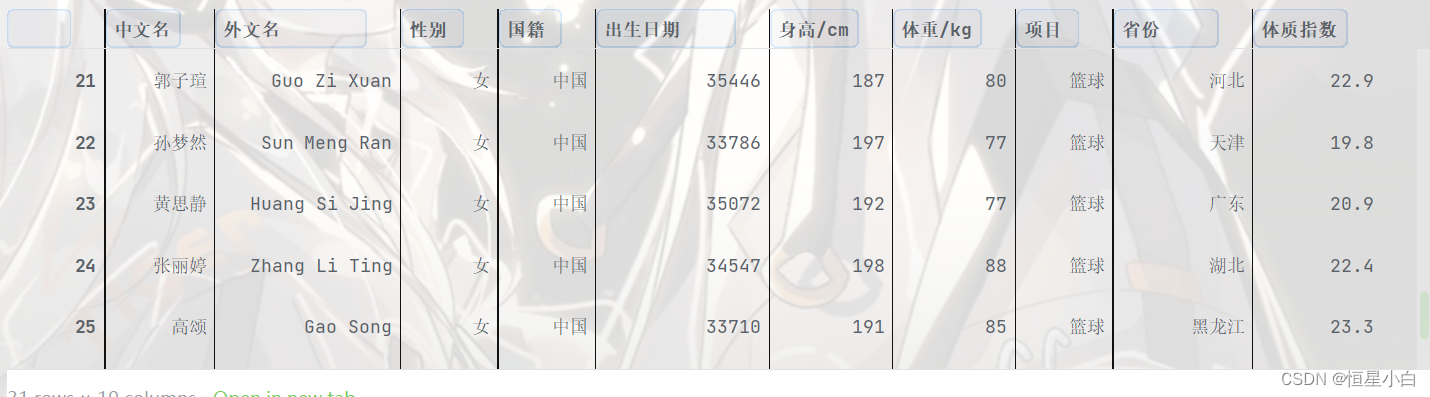
计算中国篮球运动员的体质指数
weight = basketball_data['体重/kg']
height = basketball_data['身高/cm']
sum_bmi = weight / (height / 100)**2
basketball_data['体质指数'] = sum_bmi.round(1)
basketball_data
到此任务完成


















 8278
8278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











