






- Video Pertraining Model Downstream Evaluation
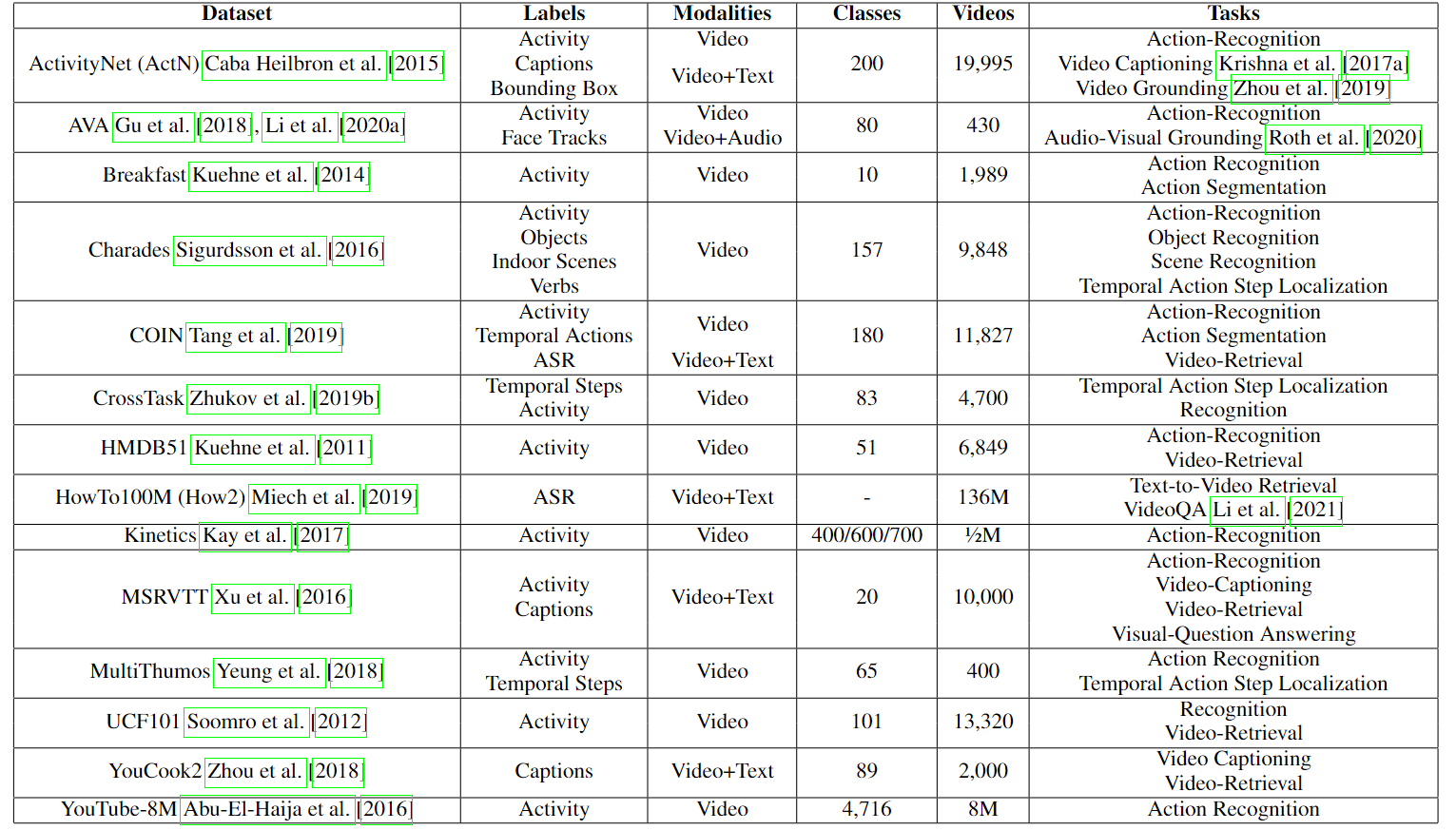
- Video Dataset
- Self-Supervised Learning Approaches
- Limitations and Future Work
- InternVideo: General Video Foundation Models via Generative and Discriminative Learning
Video Self-Supervised learning (SSL):Video Model 在大规模 unabled dataset 上 Pertraining,然后在 labeled dataset 上 Finetuning:

Video Pertraining Model Downstream Evaluation
Video Pertraining Downstream Evaluation将预训练的Video Model经过Zero-Shot(不再训练)、Fine-tuning(需要再训练)、Linear probing(需要再训练).通常在以下Task上进行测试评估:
- Action Recognition:视频分类任务,在Video Model后面接一个Linear层预测input_video的class_label,评价指标(accuracy, precision, recall)
- Temporal Action Segmentation:视频时序定位任务/视频动作分割,检测视频中某个动作的start 和 end 时间,评价指标(frame accuracy (FA))
- Temporal Action Step Localization:视频时序动作步骤定位,检测视频中哪些片段属于哪些动作的哪些步骤。对于每一帧,评价指标(recall=落在真实时间间隔内的step分配,除以视频中的总step)
- Video Retrieval:视频检索任务,寻找与给定视频相似或接近重复的视频。评价指标(retrieval, recall, similarity measures)
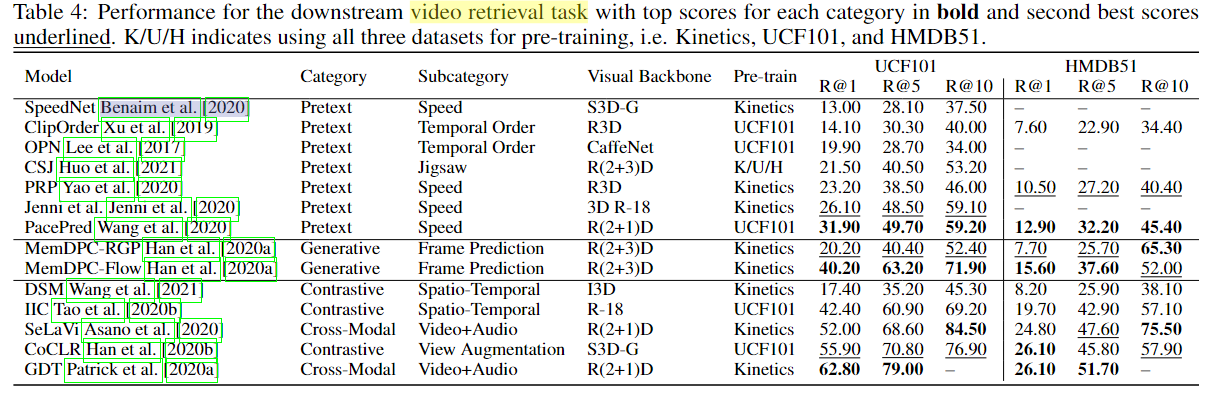
- Text-to-Video Retrieval:文本检索视频任务,将文本查询作为输入并返回相应的匹配视频。评价指标(retrieval, recall, similarity measures)
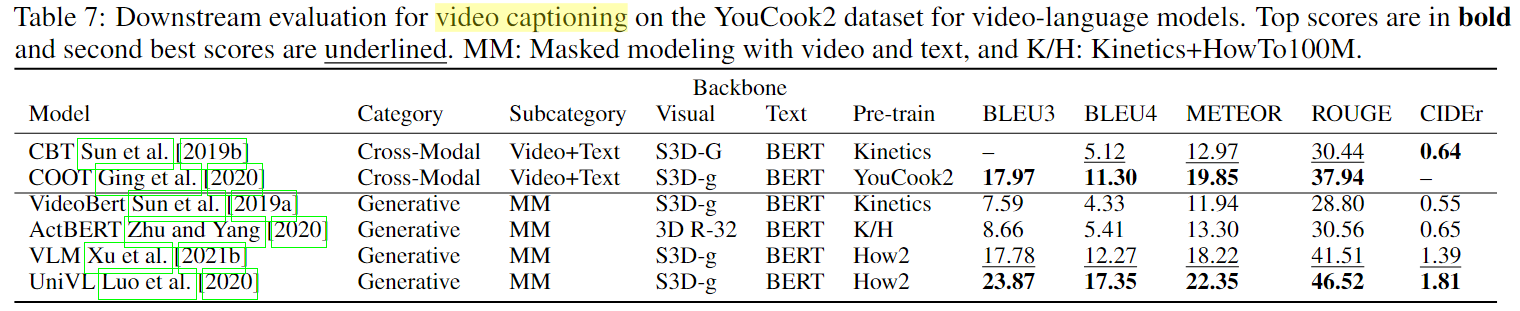
- Video Captioning:视频描述任务,生成准确描述视频内容的文本标题。评价指标(BLEU, METEOR, Rouge-L Lin,CIDEr)
Video Dataset
Self-Supervised Learning Approaches
https://www.bilibili.com/video/BV1sr4y1s7QH/?spm_id_from=333.337.search-card.all.click&vd_source=b2549fdee562c700f2b1f3f49065201b
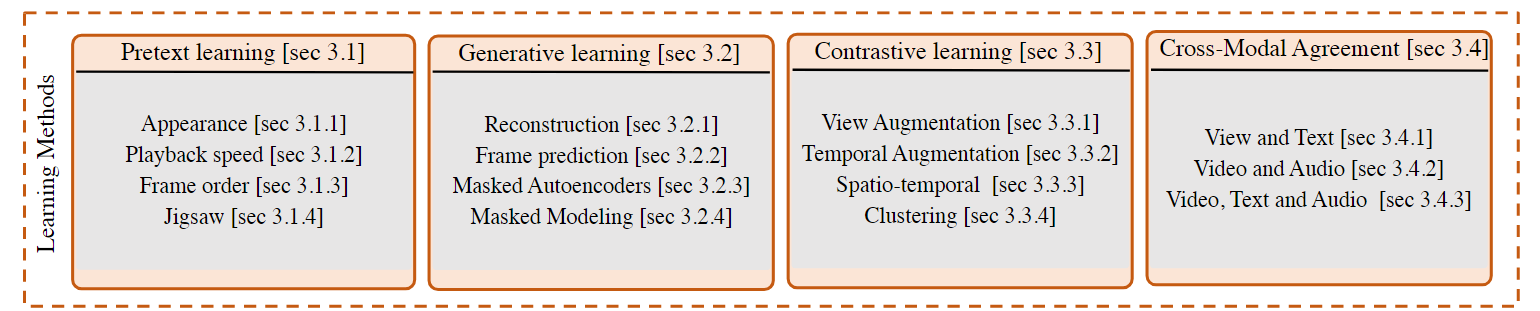
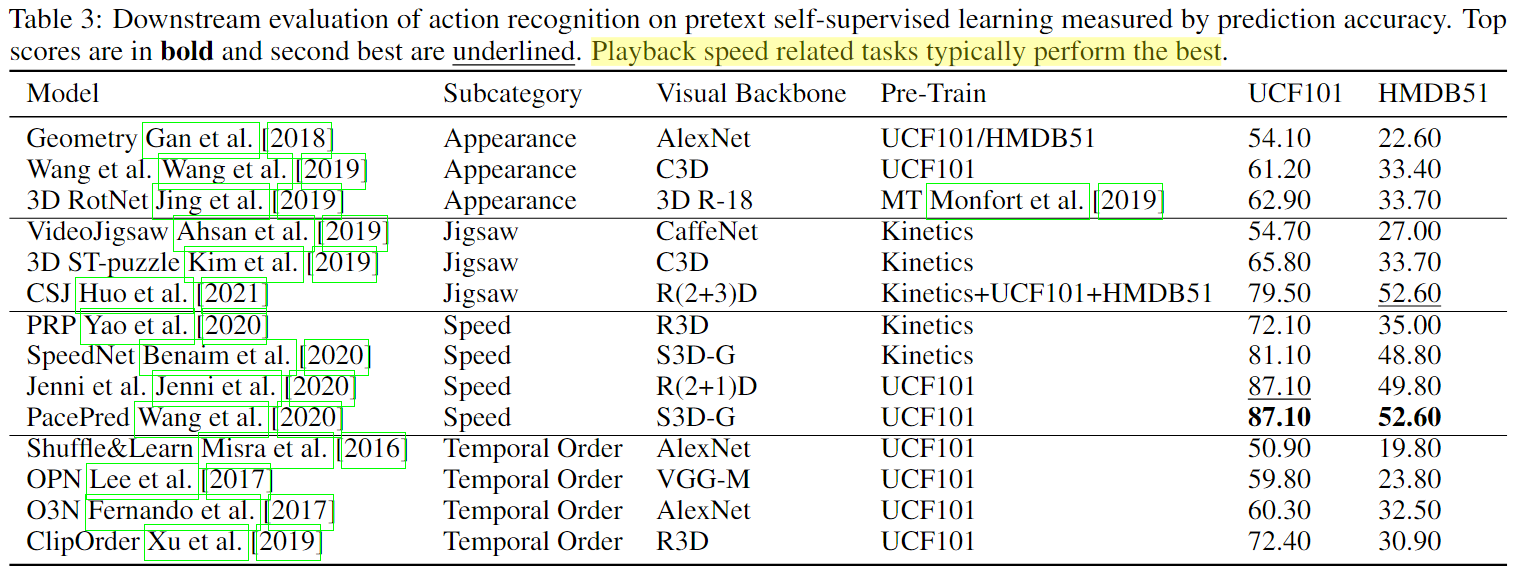
- pretext tasks:设定预定义任务进行训练。在pretext tasks中,对回放速度进行分类在下游动作识别上表现最好,这种方法比帧排序表现更好,因为它有多种方法可以通过修改速度来使用时间信号,而帧顺序具有有限的排列。
- generative learning:常用的生成方法包括生成对抗网络、掩码自动编码器和多模态掩码建模。其中一些方法使用一系列先前的帧来生成下一个帧序列。其他方法使用模型使用一个或多个模态的未屏蔽输入来生成掩码输入。效果最佳的是使用掩码建模的方法。
- contrastive learning:为锚剪辑生成有很多方法正样本和负样本,包括视图增强、时间增强、时空增强、聚类。对比学习是所有基于动作的下游任务中性能最好的学习目标。
- cross-modal agreement:具有跨模态一致性的多模态域的对比学习。这些方法既提高了动作识别任务的性能,又扩展到其他任务,如使用文本和音频模式的文本到视频检索和动作分割。
1. Pretext Learning 预定义任务
设置预定义任务的类似主要有4种:
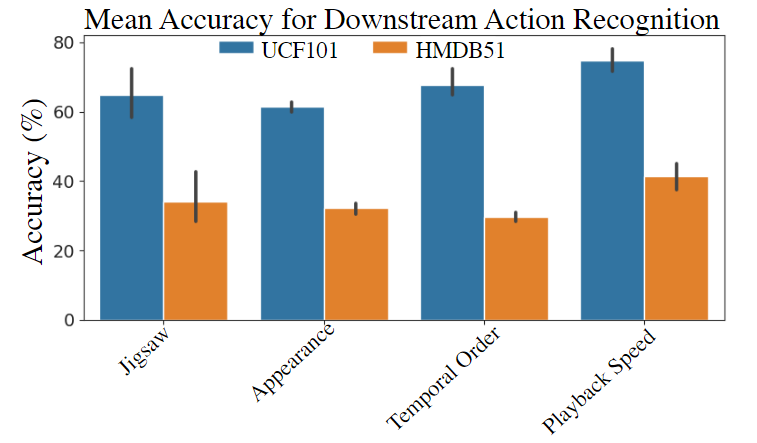
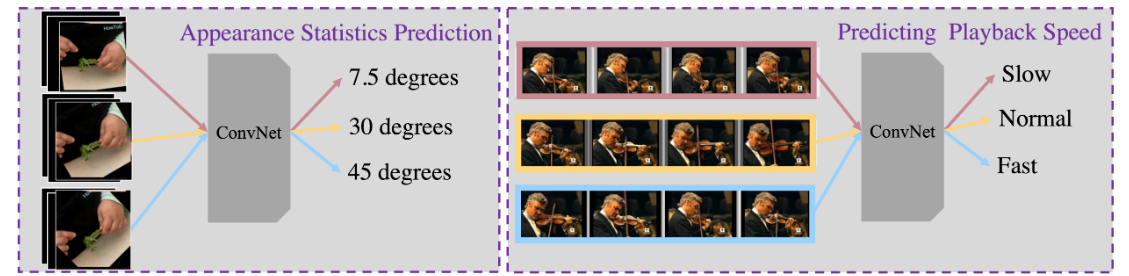
- Appearance Statistics Prediction 外观统计预测:对视频的空间和时间元素进行数据增强,要求模型对相关统计数据进行预测;
- Playback Speed 回放速度预测:改变视频的播放速度,要求模型预测速度或重建原始速度;
- Temporal Order 时序分类预测:洗牌帧,其中任务包括预测奇数和/或将帧排序到原始顺序;
- Video Jigsaw 视频拼图顺序预测:洗牌帧/视频的patch,并要求模型预测所选择的排列。
通常Playback speed任务训练的模型效果最好:
1.1 Appearance Statistics Prediction 外观统计预测
预测或分类视频的Appearance augmentation:颜色color、旋转rotation、随机噪声random noise等。如给定通过旋转增强的帧,并要求模型预测所使用的旋转程度。
1.2 Playback Speed 回放速度预测
对倍速视频的播放速度进行分类:通过改变video的播放速度,在时间维度上应用增强,并要求模型预测该变化的幅度(对加减速分类,或以原视频速度重建)。
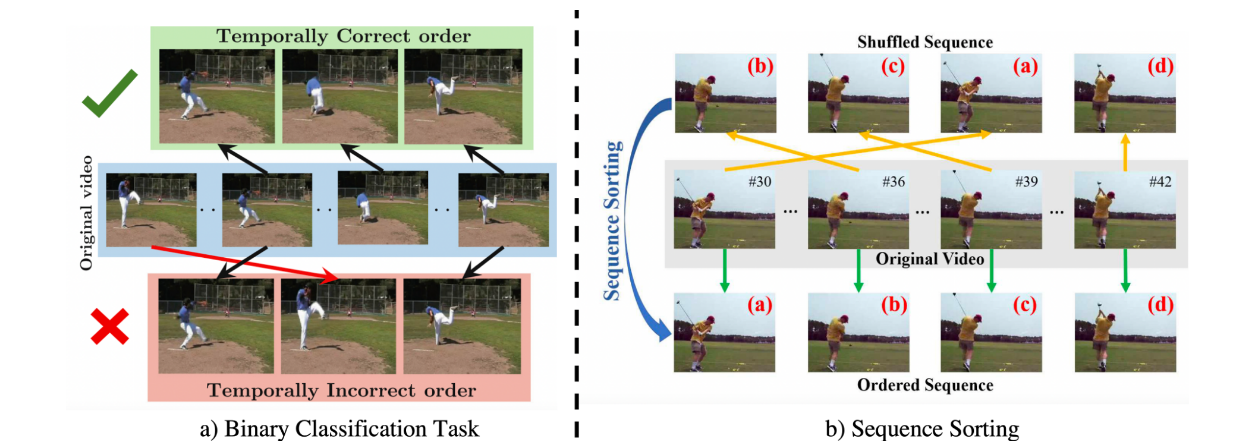
1.3 Temporal Order 时序分类预测
在时间顺序分类中,每个视频V被分成t帧的片段,训练模型来分类输入片段的顺序是否正确,或训练模型来完成正确的片段排序。
每一组剪辑都包含一个顺序正确的剪辑,其余的剪辑通过打乱顺序来修改。例如,(t2, t1, t3)是错误的,而(t1, t2, t3)是正确的。
1.4 Video Jigsaw 视频拼图顺序预测
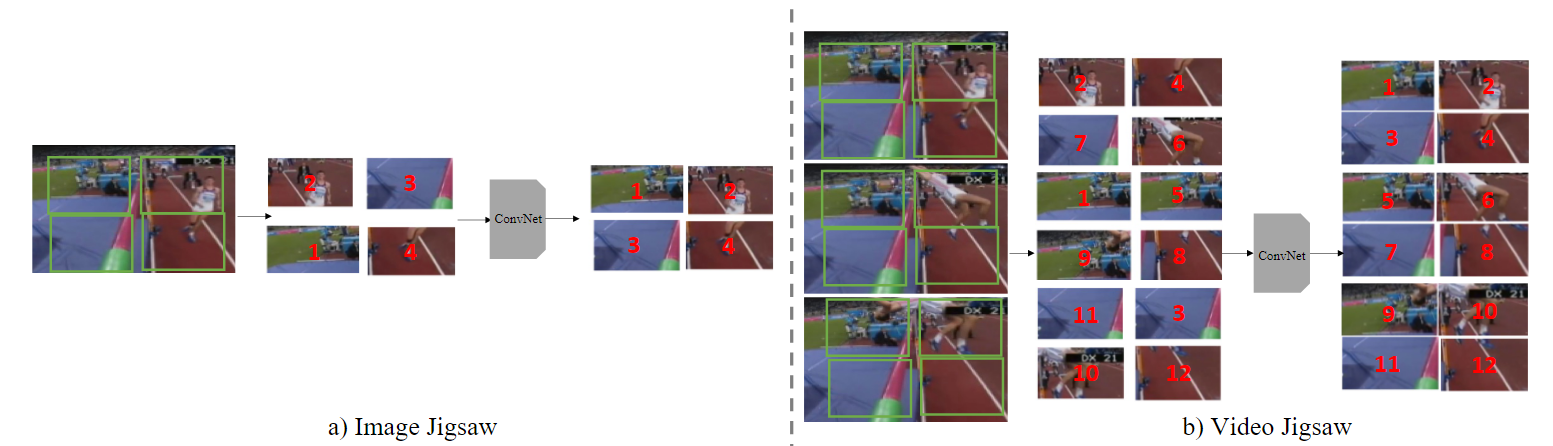
Image Jigsaw任务:首先将图像分割成网格,并将这些网格中的像素提取到孤立的patch中。然后对这些patch进行洗牌,模型必须预测patch的正确顺序。
Video Jigsaw任务:将每帧分割成2D网格(2D tensor) 或 将多个帧分割成3D网格(3D tensor),提取为patch。然后对这些patch进行洗牌,并要求模型预测正确的顺序或用于洗牌的排列。
2. Generative Approaches 生成任务
- Adversarial and Reconstruction 对抗与重建:重建改变的输入/和/或噪声;
- Frame Prediction 帧预测:利用前一帧生成序列中的后一帧;
- Masked Autoencoders 掩码自编码器MAE:生成Mask的pixel,可以是帧内的patch,也可以是整个帧;
- Multimodal Masked Modeling 多模态掩码建模:生成视频、文本和/或音频tokens序列中Mask的输入。
使用Transformer生成Mask的输入(MAE)作为其预训练任务的方法是表现最好的:
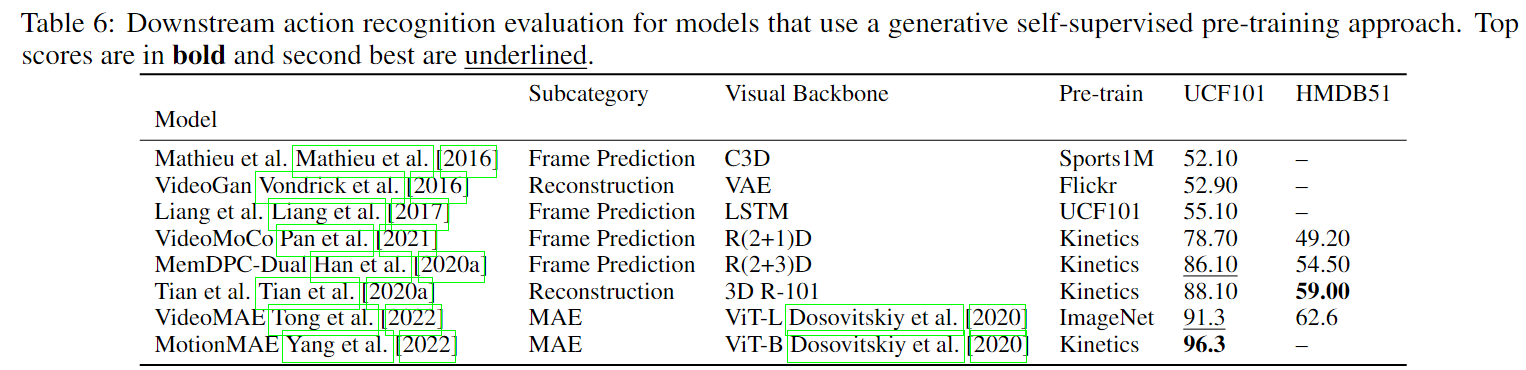
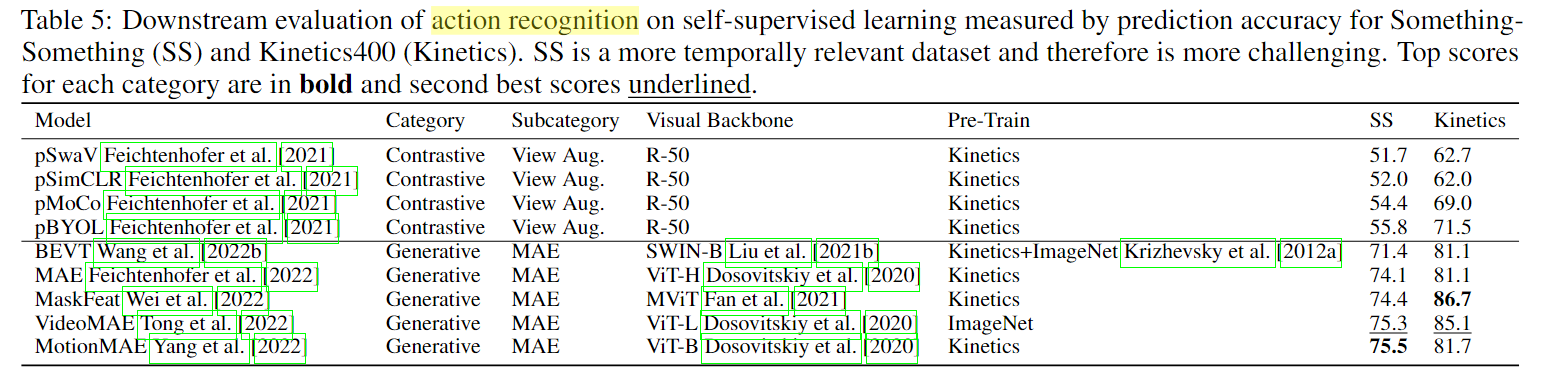
由于多模态掩模建模(MM)使用文本,这些生成方法还可以在标题生成上进行评估:
2.1 Adversarial and Reconstruction 对抗与重建
一个生成器generator从正态分布中获取随机噪声来生成图像。然后将生成的图像和原始图像传递给判别器discriminator,判别器discriminator对真实(原始)和虚假(生成)进行分类。

2.2 Frame Prediction 帧预测
前一帧被送到编解码器encoder-decoder以生成序列中的下一帧。然后将原始帧和下一帧预测传递给判别器,判别器对真实(原始)或虚假(生成)进行分类。

2.3 Masked Autoencoders 掩码自编码器MAE
随机屏蔽视频中的时空片段,并学习一个Autoencoder以像素重建它们。
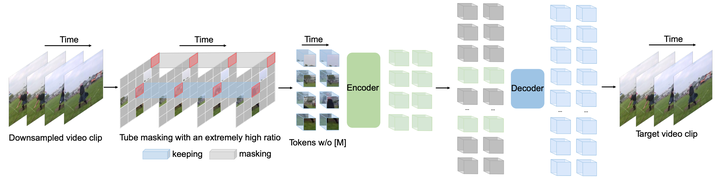
2.4 Multimodal Masked Modeling 多模态掩码建模
使用了视觉、文本和/或音频tokens的组合来进行Mask建模,以学习不同模态的联合空间。
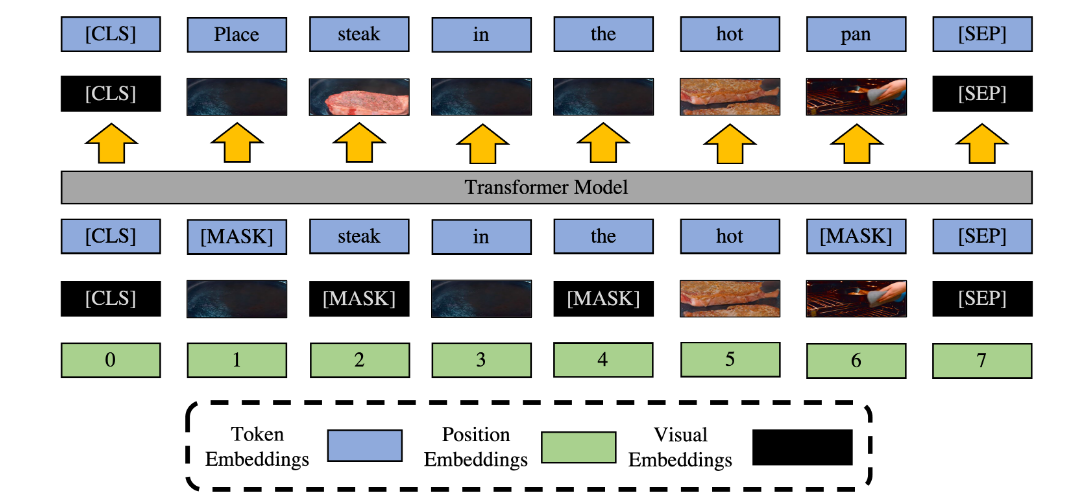
使用具有多种模态的掩码建模的方法将可视数据转换为离散的tokens,从而允许在序列中组合Text tokens和Visual tokens。在本例中,Text tokens和Visual tokens被随机mask,并要求模型“填补空白”。
3. Contrastive Learning 对比学习
将正样本对拉近,而将负样本对拉开。如从视频中的锚帧和同一视频中不同时间的帧(例如同一剪辑中的相邻帧)生成正样本对。在锚帧和其他视频的帧之间创建成一组负样本对。
产生正样本对和负样本对的方法是不同对比学习方法之间的主要区别因素:
对比学习目标函数:
- Cross-entropy:交叉熵与二元分类器一起用于确定一对是否“好”。
- Discriminators:用于返回正对较高、负对较低的分数。最常用的对比训练目标是NCE的变体,起源于NLP领域。
- NCE loss:NCE loss取一对正样本和一组负样本作为输入,使正样本对之间的距离最小,负样本对之间的距离最大。
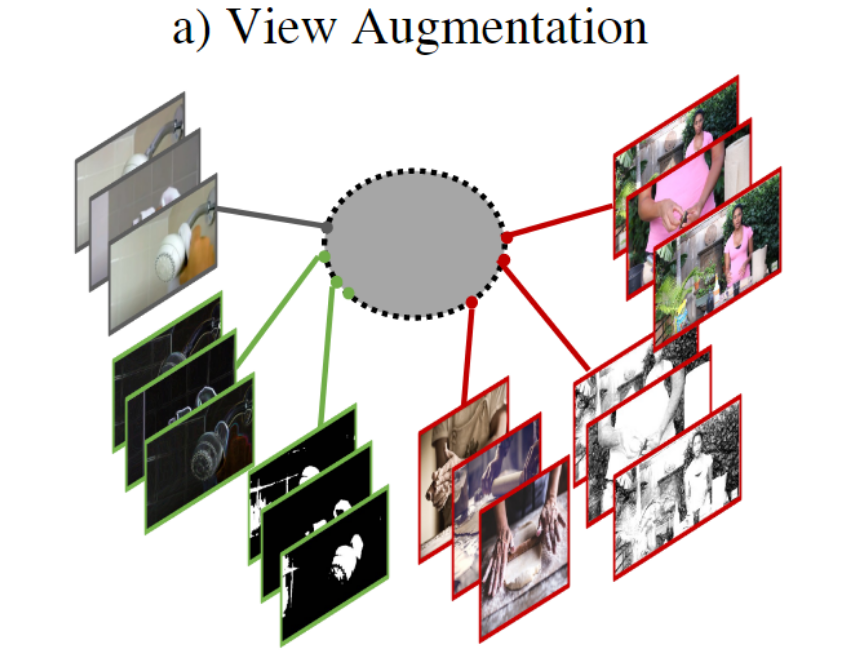
3.1 View Augmentation 视图增强
在视频中,这些增强应用于片段中的每一帧,关注通过各种转换来改变外观。这些包括随机调整大小裁剪,通道下降,随机颜色抖动,随机灰色和/或随机旋转。正样本对是原始clip的增强版本,而负样本对是来自其他视频的clip。

对于一个data sample(图中为video clips),对他们进行两种random data augmentation(如剪切,反转,高斯模糊,颜色抖动等)。经过augmented的samples放入一个encoder的network中来提取feature。
最终的contrastive loss形式如下,其目的就是尽可能地**pull(拉近)同一个sample的feature在feature space中的距离(positive samples),而push(远离)**来自不同sample的feature在feature space中的距离(negative samples)。这种contrastive loss也被称为infoNCE loss,最早在CPC中被提出。
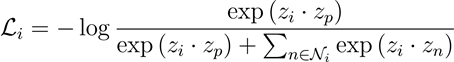
infoNCE loss基于instance discrimination假设:random augmentation并不会改变sample的semantic,因此我们希望模型提取同一个sample经过augmentation后的feature作为一组,而其他所有不同sample提取到的feature作为另一组。
CoCLR NIPS2020
Motivation
但是这种instance discrimination的方法却存在问题。对于上图中的两个video clips,上面的是一个人在打高尔夫,下面的是一个人在扔铅球。这种两种截然不同的运动,我们当然是希望它们学习到的representation在feature space中越远越好。
但是对于下图中的两个video clips,它们都是一个人在打高尔夫,这两个sample的semantic语义是非常相近的。但是按照instance discrimination的思想,由于它们是从不同视频裁剪出的clip,属于不同sample,所以在使用infoNCE loss时也会尽量的pull它们的feature distance,这显然是不合理的。
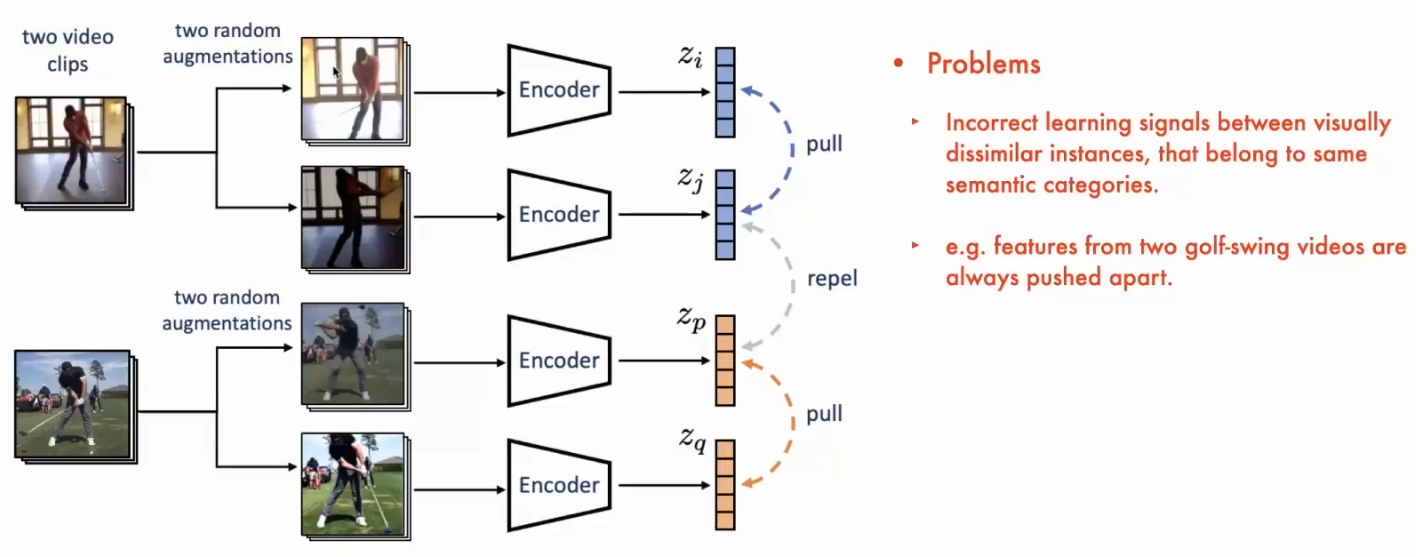
因此:我们希望通过semantic对学习到的representation进行分组,而不是通过instance进行分组。 以下图中两个video clips为例,两个clips都是关于高尔夫。但是不管是前景还是background都非常不同,所以这两个instance在RGB space中的distance是非常远的(dissimilar)。但是当我们以optical flow的view来看着两个实例时,由于两个人的动作都是在挥打高尔夫,所以这两个instance在flow的feature space里面是非常接近的(similar)。同样的,也有可能有这样的两个instance,它们在flow space中dissimilar,但是在RGB space中是similar的。
Method
利用这种特性,作者设计了一种协同训练网络(包括两个网络),通过交替使用一个 space/view 来帮助另一个 space/view 来共同训练两个网络。
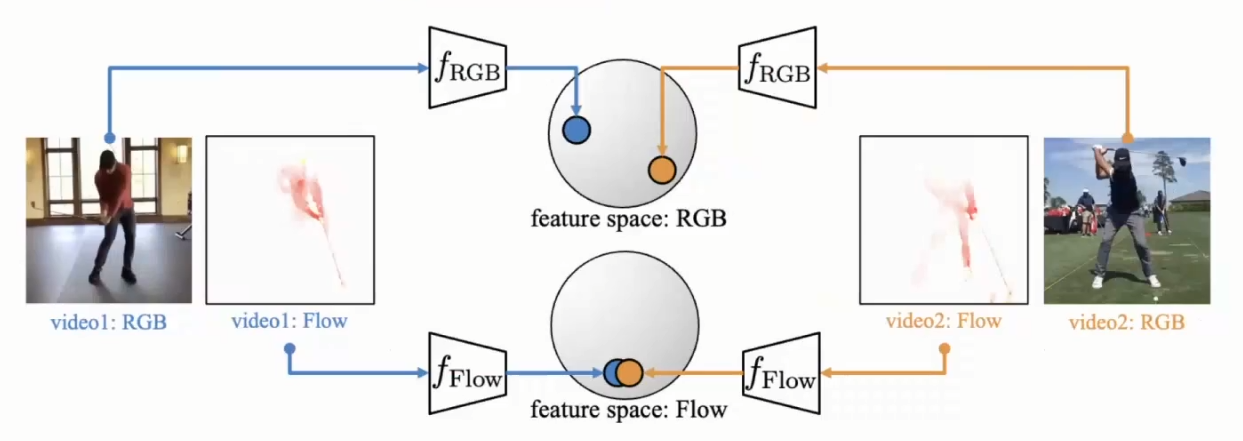
具体来说,作者设计了两个网络,一个用于RBG space,另一个用于optical flow space。整个训练是一个two stages的过程:
1.初始化:两个网络都首先通过InfoNCE loss的方法在各自的space中进行pre-trained初始化;
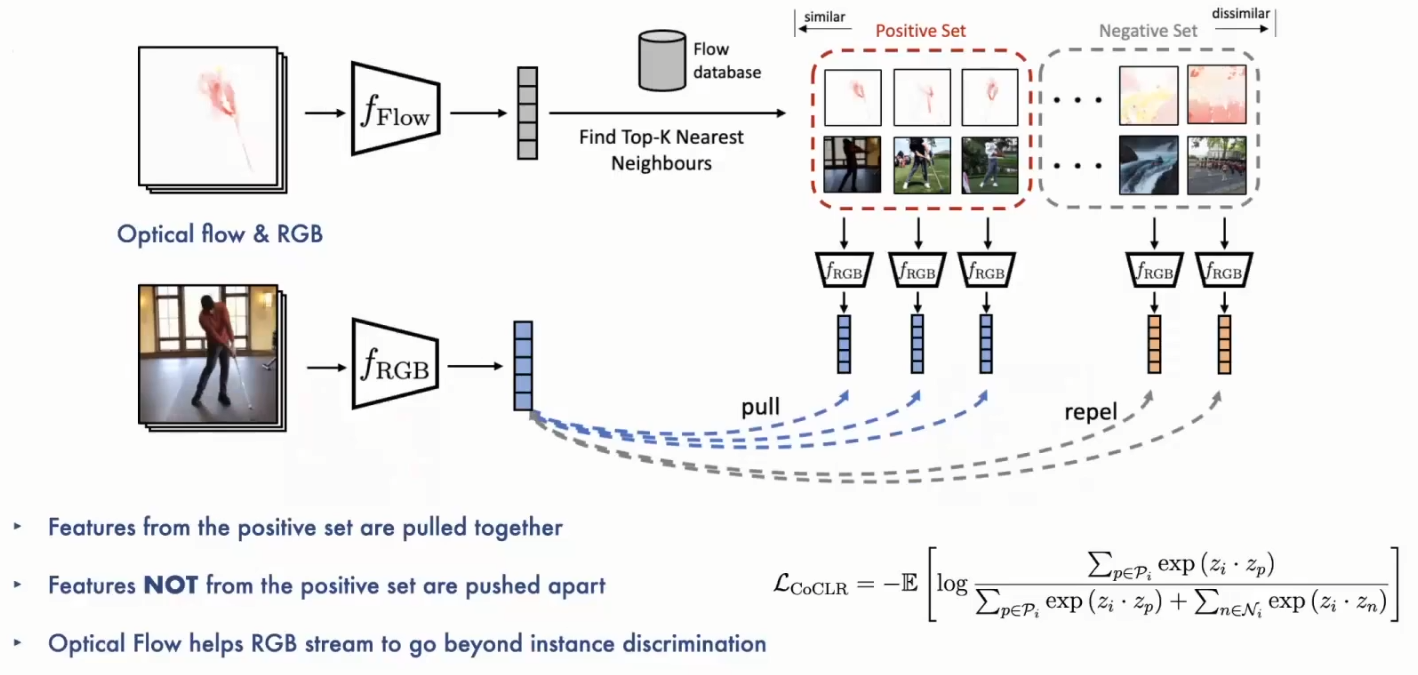
2.交叉采样:通过InfoNCE loss的方法进行train之后,RGB和Flow网络相较random初始化的网络都获得了更强学习representation的能力。之后交替利用一个网络来为另一个网络进行positive pairs的采样:首先获取optical flow的sample,将它送到Flow网络中提取特征,然后将该特征和其他flow sample提取的feature进行比较,选取在flow space中top K个相近的instances(这里K为超参数)。然后我们将这K个在flow feature相近的sample作为positive pairs用于RGB网络中对比学习的更新,更新的loss函数被称为MIL-NCE(multi-instance contrastive loss)。
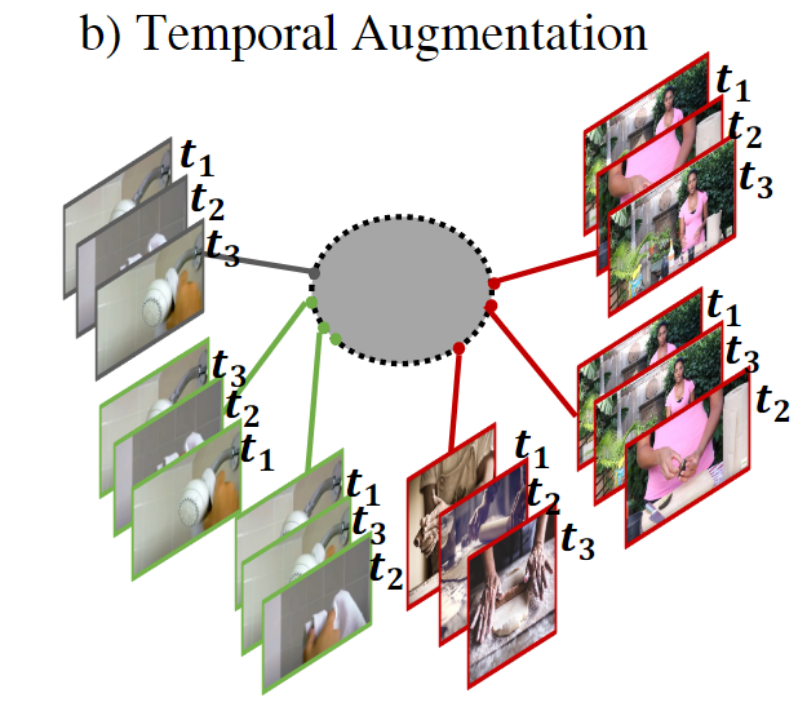
3.2 Temporal Augmentation 时序增强
通过修改时间顺序或clip间隔的开始和结束点来生成正负样本对:相同视频的不同时序构成正样本对,不同视频的相同/不同时序构成负样本对。

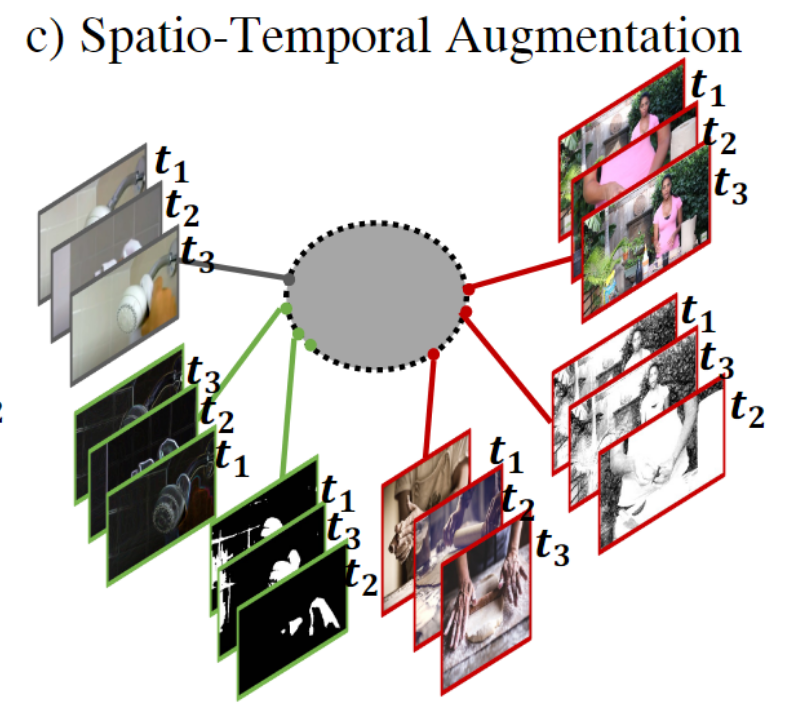
3.3 Spatio-Temporal Augmentation 时空增强
Spatio-Temporal Augmentation是View和Temporal变化的结合:相同视频的空间数据增强和时序变化构成正样本对,不同视频的空间数据增强和时序变化构成负样本对。

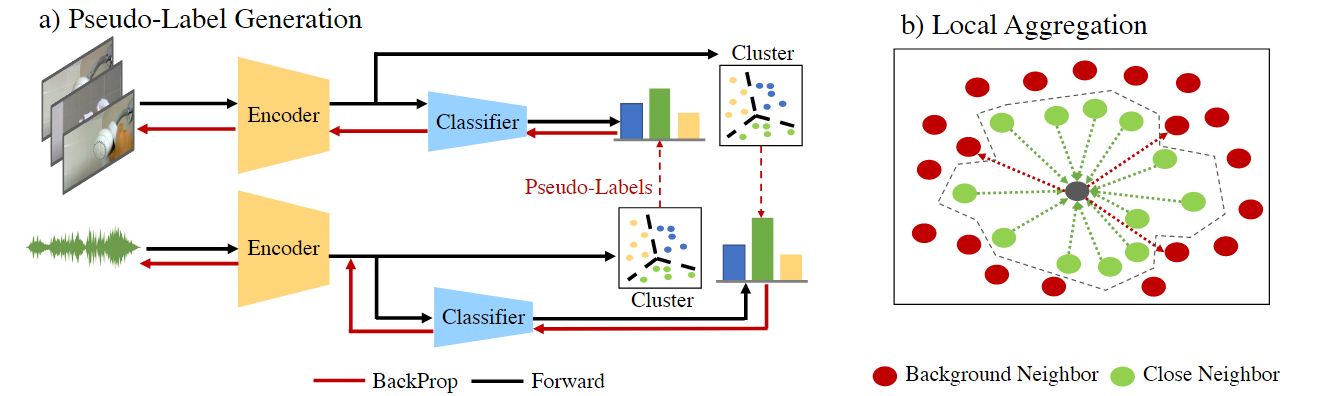
3.4 Clustering 聚类
伪标签生成使用聚类分配作为具有多种模态的伪标签。一个信号的聚类分配用作另一个信号的伪标签。
局部聚集关注latent空间,其中每个样本的“近”邻居被拉得更近,“背景”邻居被推得更远
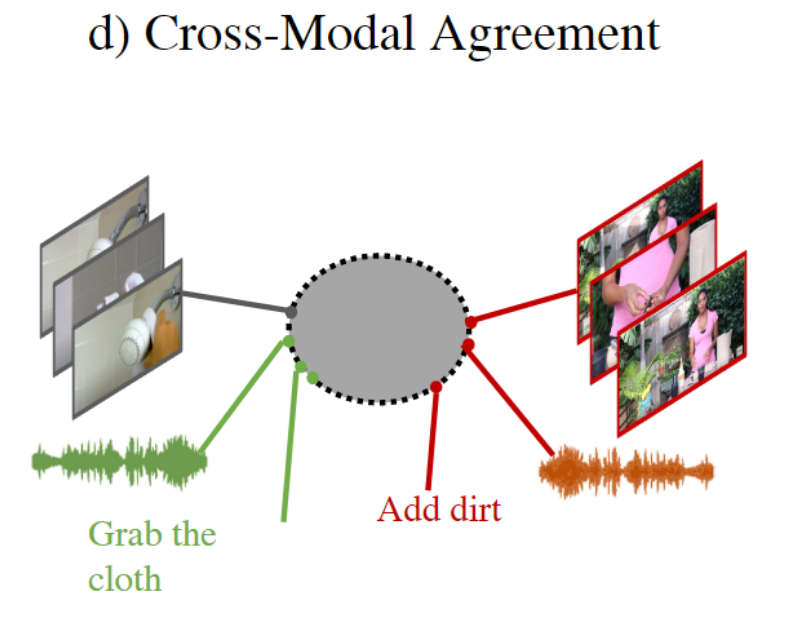
4. Cross-Modal Agreement 跨模态增强
正样本是来自相同clip的音频或文本样本,负样本是来自其他clip的音频、视频和/或文本。跨模态的正负样本对:如<video, text>,<video, audio>,<video, text, audio>。

4.1 Video and Text
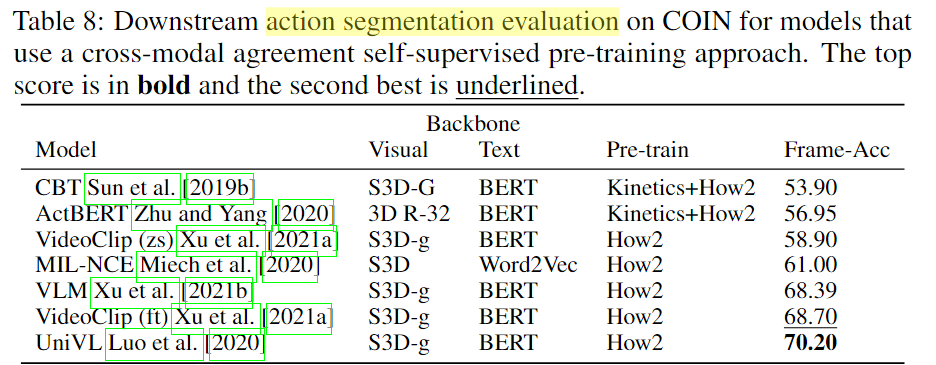
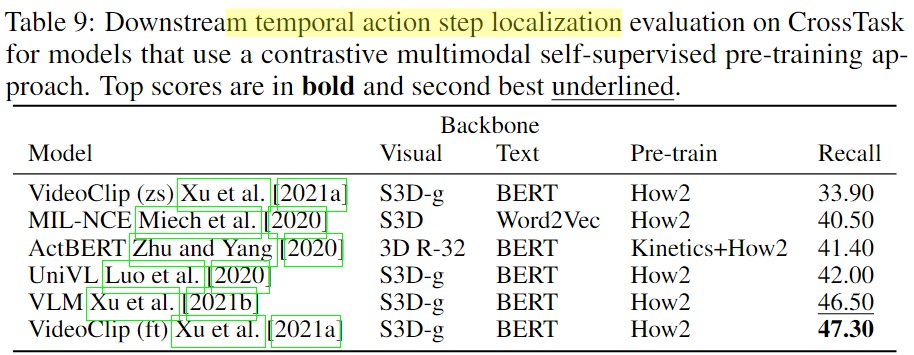


4.2 Video and Audio
4.3 Video, Text and Audio
5. Tracking 追踪
第一帧是有segment mask的,后面的帧要跟踪这个mask。或者完全没用第一帧的mask,分割每帧的object。

Limitations and Future Work
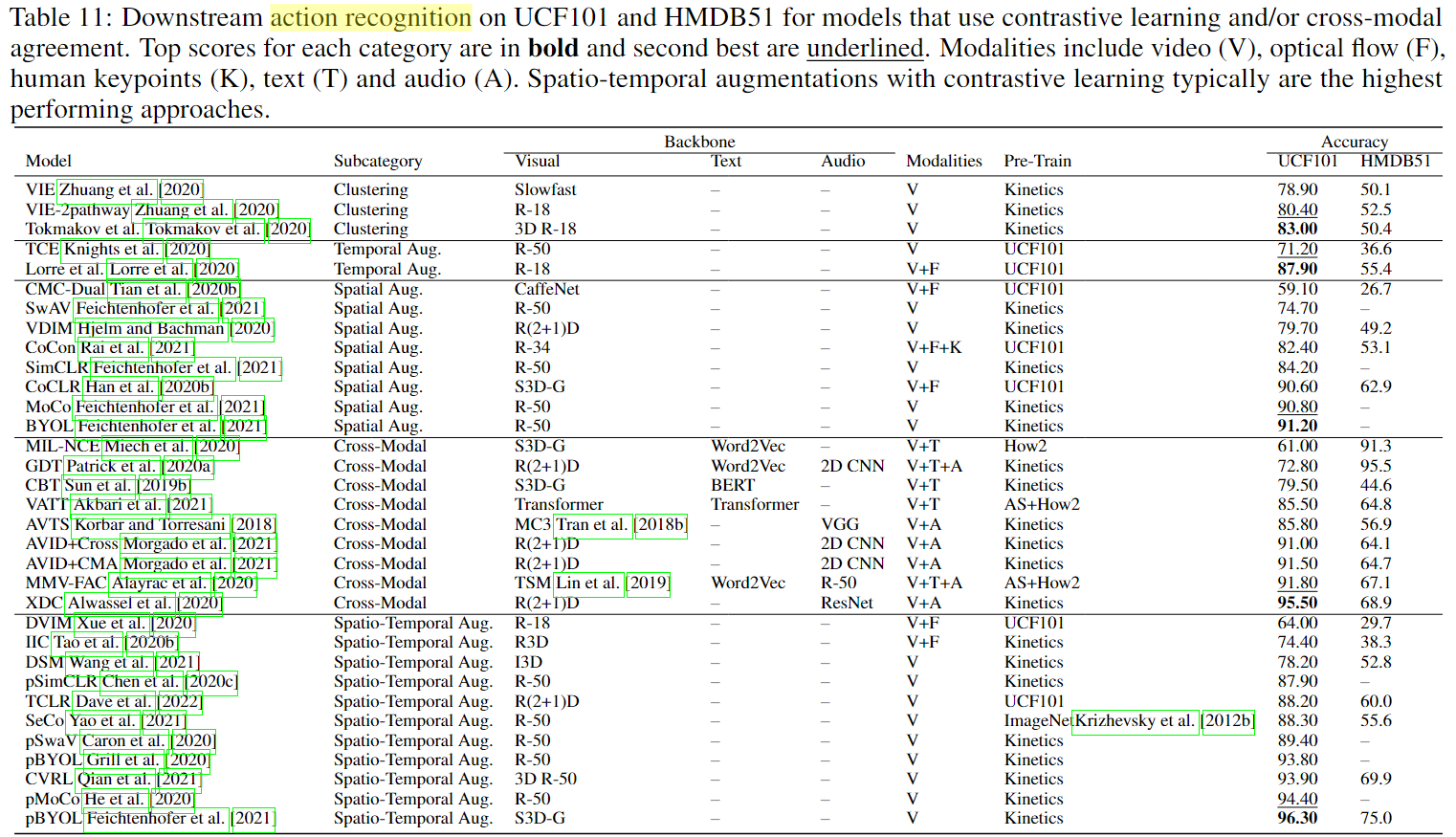
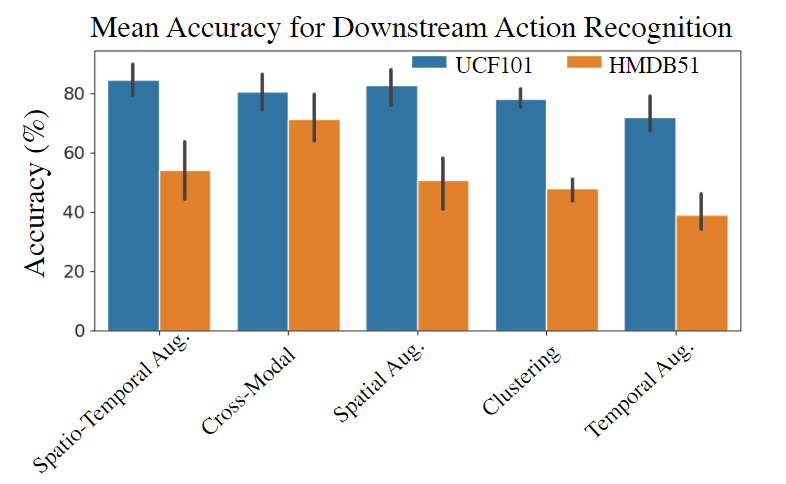
- 在评估下游动作识别时,大多数方法使用UCF101和HMDB51缺乏时间特异性的数据集。更多的方法应该额外评估时间特定数据集,如Something-Something数据集Goyal等人[2017]。特定于不同的类别,未来的工作应该试图了解跨模态方法之间的性能差异和鲁棒性。
- 从自我监督的角度来看,视频对象检测、动作检测、视频语义分割等没有得到很好的探索,是一个很有前途的未来方向。
- 结合来自多个类别的学习目标,如掩模建模和对比学习,可以进一步探索。
- 长期视频表示。目前的方法主要集中在小的视频片段上,不学习长视频的表示。在大多数方法中,视频被分成剪辑作为其预处理的一部分。虽然这些方法使用视频的时间元素来改进学习,但它们缺乏长期的时间学习。此外,已经证明像MSRVTT和UCF101这样的数据集不一定需要时间学习。未来的研究应该评估更多与时间相关的数据集,如SomethingSomethingSomething 和NExT-QA 。未来的研究还应该尝试从整个长视频中学习表示,专注于时间学习,而不仅仅是使用时间信号作为训练的指导。
- 简单的端到端方法。大多数方法使用预训练的主干作为特征提取的依赖。例如,许多多模态方法使用MIL-NCE的S3Dg。该模型已经在文本和视频上使用对比损失函数进行预训练,并且是一个开箱即用的大型计算方法。这些新方法从 S3Dg 中提取特征,然后添加大型计算方法。很少有人关注减少这些模型的大小或创建不直接依赖先前工作的方法。此外,这可以防止探测模型更好地理解这些模型正在学习的内容,尤其是当文本有语义信息时。当下游任务也是动作识别时,使用 I3D 等网络的纯视频方法也是如此。最近有一些方法利用变压器视觉编码器,如将原始视频作为输入,但这一领域的研究有限,但对未来的工作有很大的潜力。未来的工作应该更多地关注不直接依赖于先前工作的简单端到端方法,因此可以减少计算成本和依赖性。
- 可解释性和可解释性。下游任务专注于每个模态的特定区域,例如动作识别、音频的事件识别和文本的字幕生成。虽然这些有助于理解学习表示的普遍性,但它们并没有提供对这些模型实际学习的内容的洞察。虽然这是通过探测模型 Thush 等人在图像域中完成的。 [2022],但没有一种方法表明理解模型用于生成视频域中的表示。这种缺乏可解释性强制执行“黑盒模型”方法。未来的研究应该侧重于了解这些模型正在学习的内容以及为什么它们的表示更具泛化性。通过这种理解,可以进一步提高模型,并对视频提供更多理解。虽然多模态方法通常在下游任务中表现最佳,但缺乏对模型学习的内容的洞察阻碍了理解这些模式是如何相互作用的。例如,当使用两种模式时,由此产生的联合嵌入空间看起来是什么。在图 16 中,使用 t-sne 可视化该联合空间的示例。样本是来自 YouCook2 数据集中不同食谱的片段,其中视觉特征被描述为 ·,文本特征为 x。虽然跨模态VideoClip Xu等人[2021a]和联合模态UniVL Luo等人[2020]模型在文本到视频检索任务上显著优于MIL-NCE模型Miech等人[2020],但每个模态的特征嵌入彼此相距甚远。未来的工作应该调查这样的问题。更可解释的模型将更好地表示文本、视频和音频是如何交互的,并可能导致改进的语义图、事件交互的时间理解等。
- 标准基准。主干编码器和预训练协议的变化使得直接比较变得困难。虽然这项调查试图组织这些差异并讨论几个现有的基准Feichtenhofer等人[2021],Huang等人[2018],Buch等人[2022],但社区对自我监督学习进行基准评估是有益的,这允许在许多不同的方法之间进行更好的比较。虽然在图像域中,自监督学习Hendrycks和Dietterich[2018]、Bhojanapalli等人[2021]、Hendrycks等人[2021]研究了鲁棒性,但在视频领域Schiappa等人[2022]、Liang等人[2021]中缺乏类似的工作。这些模型通常在零样本学习上进行评估,因此理解对不同类型分布变化的鲁棒性将提供进一步的改进。未来的工作应该生成评估自我监督学习性能的基准以及不同方法的稳健性。
InternVideo: General Video Foundation Models via Generative and Discriminative Learning
https://zhuanlan.zhihu.com/p/614798241
















 4307
4307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











