






AI夏令营技术学习和分析
概要
随机森林(RandomForestRetrsor)
是一种集成学习的方法。通常用于回归和分类。
- 数据采样:从训练集中随机有放回地抽取样本,形成多个子样本集,每个子样本集用于训练一个决策树。
- 特征选择:对于每个决策树的节点,在进行分裂时,随机选择一部分特征来作为候选特征,而不是全部特征。这样可以增加树之间的差异性,提高集成的效果。
- 构建决策树:对于每个子样本集,使用选定的特征来构建一个决策树。决策树的生长过程中,采用一定的停止生长策略,如限制树的深度或叶节点上样本数量的最小值。
- 集成预测:当需要对新样本进行预测时,每个决策树会产生一个预测结果。对于回归问题,最常用的集成策略是取所有决策树的预测结果的平均值。
随机森林具有以下优点:
可以处理大规模数据集,并具有很好的泛化能力,不易过拟合。
对于高维特征数据集表现较好,并且在训练过程中能够评估特征的重要性。
由于有多个决策树进行平均或投票,因此对于噪音数据具有一定的鲁棒性。
lightGBM的数学原理
XGBoost:梯度提升树
CatBoost:对离散特征数据进行了优化
LightGBM:通过梯度采样和直方图算法支持并优化
- XGBoost:在传统集成学习中,Boosting系列算法的基学习器往往是串行生成,Bagging系列算法(例如随机森林)往往是并行
- 传统集成学习是从基学习器本身入手从误差优化入手。
- 模型的误差=‘距离定义’+正则化因子
- Boosting为串行生成,第i轮的预测结果也就是在第i-1轮的基础上加上fi(x)
- 为什么叫梯度提升树?
- 怎样找最优解?
- XGBoosting是机器学习的一个里程碑?优化了梯度,提高了准确度,能自主处理数据缺失,削弱了我们预处理的困难。
- XGBoost的优点有哪些?二阶泰勒展开提高了精度,正则化方法更稳健,借鉴了随机森林,在其中引入了列抽样,降低过拟合,稀疏自主感知。
- XGBoost问题:精确贪心算法需要反复迭代反复遍历,计算量和内存消耗都很大。
代码优化
为了能够将结果得出的更加满意,首先我先选择的是更改参数,根据赛题中的代码:
pred_labels = list(train_dataset.columns[-34:]) # 需要预测的标签。
train_set, valid_set = train_test_split(train_dataset, test_size=0.2) # 拆分数据集。
lgb_params = {
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'mae',
'min_child_weight': 5,
'num_leaves': 2 ** 5,
'lambda_l2': 10,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 4,
'learning_rate': 0.05,
'seed': 2023,
'nthread' : 16,
'verbose' : -1,
}
no_info = lgb.callback.log_evaluation(period=-1) # 禁用训练日志输出。
learning_rate(学习率):学习率控制梯度下降过程中每次迭代的步长。较小的通常导致较慢的收敛,但可以提供更精确和准确的模型。
num_leaves(树叶数量):较大的值允许模型捕捉数据更复杂的模式,但也可能导致过拟合。较小的值有助于防止过拟合,但可能导致拟合不足。
min_child_weight(量小子项重量):子项所需的实力重量的最小总和。
lambda_12(正则化):关于权重的2正则化项。它有助于通过惩罚大重量来防止过度拟合。
特征分数和装袋分数:这些参数分别控制特征子采样和数据子采样
装袋频率:装袋频率。它确定在迭代过程中执行装袋的频率。
test_features = time_feature(test_dataset) # 处理测试集的时间特征,无需 pred_labels。
for pred_label in tqdm(pred_labels):
train_features = time_feature(train_set, pred_labels=pred_labels) # 处理训练集的时间特征。
train_labels = train_set[pred_label] # 训练集的标签数据。
train_data = lgb.Dataset(train_features, label=train_labels) # 将训练集转换为 LightGBM 可处理的类型。
valid_features = time_feature(valid_set, pred_labels=pred_labels) # 处理验证集的时间特征。
valid_labels = valid_set[pred_label] # 验证集的标签数据。
valid_data = lgb.Dataset(valid_features, label=valid_labels) # 将验证集转换为 LightGBM 可处理的类型。
# 训练模型,参数依次为:导入模型设定参数、导入训练集、设定模型迭代次数(200)、导入验证集、禁止输出日志
model = lgb.train(lgb_params, train_data, 200, valid_sets=valid_data, callbacks=[no_info])
valid_pred = model.predict(valid_features, num_iteration=model.best_iteration) # 选择效果最好的模型进行验证集预测。
test_pred = model.predict(test_features, num_iteration=model.best_iteration) # 选择效果最好的模型进行测试集预测。
MAE_score = mean_absolute_error(valid_pred, valid_labels) # 计算验证集预测数据与真实数据的 MAE。
MAE_scores[pred_label] = MAE_score # 将对应标签的 MAE 值 存入评分项中。
submit[pred_label] = test_pred # 将测试集预测数据存入最终提交数据中。
根据以上代码,中间可以调参的200,调成100,10000,之后发现模型的拟合是越来越差的。
这是不更改任何代码和参数跑出来的结果:
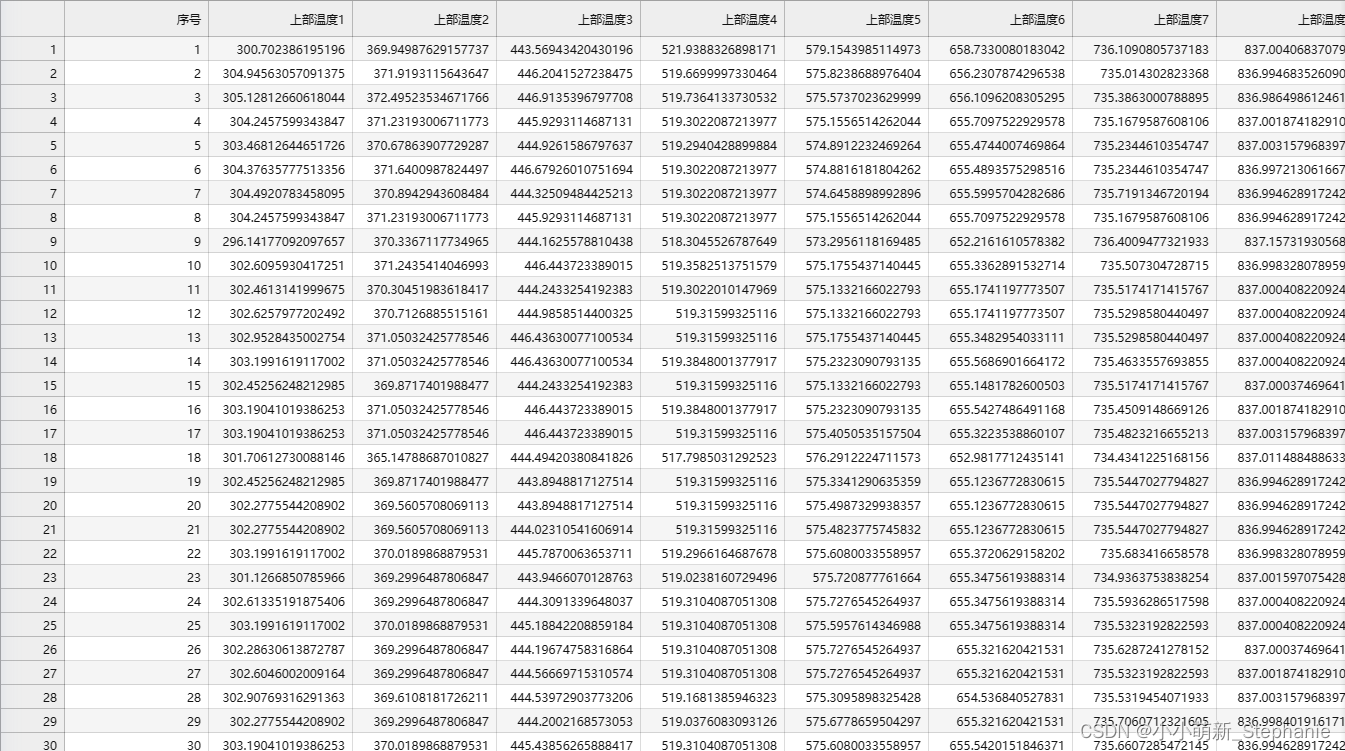
其实优化过后的跟初始的已经算是很接近的了。但是调参(100)之后的数据:
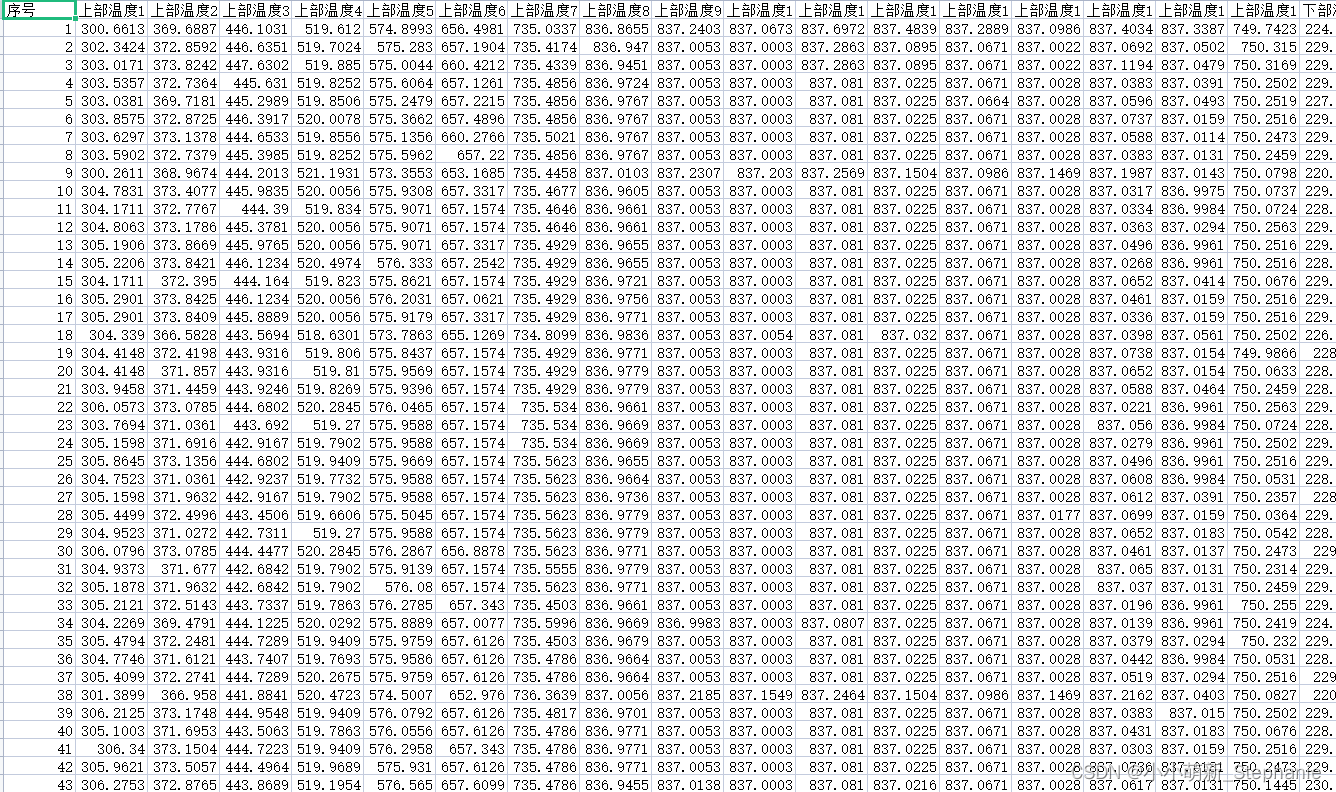
跟原本的数据差距其实是有的,因此我决定更改前面变量的参数值:
- 根据定义:learning_rate(学习率):学习率控制梯度下降过程中每次迭代的步长。较小的通常导致较慢的收敛,但可以提供更精确和准确的模型。为了能够获得更加精确的模型和数据,我决定更改learning_rate的参数之后(0.03)进行比较。
 之后发现数值的确是越来越接近测试集,但是当我把数值跳到0.02的时候,数值又远离了。因此我认为0.03是比较准确的数值。
之后发现数值的确是越来越接近测试集,但是当我把数值跳到0.02的时候,数值又远离了。因此我认为0.03是比较准确的数值。
结果
经过调整参数,以及减少和增加迭代次数,最终我获得的分数一直都在7分左右徘徊。因此我决定进一步的将模型进行优化,有以下几种方式:1.提取更多特征。2.进行结果后处理。3.尝试不同的模型。















 155
155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









