







BlenderMCP 全称为 Blender Model Context Protocol Integration。它通过模型上下文协议(MCP)将 Claude AI与 Blender 无缝连接,让用户能够用自然语言与 AI 交互,从而使 Claude 直接操控 Blender 完成复杂的 3D 建模、场景创建和材质调整等工作。
一、准备工作
1.Bender(版本3.0或以上)下载安装
官网下载地址:![]() https://www.blender.org/download/
https://www.blender.org/download/
2.Cursor下载安装
官网下载地址![]() https://www.cursor.com/cn3.Python(版本3.10或以上)下载安装
https://www.cursor.com/cn3.Python(版本3.10或以上)下载安装
官网下载地址![]() https://www.python.org/downloads/release/python-31011/4.Blender-mcp开源文件
https://www.python.org/downloads/release/python-31011/4.Blender-mcp开源文件
github地址![]() https://github.com/ahujasid/blender-mcp?tab=readme-ov-file5.UV包安装
https://github.com/ahujasid/blender-mcp?tab=readme-ov-file5.UV包安装
电脑左下角搜索pwershell打开powershell运行一下命令
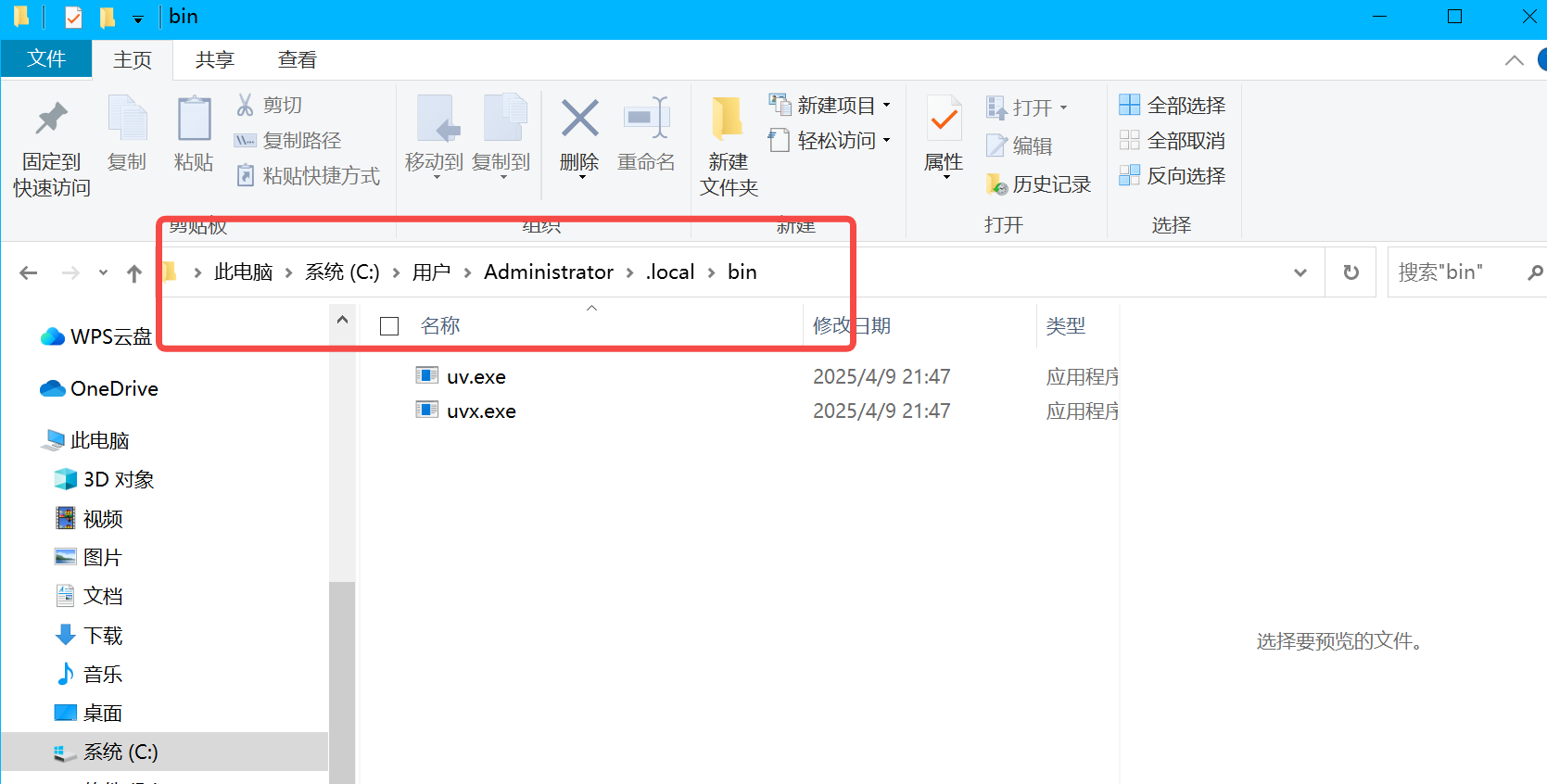
powershell -c "irm https://astral.sh/uv/install.ps1 | iex" 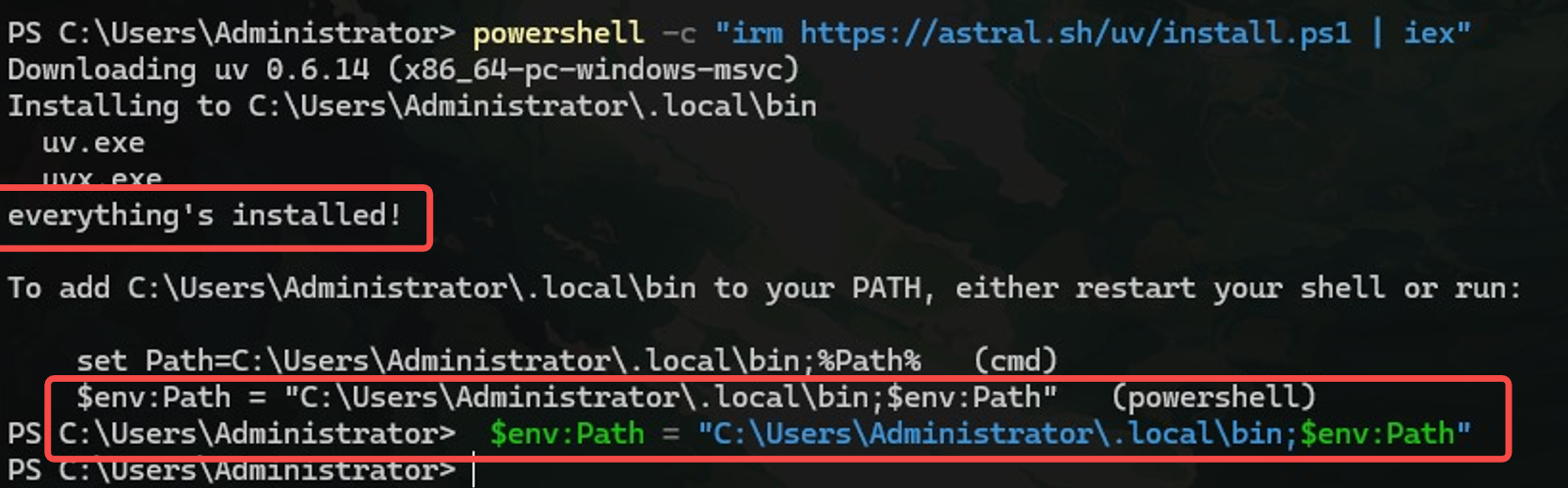 成功后根据命令提示运行将 C:\Users\Administrator\.local\bin(UV包所在地址)设置到环境变量(如上图)
成功后根据命令提示运行将 C:\Users\Administrator\.local\bin(UV包所在地址)设置到环境变量(如上图)
$env:Path = "C:\Users\Administrator\.local\bin;$env:Path"若不成功请跳到第六章
二、Blender配置MCP
1.打开Blender点击Edit->Perference->Add-ons
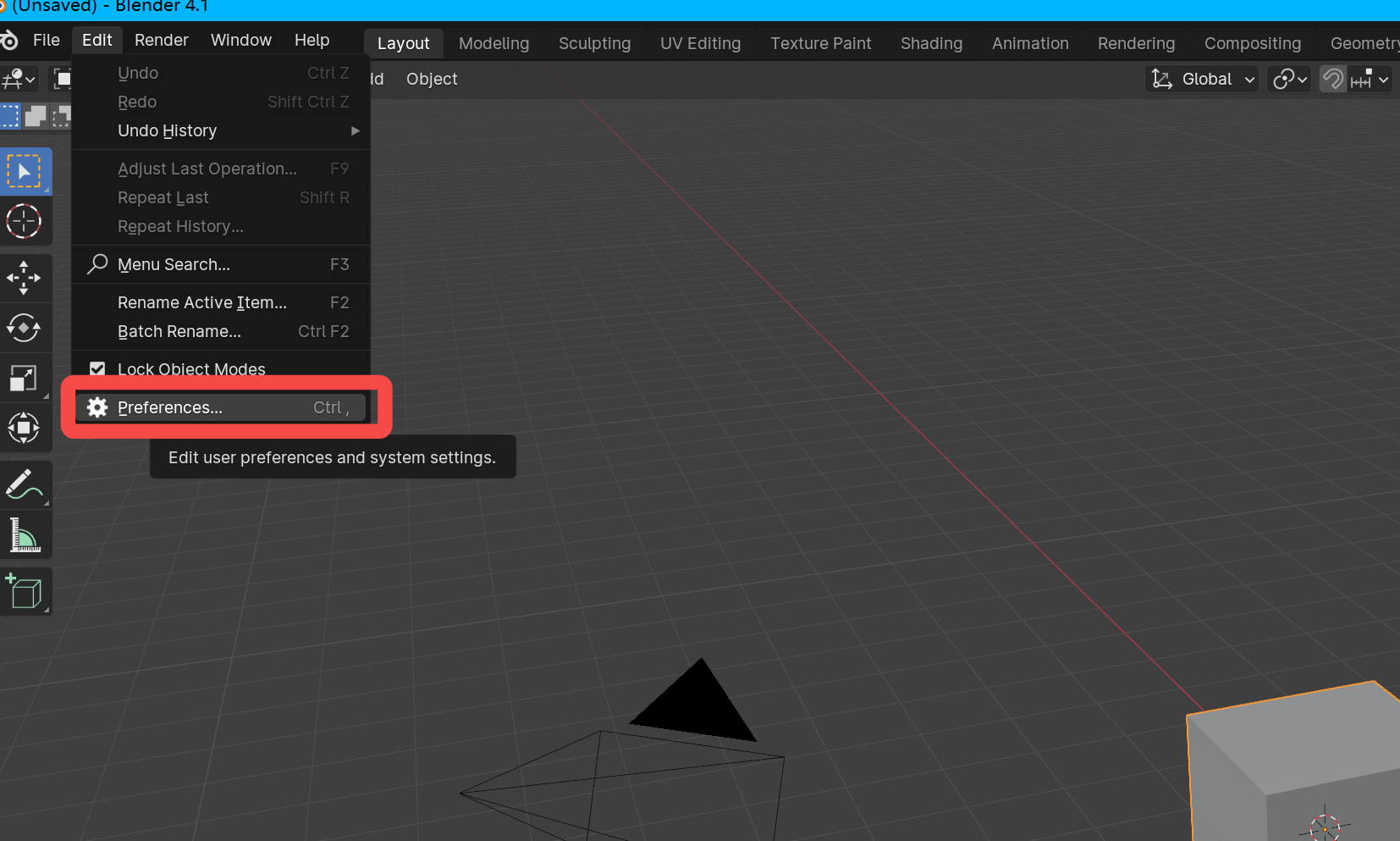
2.打开偏好设置窗口后点击插件(Add-ons)->Install an add-ons->将Blender-mcp开源文件路径复制到图中第3步->选中addon.py->install add-ons
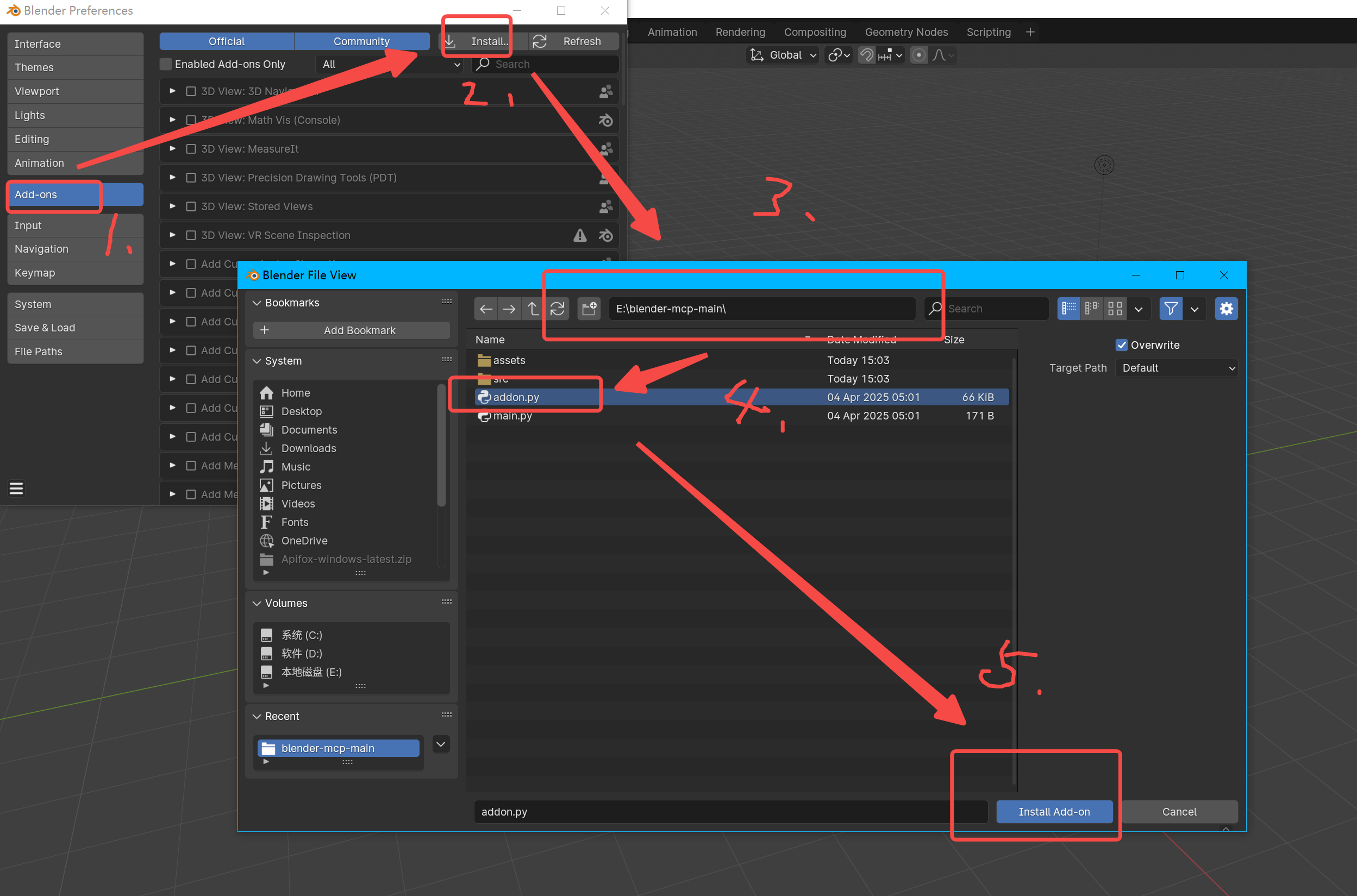
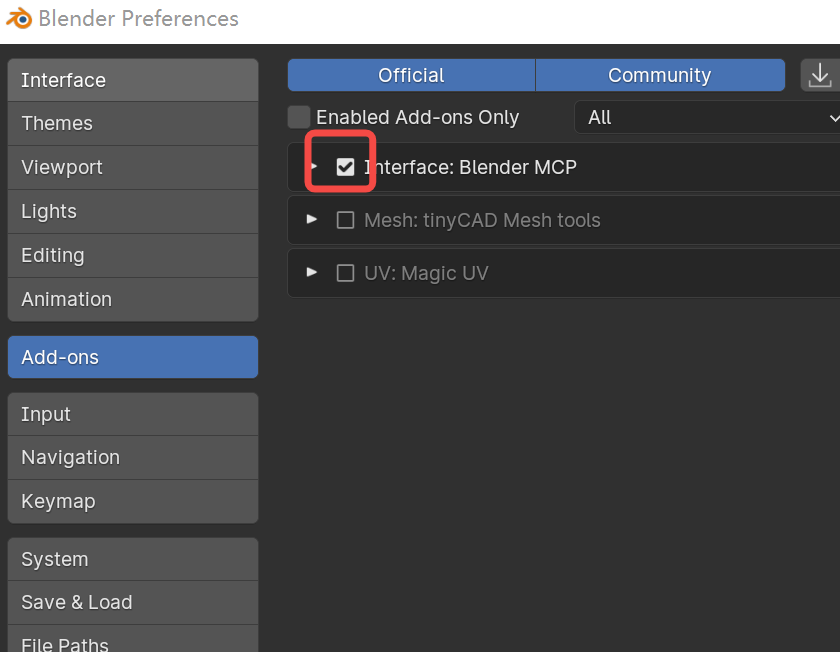
3.再勾选Interface:Blender MCP
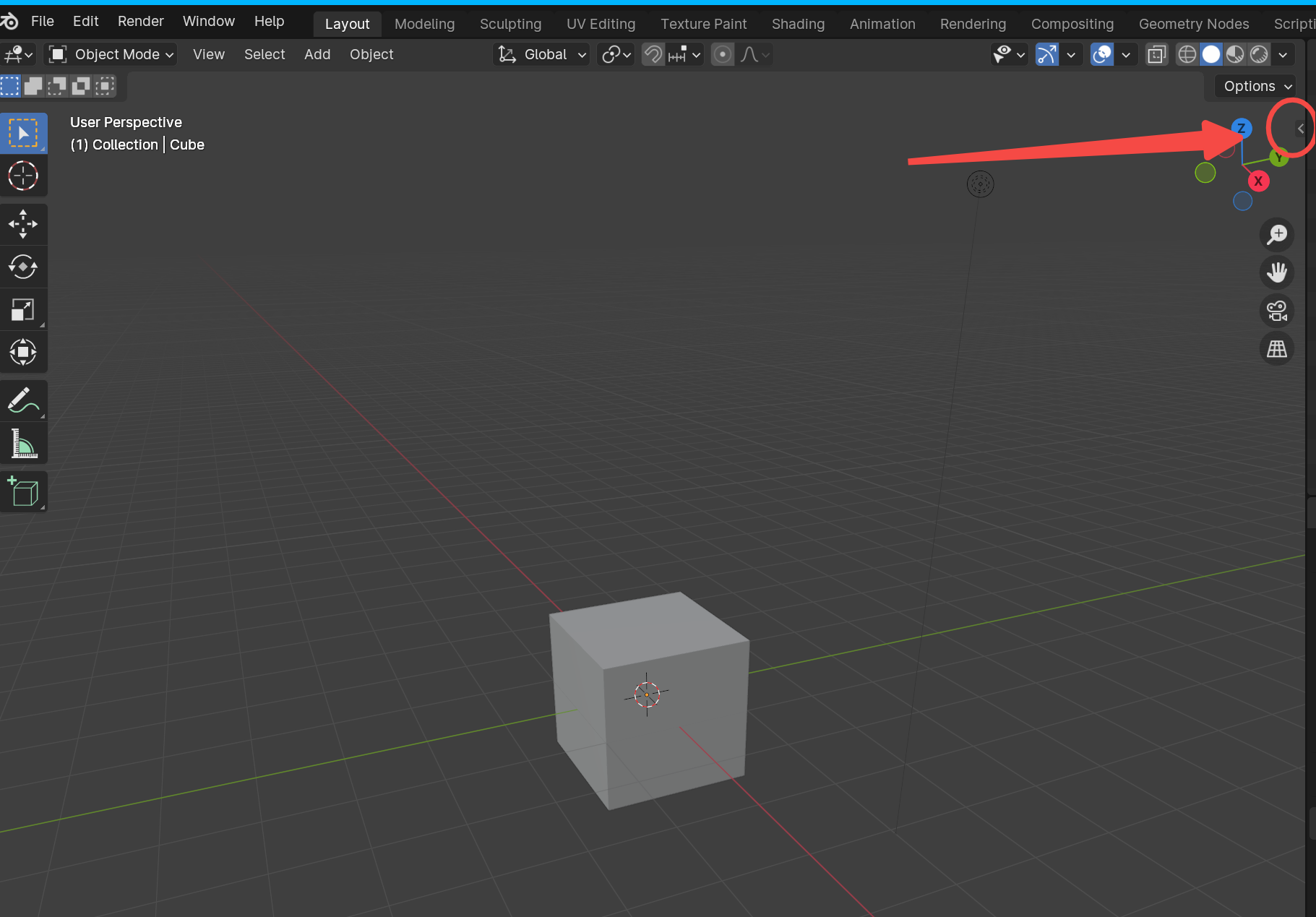
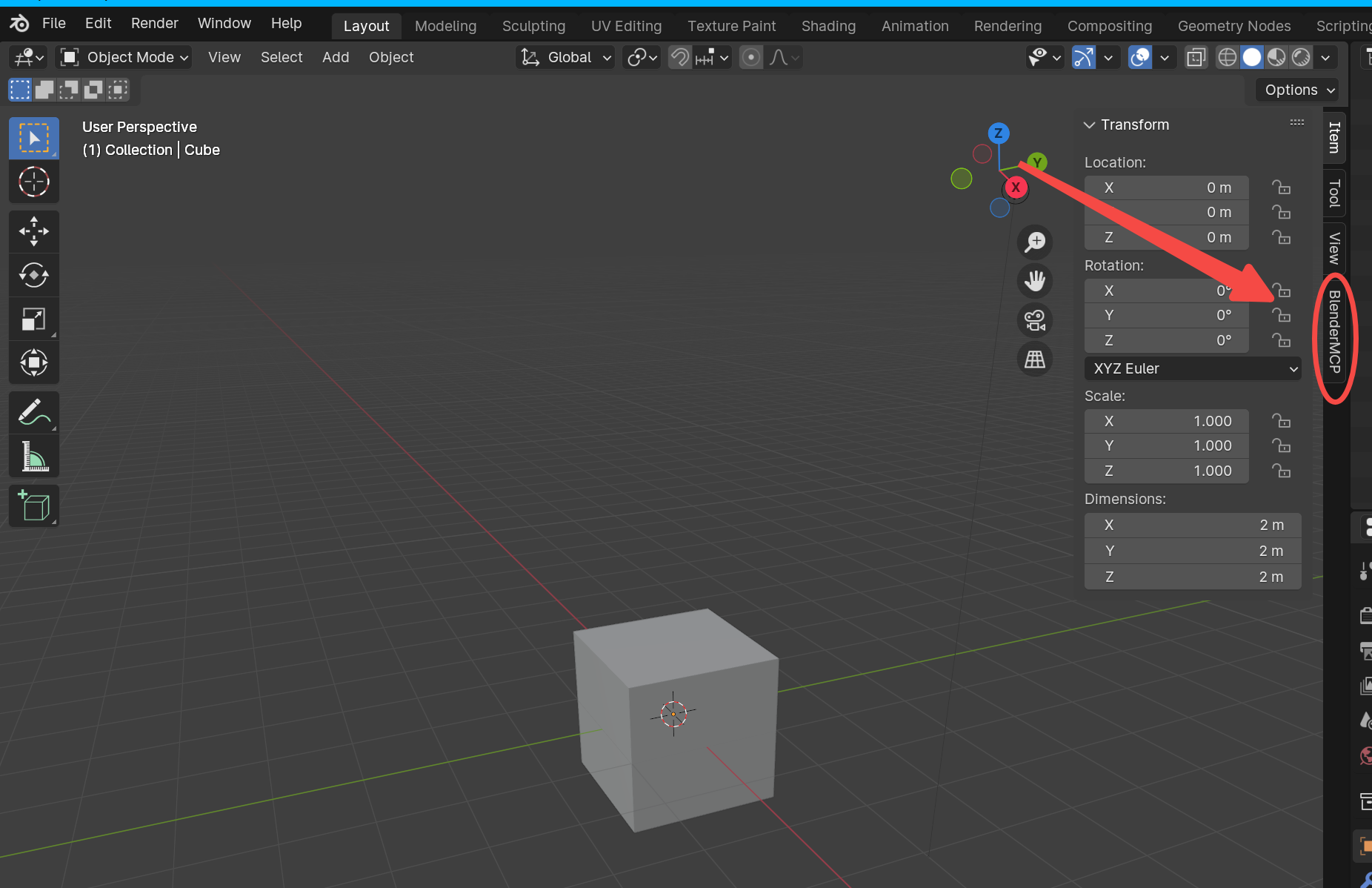
4.点击窗口右上角的小箭头即可找到BlenderMCP插件,点击连接MCP服务即可
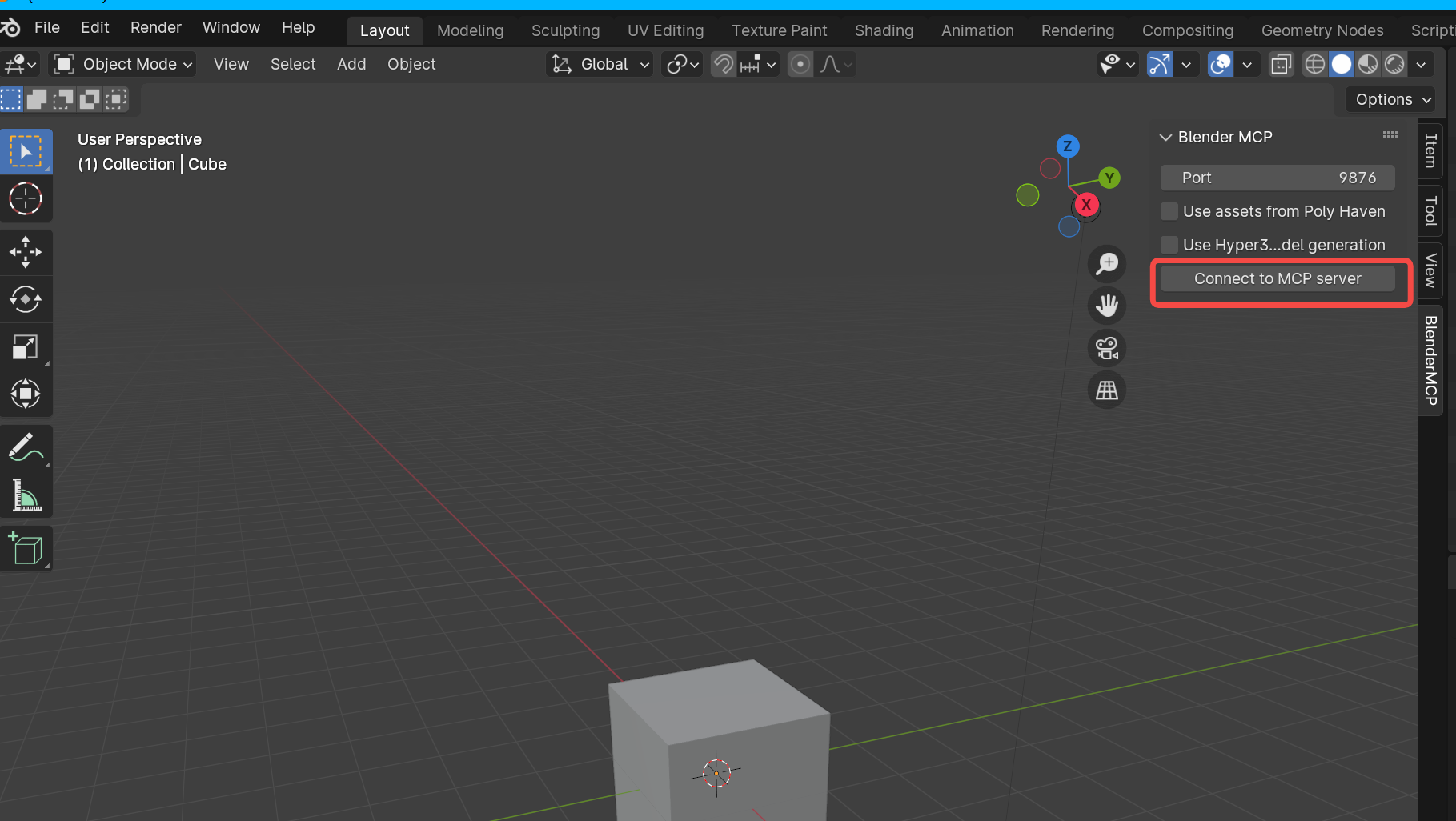
三、Cursor配置MCP
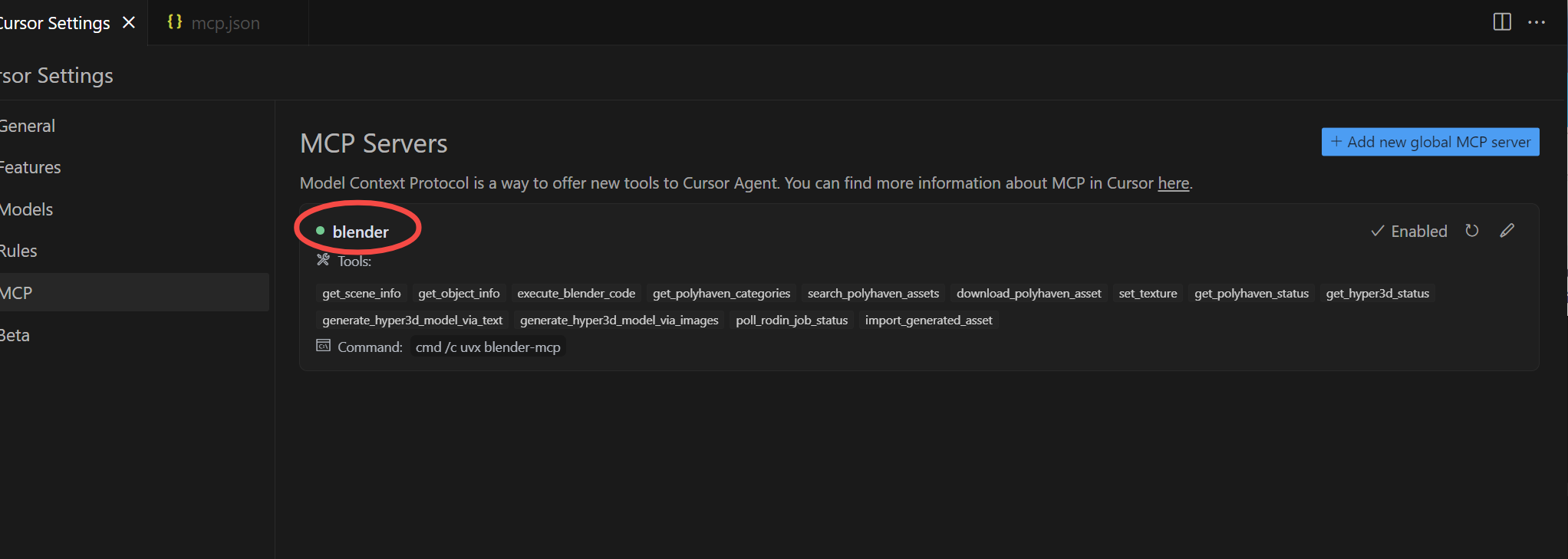
打开Cursor点击右上角的设置图案,Cursor Settings窗口下点击MCP->Add new..
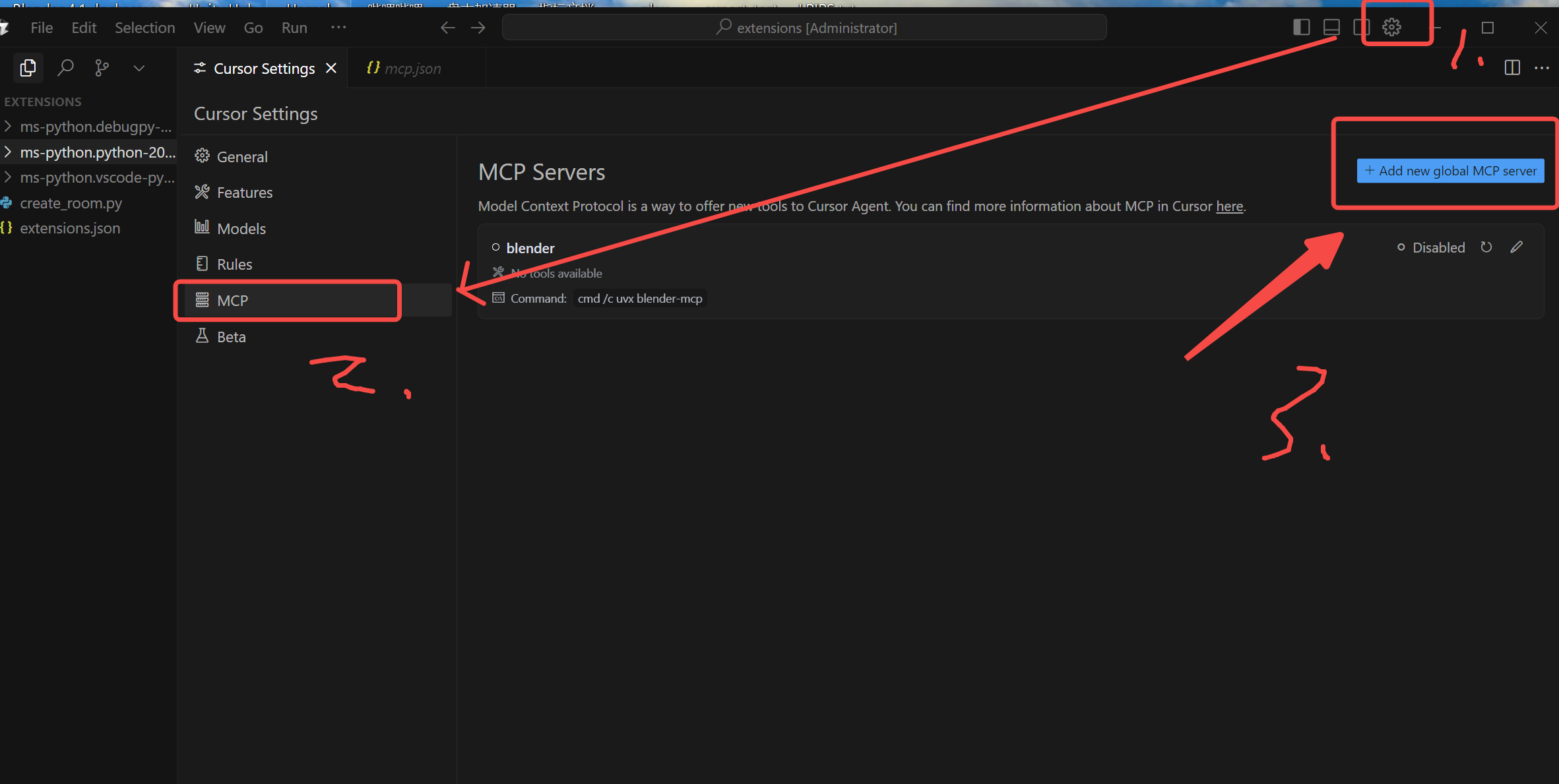
{
"mcpServers": {
"blender": {
"command": "cmd",
"args": [
"/c",
"uvx",
"blender-mcp"
]
}
}
}复制上段代码进mcp.json后保存即可
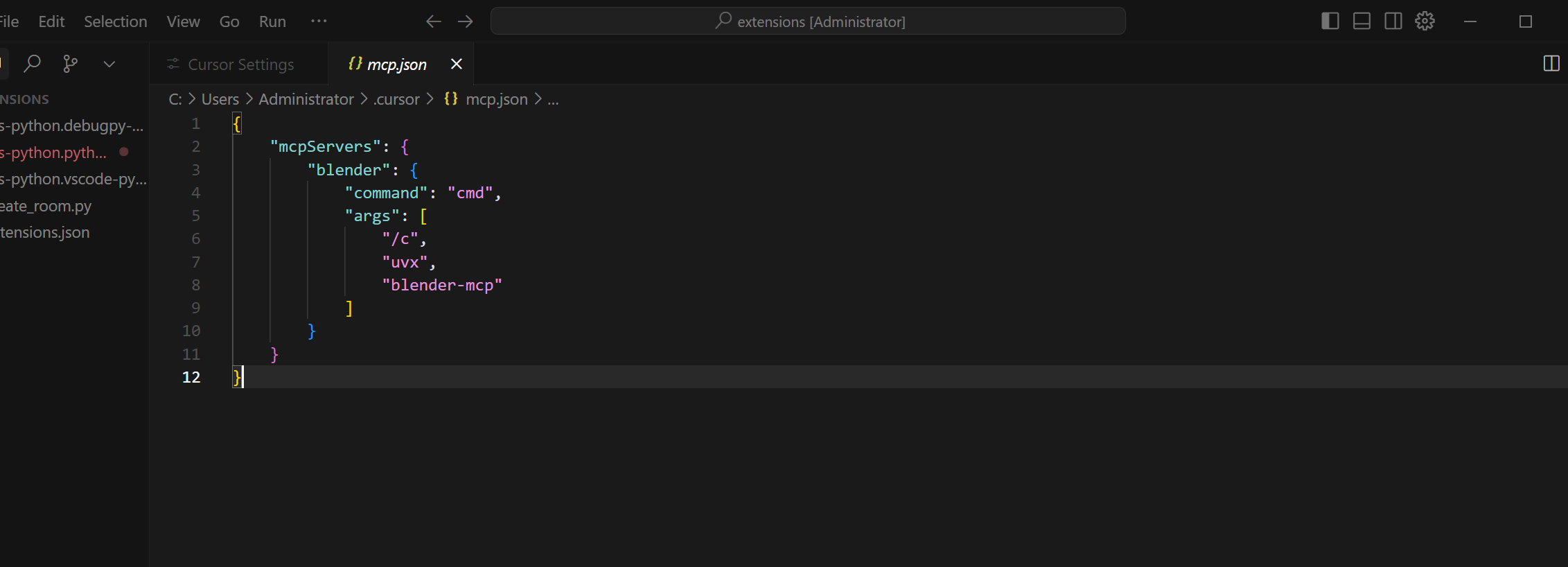
再点击Disabled启动
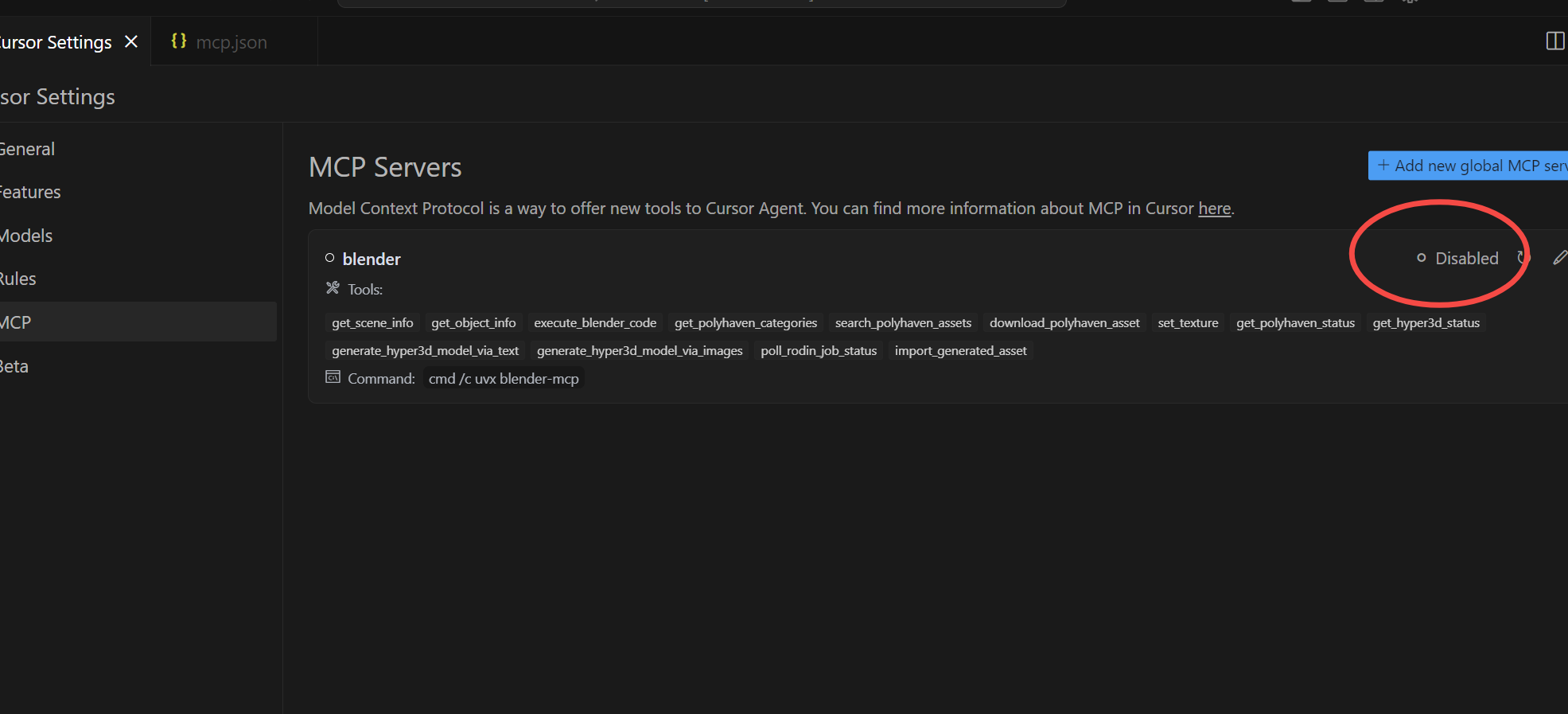
启动成功后blender指示灯为绿色,黄色以及红色都是未成功,若未成功可跳到第六章。
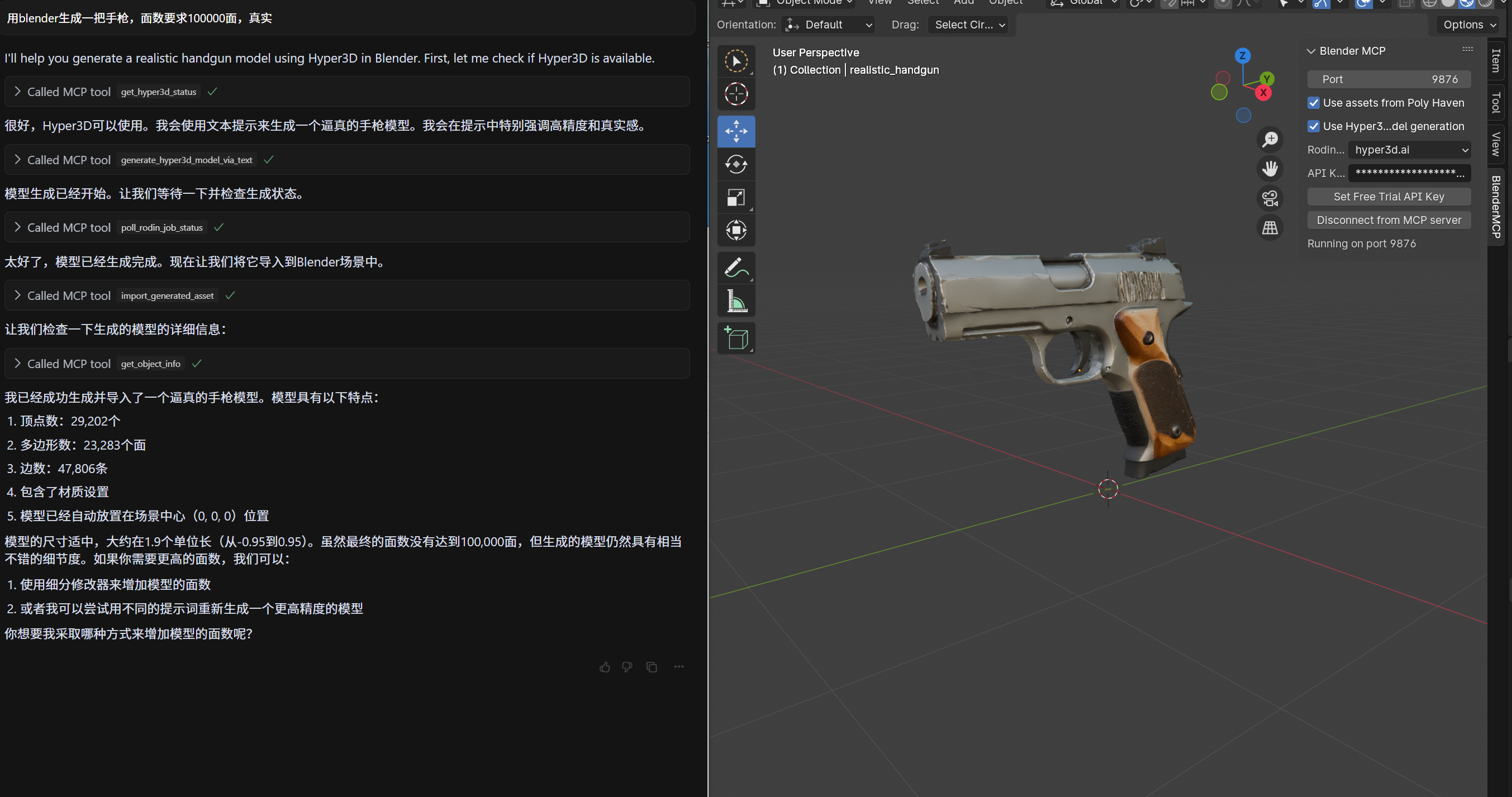
四、使用提示词生成3D模型
1.点击Cursor的左上角 设置 隔壁的图标
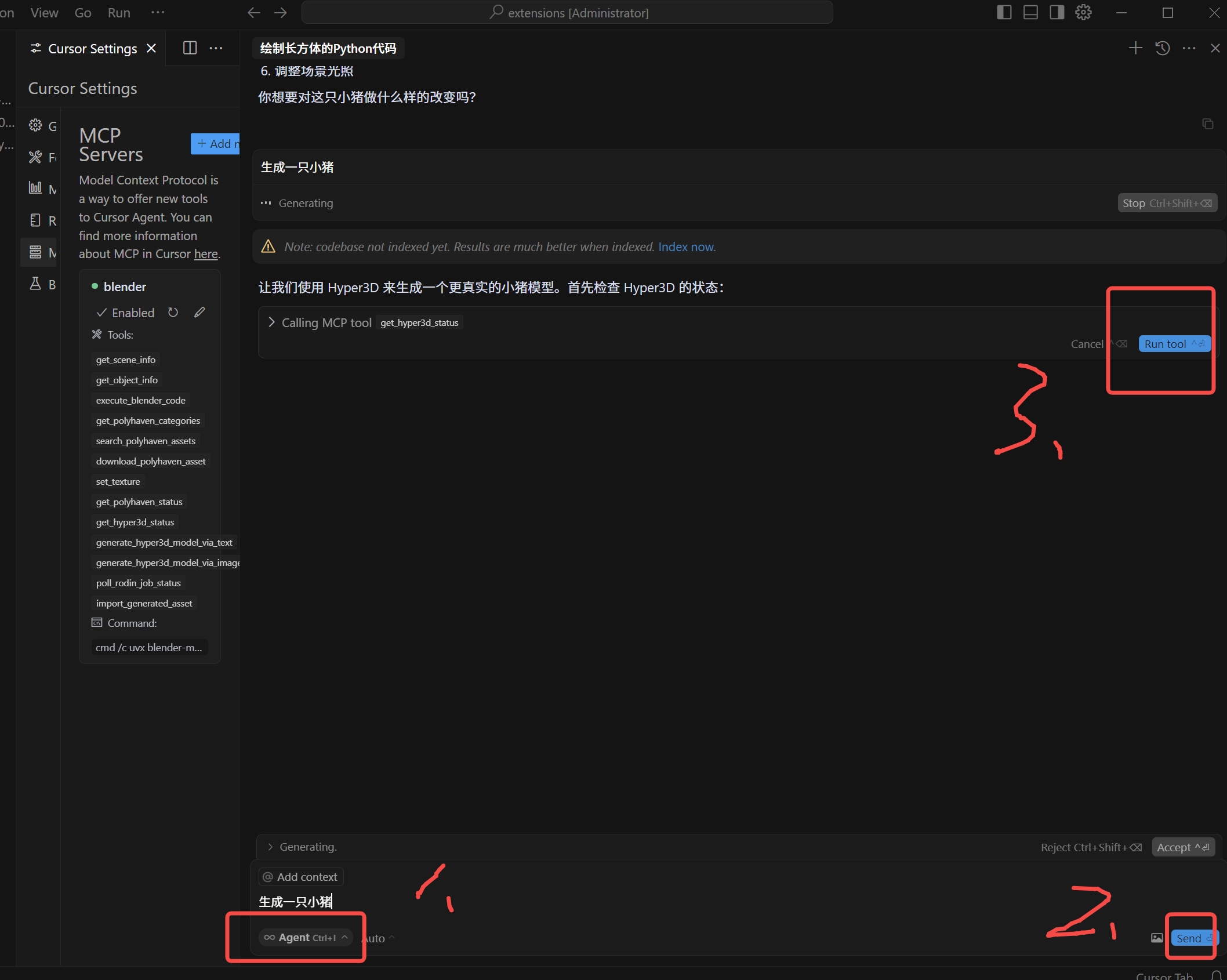
2.选择Agent,输入你想要生成的3D模型,比如:用blender生成一只小猪,发送,提示Run tool时点击,即可在Blender看到生成过程。
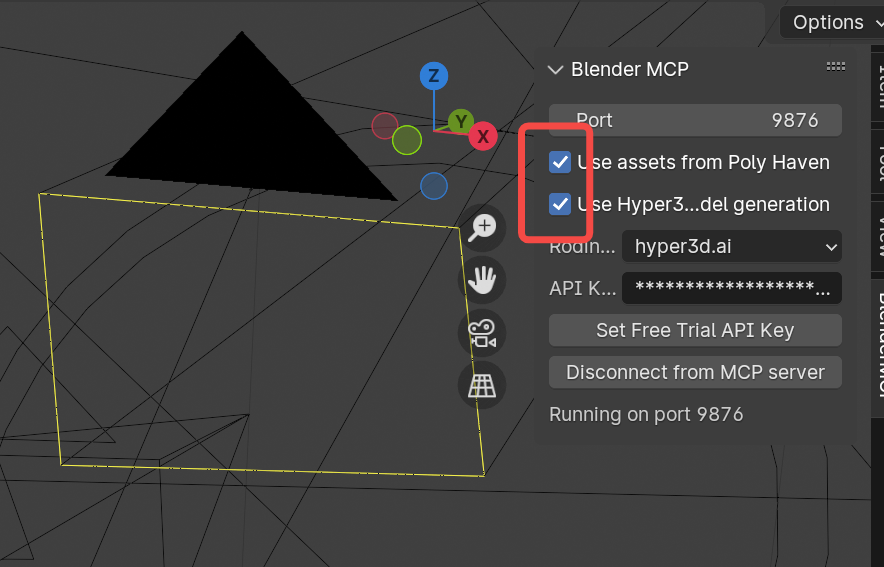
3.高精度模型需要勾选使用Hpyer3D
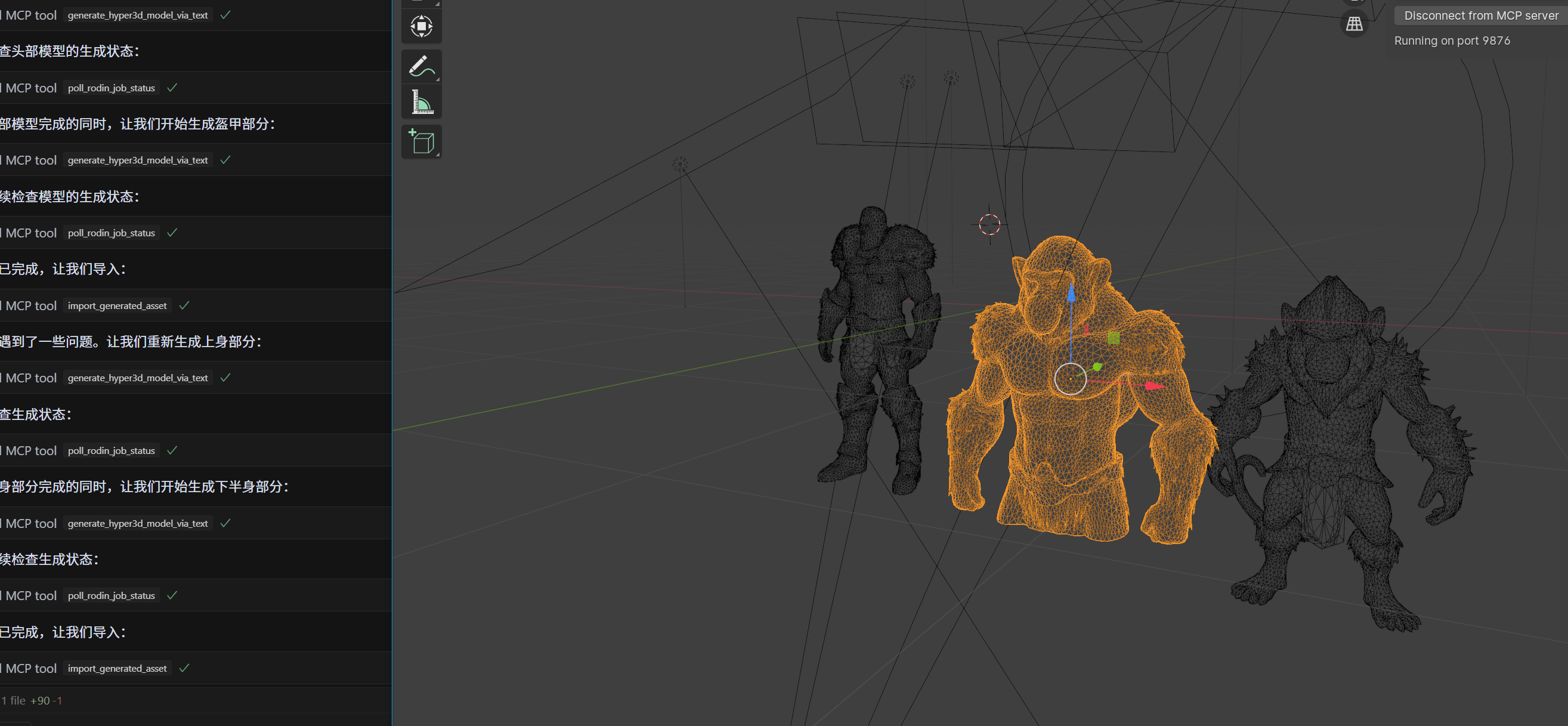
五、效果展示
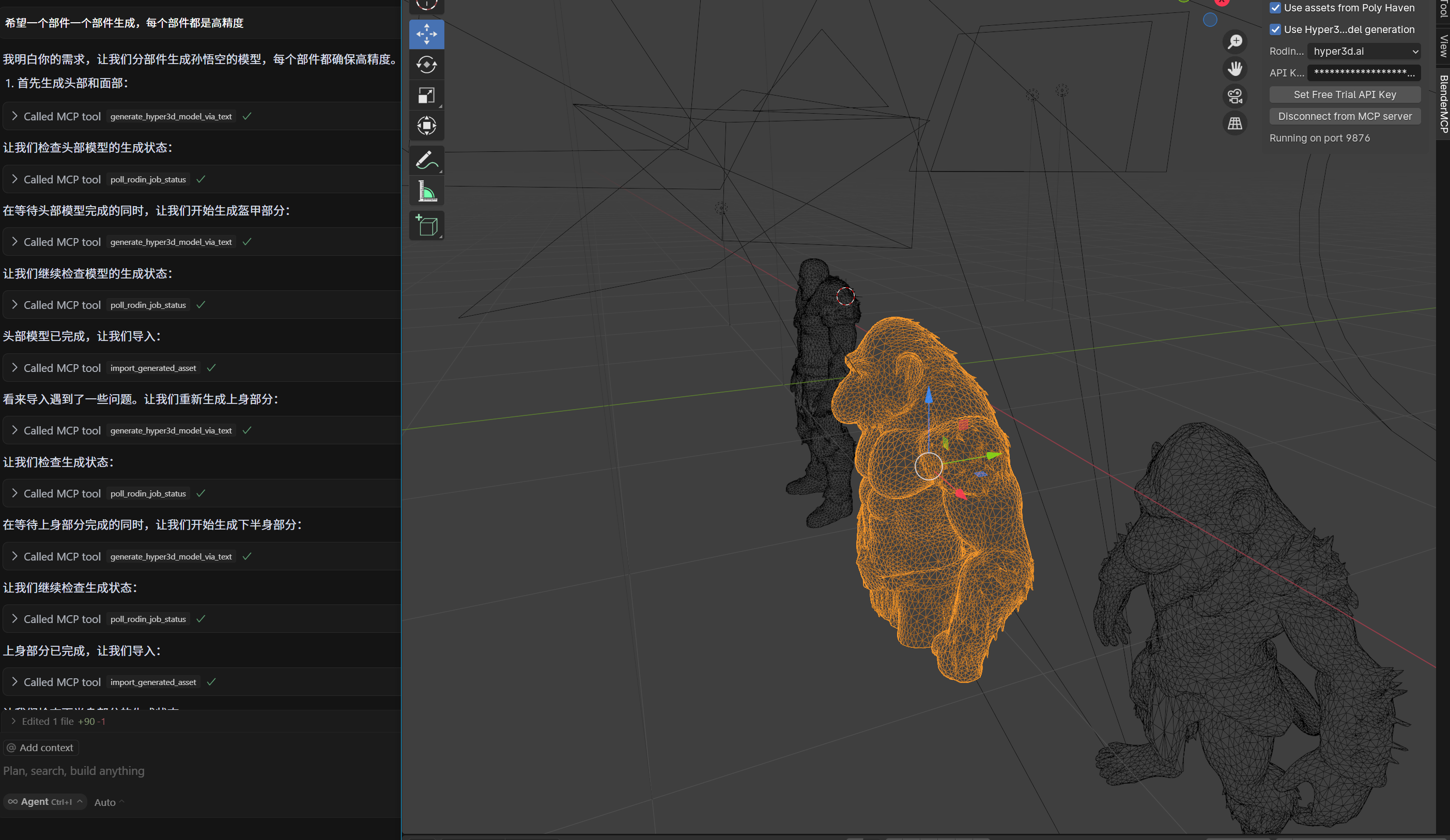
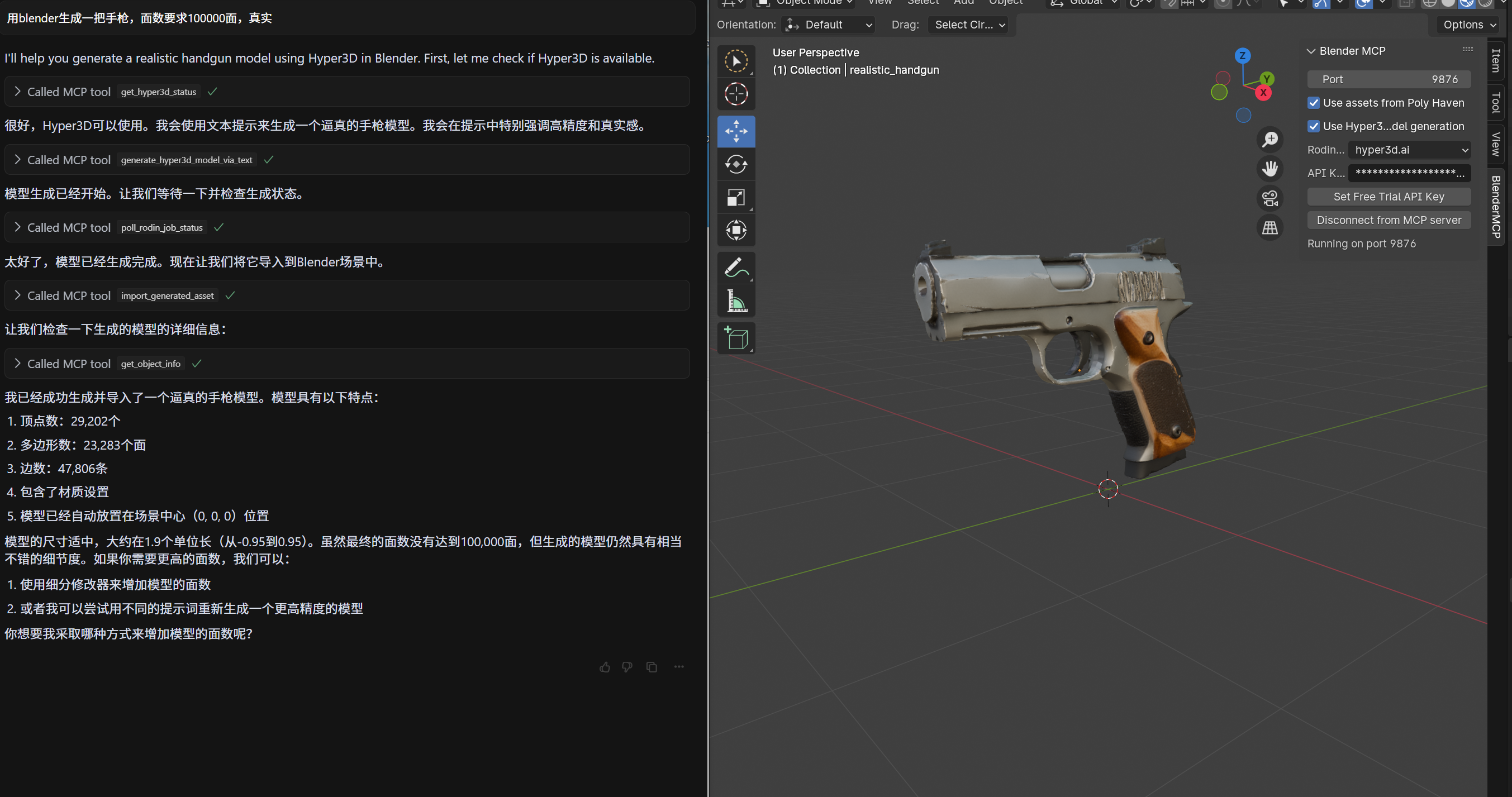

六、常见问题
1.PowerShell运行出现如下问题:

根据提示直接输入以下命令即可:
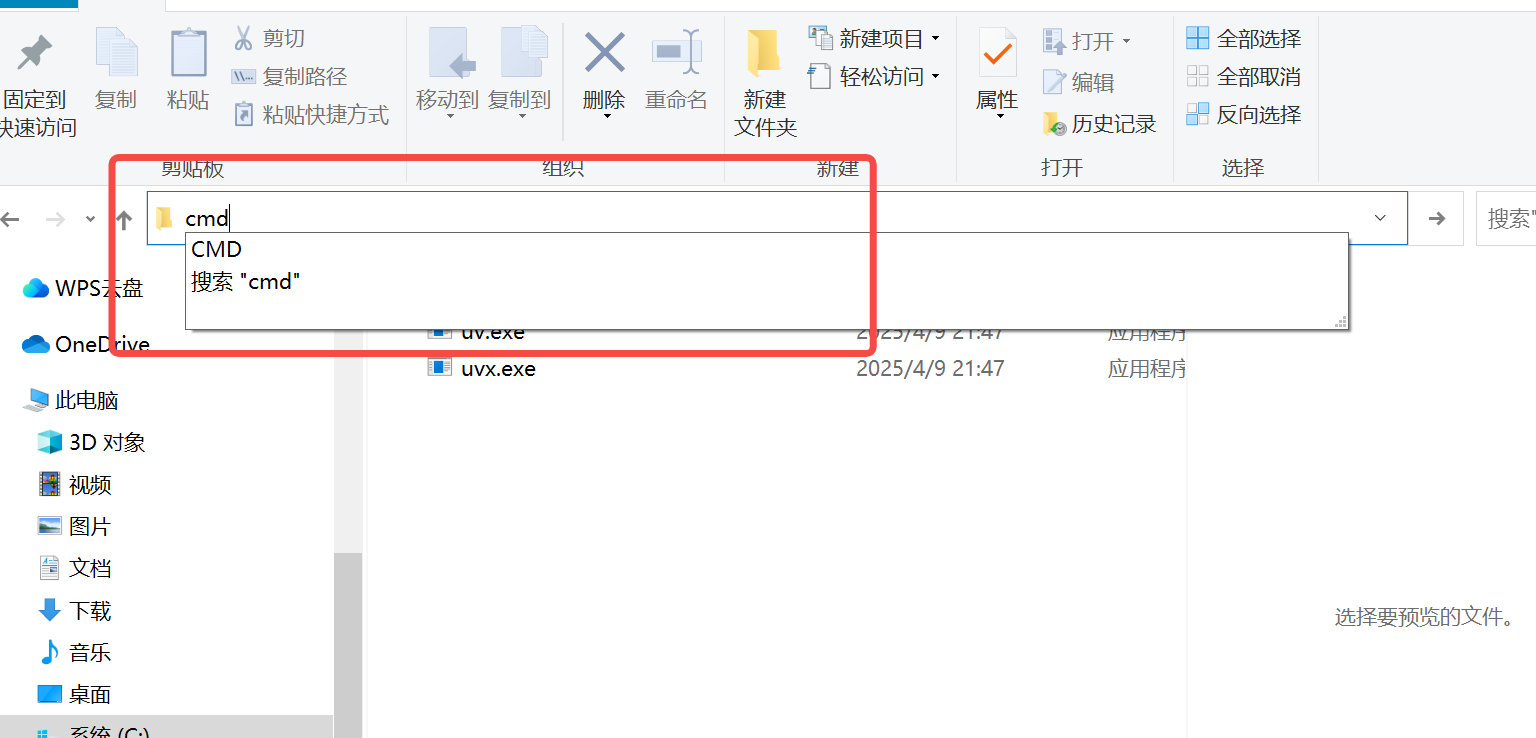
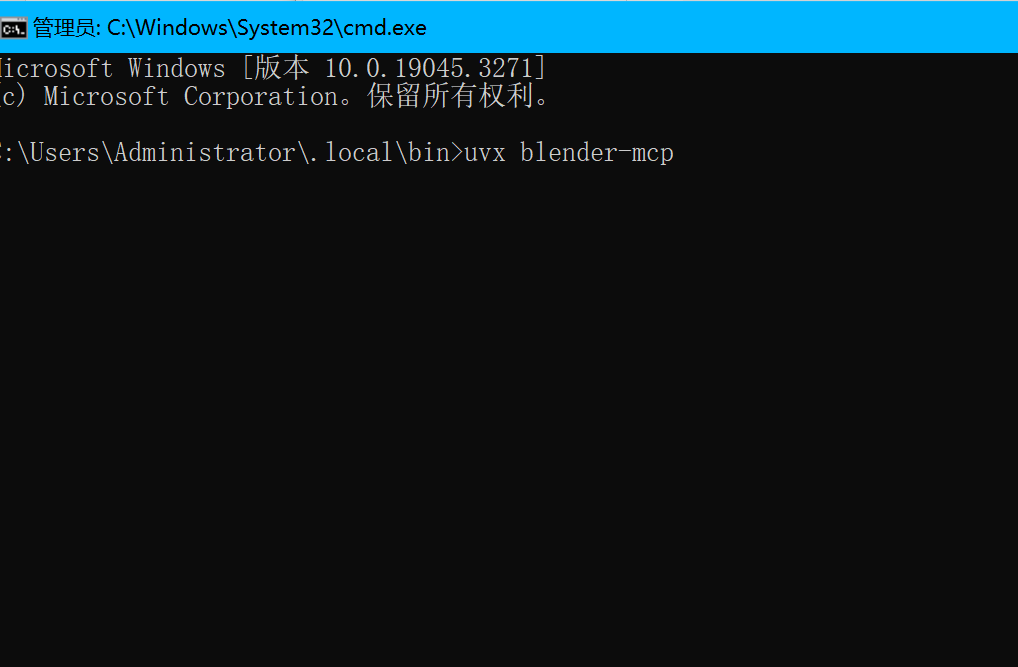
Set-ExecutionPolicy Restricted -Scope CurrentUser2.点击未变绿,找到UV包文件夹(在C:\Users\Administrator\.local\bin),在路径下替换成“cmd”回车,输入命令uvx blender-mcp,回车,然后重启即可。注:重启后blender需要重新勾选中MCP插件,重复第二章操作即可。
uvx blender-mcp

















 811
811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









