






目录
一、正则表达式
1.内容列表
-
.:匹配任何单个字符。 -
?:上一项是可选的,最多匹配一次。 -
*:前一项将被匹配零次或多次。 -
+:前一项将被匹配一次或多次。 -
{N}:上一项完全匹配N次。 -
{N,}:前一项匹配N次或多次。 -
{N,M}:前一项至少匹配N次,但不超过M次。 -
--:表示范围,如果它不是列表中的第一个或最后一个,也不是列表中某个范围的终点。 -
^:匹配行首的空字符串;也代表不在列表范围内的字符。 -
$:匹配行尾的空字符串。 -
\b:匹配单词边缘的空字符串。 -
\B:匹配空字符串,前提是它不在单词的边缘。 -
\<:匹配单词开头的空字符串。 -
\>:匹配单词末尾的空字符串。
| \d | 匹配一个数字字符。等价于[0-9]。 |
|---|---|
| \D | 匹配一个非数字字符。 |
| \f | 匹配一个换页符。 |
| \n | 匹配一个换行符。 |
| \r | 匹配一个回车符。 |
| \s | 匹配任何不可见字符,包括空格、制表符、换页符等等。 |
| \S | 匹配任何可见字符。 |
| \t | 匹配一个制表符。 |
| \v | 匹配一个垂直制表符。 |
| \w | 匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”, |
| \W | 匹配任何非单词字符。 |
2.简单实例
| 正则表达式 | 描述 |
|---|---|
/\b([a-z]+) \1\b/gi | 一个单词连续出现的位置。 |
/(\w+):\/\/([^/:]+)(:\d*)?([^# ]*)/ | 匹配一个 URL 解析为协议、域、端口及相对路径。 |
/^(?:Chapter|Section) [1-9][0-9]{0,1}$/ | 定位章节的位置。 |
/[-a-z]/ | a 至 z 共 26个 字母再加一个 - 号。 |
/ter\b/ | 可匹配 chapter,而不能匹配 terminal。 |
/\Bapt/ | 可匹配 chapter,而不能匹配 aptitude。 |
/Windows(?=95 |98 |NT )/ | 可匹配 Windows95 或 Windows98 或 WindowsNT,当找到一个匹配后,从 Windows 后面开始进行下一次的检索匹配。 |
/^\s*$/ | 匹配空行。 |
/\d{2}-\d{5}/ | 验证由两位数字、一个连字符再加 5 位数字组成的 ID 号。 |
<[a-zA-Z]+.*?>([\s\S]*?)</[a-zA-Z]*?> | 匹配 HTML 标记。 |
| 正则表达式 | 描述 |
|---|---|
hello | 匹配 {hello} |
gray|grey | 匹配 {gray, grey} |
gr(a|e)y | 匹配 {gray, grey} |
gr[ae]y | 匹配 {gray, grey} |
b[aeiou]bble | 匹配 {babble, bebble, bibble, bobble, bubble} |
[b-chm-pP]at|ot | 匹配 {bat, cat, hat, mat, nat, oat, pat, Pat, ot} |
colou?r | 匹配 {color, colour} |
rege(x(es)?|xps?) | 匹配 {regex, regexes, regexp, regexps} |
go*gle | 匹配 {ggle, gogle, google, gooogle, goooogle, ...} |
go+gle | 匹配 {gogle, google, gooogle, goooogle, ...} |
g(oog)+le | 匹配 {google, googoogle, googoogoogle, googoogoogoogle, ...} |
z{3} | 匹配 {zzz} |
z{3,6} | 匹配 {zzz, zzzz, zzzzz, zzzzzz} |
z{3,} | 匹配 {zzz, zzzz, zzzzz, ...} |
[Bb]rainf\*\*k | 匹配 {Brainf**k, brainf**k} |
\d | 匹配 {0,1,2,3,4,5,6,7,8,9} |
1\d{10} | 匹配 11 个数字,以 1 开头 |
[2-9]|[12]\d|3[0-6] | 匹配 2 到 36 范围内的整数 |
Hello\nworld | 匹配 Hello 后跟换行符,后跟 world |
\d+(\.\d\d)? | 包含一个正整数或包含两位小数位的浮点数。 |
[^*@#] | 排除 *、@ 、# 三个特色符号 |
//[^\r\n]*[\r\n] | 匹配 // 开头的注释 |
^dog | 匹配以 "dog" 开始 |
dog$ | 匹配以 "dog" 结尾 |
^dog$ | is exactly "dog" |
二、id和class的区别
1.id
id属性是元素在网页内的唯一标识符。比如,网页可能包含多个<p>标签,id属性可以指定每个<p>标签的唯一标识符。
<p id="p1"></p> <p id="p2"></p> <p id="p3"></p>
上面代码中,三个<p>标签具有不同的id属性,因此可以区分。
id属性的值必须是全局唯一的,同一个页面不能有两个相同的id属性。另外,id属性的值不得包含空格。
id属性的值还可以在最前面加上#,放到 URL 中作为锚点,定位到该元素在网页内部的位置。比如,用户访问网址https://foo.com/index.html#bar的时候,浏览器会自动将页面滚动到bar的位置,让用户第一眼就看到这部分内容。
2.class
class属性用来对网页元素进行分类。如果不同元素的class`属性值相同,就表示它们是一类的。
<p class="para"></p> <p></p> <p class="para"></p>
上面代码中,第一个<p>和第三个<p>是一类,因为它们的class属性相同。
元素可以同时具有多个 class,它们之间使用空格分隔。
<p class="p1 p2 p3"></p>
上面的p元素同时具有p1、p2、p3三个 class。
三、DNS原理
1.几种解析方式
(1) `A`:地址记录(Address),返回域名指向的IP地址。
(2) `NS`:域名服务器记录(Name Server),返回保存下一级域名信息的服务器地址。该记录只能设置为域名,不能设置为IP地址。
(3)`MX`:邮件记录(Mail eXchange),返回接收电子邮件的服务器地址。
(4)`CNAME`:规范名称记录(Canonical Name),返回另一个域名,即当前查询的域名是另一个域名的跳转。
(5)`PTR`:逆向查询记录(Pointer Record),只用于从IP地址查询域名。

负载均衡:

2.工作原理
(1)解析规则

①递归和迭代
输入百度域名,首先查本地缓存,若缓存未查到,再去查hosts,然后网关(路由器上内置dns服务器,13台根域的地址),然后根域服务器顶级域→.com→baidu.com→解析服务器(解析IP与域名的映射关系)→返回路由器→返回缓存,知晓网站IP后,建立稳定可靠连接(https,keep alive,使用TCP/IP协议),与百度三次握手建立长连接,浏览器关闭,keep alive终止,三次握手后然后进行证书匹配(对称加密和非对称加密,是否安全),最后发送http request请求,200OK请求成功。
com:一级域名,表示这是一个企业域名。当然还有net(网络提供商),org(非盈利组织)等
baidu:二级域名,指公司名。
www:习惯用法。

②优先查看hosts的映射关系

四、网页组成
eg:https://www.example.com:80/path/to/myfile.html?key1=value1&key2=value2#anchor
端口号:
ftp:20、21
telnet:23
ssh:22
smtp:25 邮件协议
DNS:53
DHCP:67、68
http:80
pop3:110 邮件协议
https:443
ladp:389 域控制器上的端口
mysql:3306
sqlserver:1433 c#
oracle:1521
windows远程连接:3389
redis(nosql数据库)6379
1.协议
协议(scheme)是浏览器请求服务器资源的方法,上例是https://的部分,表示使用 HTTPS 协议。
2.主机
主机(host)是资源所在的网站名或服务器的名字,又称为域名。上例的主机是www.example.com。
request和response
response返回时的状态码
200:访问成功
404:not found
403:forbidden 权限不够
401:unauthorized 未授权,必须有账号密码才可以登录
500:服务器错误(代码、服务器配置错误)
3开头的重定向:登陆页面最常出现
301:状态码301和状态码302相似,不同的是状态码301往往代表的是永久性的重定向302:代表临时跳转。
303:see other,客户端应当采用get方法获取资源
304:服务器通过返回状态码304可以告诉客户端请求资源成功
307:临时重定向
308:永久重定向
3.端口
同一个域名下面可能同时包含多个网站,它们之间通过端口(port)区分。“端口”就是一个整数,可以简单理解成,访问者告诉服务器,想要访问哪一个网站。HTTP 协议的默认端口是80,如果省略了这个参数,服务器就会返回80端口的网站。
端口紧跟在域名后面,两者之间使用冒号分隔,比如www.example.com:80。
4.路径
路径(path)是资源在网站的位置。比如,/path/index.html这个路径,指向网站的/path子目录下面的网页文件index.html。
5.查询参数
查询参数(parameter)是提供给服务器的额外信息。参数的位置是在路径后面,两者之间使用?分隔,上例是?key1=value1&key2=value2。
6.锚点
锚点(anchor)是网页内部的定位点,使用#加上锚点名称,放在网址的最后,比如#anchor。浏览器加载页面以后,会自动滚动到锚点所在的位置。
DHCP工作原理
五、五种编码
1.urlcode
(1)编码规则
将需要转码的字符转为16进制,然后从右到左取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式。
eg:空格ASCII码是32,对应16进制是20,那么urlencode编码结果是:%20,中ASCII码是-10544,对应的16进制是D6D0,那么urlencode编码结果是:%D6%D0
(2)xss_location绕过实例

①代码含义
2:php代码关掉浏览器防御
3:三元运算符
4、5:replace函数对数组中东西进行替换,结果输出到img标签
②过滤
():防止执行函数
&:防止使用html实体编码
\u:unicode
<>:js标签
③绕过

a:对大小括号进行unicode编码,但是浏览器解码后才进入程序中,还是过滤掉了大小括号

b:对%进行编码
%:%25 (:%28 ):%29 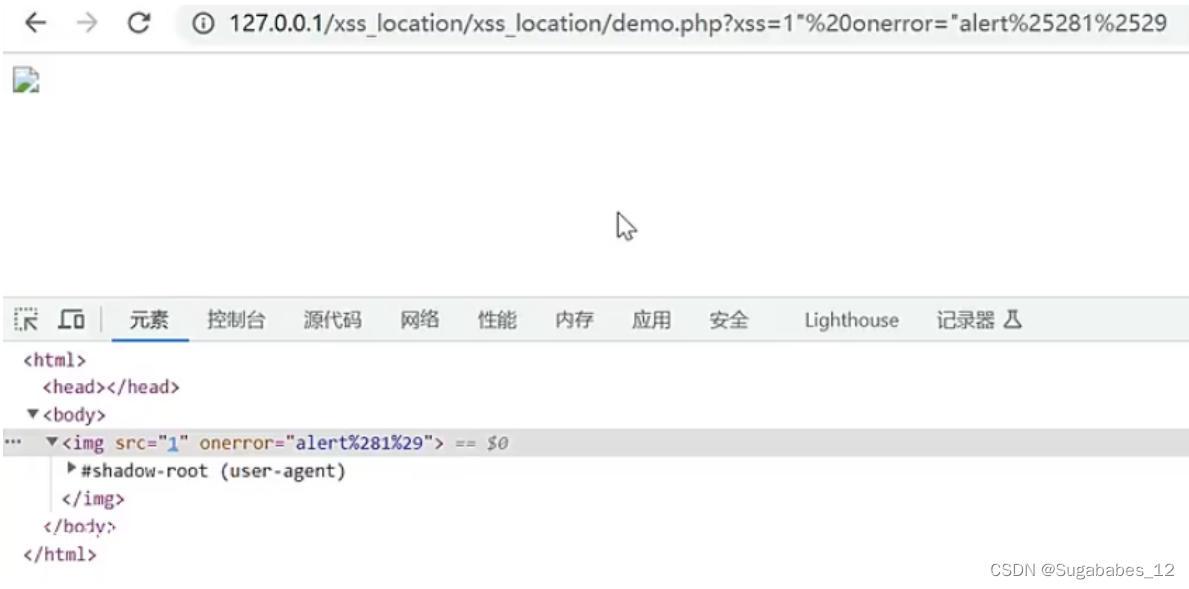
c:js中不允许编码符号
d:location函数可以将右边一串符号转换为变量,js中变量值可以编码,如下图,绕过并产生了弹窗

 2.unicode
2.unicode
3.ASCII

4.html实体编码
<p>hello</p>
<!-- 等同于 -->
十进制
<p>hello</p>
<!-- 等同于 -->
十六进制
<p>hello</p>
(1)html页面解析实体编码
①空格: ;


②< :<; >: >;

浏览器解析结果:

5.UTF-8
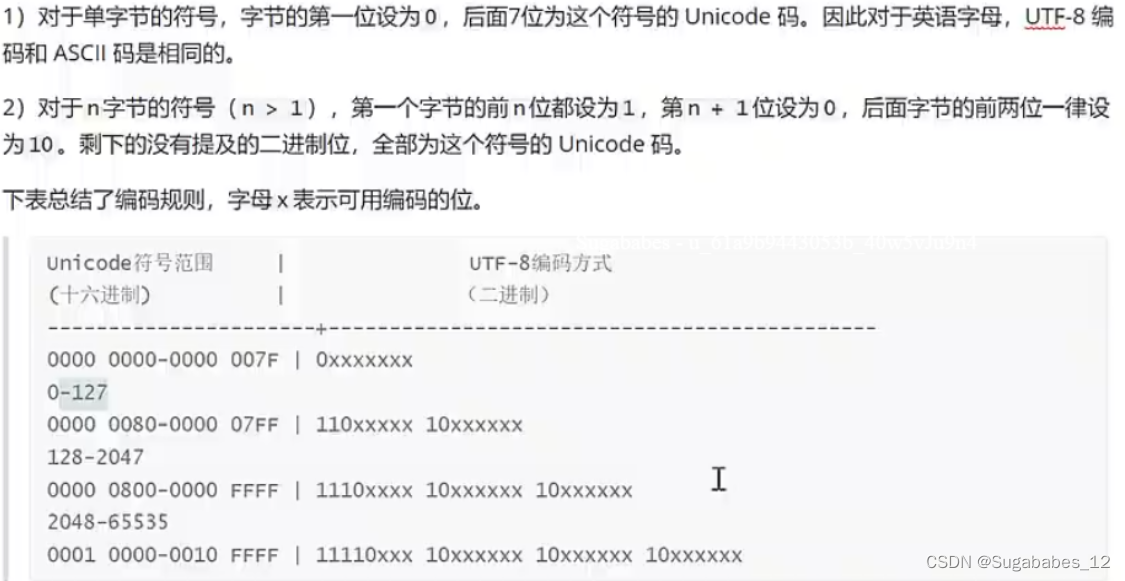
在 ASCII 码范围内的代码点,UTF-8 使用 1 个字节表示。
大于 ASCII 码范围的代码点,UTF-8 使用多个字节表示。UTF-8 使用第一个字节的前几位表示该 Unicode 字符的字节长度(第一个字节的开头 1 的数目就是该 Unicode 字符的字节长度),其余字节的前两位固定为 10,作为标记
如果第一个字节的前两位为 1,第三位为 0(110xxxxx),则表示 UTF-8 使用 2 个字节表示该 Unicode 字符;
如果第一个字节的前三位为 1,第四位为 0(1110xxxx),则表示 UTF-8 使用 3 个字节表示该 Unicode 字符;
依此类推;
如果第一个字节的前六位为 1,第七位为 0(1111110x),则表示 UTF-8 使用 6 个字节表示该 Unicode 字符;














 782
782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









