






 本文详细介绍了如何使用Python的requests和BeautifulSoup库进行网页爬取,包括获取链接、提取产品信息的过程,以及一个完整的爬虫函数示例。
本文详细介绍了如何使用Python的requests和BeautifulSoup库进行网页爬取,包括获取链接、提取产品信息的过程,以及一个完整的爬虫函数示例。
在这篇博客文章中,我将向你展示如何使用 Python 来爬取网页数据。我们将使用 Python 的 requests 和 BeautifulSoup 库来获取网页内容,并提取我们感兴趣的信息。
爬取的网页
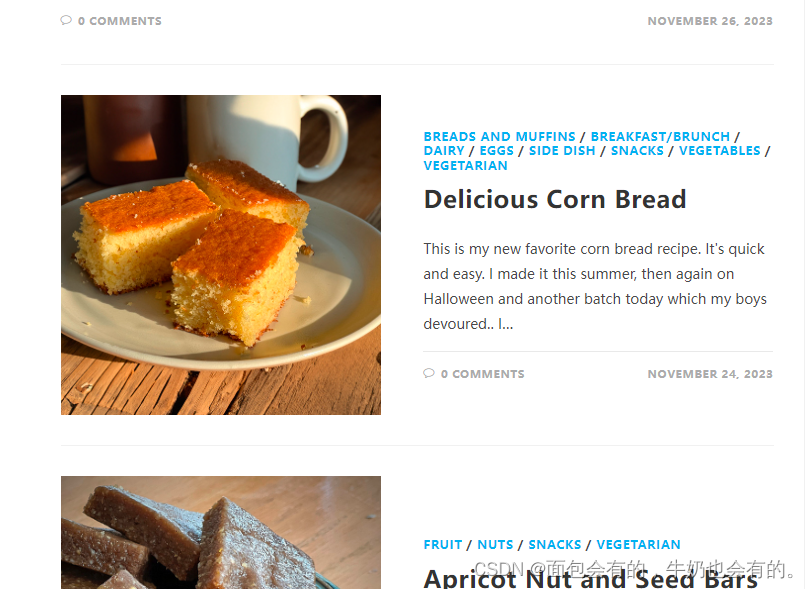

效果展示
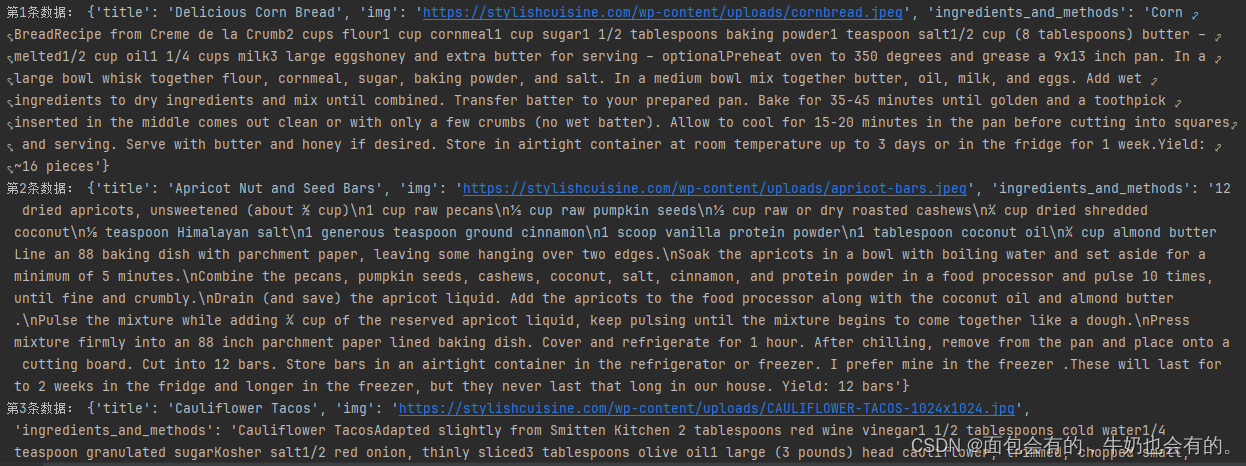
准备工作
首先,我们需要安装 requests 和 BeautifulSoup 库。你可以使用以下命令在你的 Python 环境中安装这两个库:
pip install requests beautifulsoup4
爬取链接
我们首先定义一个函数 crawled_links(url) 来爬取给定 URL 中的所有链接。我们使用 requests.get(url, headers=headers) 发送 HTTP 请求获取网页内容,然后使用 BeautifulSoup 解析网页内容。我们使用 find_all('a', class_='thumbnail-link') 找到所有 class 为 'thumbnail-link' 的 <a> 标签,并获取这些标签的 href 属性值。
def crawled_links(url):
data = [] # 存储爬取到的链接列表
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
try:
response = requests.get(url, headers=headers) # 发送请求获取网页内容
response.raise_for_status() # 确保请求成功,如果出错则抛出异常
except requests.exceptions.RequestException as e:
print(f"访问URL时发生错误: {e}") # 打印错误信息
# 处理错误或退出脚本
soup = BeautifulSoup(response.text, 'html.parser') # 解析网页内容
products = soup.find_all('a', class_='thumbnail-link') # 找到所有class为'thumbnail-link'的<a>标签
for product in products:
href_value = product.get('href') # 获取<a>标签的href属性值
# 添加到列表中
data.append(href_value)
return data # 返回爬取到的链接列表
提取产品信息
然后,我们定义一个函数 menu(url) 来从给定的 URL 中提取产品信息。我们首先获取产品的标题和图片链接,然后尝试从不同的地方获取产品的制作方法。我们处理了多种可能的情况,包括存在 blockquote 标签、p[style*="padding"] 标签等,并且正确地检查了 find_all() 或 select() 返回的列表是否为空。
def menu(url):
data = [] # 创建一个空列表来存储数据
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'} # 设置请求头
try:
response = requests.get(url, headers=headers) # 发送GET请求获取网页内容
response.raise_for_status() # 检查请求是否成功
except requests.exceptions.RequestException as e:
print(f"访问URL时发生错误: {e}") # 请求失败时打印错误信息
# 处理错误或退出脚本
soup = BeautifulSoup(response.text, 'html.parser') # 用BeautifulSoup解析网页内容
products = soup.find_all('div', class_='entry-content clr') # 找到所有指定类名的div标签
# 标题
first_em = soup.find_all('h2', class_='single-post-title entry-title') # 找到所有指定类名的h2标签
title = first_em[0].get_text() # 获取第一个h2标签的文本内容
# 图片链接
img_element = products[0].select_one('img[fetchpriority="high"]') # 选择第一个指定属性的img标签
img = img_element.get('src') # 获取img标签的src属性值
# 食材及做法
# 省略其他代码...
# 组成一个字典
product_dict = {
'title': title, # 将标题赋值给字典的title键
'img': img, # 将图片链接赋值给字典的img键
'ingredients_and_methods': res, # 将食材及做法赋值给字典的ingredients_and_methods键
}
return product_dict # 返回字典产品
组合所有部分
最后,我们定义一个函数 get_data() 来组合以上所有部分。我们首先获取所有页面的 URL,然后对每个页面爬取所有产品的 URL,最后对每个产品的 URL 提取产品信息,并将所有产品信息添加到一个列表中。
def get_data():
# 获取链接
url = link()
# 存储数据的列表
data = []
# 遍历链接列表
for i in url:
# 获取爬取到的链接
res = crawled_links(i)
# 遍历爬取到的链接列表
for j in res:
# 调用menu函数处理链接
res = menu(j)
# 将处理后的链接添加到数据列表中
data.append(res)
# 返回数据列表
return data
现在,你可以运行 get_data() 函数来爬取所有产品的信息:
if __name__ == '__main__':
res = get_data()
print(res)
这就是我们的 Python 网络爬虫。虽然这只是一个基础的爬虫,但它可以作为更复杂爬虫的基础。你可以根据你的需要修改这个爬虫,例如添加更多的错误处理代码,或者使用数据库来存储爬取的数据。
希望这篇文章能帮助你理解 Python 网络爬虫的基本原理和实现方法。如果你有任何问题或建议,欢迎留言讨论。
完整代码如下
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
def crawled_links(url):
data = [] # 存储爬取到的链接列表
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
try:
response = requests.get(url, headers=headers) # 发送请求获取网页内容
response.raise_for_status() # 确保请求成功,如果出错则抛出异常
except requests.exceptions.RequestException as e:
print(f"访问URL时发生错误: {e}") # 打印错误信息
# 处理错误或退出脚本
soup = BeautifulSoup(response.text, 'html.parser') # 解析网页内容
products = soup.find_all('a', class_='thumbnail-link') # 找到所有class为'thumbnail-link'的<a>标签
for product in products:
href_value = product.get('href') # 获取<a>标签的href属性值
# 添加到列表中
data.append(href_value)
return data # 返回爬取到的链接列表
def menu(url):
data = [] # 创建一个空列表来存储数据
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'} # 设置请求头
try:
response = requests.get(url, headers=headers) # 发送GET请求获取网页内容
response.raise_for_status() # 检查请求是否成功
except requests.exceptions.RequestException as e:
print(f"访问URL时发生错误: {e}") # 请求失败时打印错误信息
# 处理错误或退出脚本
soup = BeautifulSoup(response.text, 'html.parser') # 用BeautifulSoup解析网页内容
products = soup.find_all('div', class_='entry-content clr') # 找到所有指定类名的div标签
# 标题
first_em = soup.find_all('h2', class_='single-post-title entry-title') # 找到所有指定类名的h2标签
title = first_em[0].get_text() # 获取第一个h2标签的文本内容
# 图片链接
img_element = products[0].select_one('img[fetchpriority="high"]') # 选择第一个指定属性的img标签
img = img_element.get('src') # 获取img标签的src属性值
# 食材及做法
try:
fourth_p_element = soup.find_all('p', class_='has-background') # 找到所有指定类名的p标签
text_content = fourth_p_element[0].get_text() # 获取第一个p标签的文本内容
string = text_content.replace('\xa0', ' ') # 将\xa0替换为空格
res = string.replace("Ã\x97", "x") # 将"Ã\x97"替换为"×"
except:
if soup.find('blockquote'):
blockquote = soup.find('blockquote') # 找到第一个blockquote标签
p_tags_with_padding = soup.select('p[style*="padding"]')
p_tags_in_blockquote = blockquote.find_all('p')[:-1]
# 提取文本内容
if len(p_tags_with_padding) > 0:
p_tags = soup.select('p[style*="padding"]') # 选择所有指定属性的p标签
# 提取文本内容
res_str = [p.get_text() for p in p_tags]
strin = ' '.join(res_str)
res = strin.replace("\xa0", " ") # 将\xa0替换为空格
elif len(p_tags_in_blockquote) > 0:
# 找到所有的 <p> 标签,排除最后一个
p_tags = blockquote.find_all('p')[:-1]
# 提取文本内容
texts = [p.get_text() for p in p_tags]
strin = ' '.join(texts)
res = strin.replace("\xa0", " ") # 将\xa0替换为空格
else:
p_tags = [p for product in products for p in product.find_all('p')[:-1]]
# 提取文本内容
res_str = [p.get_text() for p in p_tags]
string = ' '.join(res_str)
stri = string.encode('latin-1', errors='ignore').decode('utf-8', errors='ignore')
strin = stri.replace("\n", " ") # 将换行符替换为空格
res = strin.replace("\xa0", " ") # 将\xa0替换为空格
else:
p_tags = products[-1].find_all('p')[-3:]
# 提取文本内容
res_str = [p.get_text() for p in p_tags]
string = ' '.join(res_str)
strin = string.replace("\xa0", " ") # 将\xa0替换为空格
res = strin.encode('latin-1', errors='ignore').decode('utf-8', errors='ignore') # 将字符串转为小写
# 组成一个字典
product_dict = {
'title': title, # 将标题赋值给字典的title键
'img': img, # 将图片链接赋值给字典的img键
'ingredients_and_methods': res, # 将食材及做法赋值给字典的ingredients_and_methods键
}
return product_dict # 返回字典产品
def link():
data = []
# 菜单的页数
number_of_pages = 1
for i in range(1, number_of_pages + 1):
url = f'https://stylishcuisine.com/page/{i}/'
# 添加到列表中
data.append(url)
return data
def get_data():
y = 0
# 获取链接
url = link()
# 存储数据的列表
data = []
# 遍历链接列表
for i in url:
# 获取爬取到的链接
res = crawled_links(i)
# 遍历爬取到的链接列表
for j in res:
# 调用menu函数处理链接
res = menu(j)
# 将处理后的链接添加到数据列表中
data.append(res)
y += 1
print(f'第{y}条数据:', res)
# 返回数据列表
return data
if __name__ == '__main__':
res = get_data()
print(res)


















 235
235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









