






参加DataWhale吃瓜教程-Part2 打卡笔记
西瓜书 第三章 线性模型
南瓜书 第三章 决策树
前言
根据前面的学习,我们系统的了解了一些机器学期的背景,接下来就需要更加深入的了解机器学习。
而接下来的部分我会整理出西瓜书和南瓜书的线性模型,决策树的学习笔记
一、线性模型
其实我们从初中开始学习解方程组开始,就已经开始接触一元一次方程:y=kx+b,而机器学习中的线性模型,线性回归也是以这个方程为基础,同时以矩阵为进阶。
a. 一元线性回归:
根据西瓜书上的内容:

如何确定w和b呢?就是衡量f(x)与y之间的区别。这也叫做均方误差。
根据几何定义,均方误差便是试图找到一条直线,使所有的样本到直线上的欧式距离之和最小。
有一般线性回归,根据我们微积分的知识,还有对数线性回归:
 来源:西瓜书
来源:西瓜书
上面的这幅图便是对数线性回归示意图。
接下来,因为在统计学中,我们有接触过回归模型便是连续性的,但是如果我们需要做分类任务怎么办?分类模型是离散型的。
因此我们就不得不提单位阶跃函数。

根据书本上的图,我们可以看出来,右边红色公式便是单位阶跃函数,它并不是连续性的,有点像数学中求导(求面积)。
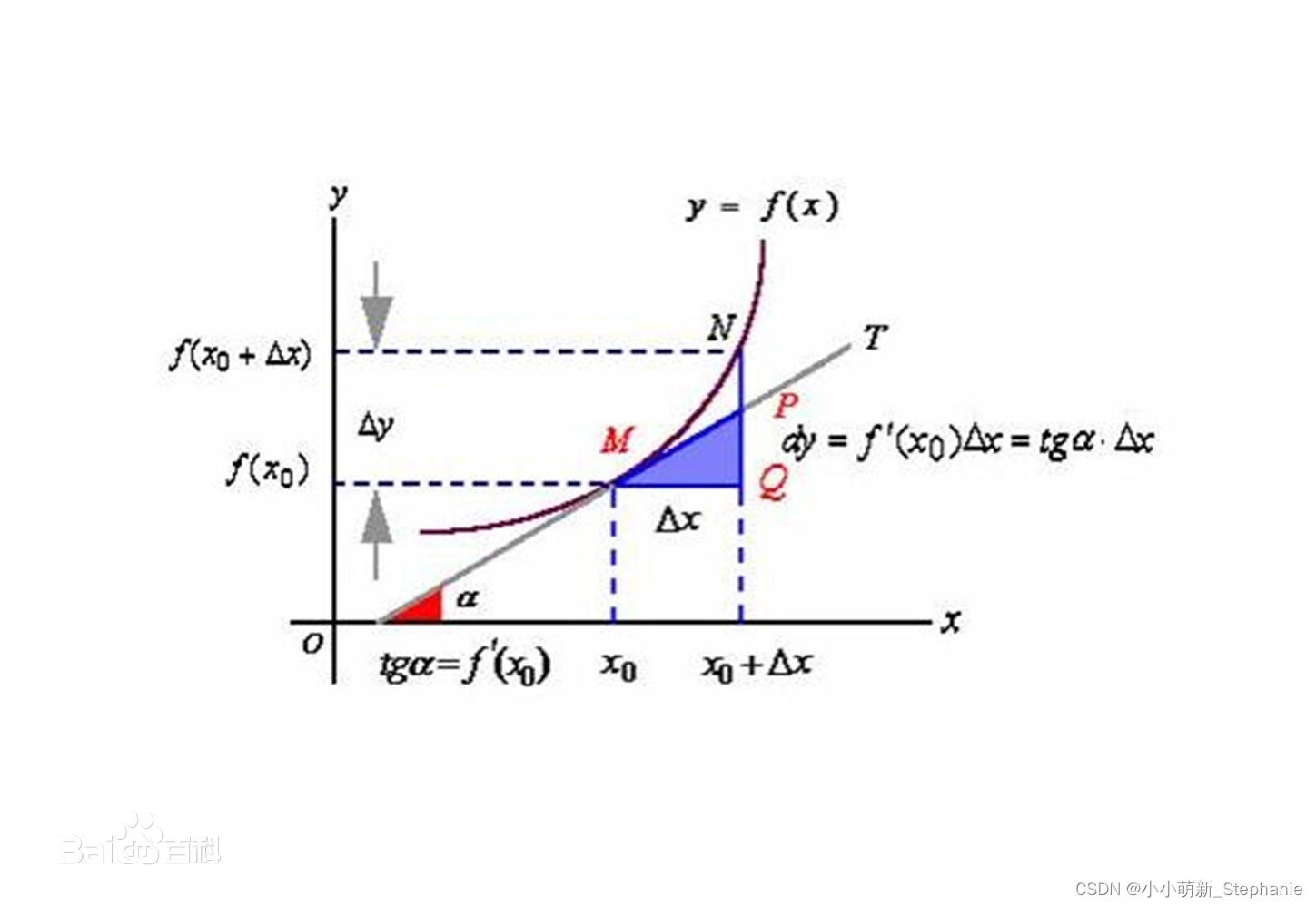
而线性回归模型的预测是为了能够使预测结果去逼近真实标记的对数几率。它有以下几点好处:
避免了假设分布不准确所带来的问题;它不是仅预测出“类别”,而是可得到近似概率预测,这对许多需利用概率辅助决策的任务很有用;此外,对率函数是任意阶可导的凸函数,有很好的数学性质,现有的许多数值优化算法都可直接用于求取最优解。
二、多分类学习
1.拆分策略
“一对一”(One vs. One,简称OvO )、 “一对其余“(One vs. Rest,简称 OvR)和 "多 对 多 " (Many vs. Many ,简称 MvM).
书中给到了一张图:
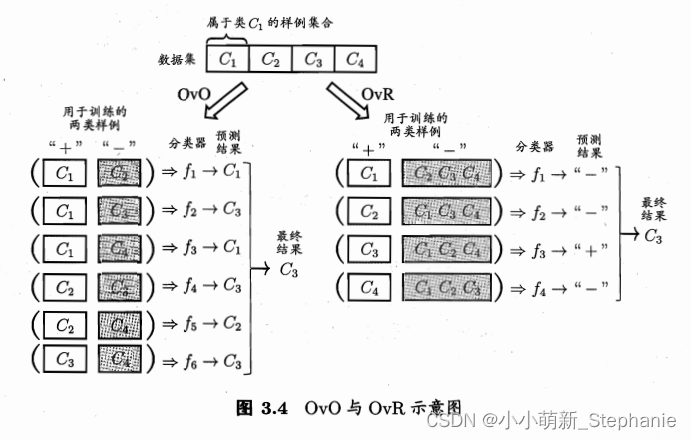
根据上面的图片,可以明白预测结果是根据分类器调整的,最终结果取决于出现最多的预测结果。
2.类别不平衡问题
类别不平衡(class-imbalance)就是指分类任务中不同类别的训练样例数目差别很大的情况.不失一般性,本节假定正类样例较少,反类样例较多。在现实的分类学习任务中,我们经常会遇到类别不平衡,例如在通过拆分法解决多分类问题时,即使原始问题中不同类别的训练样例数目相当,在使用OvR、MvM策略后产生的二分类任务仍可能出现类别不平衡现象,因此有必要了解类别不平衡性处理的基本方法。
三、决策树(预测学模型)
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。如下图所示[^1]:
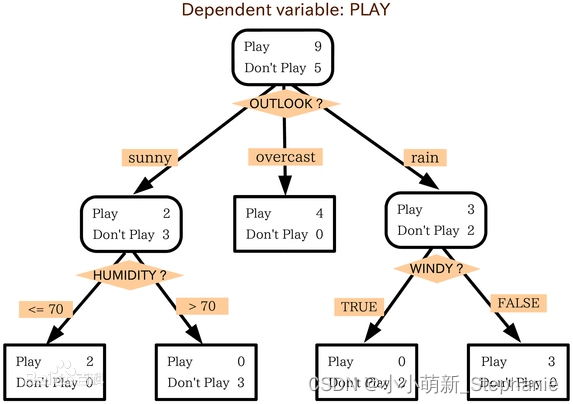
可以看的出来,这有点像家庭族谱,从祖先到现代家人。而最近的也就是最下面这一行,拥有它所在的直系行的所有特征。
一个决策树包含三种类型的节点:
- 决策节点:通常用矩形框来表示
- 机会节点:通常用圆圈来表示
- 终结点:通常用三角形来表示
但通过阅读资料,发现其实决策树也是存在缺点的:
- 对连续性的字段比较难预测。
- 对有时间顺序的数据,需要很多预处理的工作。
- 当类别太多时,错误可能就会增加的比较快。
- 一般的算法分类的时候,只是根据一个字段来分类。
总结
以上就是这一段时间学习的笔记,内容比较多,然后也是越来越深入机器学习了,觉得把只要数学好,相信机器学习是能够学好的!!
注释:
[^1]:https://baike.baidu.com/item/%E5%86%B3%E7%AD%96%E6%A0%91/10377049?fr=ge_ala















 1087
1087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









