








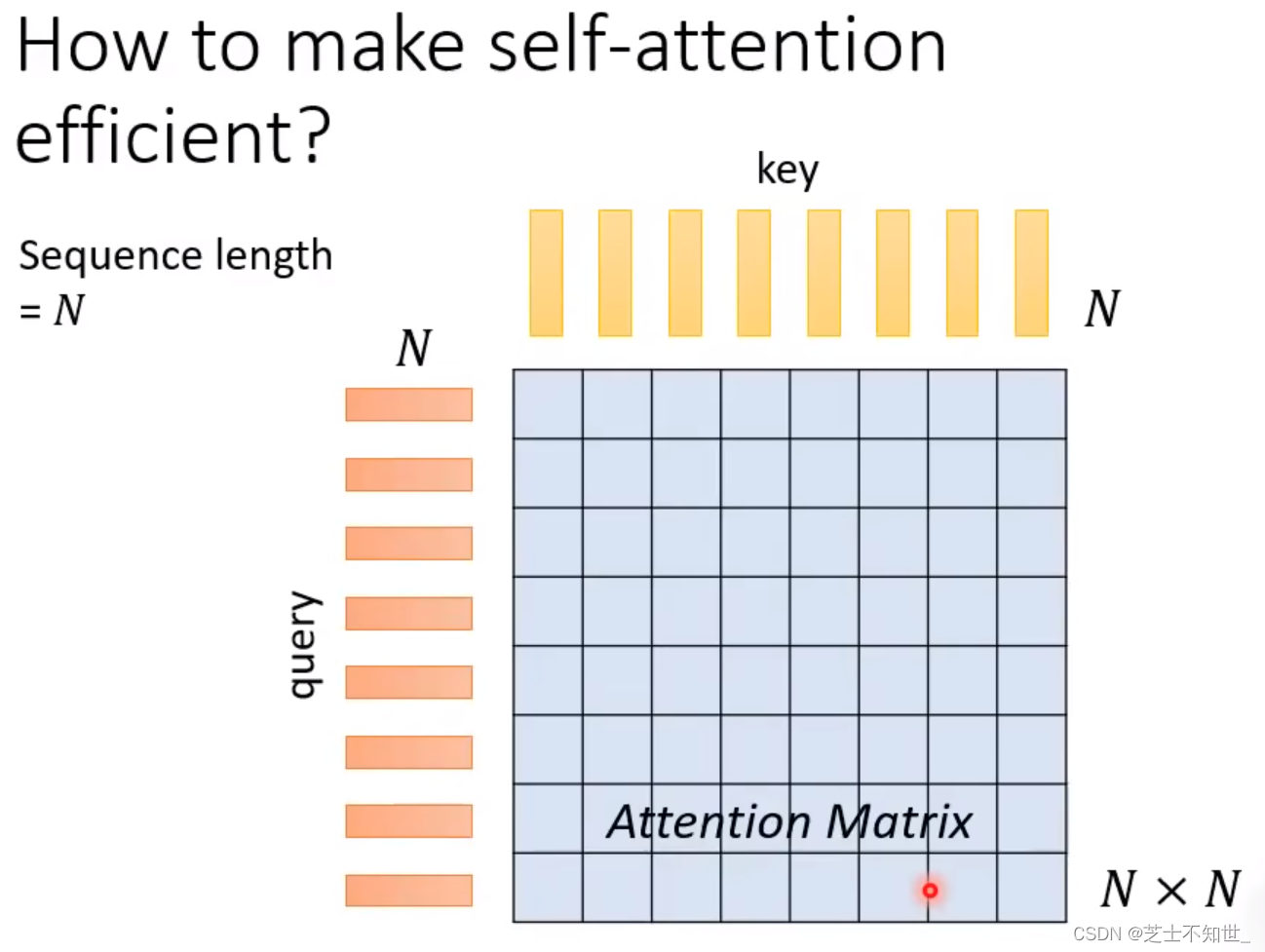
人工设计Self-attention的N*N矩阵
Self-attention处理的是一个sequence序列,它也叫xxFormer系列。
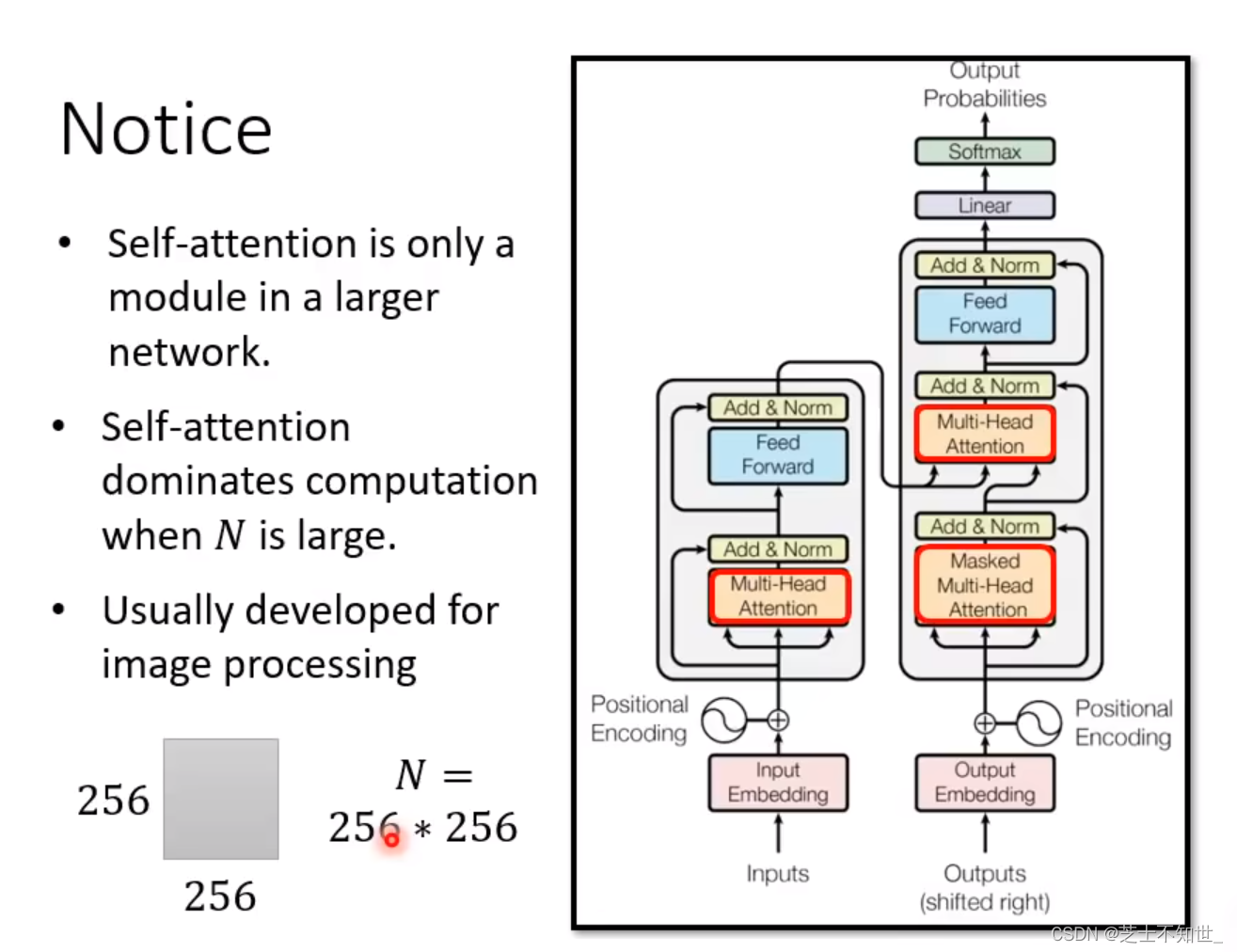
Self-Attention往往只是整个网络的一部分,当输入序列长度非常大时,网络的主要计算量将会取决于Self-Attention的N*N矩阵乘法QxK。所以对其改进常常在CV领域,人为设计矩阵计算, 加快Self Attention的矩阵运算。
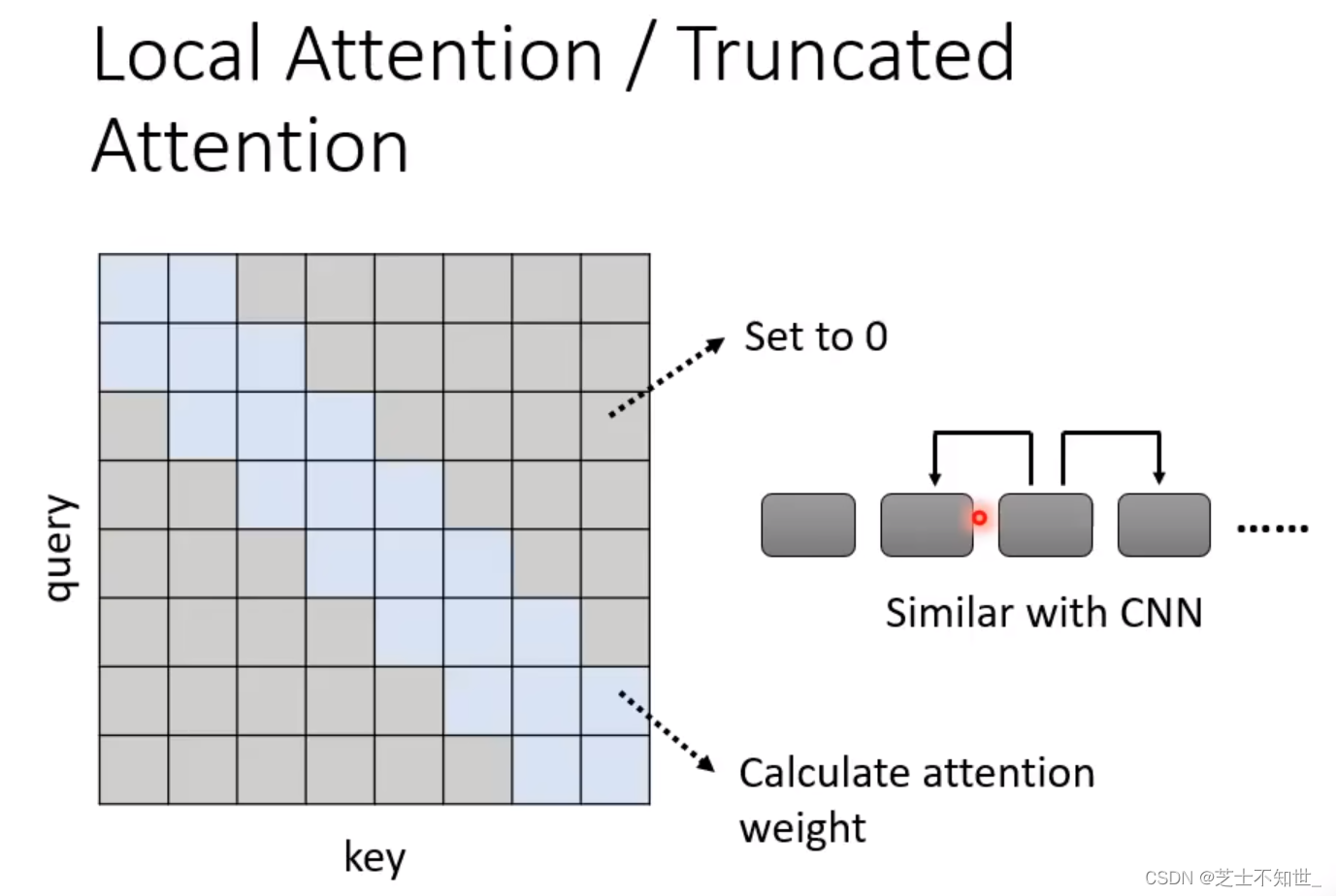
1. Local Attention/Truncated Attention
计算方法:只计算矩阵中蓝色部分值,其余灰色的不用计算(填0)
问题:相当于只关联sequence中相邻的token,失去了Attention的全局性,和CNN的效果就比较相似了,只有局部感受野。
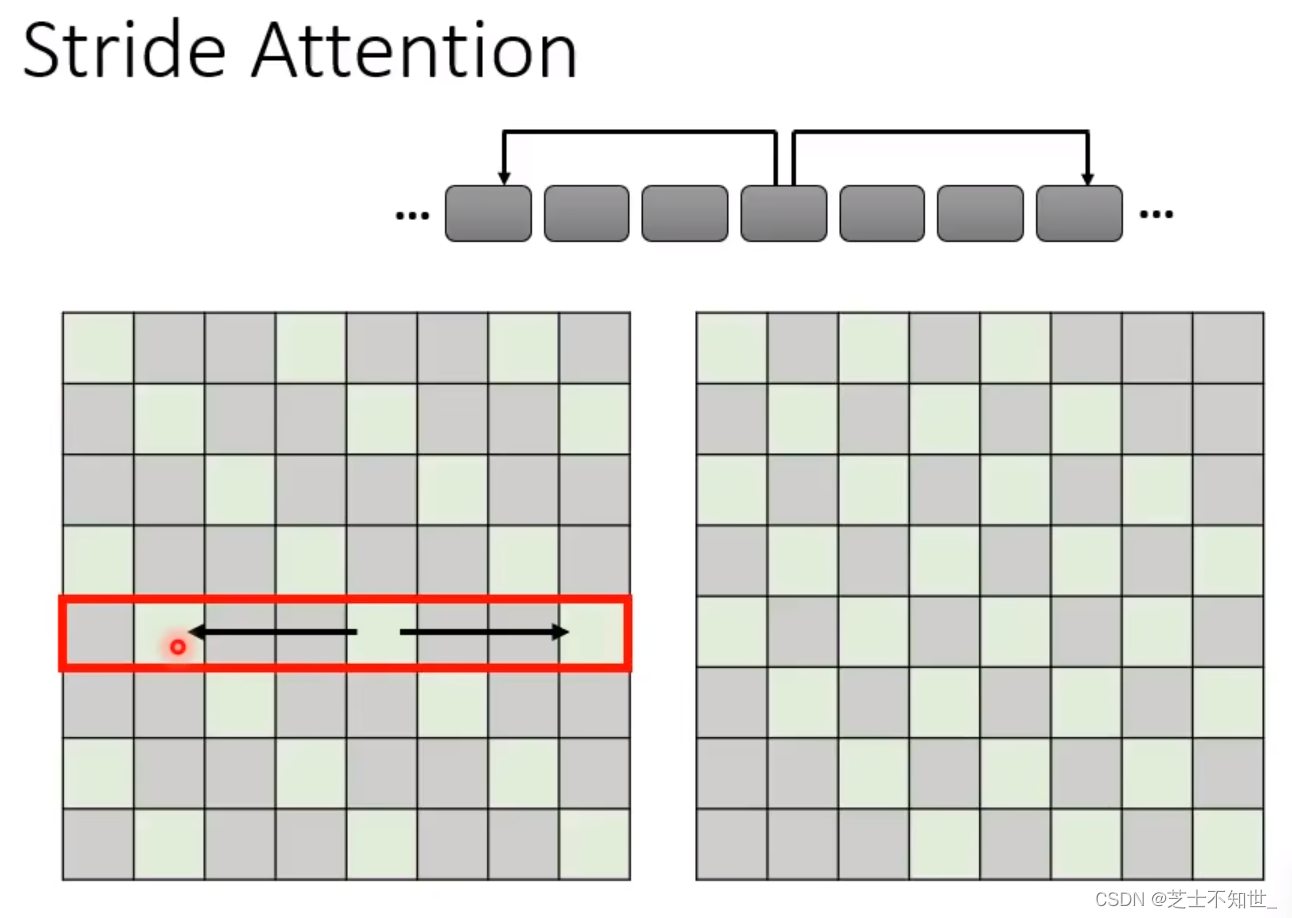
2. Stride Attention
计算方法:只计算矩阵中青色部分值,其余灰色的不用计算(填0)
问题:相当于关联sequence中间隔stride步长的token,增加了Local Attention的感受野大小,类似于空洞卷积,但依然无法关注到全局的token信息。
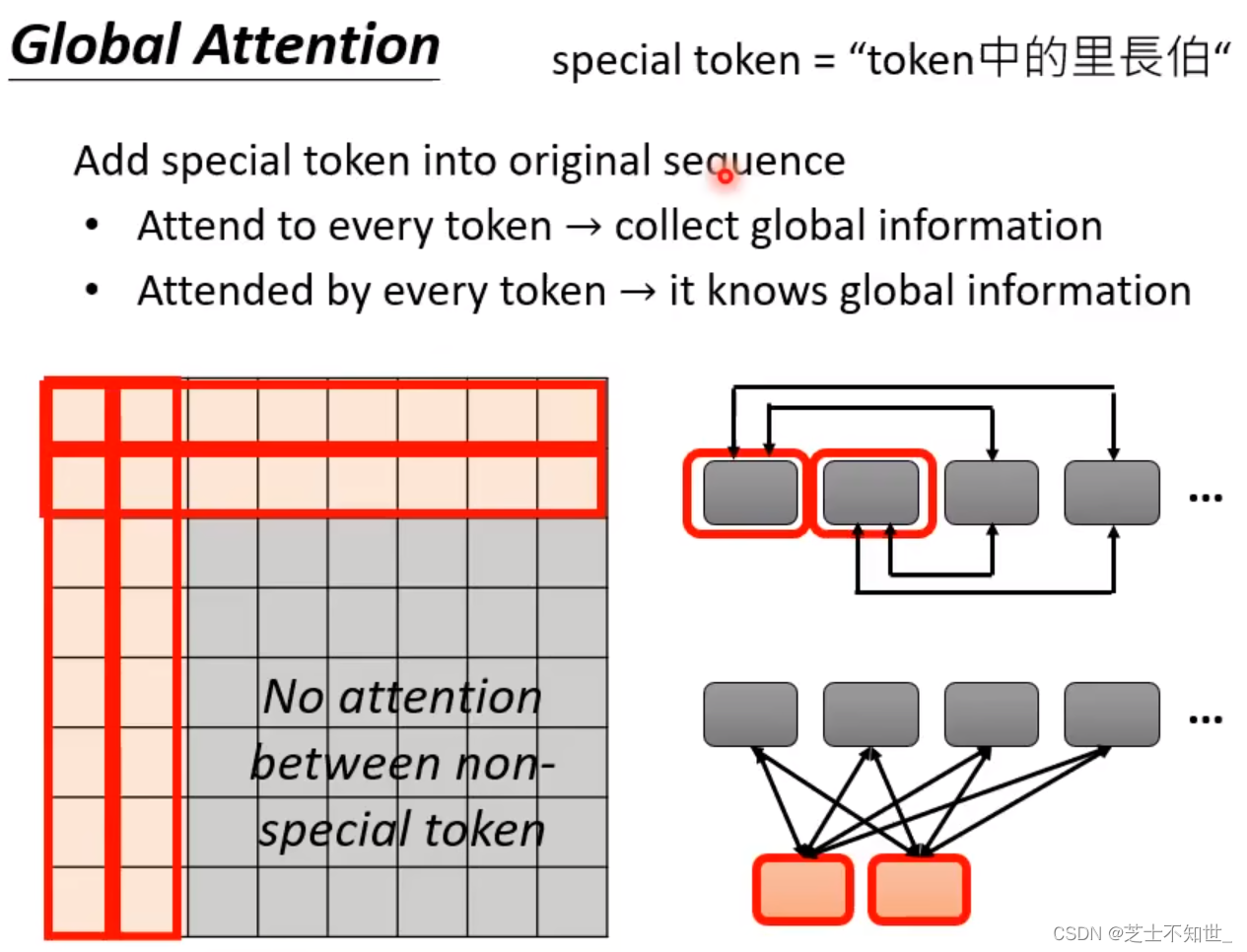
3. Global Attention
计算方法:只计算矩阵中橙色部分值(对应两个sepcial tokens与所有tokens进行交互),其余灰色的不用计算(填0)
两种类型:①直接选取原sequence中的几个token做sepcial token。②额外补充两个tokne做sepcial token(如CLS token)。
意义:将sepcial token与其余所有tokens进行交互,既在矩阵运算方面减少了计算量,有保证了sepcial token包含全局sequence token信息。
人工设计Self Attention的使用与选择
不同的Self Attention各有所长,可以使用Mutile-Head Attention,在不同的head使用不同的Self Attention。
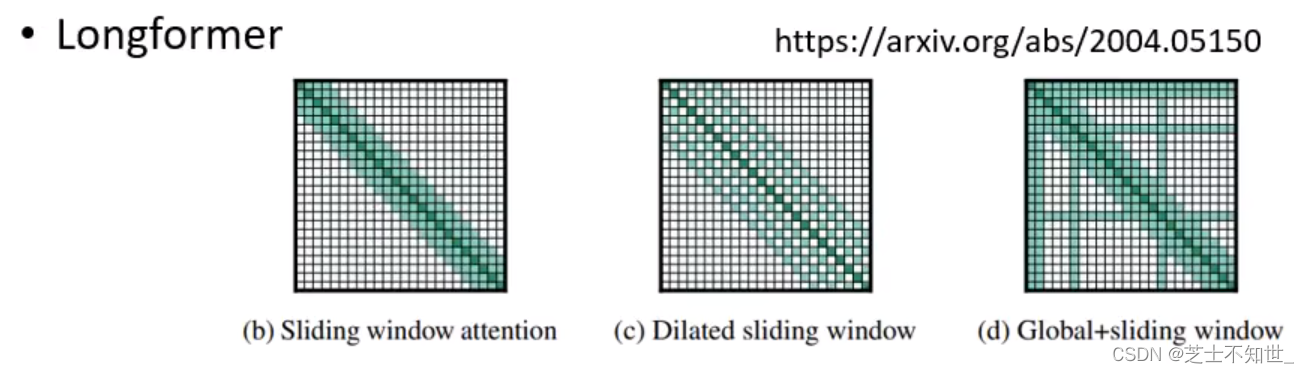
1.LongFomer
三个Head:Local Attention+Stride Attention+Global Attention
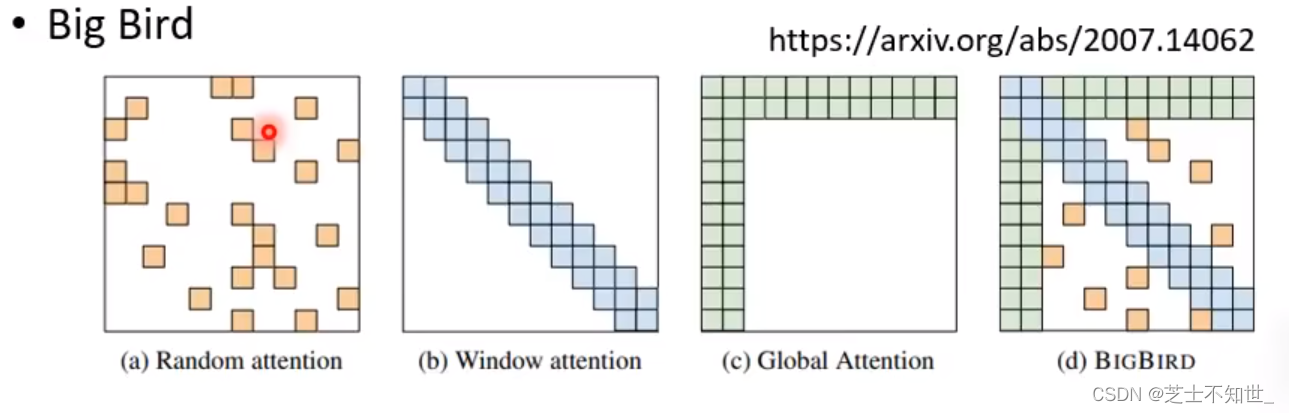
2.Big Bird
四个Head:Random Attention+Local Attention+Stride Attention+Global Attention
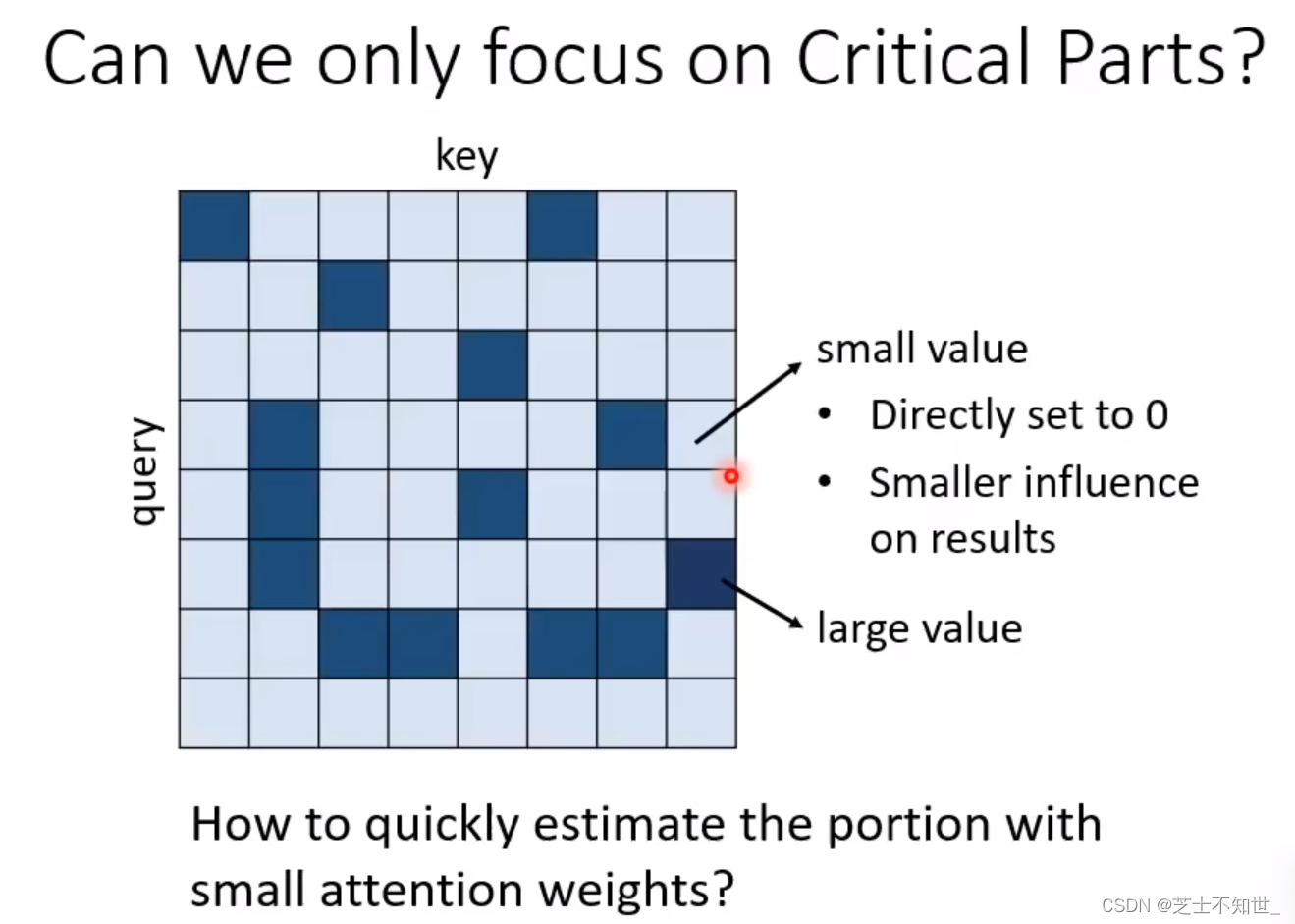
自动设计Self Attention的N*N矩阵
引入类似模型加速的思想,小值(不重要的值)对结果的影响较小,把小值设0,加速模型运算。
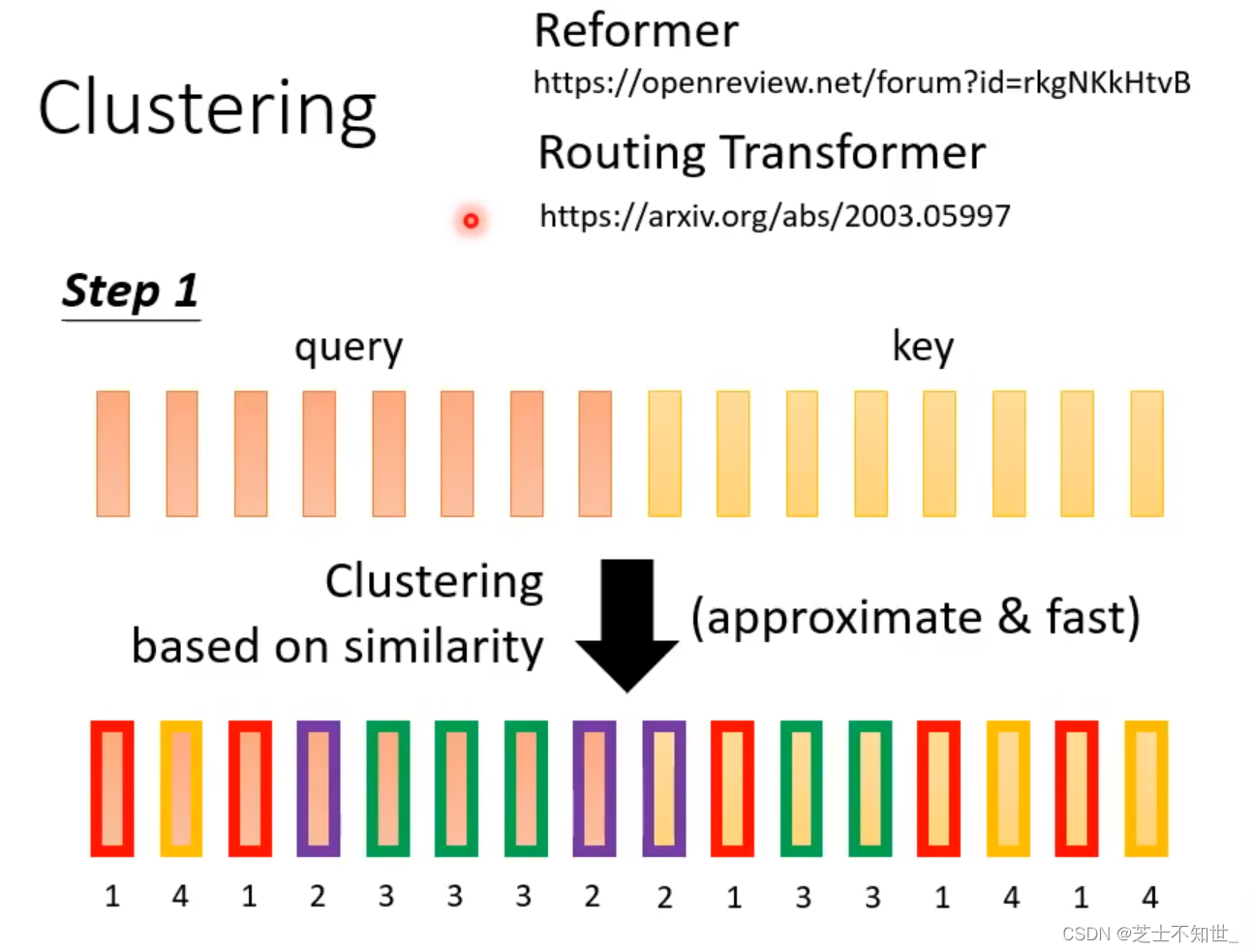
1. Reformer
小值:不是同一类的token运算的值。
计算方法:
Step1:先将Q和K放在一起进行聚类,相似的token会被分为同一个类。
Step2:在QxK矩阵运算中,只有同一个类的token才会被计算,其他的位置直接填0。
意义:聚类计算,虽然在聚类的过程中是由机器完成的,但同类计算这个规则是由人为规定的,还不是完全的自动设计(即完全自动learn要计算那些值)

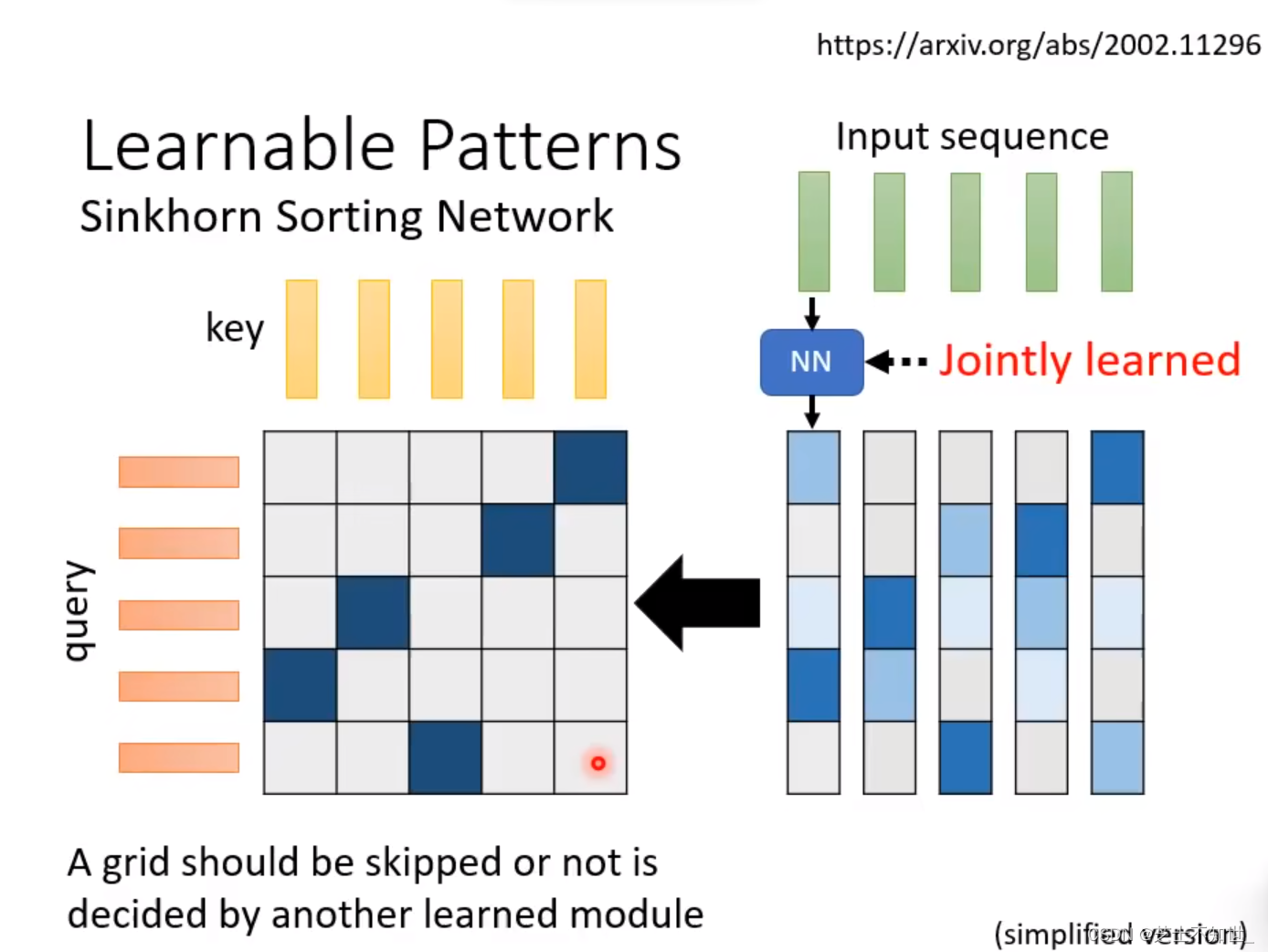
2.Sinkborn Sorting Network
设置一个前置Network,学习QxK矩阵中那些值需要计算,这个Network是可以和整个网络一起训练的。
意义:实现了自动设计N*N矩阵的运算。
不需要N*N大小的矩阵
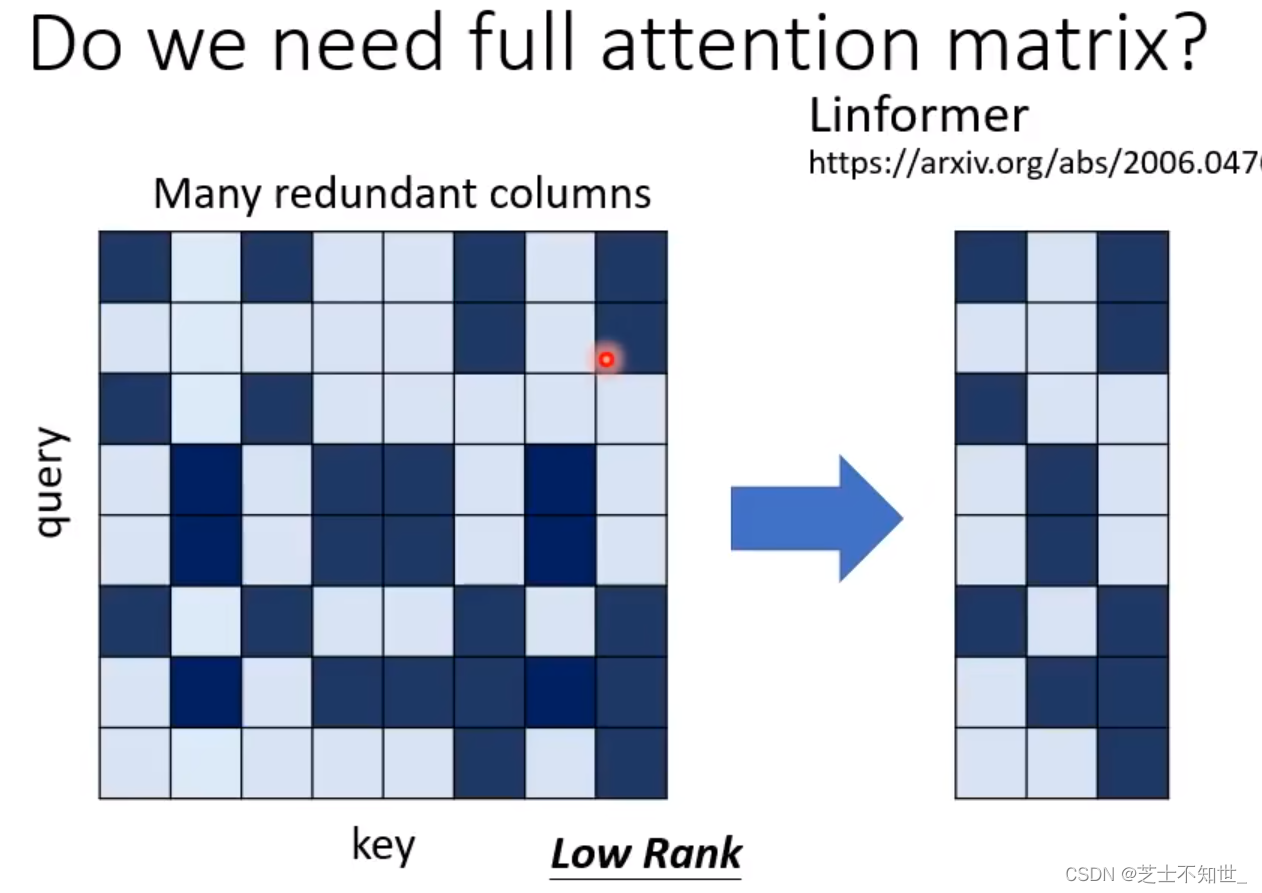
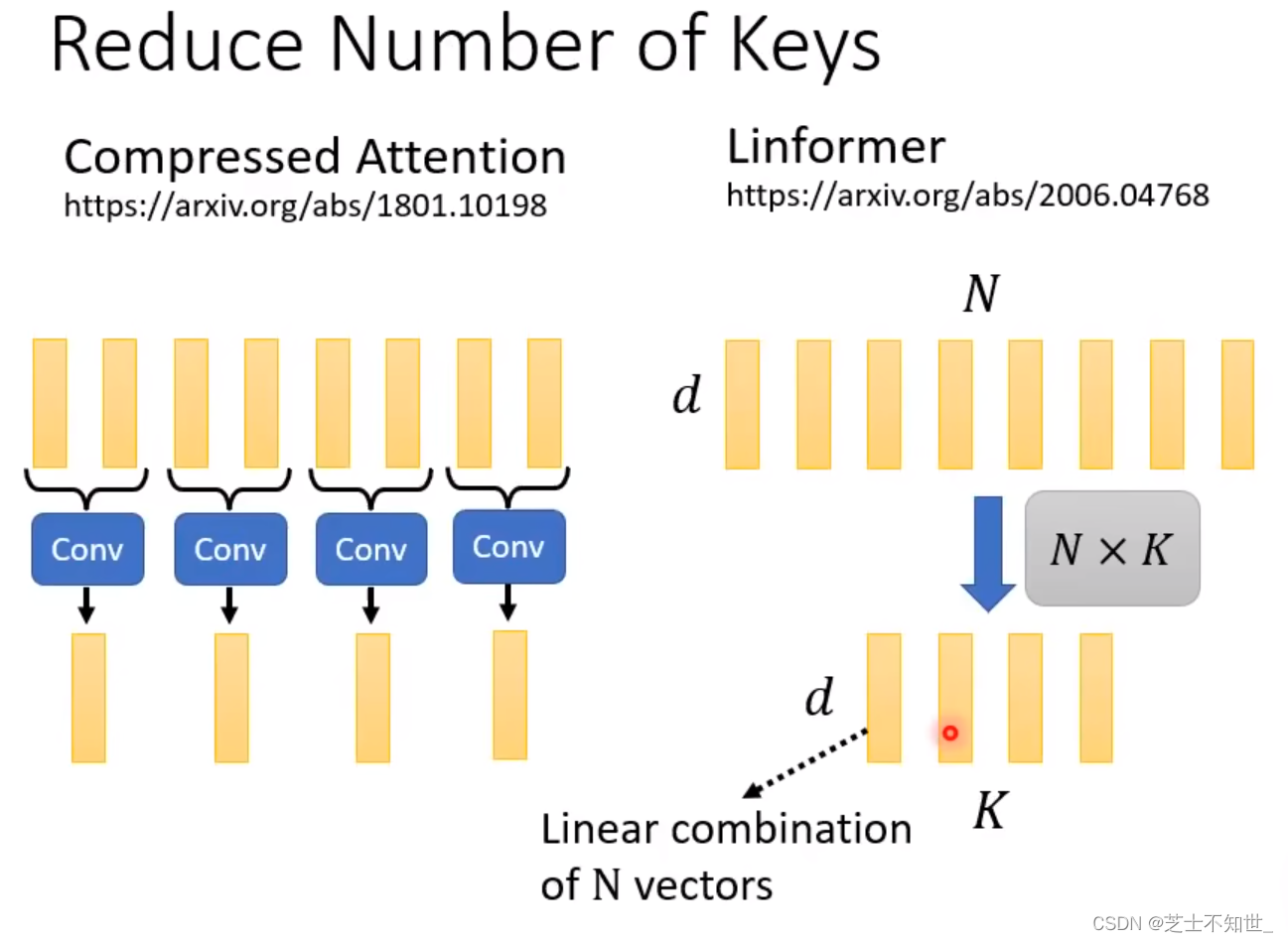
1.Linformer和Comperssed Attention
计算方法:从N个key中选出/算出K个代表,同样value也选出K个代表,与query进行计算,只需要计算KxN的矩阵。
为什么不让query也选出K个代表计算?
因为如果query也减少,那么输出的sequence的长度将小于N个,对于某些任务,Self Attention不应改变输入sequence的长度。
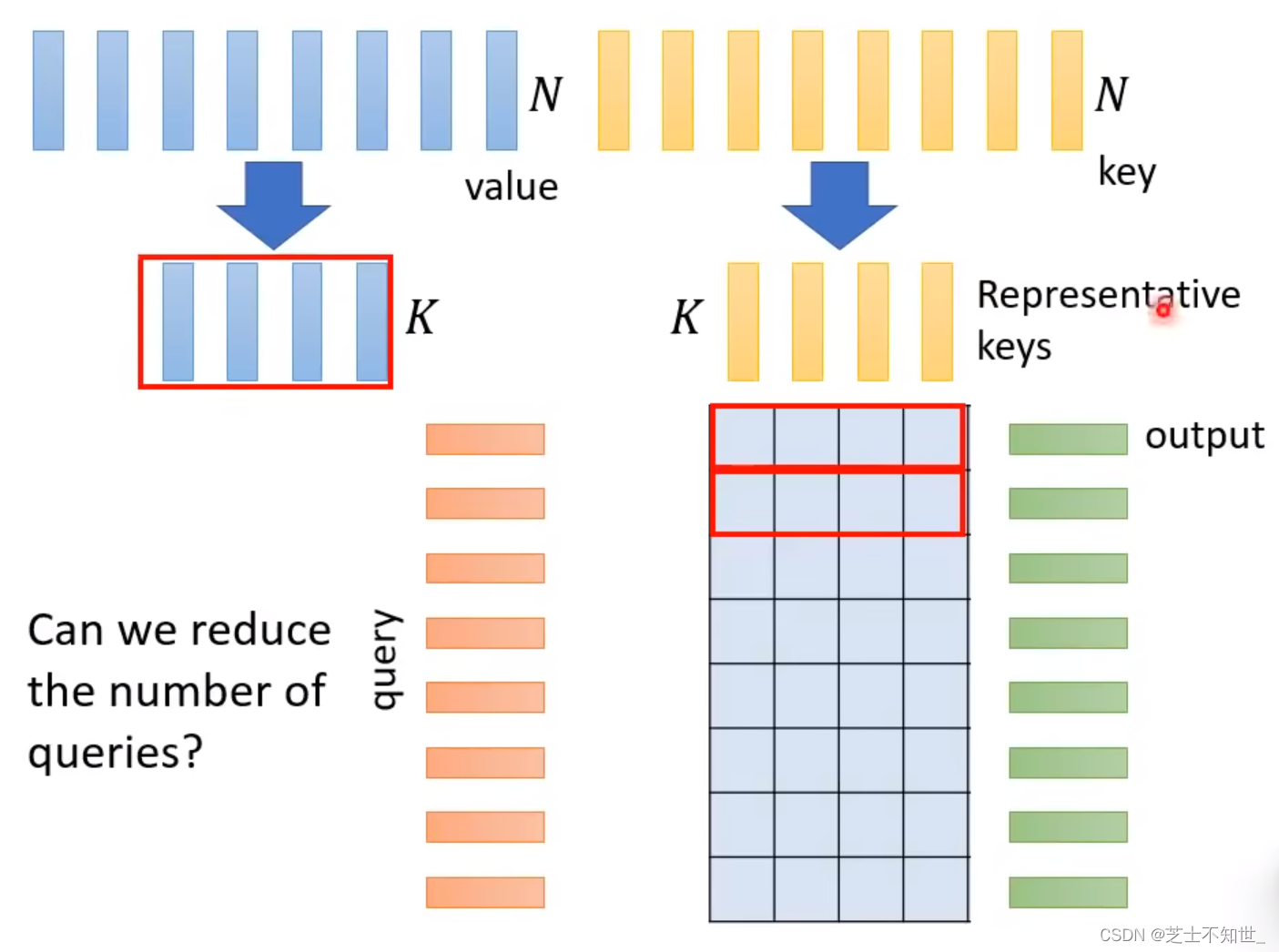
选出/算出,减少key的方法:
Comperssed Attention:用卷积减少key。
Linformer:将N个key进行线性结合(乘NxK的矩阵)
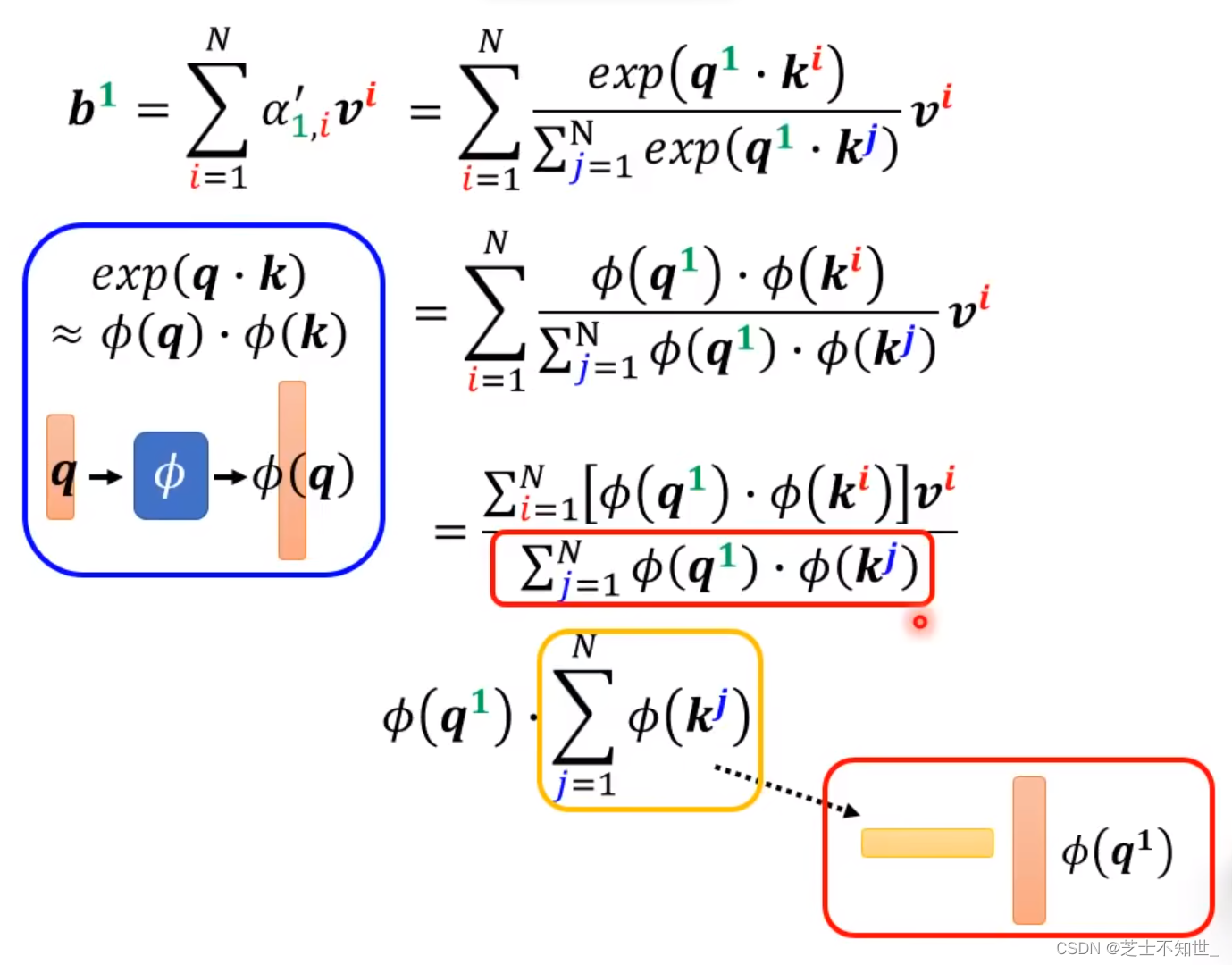
从Attention本质改进矩阵运算
如果忽略softmax,Attention的本质就是QKV矩阵乘法
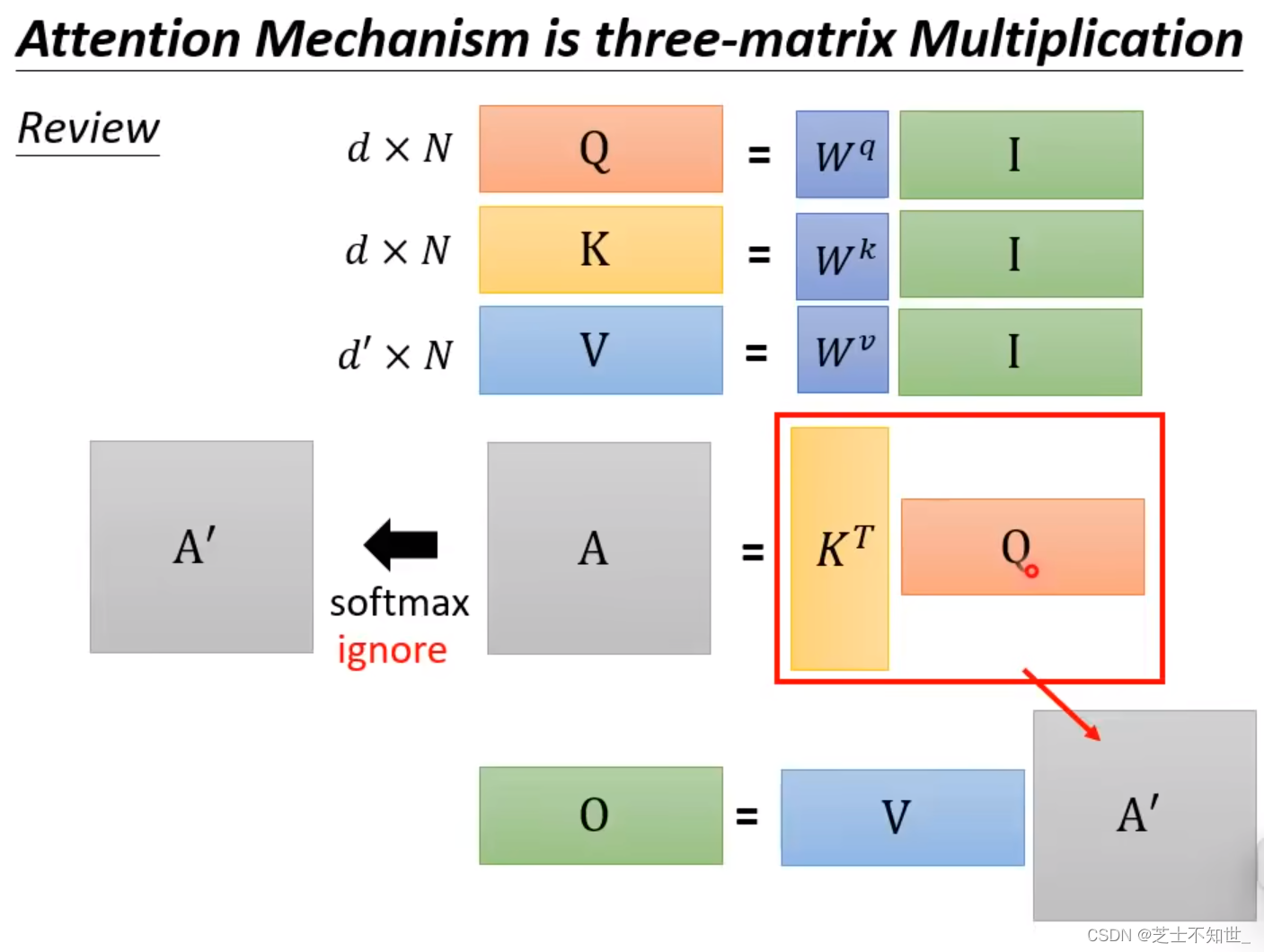
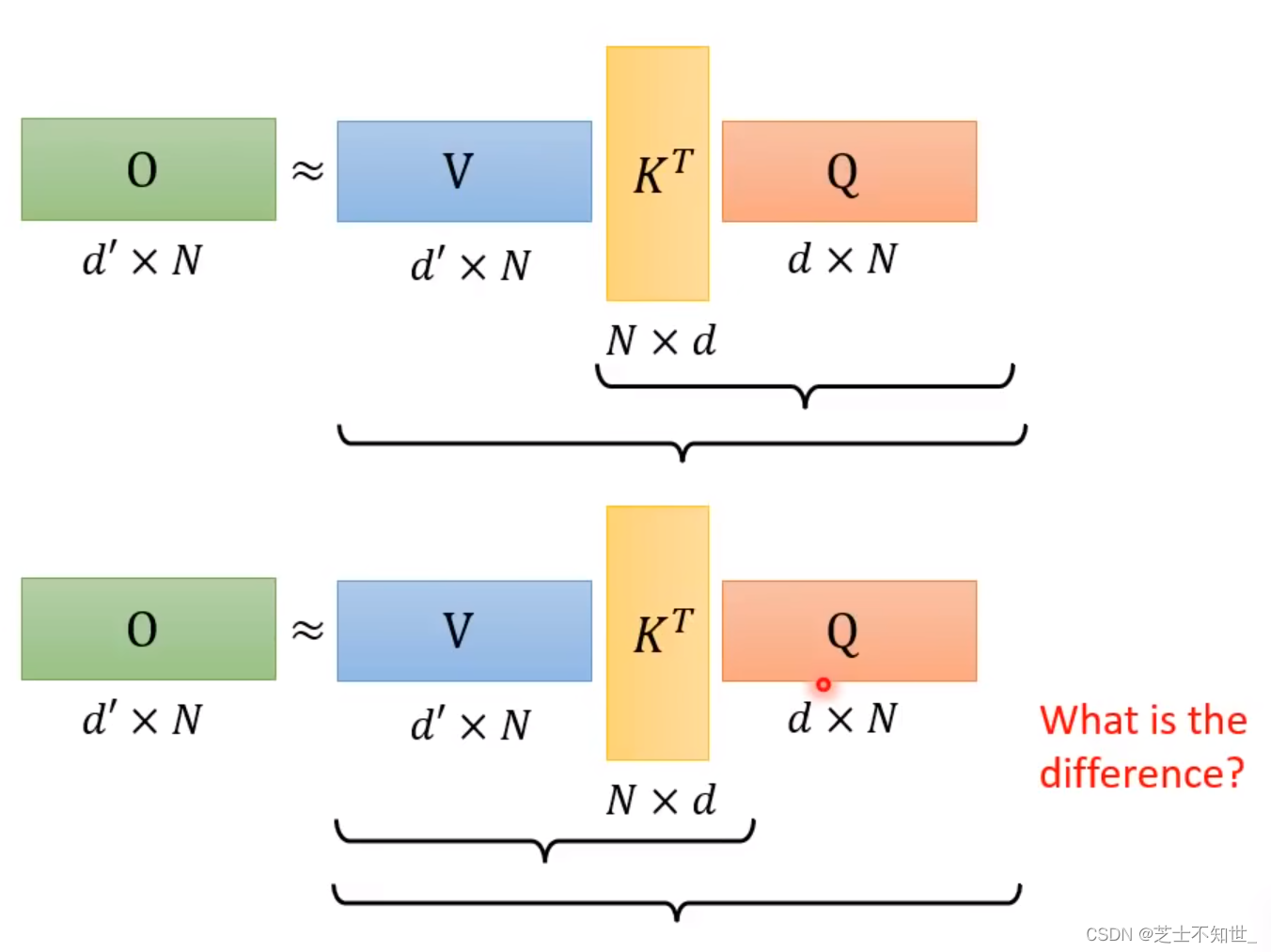
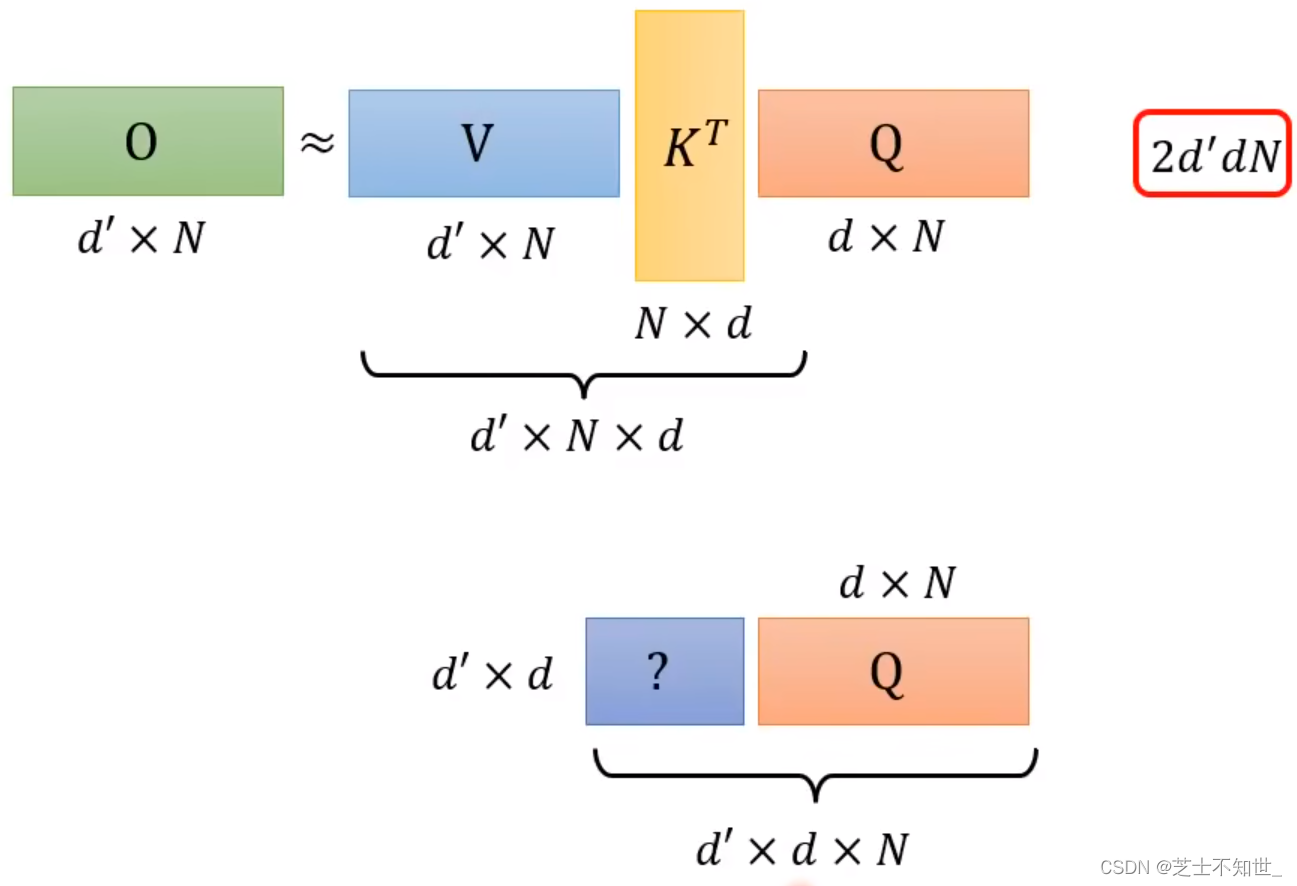
QKV三矩阵运算的先后顺序不同,计算量不同。
计算量:(VK)Q < V(KQ)
V(KQ)的乘法次数:(d+d’)x N平方 -》 N平方数量级
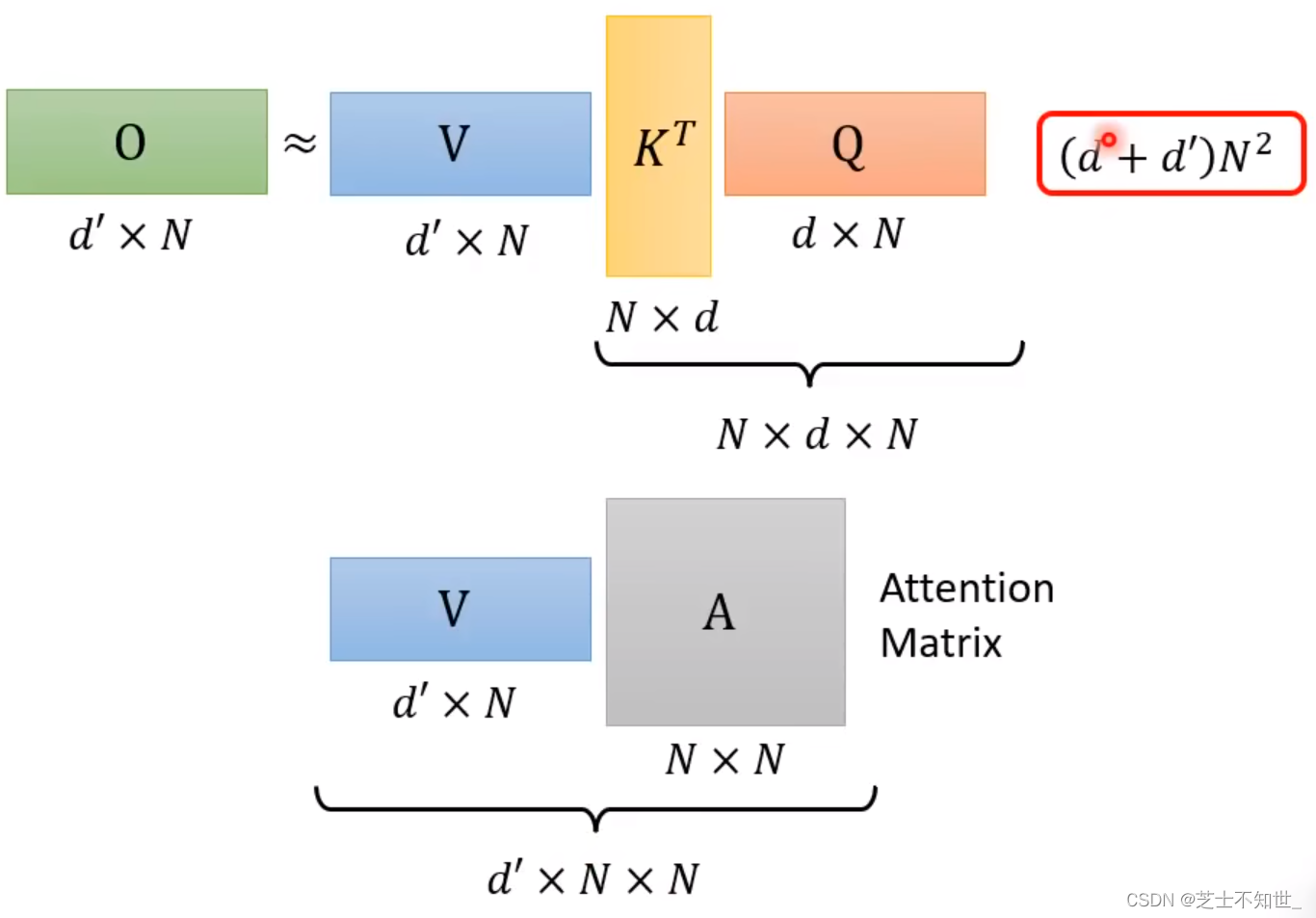
(VK)Q的乘法次数:2d’dN -》 N数量级
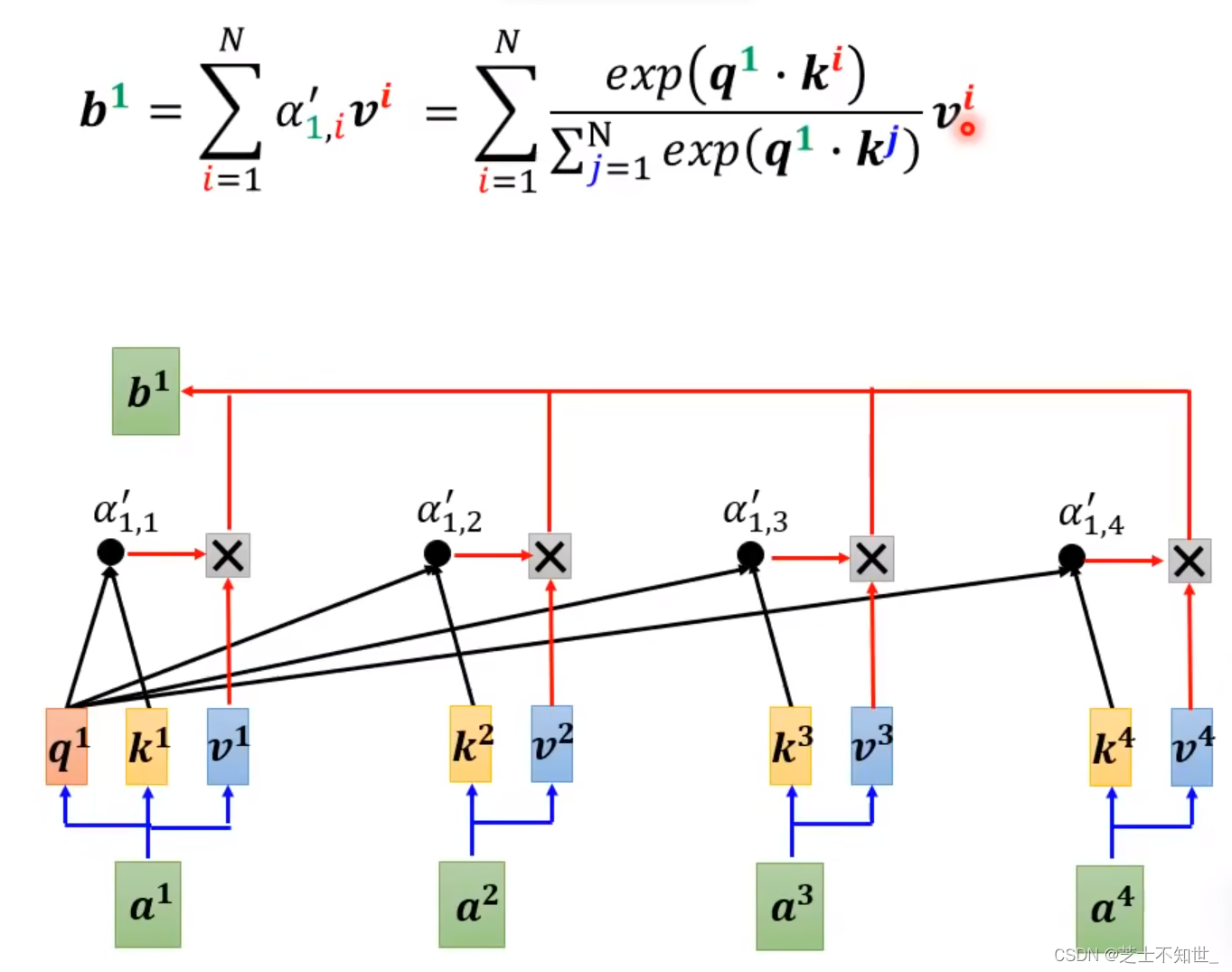
原先V(KQ)含softmax的计算过程:
简化后(VK)Q含softmax的过程:

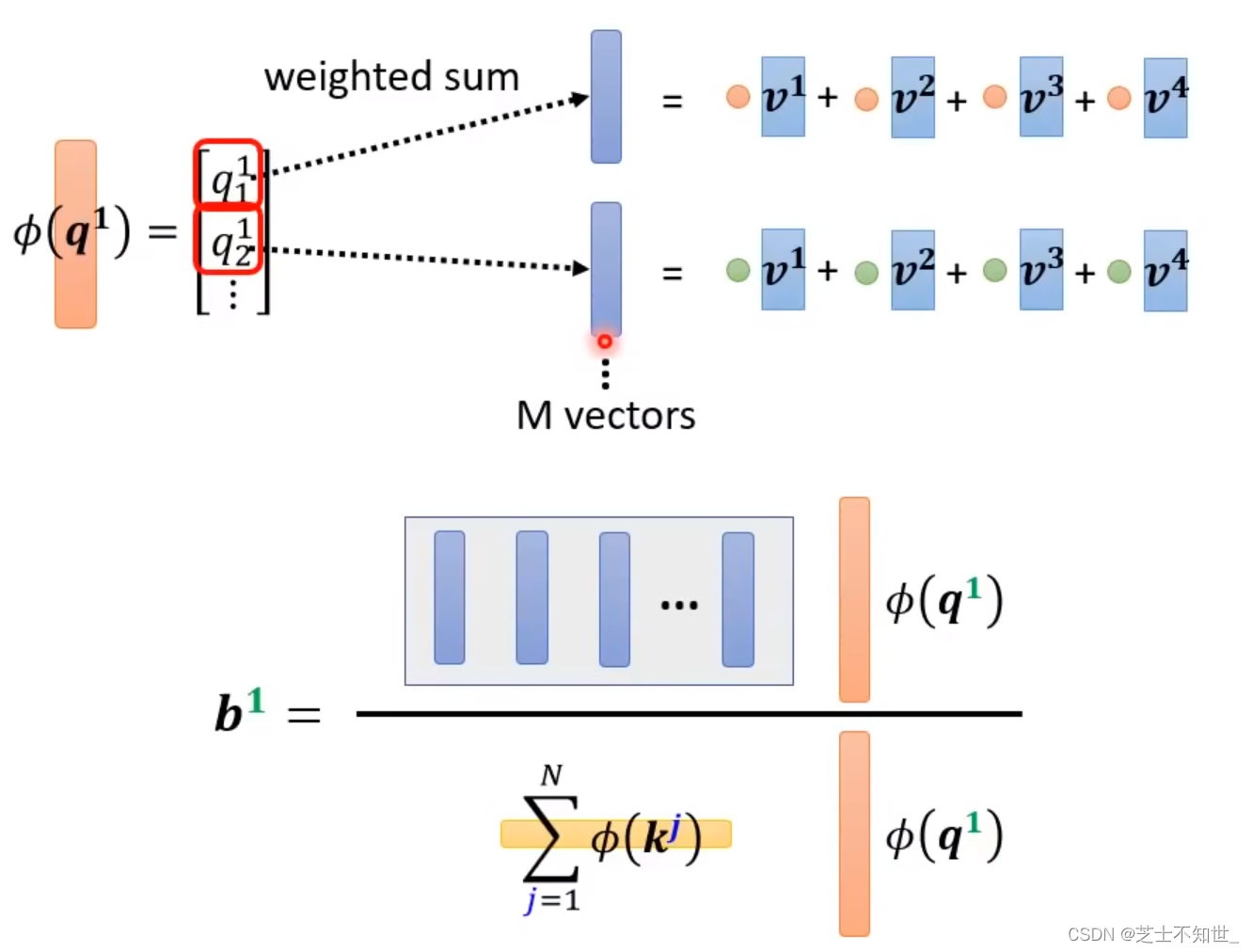
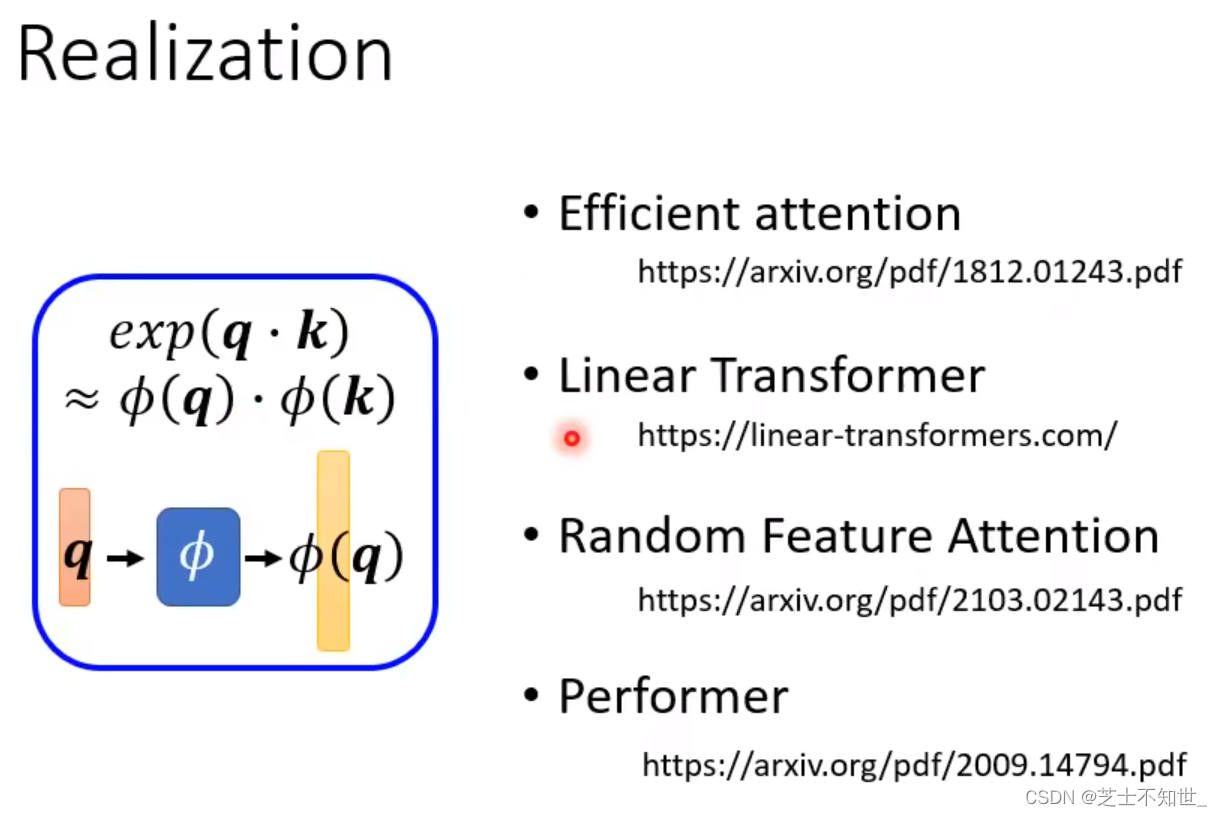
下面不同论文均使用(VK)Q的计算方法,只是映射函数fai不同:
颠覆性Attention计算方式
Attention更核心的本质是输入一个sequence,输出对应sequence。
Synthesizer不需要QK,只需V,把之前QK生成的attention矩阵变成network的参数进行训练,再与V相乘。

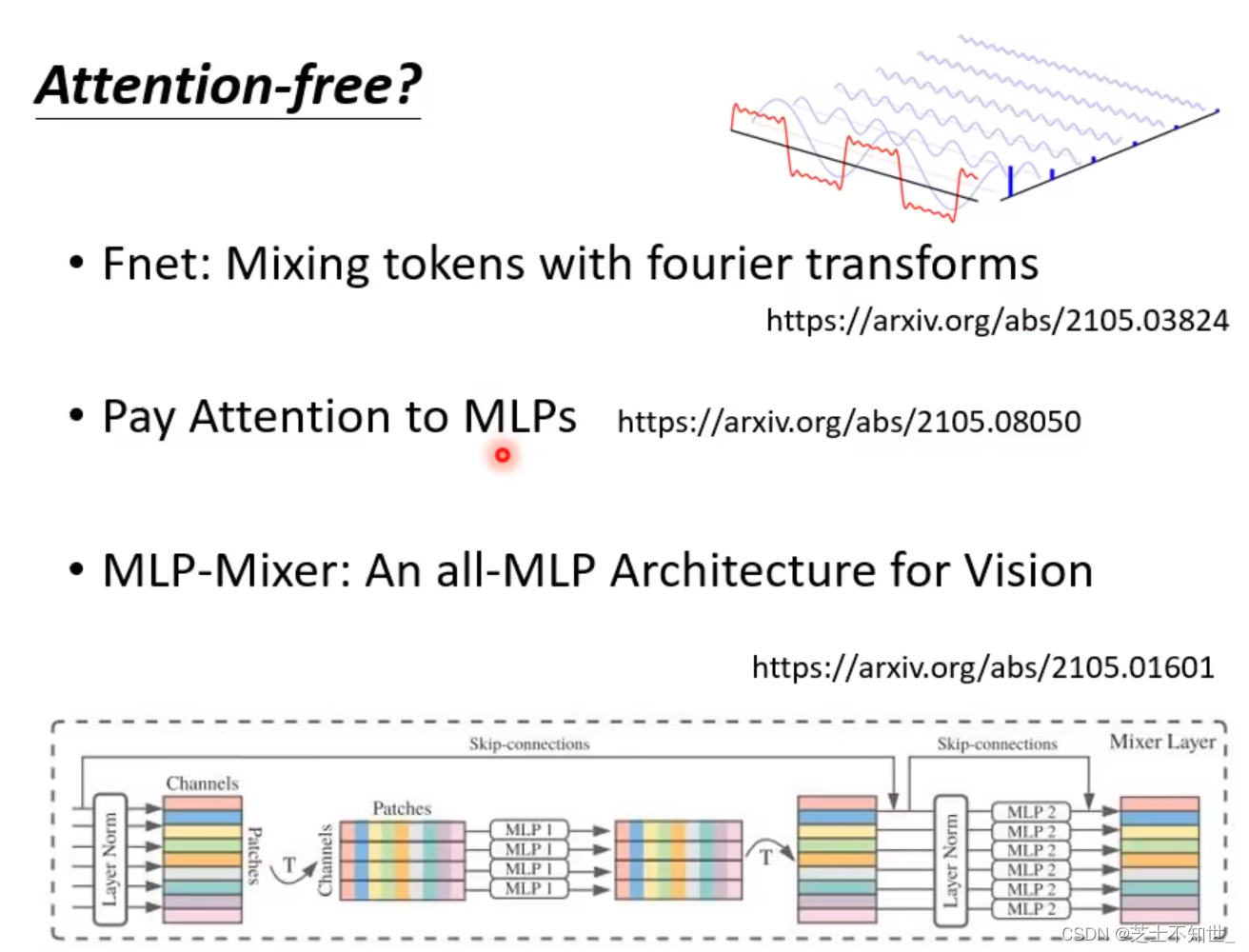
处理Sequence不用Attention



















 3564
3564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











