






系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第四章 决策树
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
提示:这里可以添加本文要记录的大概内容:
提示:以下是本篇文章正文内容,下面案例可供参考
一、决策树是什么?
二、算法解析
1.信息增益
“信息熵”(information entropy)是度量样本集合纯度最常用的一种指标。

Ent(D)的值越小,则D的纯度越高。假定离散属性a有V个可能的取值{,
,...,
},若使用a来对样本集D进行划分,则会产生V各分支节点,其中第v个分支节点包含了D中所有在属性a上取值为
的样本,记为
。我们可根据式(4.1)计算出
的信息熵,再考虑到不同的分支结点所包含的样本数不同,给分支结点赋予权重
,也就是样本数越多的分支结点的影响越大,于是可计算出用属性a对样本集D进行划分所获得的“信息增益”(information gain)。
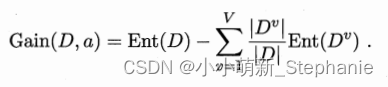
一般而言,信息增益越大,则意味着使用属性a来划分所获得的“纯度提升”越大。因此,我们可用信息增益来进行决策树的划分属性选择。其中,我们又要提到一个“条件熵”,“条件熵”表示的是在已知一个随机变量的条件下,另一个随机变量的不确定性。互信息定义信息熵和条件熵的差,他表示的是已知一个随机变量的信息后使得另一个随机变量的不确定性减小的程度。
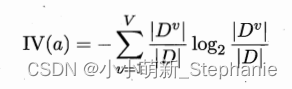
2.连续与缺失值
连续与缺失值的预处理均属于特征工程的范畴。
有些分类器只能使用离散属性,当遇到连续属性时,则需要特殊处理。若先使用某个离散化算法对连续属性离散化后再调用决策树算法。
3. 多变量决策树

斜纹阴影部分表示已确定标记为坏瓜的样本,点状阴影部分表示已确定标记为好瓜的样本,空白部分表示需要进一步划分的样本。在第一次划分的基础上再进行一次划分,满足此条件的样本直接被标记为坏瓜,而不满足词条此的样本还需要进一步划分。在第二次划分的基础上,不满足此条件的样本直接标记为好瓜,而满足此条件的样本还需进一步划分。在第三次划分的基础上继续划分,满足此条件的样本直接标记为好瓜,而不满足此条件的样本直接标记为坏瓜。















 7216
7216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









