






1. SAM三大创新点
本文3大创新点:
- 任务:可交互式图像分割模型(交互提示词:稀疏提示{点、框、文本}和密集提示{掩码})、Zero-shot零样本学习(ZSL就是希望我们的模型能够对其从没见过的类别进行分类,让机器具有推理能力,实现真正的智能)
- 模型:提示词prompt编码器+图像image编码器+掩码mask解码器
- 数据:数据用于模型训练,模型检测未知数据,形成数据引擎闭环,得到1100万张授权的图片上有超过10亿个尊重隐私的掩码数据。
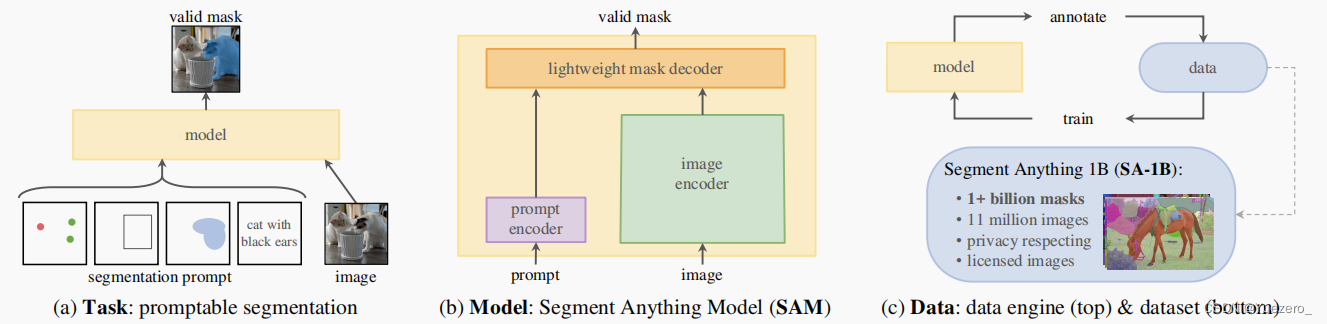
目标:根据prompt生成有效的mask掩码。
SAM带来的思考:修改模型结构已经不是重点,SAM为CV的发展带来了全新的思考——数据引擎与基于提示词的Zero-shot。
同时 提示prompt和组合compose是一种强大的工具,它使单个模型能够以可扩展的方式使用,并有可能完成在模型设计时未知的任务。可组合系统设计,由提示工程等技术驱动,将比专门为一组固定任务训练的系统提供更广泛的应用。
2. SAM数据引擎
模型与数据的循环标注训练:
1.辅助手动阶段:SAM 协助 手工标注 对掩码进行标注,类似于经典的交互式分割设置。
2.半自动阶段:SAM可以通过提示可能的对象位置来为对象的子集自动生成掩码,手工标注专注于对模型未分割出来的剩余对象进行标注,从而帮助增加掩码的多样性。
3.全自动阶段:我们用一个规则的前景点网格提示SAM,平均每张图像产生∼100个高质量的掩模。
3. SAM模型架构
i
m
a
g
e
编码器
+
p
r
o
m
p
t
编码器
+
m
a
s
k
解码器
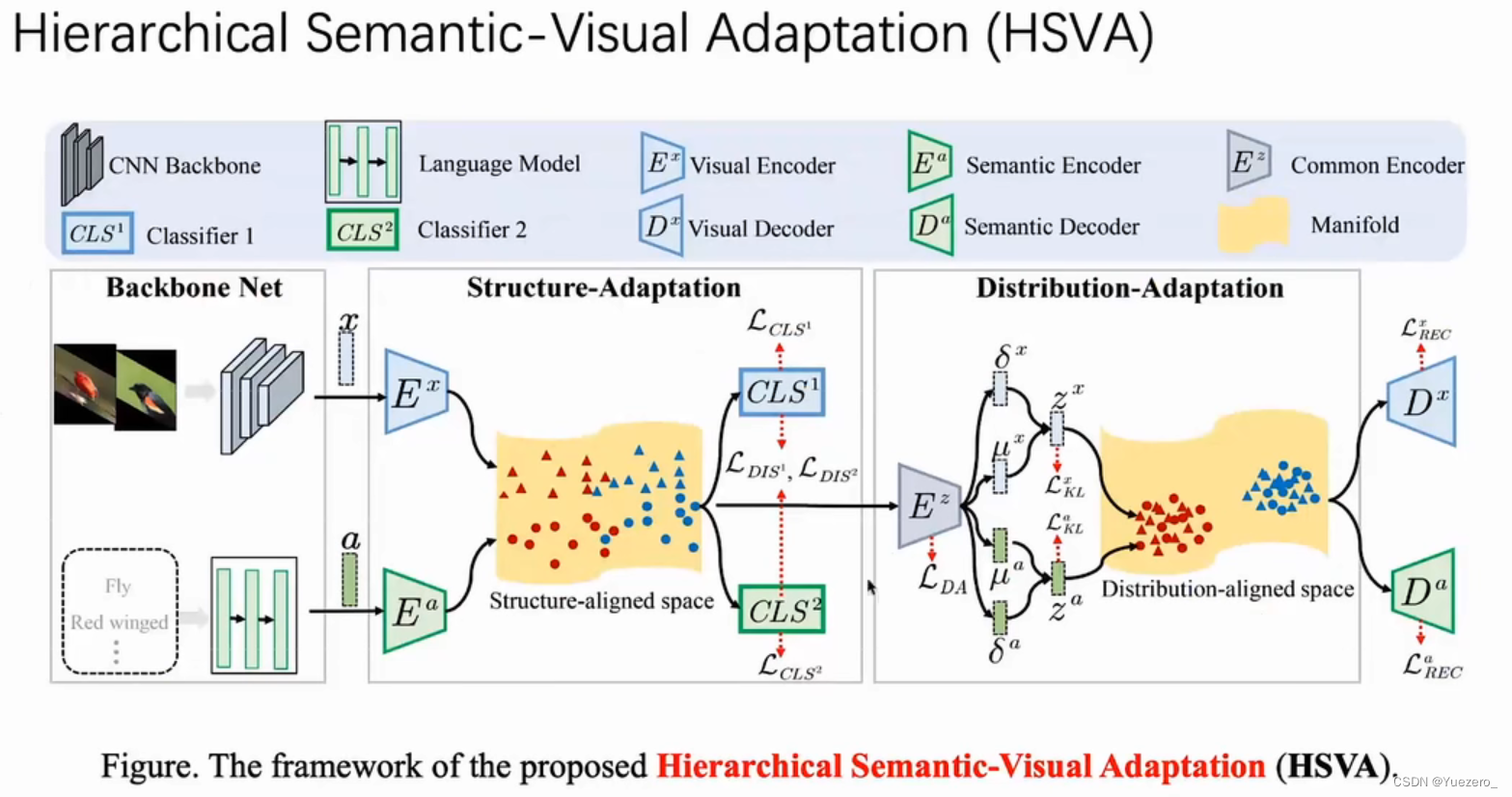
image编码器+prompt编码器+mask解码器
image编码器+prompt编码器+mask解码器
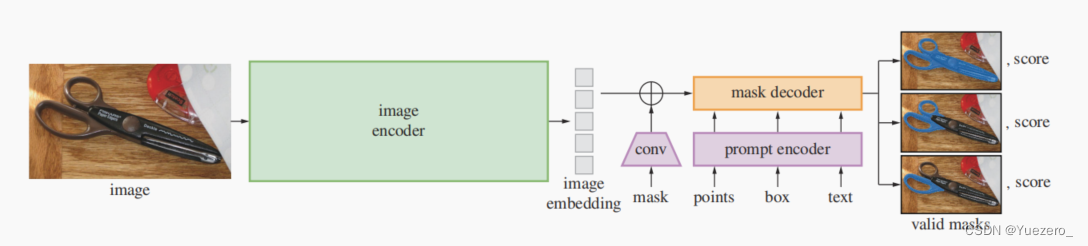
一个强大的图像编码器计算图像embedding,一个提示编码器嵌入提示embedding,然后将两个信息源组合在一个轻量级掩码解码器中来预测分割掩码。
Image编码器:图像->图像向量,使用MAE(ViT预训练模型,CVPR2022);
Prompt编码器:稀疏提示(点/框/文本)->提示向量,使用CLIP(文本编码模型,CVPR2021);稠密提示(掩膜)->256维提示向量,使用卷积;
Mask解码器:图像向量+提示向量->掩码前景概率,使用Transformer decoder block + 动态mask预测头:
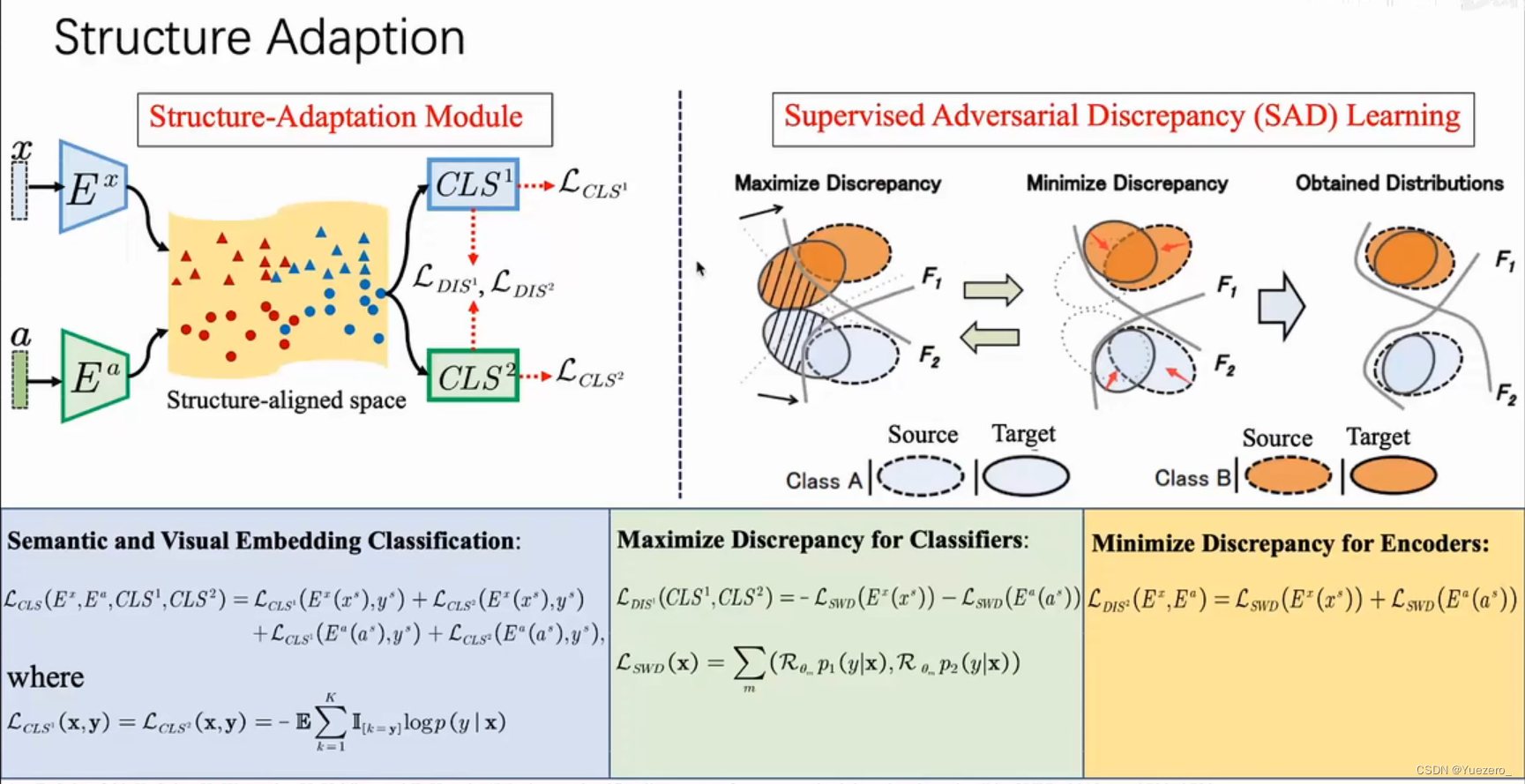
- Transformer decoder block:(1)对提示向量的self-attention,(2)从提示向量(Q)到图像向量(KV)的corss-attention,(3)点级MLP更新每个提示向量,(4)从图像向量(Q)到提示向量(KV)的corss-attention,用提示向量更新图像向量。
- 提示强化:原始的提示向量(包括它们的位置编码)都会被重新添加到第一个decoder 更新后的标记中,这允许强烈地依赖于提示向量的几何位置和类型。
- 输出上采样:在运行两个Transformer decoder block之后,对图像向量进行4倍上采样(2个反卷积),同时MLP 将输出token 映射到 动态线性分类器,然后计算每个图像位置的掩码前景概率。
歧义:为了使SAM感知到歧义(点状prompt指向一个人的衬衫,返回2个mask,一个是衬衫,一个是穿着陈述的人),我们将其设计为预测一个prompt的多个mask,允许SAM自然地处理歧义,比如衬衫和人的例子。
4. Zero-shot零样本学习ZSL
4.1 零样本学习ZSL概述
过去的监督学习Supervised(直接在大量带标签数据上进行训练)、无监督学习Unsupervised(在大量无标签数据上,通过对数据内在特征的挖掘)、半监督学习Semi-supervised(将大量标签数据加入到少量带标签数据中一起训练来进行监督学习)、自监督学习Self-supervised(先在无标签数据上进行辅助任务的训练,再在少量带标签数据上进行微调)在进行分类时,都依赖于训练时已经见过的类别,未见过的类别不能进行分类,缺乏异类泛化性能。
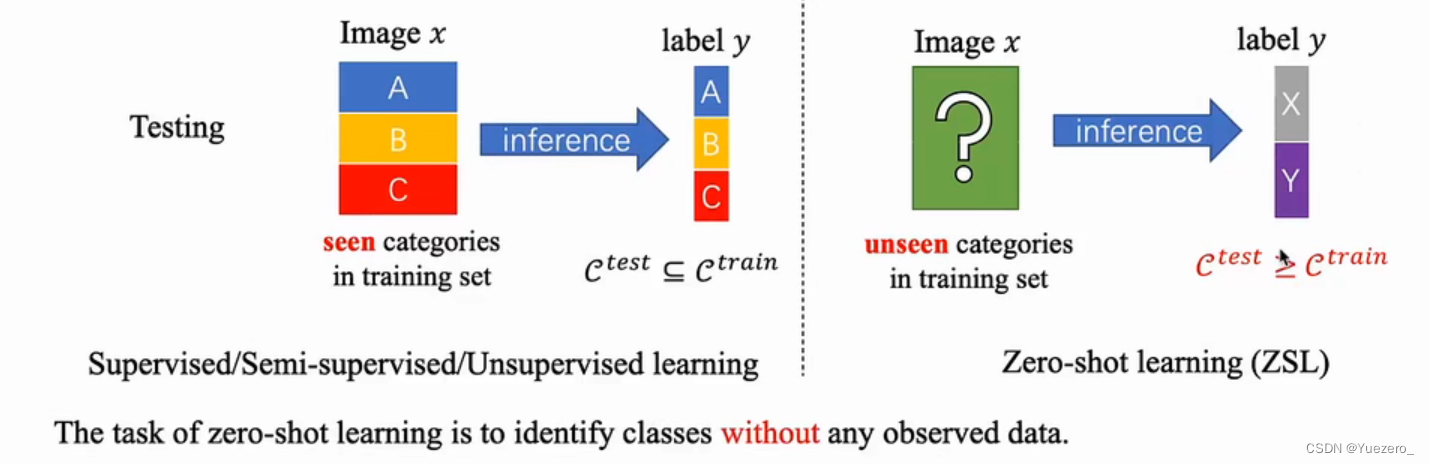
ZSL就是希望我们的模型能够对其从没见过的类别进行分类,让机器具有推理能力,实现真正的智能,在有限的样本类别中,认知无限的世界。
可见类 & 不可见类(seen classes & unseen classes):在ZSL问题中,特征空间(feature space)包含一些带标签的训练实例,这些实例所涵盖的的类别就称为可见类(seen classes);同时,特征空间中还包含一些不带标签的测试实例,这些实例所属的类别称为不可见类(unseen classes)。
例子,假设我们的模型已经认识了马,老虎、熊猫,现在需要该模型学习如何识别 斑马,那么我们需要告诉模型一个提示prompt/attribute,怎样的对象才是斑马,但是并不能直接让模型看见斑马。所以模型需要知道的信息是马的样本、老虎的样本、熊猫的样本、不同样本的标签,以及关于前三种动物和斑马的描述,这样经过训练模型便可识别斑马这种未见过的类别。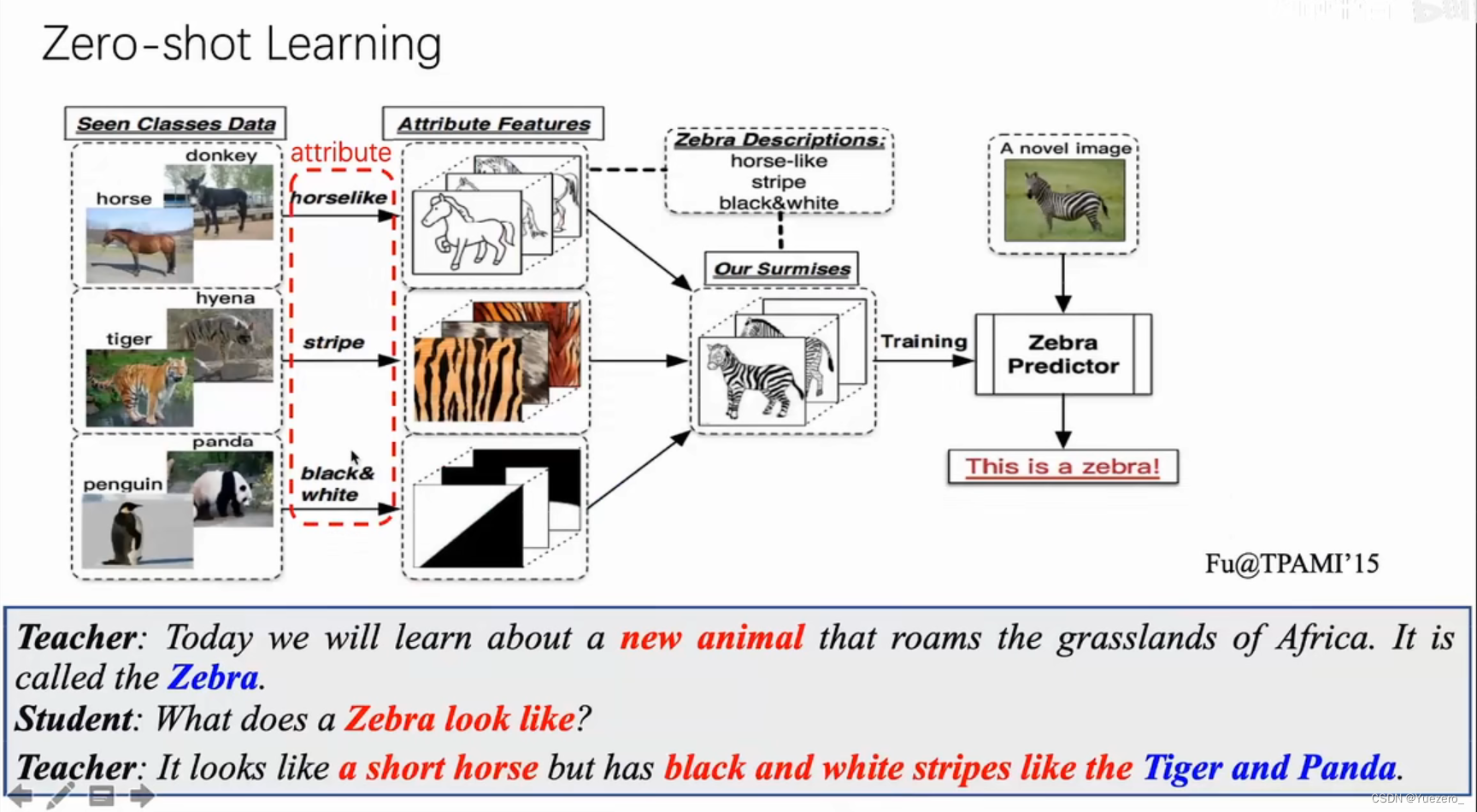
4.2 零样本学习ZSL形式化表示
形式化表示:
(1)训练集数据
X
t
r
X_{tr}
Xtr 及其标签
Y
t
r
Y_{tr}
Ytr ,包含了模型需要学习的类别(马、老虎和熊猫),这里和传统的监督学习中的定义一致;
(2)测试集数据
X
t
e
X_{te}
Xte 及其标签
Y
t
e
Y_{te}
Yte,包含了模型需要辨识的类别(斑马),这里和传统的监督学习中也定义一直;
(3)训练集类别的描述
A
t
r
A_{tr}
Atr ,以及测试集类别的描述
A
t
e
A_{te}
Ate ;我们将每一个类别
y
i
∈
Y
y_{i}\in Y
yi∈Y ,都表示成一个语义向量
a
i
∈
A
a_{i}\in A
ai∈A 的形式,而这个语义向量的每一个维度都表示一种高级的属性,比如“黑白色”、“有尾巴”、“有羽毛”等等,当这个类别包含这种属性时,那在其维度上被设置为非零值。对于一个数据集来说,语义向量的维度是固定的,它包含了能够较充分描述数据集中类别的属性。
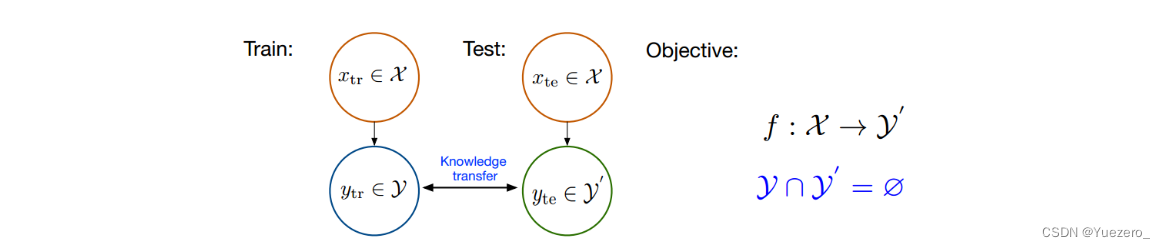
在ZSL中,我们希望利用
X
t
r
X_{tr}
Xtr和
Y
t
r
Y_{tr}
Ytr来训练模型,而模型能够具有识别
X
t
e
X_{te}
Xte 的能力,因此模型需要知道所有类别的描述
A
t
r
A_{tr}
Atr 和
A
t
e
A_{te}
Ate 。ZSL这样的设置其实就是上文识别斑马的过程中,需要额外为它提供提示信息,作为已知类别和未知类别的语义知识迁移桥梁,从而达到对未知类的认知。
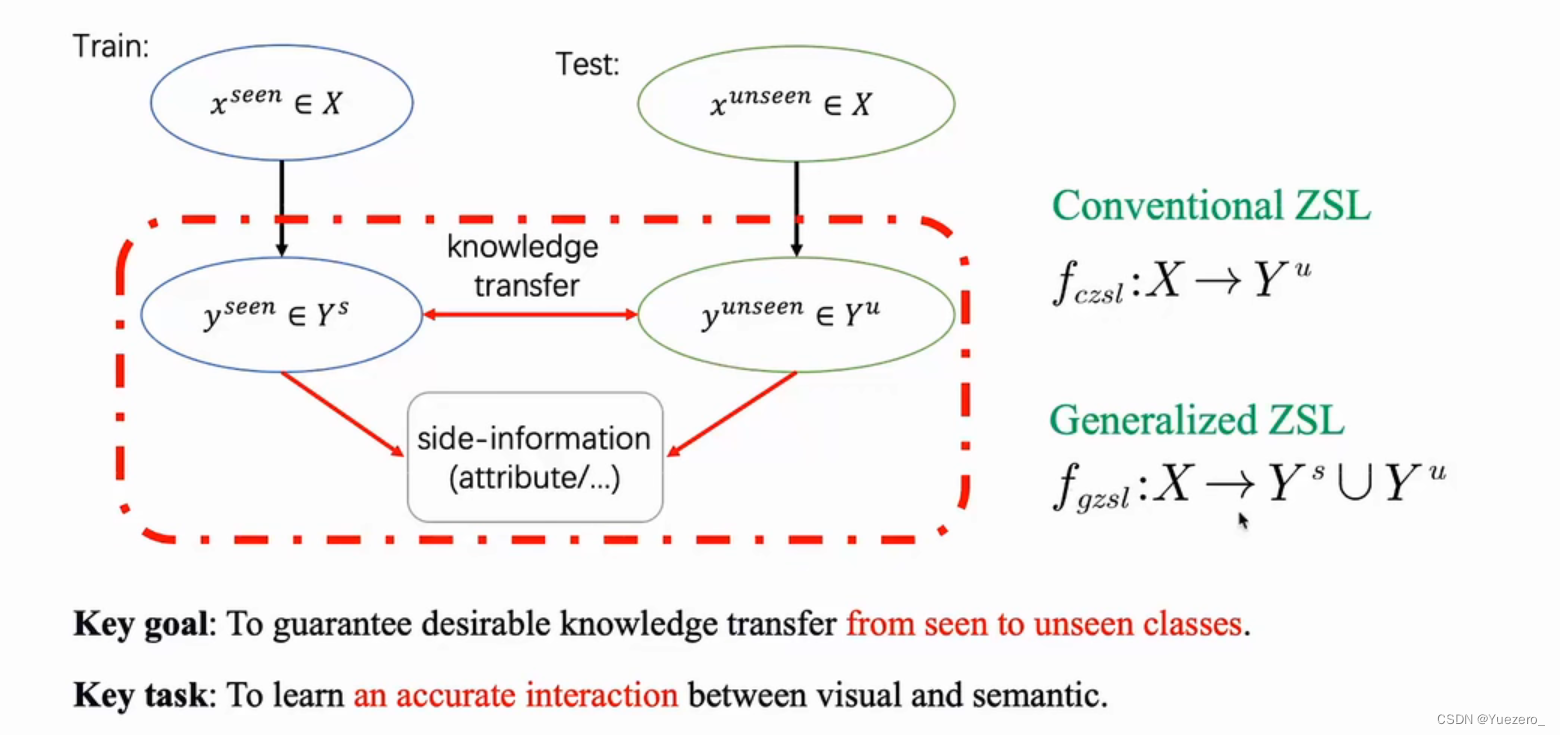
4.3 零样本学习ZSL通用架构
先在大型数据集上进行预训练,得到一个基本的特征提取模型(通用的视觉权重),再对ZSL视觉空间提取特征,将ZSL视觉特征(未知类图像特征) 与 语义空间(未知类属性提示)进行交互。
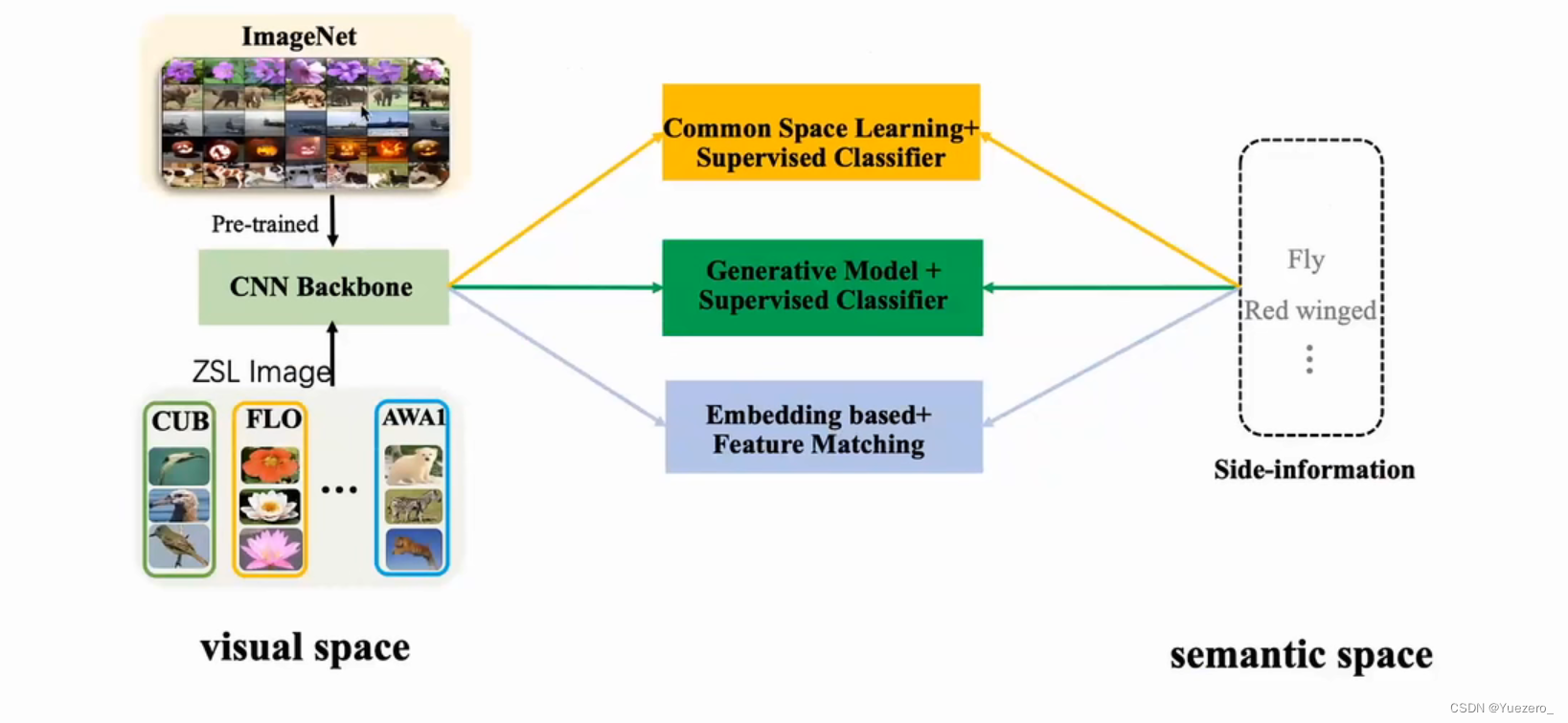
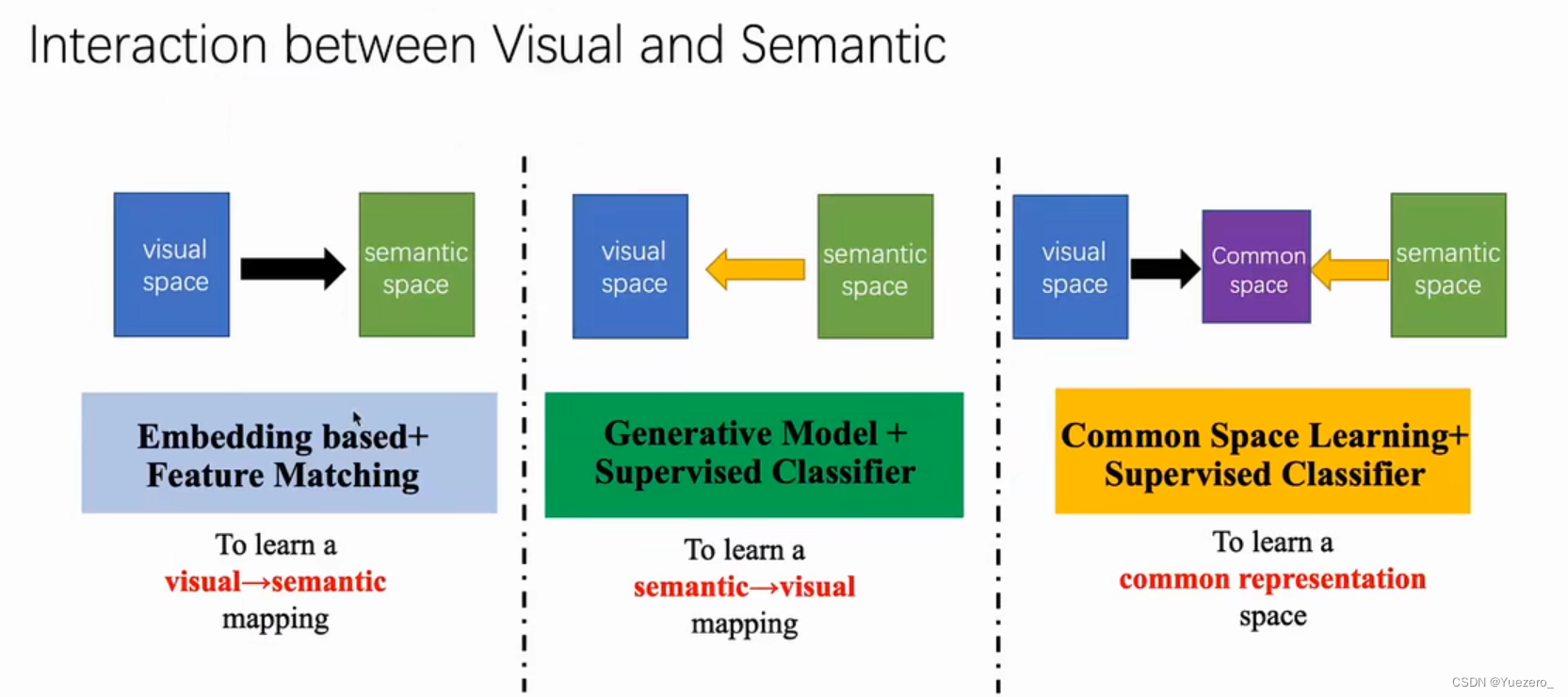
交互的方式主要分为3种:
(1)基于嵌入的特征匹配:学习视觉到语义的映射,将视觉特征嵌入到语义空间,转换为语义空间的有监督的分类任务。
(2)基于生成模型的监督学习:学习语义到视觉的映射,根据未见类的属性,生成未见类的视觉样本,转换为视觉空间的有监督的分类任务。
(3)基于公共空间的监督学习:将视觉和语义同时映射到一个公共空间,视觉特征转换为公共空间的视觉特征,语义特征转换为公共空间的 ,转换为公共空间的有监督的分类任务。
4.4 零样本学习ZSL面临问题

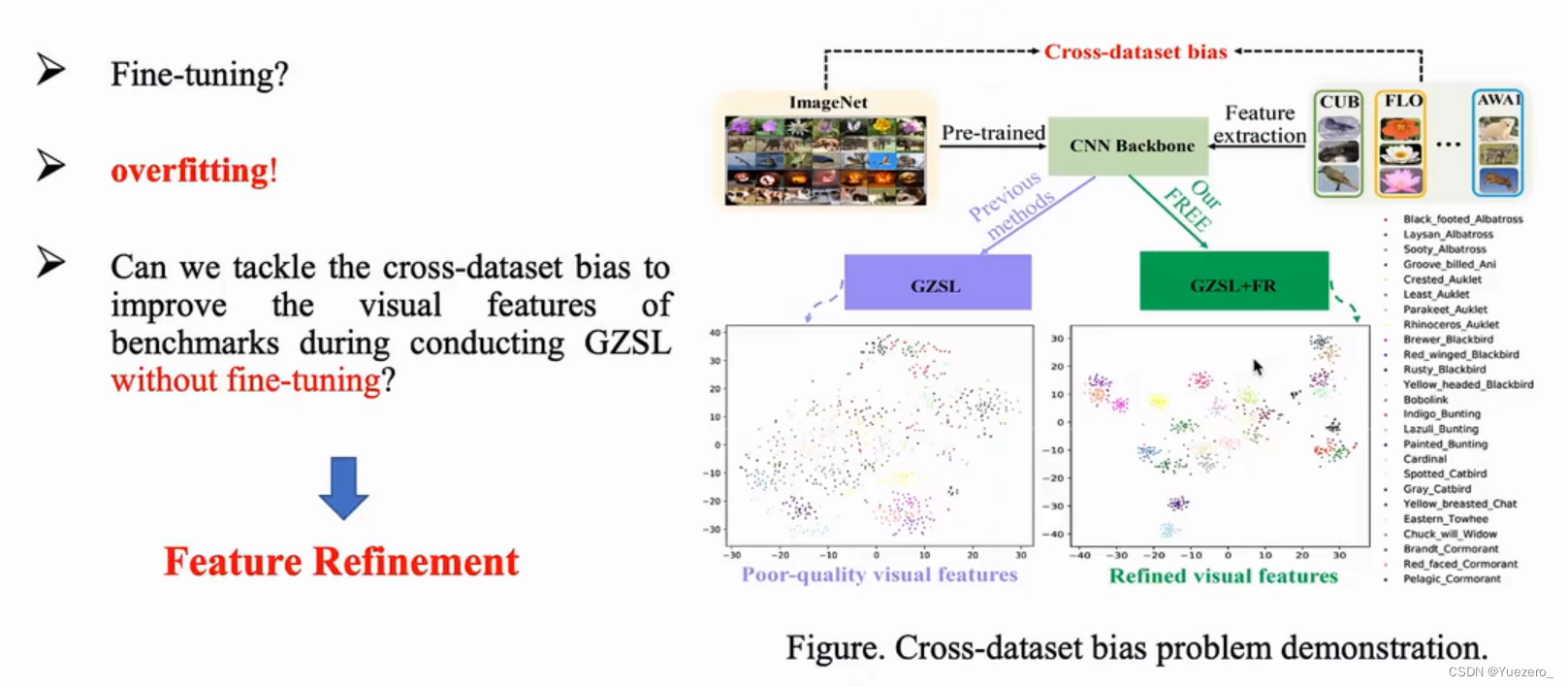
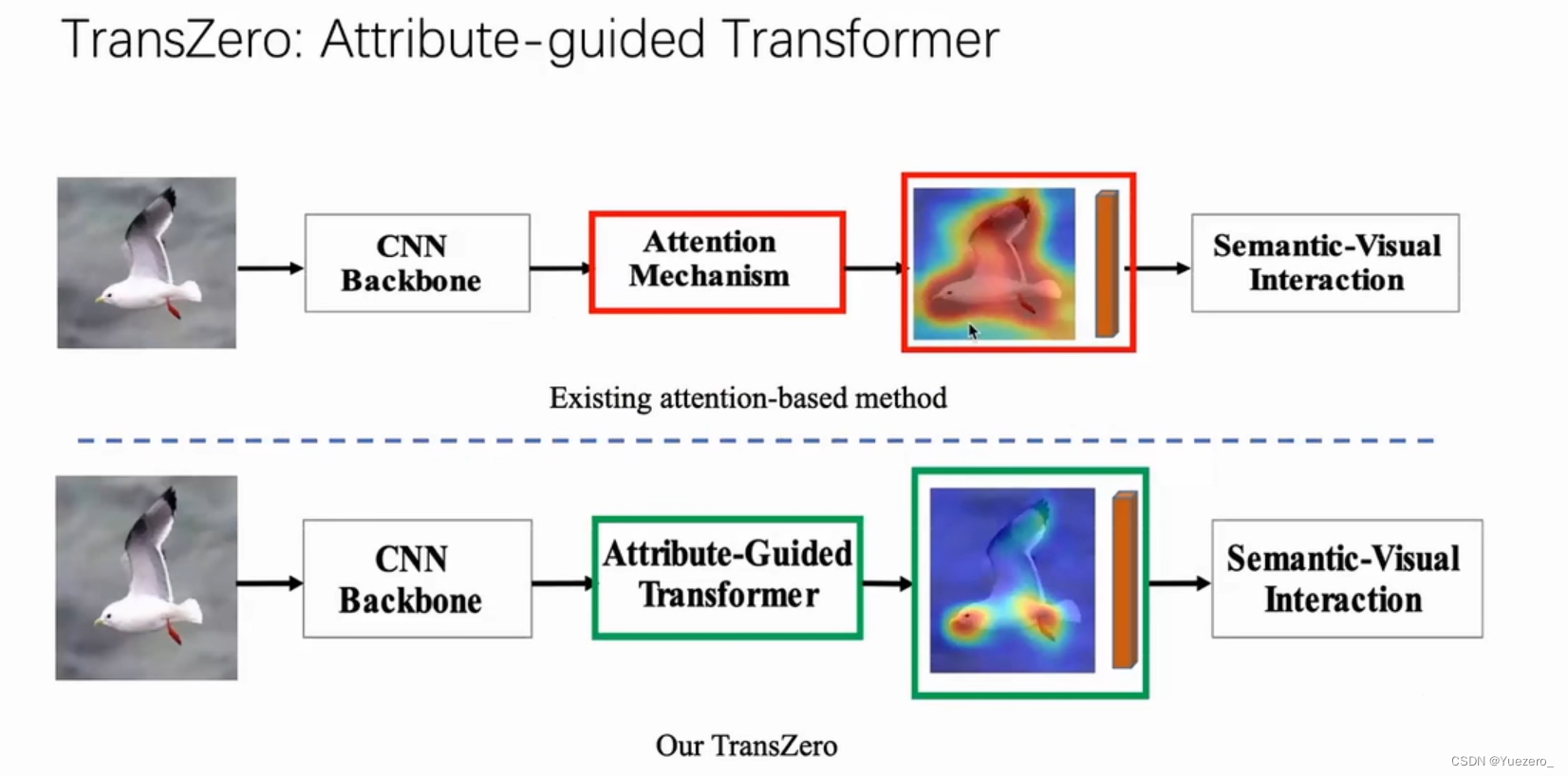
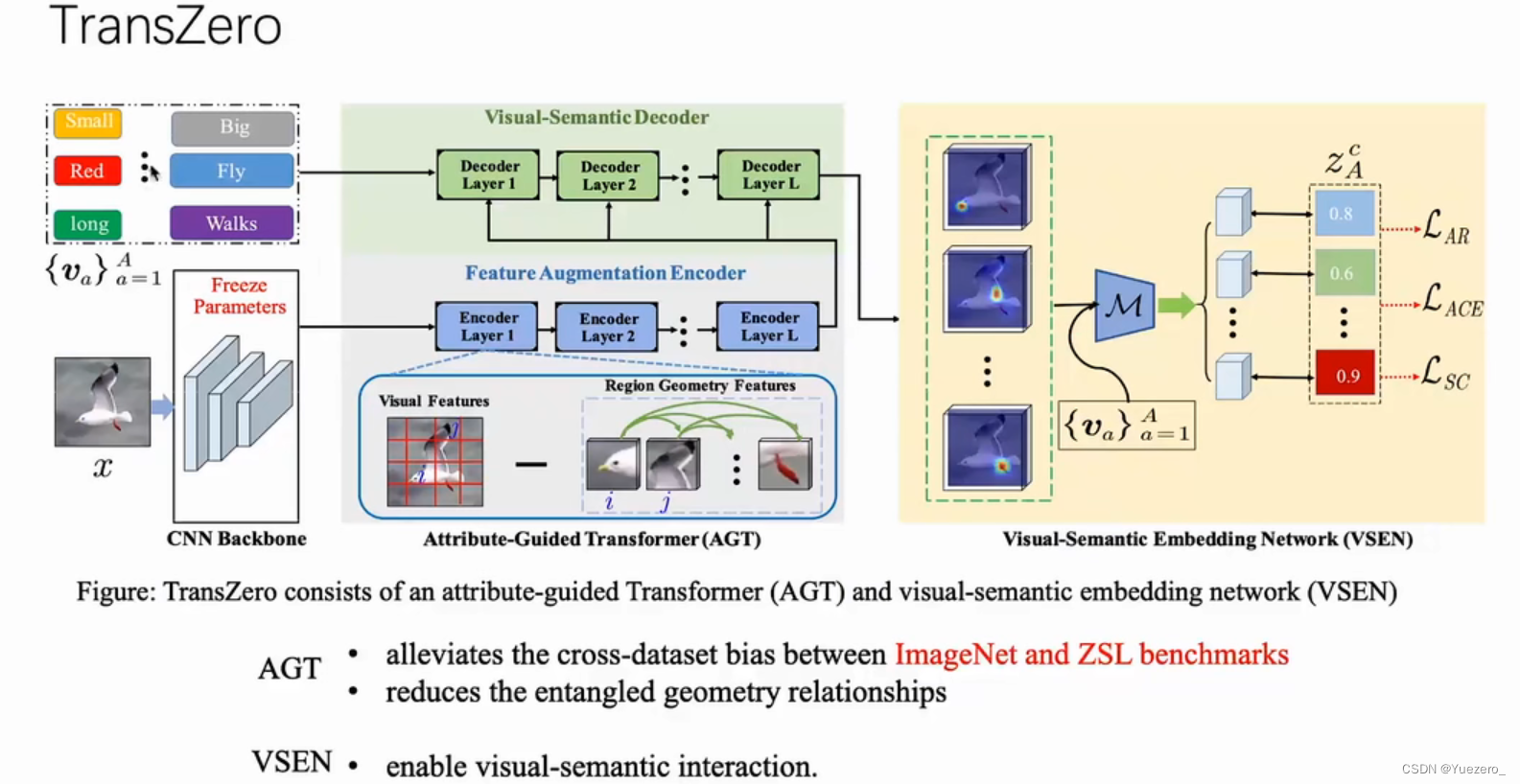
(1)数据集跨域偏差(Cross-Databset Bais)
在Imagenet上预训练,在其他ZSL数据集上进行下游任务的训练,两个数据集的分布不同,带来特征表达的偏差。

解决方法:
Fine-tuning:因为ZSL数据集本身就非常小,所以在ZSL数据集上对backbone进行微调,很容易造成过拟合,所以微调方法行不通。
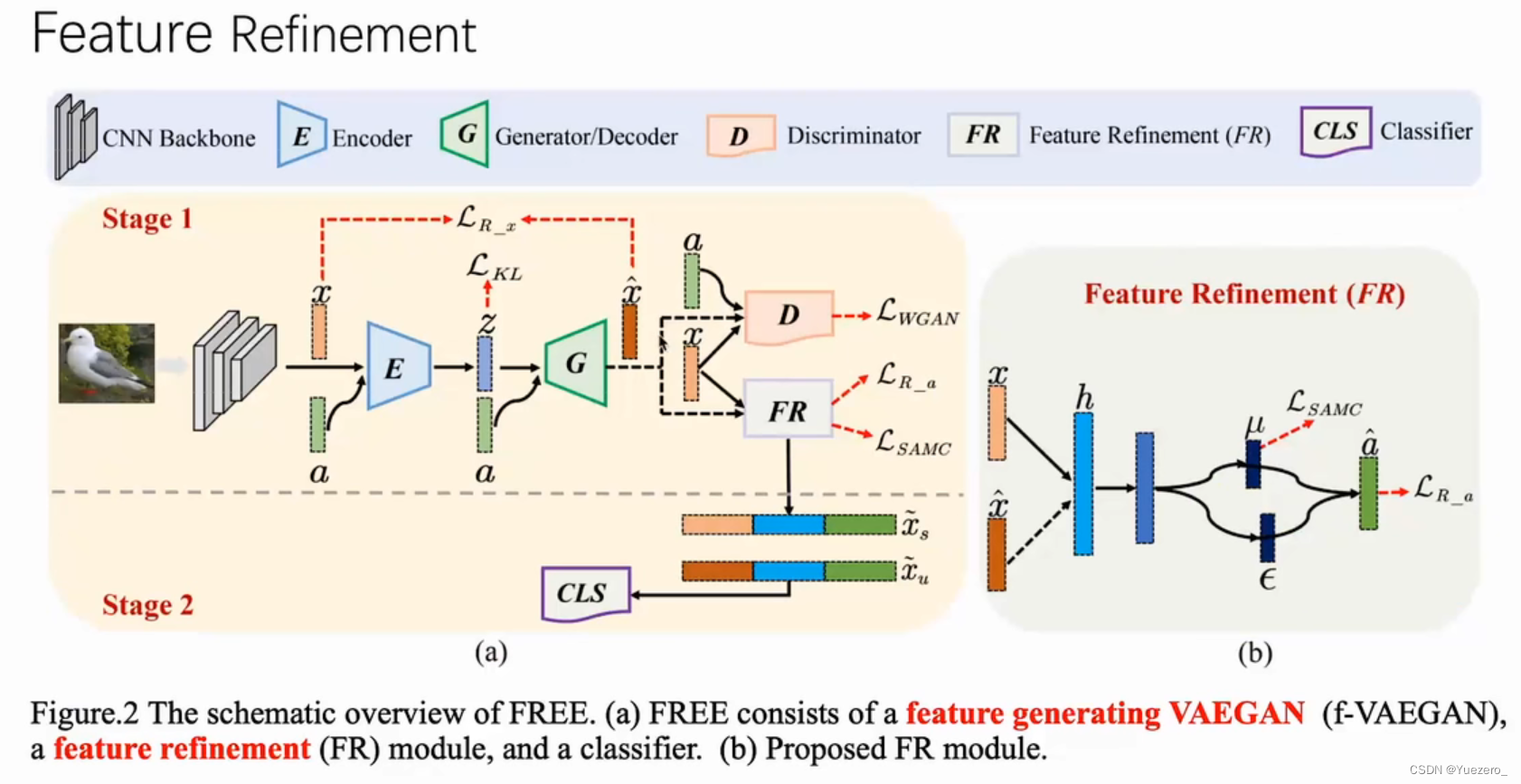
Feature Refinement:直接在零样本学习的过程中,对视觉特征进行Refinement,提升已见类和未见类的特征分布。
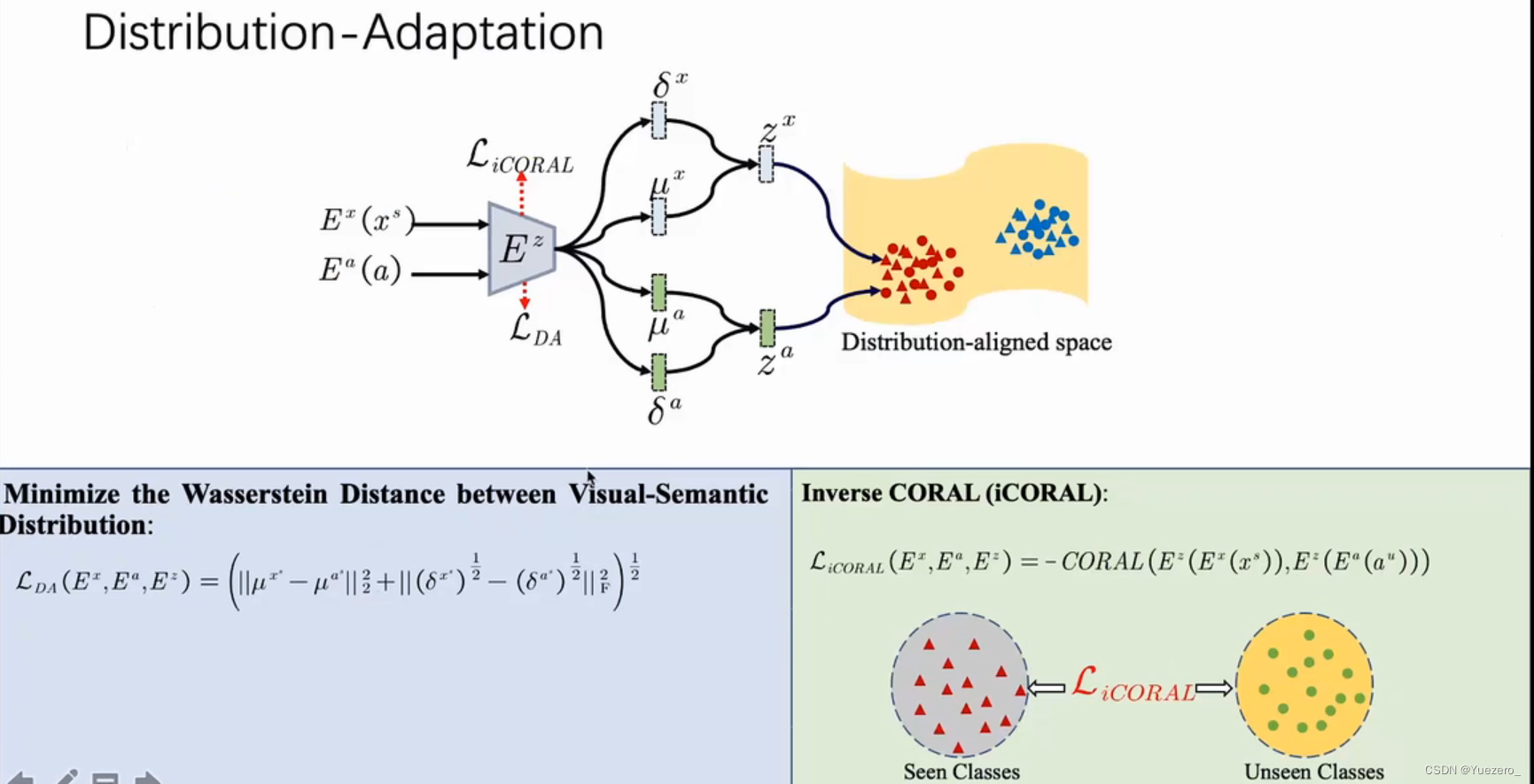
(2)异构特征对齐(Heterogeneous Features Alignment)
视觉空间和语义空间两个异构空间的特征存在 特征分布差异 和 流形结构差异,对齐这两种异构特征很重要。
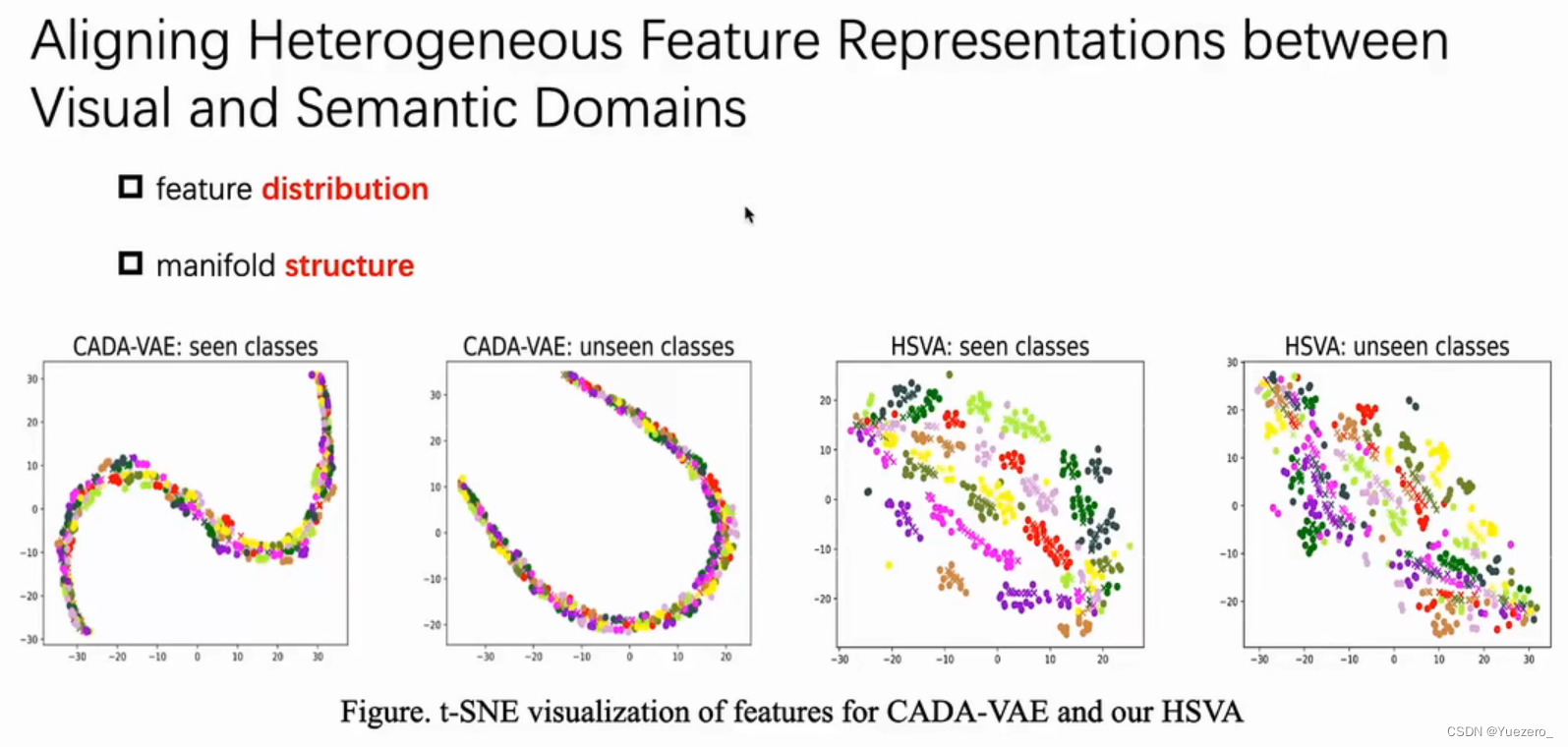
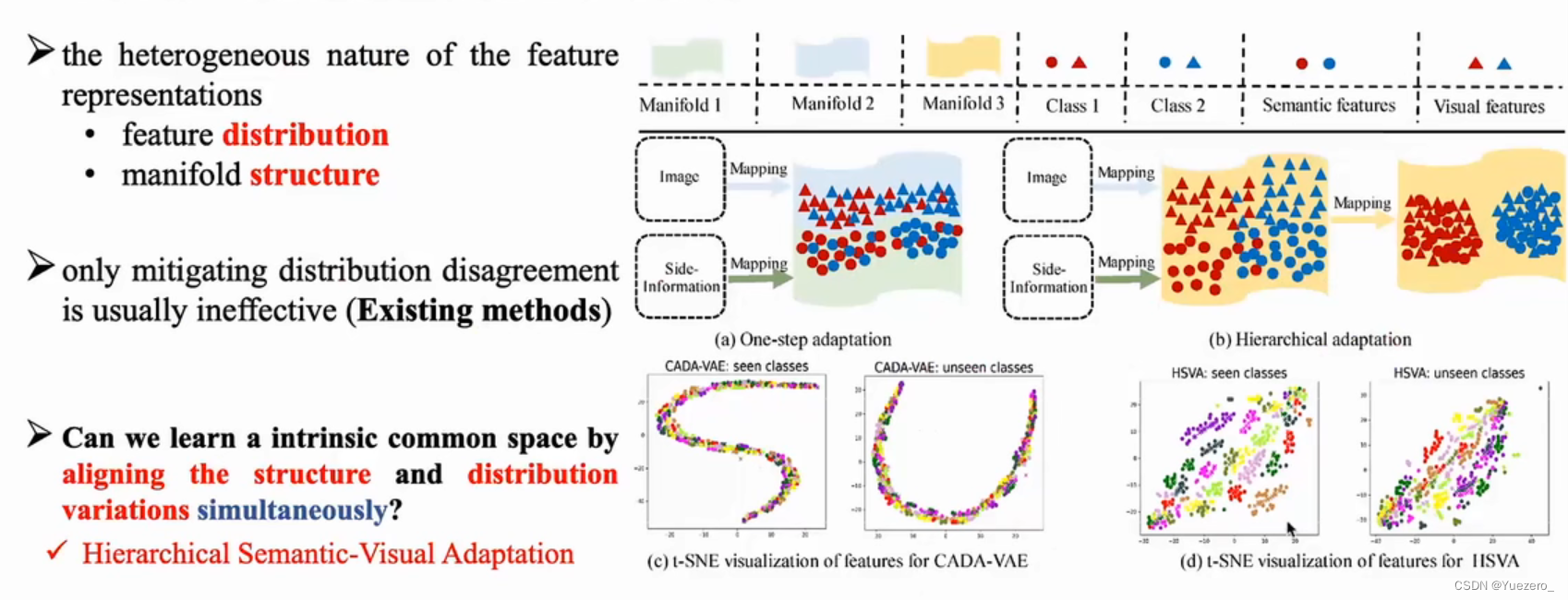
解决方法:
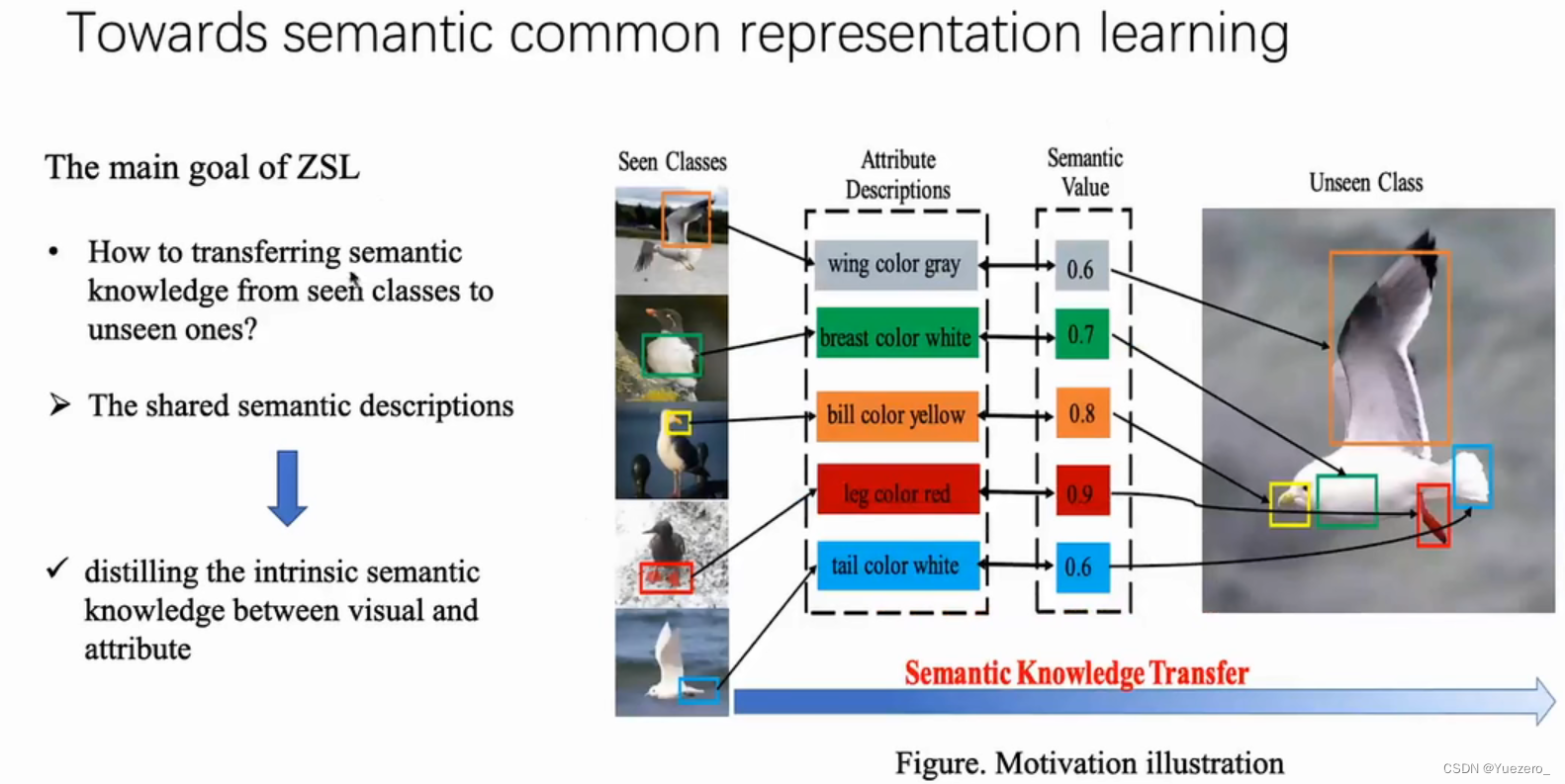
(3)本真特征表示(Intrinsic Semantic Representation)
如何高效的表示视觉空间和语义空间的本真特征是个问题。
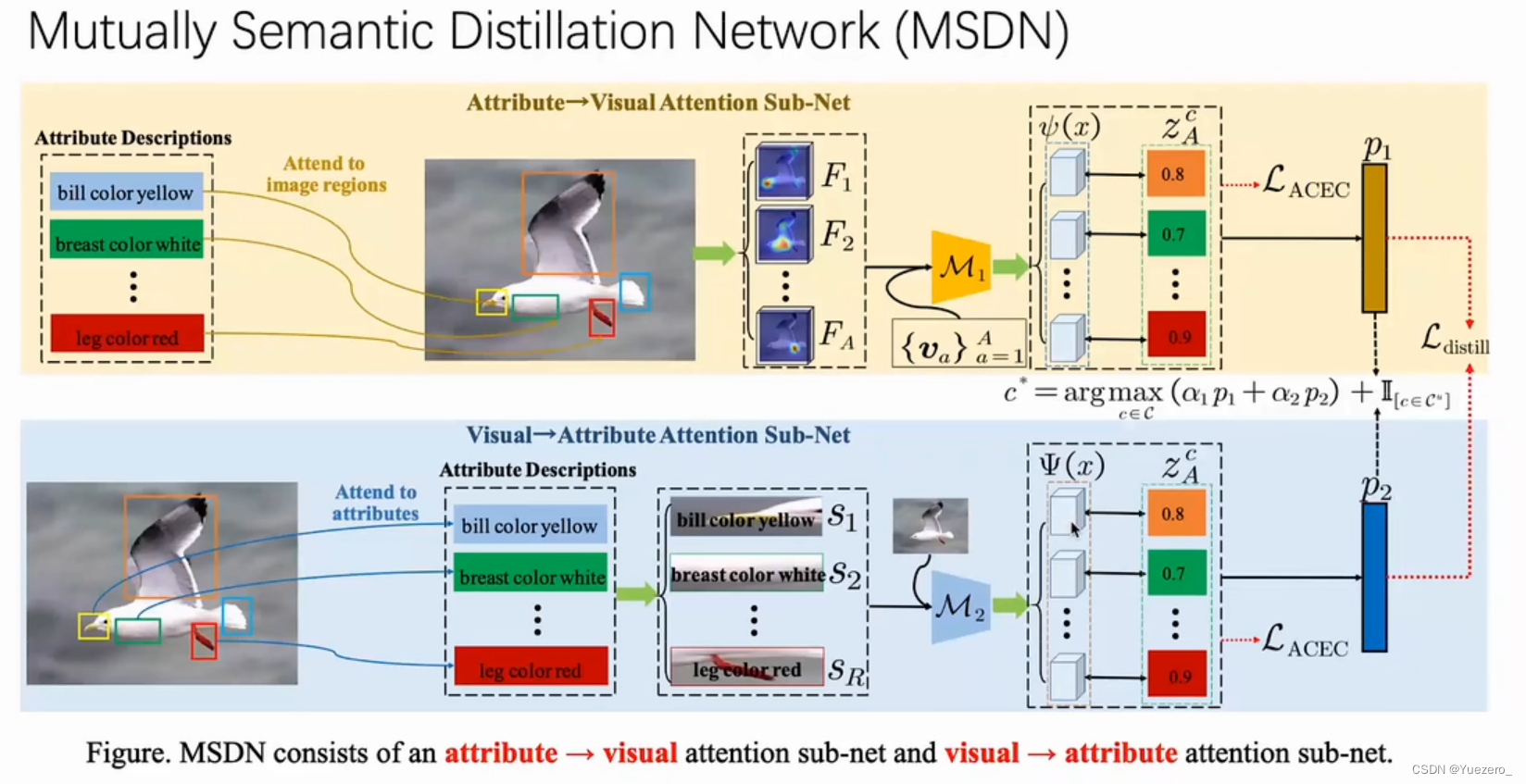
解决方法:
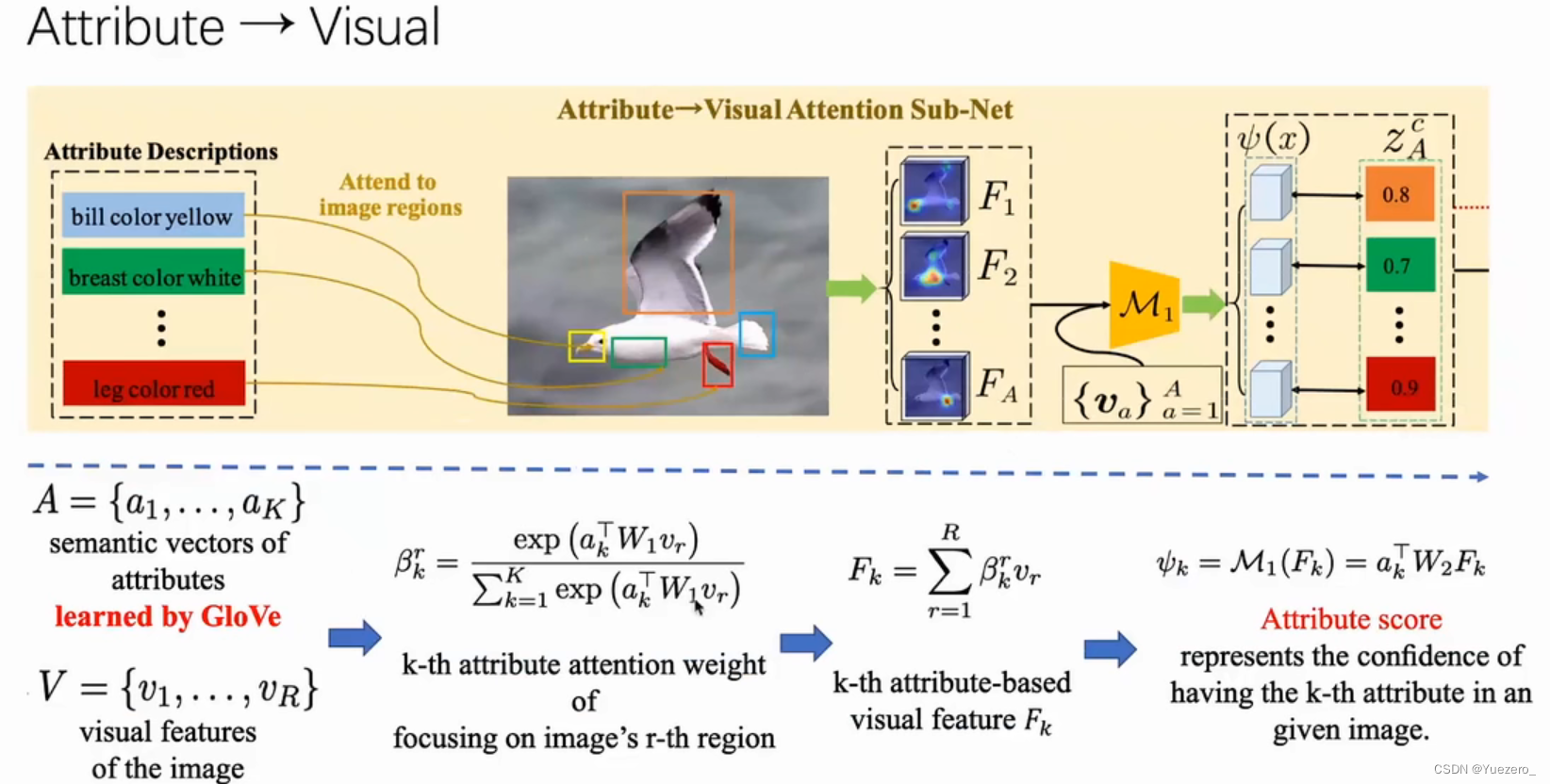
(4)领域漂移问题(domain shift problem)
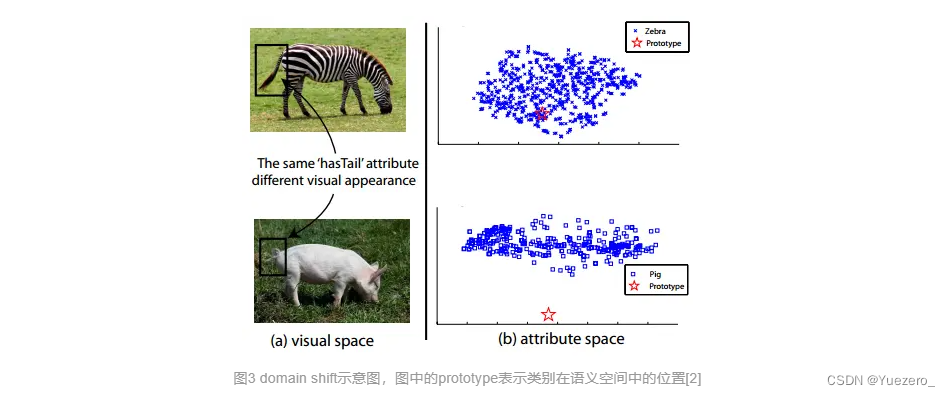
该问题的正式定义首先由提出。简单来说,就是同一种属性,在不同的类别中,视觉特征的表现可能很大。如图3所示,斑马和猪都有尾巴,因此在它的类别语义表示中,“有尾巴”这一项都是非0值,但是两者尾巴的视觉特征却相差很远。如果斑马是训练集,而猪是测试集,那么利用斑马训练出来的模型,则很难正确地对猪进行分类。
(5)枢纽点问题(Hubness problem)
这其实是高维空间中固有的问题:在高维空间中,某些点会成为大多数点的最近邻点。这听上去有些反直观,细节方面可以参考。由于ZSL在计算最终的正确率时,使用的是K-NN,所以会受到hubness problem的影响,并且中,证明了基于岭回归的方法会加重hubness problem问题。
(6)语义间隔(semantic gap)
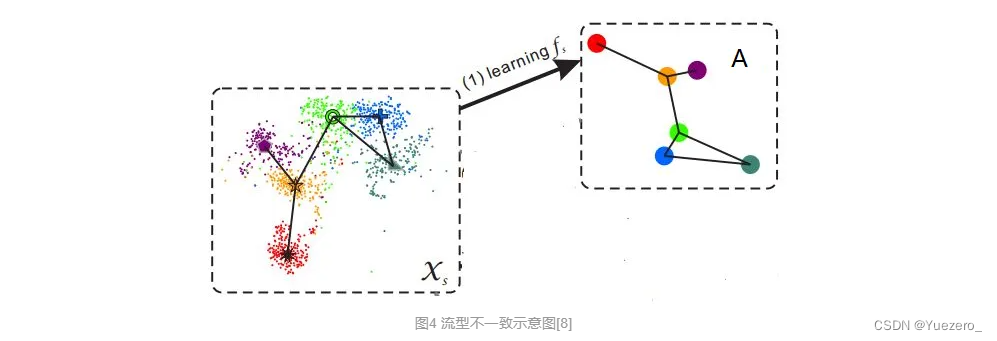
样本的特征往往是视觉特征,比如用深度网络提取到的特征,而语义表示却是非视觉的,这直接反应到数据上其实就是:样本在特征空间中所构成的流型与语义空间中类别构成的流型是不一致的。(如图4所示)这使得直接学习两者之间的映射变得困难。
















 1585
1585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











