





行李危险品检测的最新进展:一份全面而系统的调查
原论文下载地址: Recent Advances in Baggage Threat Detection: A Comprehensive and Systematic Survey | ACM Computing Surveys
摘要 自20世纪70年代初以来,X射线成像系统已使安检人员能够识别行李和货物中的潜在危险品。然而,人工筛选危险品的过程非常耗时,而且容易出现人为错误。因此,研究人员利用计算机视觉技术的最新进展,通过机器学习模型、2D X射线和3D CT图像来帮助行李安检危险品识别。然而,这些方法的性能受到严重遮挡、类不平衡和有限的标记数据的严重影响,并且由于巧妙地隐藏和新型危险品的出现而使得检测进一步复杂化。因此,研究界必须设计出合适的方法,利用现有文献中的发现,朝着新的方向前进。为了实现这一目标,我们提供了一个结构化的调查,系统地了解行李危险品检测的最新进展。此外,我们还提出了对X射线成像系统和危险品识别领域面临的挑战的理解。我们将在基于2D和3D CT X射线的行李危险品安检的背景下对提出的方法进行分类,并对四种基准评估方法的性能进行比较分析。此外,我们还讨论了当前的挑战和未来研究的途径。
关键词 行李安检,计算机视觉,深度学习,2D X射线和3D CT安检
-
引言
在过去的几十年里,航空和其他运输部门越来越受欢迎,这给在安全检查站周围保持高度监视以降低恐怖活动的风险带来了挑战。全球化和电子商务进一步扩大了跨境货物流动和货运,增加了安全风险。为了帮助进行风险评估,在全球范围内实施安检措施,安检检查站引入了金属探测器、后向散射X射线成像系统、X射线(2D和3D CT)成像系统和毫米波(mmW)成像系统[218]。虽然金属探测器无法检测非金属危险品(包括爆炸物),但基于健康和隐私问题,后向散射成像受到了严厉的批评。非电离毫米波具有穿透衣物的能力,目前在非侵入性人体安检中是一种流行的选择,可以检测任何隐藏的威胁和违禁品[90]。
与此同时,基于X射线成像的行李检查已经成为确保交通枢纽和其他高风险地点公共安全的标准。行李检查是一种人工检查程序,X射线成像系统以“类似阴影”的图像捕捉行李内的物品,使操作人员能够确保行李中不包含任何隐藏的威胁。因此,筛选过程依赖于人类对X射线图像的推断,以识别带有重叠物体的杂乱扫描中有意隐藏的威胁项目。基于X射线的行李和货物检查已经在世界范围内发现了一些违禁物品,包括枪支和爆炸物,降低了相当大的风险。
根据最近的记录,2019年美国在乘客行李中检出4432支枪,其中87%是上膛的。尽管取得了成功,但需要指出的是,仔细检查违禁物品的扫描需要专业知识和警惕,因为在X射线扫描中,被遮挡物体的轮廓可能会相互重叠,因此很难熟练地区分威胁物品。在日常监控中,这些非法物品的出现频率较低,这使得运营商快速定位它们更具挑战性。简而言之,由于疲劳和分心,人工筛查繁琐且容易出错,更不用说在高峰时段保持工作状态的压力[137],同时它还需要在只有几秒钟的时间内识别一系列不同的违禁物品(从枪支和锋利的工具到超出预设限制的液体、气溶胶和凝胶(lag))[135]。研究[139]还表明,人工操作人员只能获得80%至90%的成功率。
为了简化行李安检过程,已经提出了几种自动安检系统。然而,与常规物体探测器在RGB图像上的优越结果不同,X射线探测器由于X射线和RGB图像之间固有的差异而受到性能限制。其他问题包括严重的类别不平衡、有限的数据集、严重的遮挡和很少的先验知识。另一个问题是危险品类别内的高度类间差异[150]。最近非法聚合物和碳组成的物品(3D打印枪支、陶瓷刀)的激增进一步阻碍了威胁检测的性能,因为这些在X射线扫描中几乎看不到。拆除和隐藏这些威胁可能会导致严重的后果。目前最先进的方法不足以强大到应对现实生活中怀有恶意的对手或领先于这些不断发展的威胁[161]。因此,在这项调查中,我们的目标是提供新的见解,以引导新方向,并通过提供该领域现有研究的广泛概述来鼓励新的研究人员。
1.1动机与贡献
尽管几个框架取得了令人满意的结果,但在检测高度闭塞的威胁时并不理想,这些威胁由于姿态变化、类不平衡和有限的训练数据而进一步复杂化。目前的大多数方法只处理领域内的特定问题。目前,利用基于形状和基于区域先验的框架[20,123]并不能解释威胁类别的高度结构多样性,导致在现实场景中失败。类似地,聚焦于遮挡的研究在单个数据集上进行评估[192,213],或者需要根据扫描仪规格进行严格的参数微调[71,75]。还有关于威胁的研究行李CT图像中的检测仅针对有限的威胁类别进行评估[206],而且还未部署。行李筛查受到不断变化的威胁环境的影响,因此行李威胁检测方法必须考虑快速变化的新型威胁以及识别拆卸和隐藏的违禁品[227]。这篇文章为研究人员提供了一个平台,以确定现有文献中的差距,并为他们提供了一个机会,以制定新的框架来有效和高效地解决这些问题。
此外,少数已发表的调查(表1)要么只涉及图像增强方法[92]和传统方法[154],要么概述了不同X射线成像应用中的技术[127]。Mery等人[134]提出了一种行李威胁识别的潜在解决方案,它混合了X射线能级、多视图和检测算法。然而,相关研究中的方法并没有被彻底探索,以使研究人员能够比较不同策略的优势和局限性。Mouton和Breckon[144]专注于行李CT量的危险品检测(基于深度学习的方法未包括在内,因为它们尚未被使用)。Rogers等人[175]回顾了货物集装箱中的威胁检测方法,由于缺乏货物领域的文献,很少采用来自行李威胁检测的技术。Akcay等人[8]回顾了2D X射线安全成像中使用的方法。然而,新的基准[191,201,213]发布了,随后引入了几个有前景的基于深度学习的危险品识别框架。此外,该调查缺乏对3D CT技术以及拆卸和3D打印枪支等新挑战和危险品的回顾。先前的调查[8,127,134,154]也没有在公共数据集上对现有方法进行基准测试。

在本文中,我们的目标是对现有的X射线行李安检文献进行全面和系统的调查,包括2D X射线和3D CT成像,作为该领域最先进的一站式参考点,从而促进不同方法的性能评估,并利用这些发现为该领域的未来方向提供指导。我们的主要贡献如下:
-
以领域为重点的问题:我们讨论行李安全检查特有的问题和当前的挑战。
-
分类:我们提出对现有文献进行综合分类,包括2D和3D CT X射线成像,从而聚焦相关研究方向(见图1)。
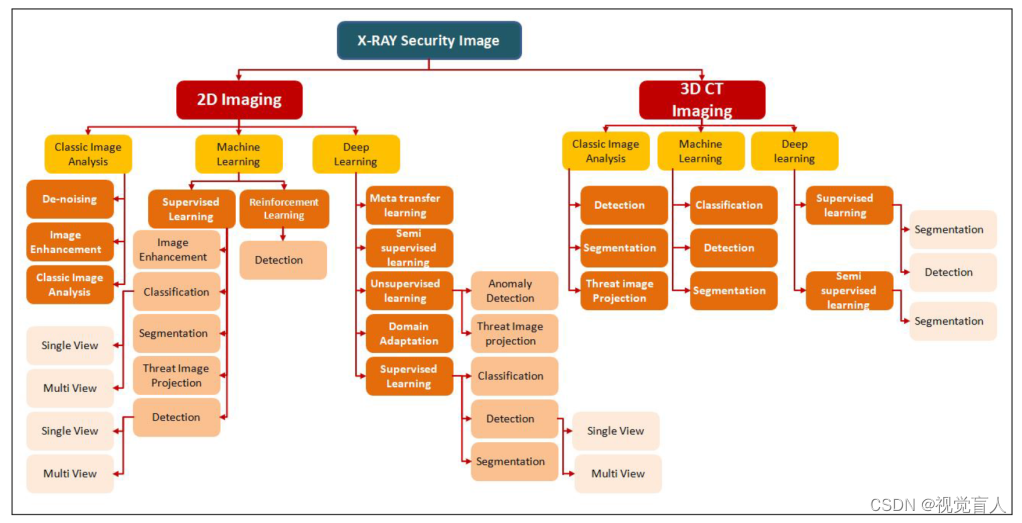
图1
-
系统回顾:我们概述了2D和3D X射线行李筛查,并回顾了主要出版物中的相关研究,以系统地了解该领域的进展。
-
性能基准测试和实验协议:据我们所知,我们是第一个对现有的四个基准测试(GDXray[131]、SIXray[138]、OPIXray[138]和Compass-XP[28])的当前方法及其实验协议进行全面性能分析的团队。
-
未来方向:我们讨论可能的未来方向及其对解决当前问题的影响。
本文的其余部分组织如下:第2节介绍了X射线成像系统的概述;第3节介绍数据集和评估指标;第4节和第5节分别研究了2D和3D CT X射线成像方法,介绍了对应使用的经典图像分析、机器学习和深度学习方法;第6节揭示了研究差距和未来的方向;第7节是结论。
-
X射线安检
基于X射线的筛查是非侵入性威胁评估中最古老和最广泛使用的方法。为了更好地理解与自动危险品识别相关的挑战,本文将探讨2D X射线和3D CT成像系统,并简要概述它们的区别(表2)。

2.1 2D X射线成像系统
一般来说,X射线成像不同于摄影图像,因为它们通过衰减穿过感兴趣的物体的X射线来捕捉物体的结构细节。系统概述如图2所示。当一束X射线穿透一个物体(放置在其路径上)时,它会经历不同程度的衰减,然后被探测器记录为“类似阴影”的投影。入射光束所受的衰减可表示为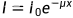 ,I是观测到的强度,I0是入射光束的强度,x是物体的厚度,μ是物体的衰减系数,而衰减系数又取决于能量、材料的原子序数和密度。最终观测到的强度取决于X射线路径上的所有物体。因此,X射线透射图像不同于反射图像,反射图像中的像素只属于单个项目。从观测到的衰减中精确推断材料的原子序数有助于有效地区分X射线路径中的物体。然而,传统的单能量X射线成像不足以完成这项任务,因为不同厚度的不同材料可以产生相同程度的衰减。尽管金属物体由于其明显的高衰减,可以很容易地在单能量扫描中发现,但对于塑料等其他材料来说却不是这样。因此,多能量X射线成像系统利用不同能级的X射线来更好地区分材料。通常,利用双能X射线成像系统(分别由低和高阳极电压产生)获得的低能和高能扫描,通过分析各自能量下的衰减来校准,从查找表中推断出材料成分[186],基于该信息对图像进行伪着色,可以更好地识别行李内容。在某些情况下,双能量体系仍然容易被识别出材料的组成,例如有机液体和聚碳材料[216]。
,I是观测到的强度,I0是入射光束的强度,x是物体的厚度,μ是物体的衰减系数,而衰减系数又取决于能量、材料的原子序数和密度。最终观测到的强度取决于X射线路径上的所有物体。因此,X射线透射图像不同于反射图像,反射图像中的像素只属于单个项目。从观测到的衰减中精确推断材料的原子序数有助于有效地区分X射线路径中的物体。然而,传统的单能量X射线成像不足以完成这项任务,因为不同厚度的不同材料可以产生相同程度的衰减。尽管金属物体由于其明显的高衰减,可以很容易地在单能量扫描中发现,但对于塑料等其他材料来说却不是这样。因此,多能量X射线成像系统利用不同能级的X射线来更好地区分材料。通常,利用双能X射线成像系统(分别由低和高阳极电压产生)获得的低能和高能扫描,通过分析各自能量下的衰减来校准,从查找表中推断出材料成分[186],基于该信息对图像进行伪着色,可以更好地识别行李内容。在某些情况下,双能量体系仍然容易被识别出材料的组成,例如有机液体和聚碳材料[216]。
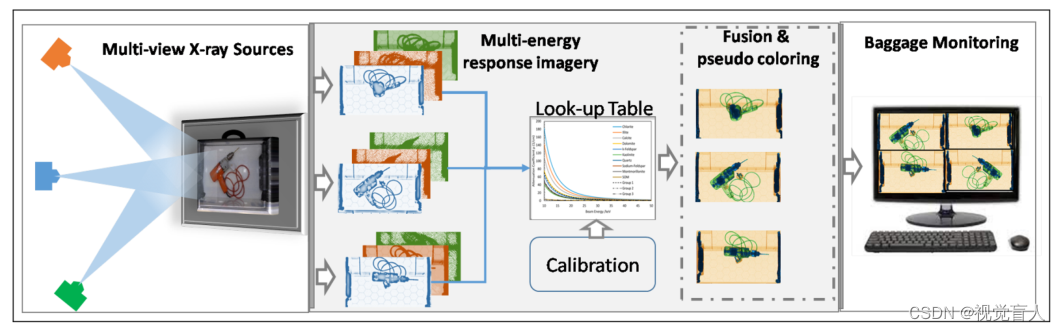
图2
2.2 3D X射线CT成像系统
计算机断层扫描(CT)最初是为医疗诊断而设计的,是一种用于行李检查以识别爆炸物材料的放射成像方案[173]。当X射线源和探测器阵列围绕行李旋转时,就会获得CT扫描,从多个角度捕捉投影,以生成强度剖面。该强度剖面用于生成密度图,以表示行李的2D切片。衰减系数在每一点的恢复被表述为一个不适定问题。提出了几种重构算法,比如基于Radon变换[51]的滤波反投影(FBP)方法[143],然后将这些图像切片进行堆叠,以生成以各向异性体素分辨率为特征的体积数据。然而,与X射线一样,单能量CT扫描仪在有效区分材料时面临模糊性。因此,在双能CT扫描仪(DECT)中,物体以两种不同的能量进行扫描。除此之外,商业系统还采用基于其有效原子序数的伪着色来帮助操作人员有效地分析违禁品,原子序数较高的物体(如金属)被染成蓝色,而较低的物体被染成橙色,两者之间的物体被染成绿色。然而,对原子序数的不准确估计(由于背景重叠)往往会导致误检,并因分辨率差、有限的先验知识和金属人工制品而加剧。
2.3 智能安检的挑战
人工筛查是一个讨价还价的过程,成功率只有80%-90%[139],尽管在过去几年里成功没收了几件违禁物品。杂乱多变的行李图像使人难以识别违禁品。虽然多视角扫描系统可以帮助操作人员从多个角度捕捉图像,但人工筛查中的其他问题包括由于禁用物品很少出现而导致长时间保持警惕的无聊和错误。研究人员致力于开发强大而高效的自动化系统来克服这些漏洞,并为行李威胁筛查提供可靠的解决方案。由于其广泛的应用,目标检测已成为计算机视觉中热门研究的领域之一,通过利用深度学习的成果,并得到巨大公共数据集的支持,取得了令人震惊的结果。然而,这些算法在行李安全方面并没有达到类似的水平。智能安检仍然是一个公开的挑战的主要原因有:
-
X射线扫描的固有特征:与摄影图像相反,X射线扫描图像缺乏细节信息且对比度低,是行李威胁检测算法[19]性能不佳的原因之一。
-
复杂背景和遮挡:由于遮挡、紧密堆叠和高度混乱的行李使得在图像中很难识别出违禁品,特别是在重叠的高密度物体的情况下。物体的方向也可能导致自遮挡(如图3所示)。
-
有限的数据集:X射线行李图像的敏感性和版权问题限制了大型数据集的可用性。因此,它延迟了深度学习方法在该领域的部署,并限制了它们的成就(因为大多数当前框架严重依赖于注解良好的数据集)。
-
类别不平衡:安检中禁用物品的稀少出现也导致了类别不平衡的问题,这种长尾数据分布使得适当的无偏技术建模非常困难。
-
图像质量:与医疗级CT扫描仪的特点是亚毫米各向同性分辨率不同,CT扫描仪以更快的扫描速度换取差的图像质量。金属伪影的体素分辨率较差,导致检测性能较差[52]。
-
有限的先验信息:行李内容物的不确定性限制了行李扫描中先验知识(形状、拓扑或空间变化)的使用[120,123](与医学图像分析不同)。此外,使用形状先验来识别违禁物品的研究将无法检测到拆卸的违禁品(这与他们先前的形状理解不同),例如拆卸的枪支[52,55]。
-
泛化有限:针对特定对象设计的违禁物品检测算法无法对其他物品获得类似的结果。检测算法也能发现从不同扫描仪获得的图像难以达到相同的性能,必须进行相应的调整。
-
新型违禁品:聚合物和碳构成的威胁物品(如3D打印枪支)在X射线扫描中几乎看不到,这使得它们几乎不可能被发现。现有方法对新的和不断发展的威胁的有限适应性是安全部门风险评估的一个严重问题。因此,开发更强大、更灵活、更实时的行李扫描违禁品识别方法势在必行。

-
数据集和评价指标
3.1 数据集
本节探讨用于X射线行李筛查研究的常用数据集(表3中总结)。
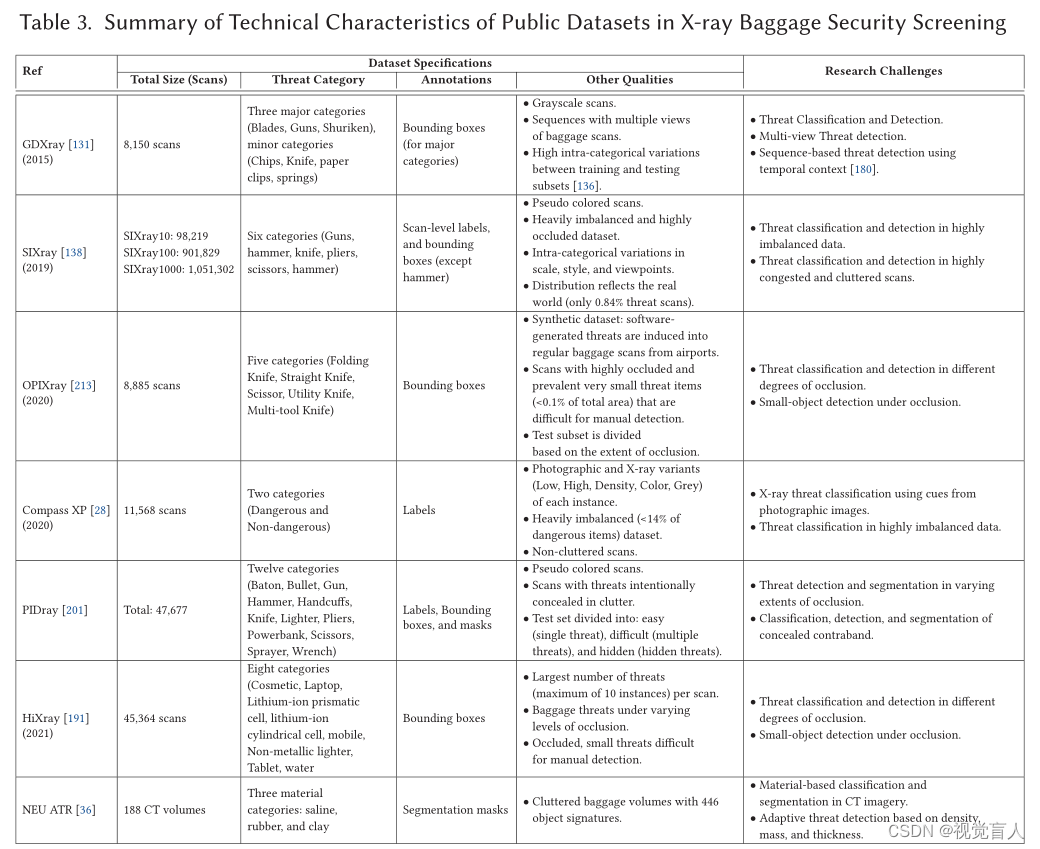
3.1.1 公共数据集
GRIMA X-ray (GDXray)[131]包含19,407张灰度图像,分为5类,用于多种应用,其中包括8,150张用于安检的X射线图像。行李类别被细分为不同的系列,重点关注三种主要的危险品:手枪、飞镖和剃须刀片。它提供了600个标注图像来实现自动检测。然而,GDXray中相对较少杂乱的X射线图像被研究团体认为缺乏遮挡。
Security Inspection X-ray (SIXray)[138]包含超过100万张图像,其中只有不到1%的图像存在违禁品,在遮挡和类不平衡方面给研究带来了更多的挑战。SIXray数据集集中于六大类违禁品:枪支(3131张图像)、刀具(1943张图像)、钳子(3961张图像)、扳手(2199张图像)、剪刀(983张图像)和锤子(60张图像)。数据集还包括三个细分:SIXray10、SIXray100和SIXray1000,其中数字表示负样本和正样本的比例。每个细分进一步分为训练集和测试集,比例为4:1。
Occluded Prohibited Items X-ray (OPIXray) [213]于2020年发布,是使用以标准行李扫描为背景的软件综合生成的。它由8885张行李扫描图组成,使用不同种类的刀具:折叠刀(1993张图像)、直刀(1044张图像)、多功能刀(1978张图像)、多工具刀(1978张图像)和剪刀(1863张图像)。大约30个训练扫描和5个测试扫描包含多个违禁品。根据X射线扫描中遇到的遮挡程度,测试集被划分为三个子集,即OL1(922张图像),OL2(548张图像)和OL3(306张图像)。
Compass-XP[28]数据集最初的目标是利用拍摄图像中的信息来提高X射线危险品检测性能,该数据集由成对图像(负样本:1643对,正样本:258对)组成,其中以两种方式捕获项目。拍摄图像由索尼DSC-W800数码相机获得,X射线图像(低能量、高能、材料密度、灰度和彩色扫描)由Gilardoni FEP ME 536 X射线扫描仪获得。
Prohibited Item Detection (PIDray) [201]数据集是最近增加到公共X射线安检基准集合的数据集,它对有意隐藏的威胁的研究提出了进一步的挑战。该数据集包含47,677个行李扫描,包括12类违禁物品,是最广泛的行李违禁品X射线扫描集合,包含40%图像的测试子集进一步分为三个子组:简单(9482个单一危险品扫描),困难(3733个多重危险品扫描)和隐藏(5005个故意隐藏的危险品扫描)。
High-quality X-ray (HiXray)[191]数据集是最近增加的另一个数据集,由从机场收集的45,364个行李X射线安检图像组成。该数据集包含102928件常规违禁物品,分为8类:便携式锂充电器(棱柱状和圆柱形)、水、笔记本电脑、手机、平板电脑、化妆品和非金属打火机。HiXray每次扫描平均有2.27个非法项目,每次扫描最多有10个实例。测试子集根据遮挡的程度进一步细分:OL1(无遮挡),OL2(部分遮挡)和OL3(严重遮挡)。
Northeastern University Automatic Threat Recognition (NEU ATR)[36]数据集由美国DHS(Department of Homeland Security)赞助的东北大学警报中心发起,由188个行李CT卷组成,包含446个对应于盐水、橡胶和粘土的目标标签。512 × 512的CT切片对应475 mm × 475 mm的视场,切片之间的间距为1.5 mm。体素值在0到32,767 MHU (Modified Hounsfield Unit)之间变化[220],其中空气和水的值分别为0和1024。
3.1.1 私人数据集
Durham Baggage Patch/Full Image数据集包括使用单视图x射线扫描仪捕获的约15,500张伪彩色x射线图像[10,11]。通过手工裁剪构建的昵称为Dbp2和Dbp6的不同版本的数据集已用于二进制和多类别(相机、陶瓷刀、火器、火器部件、刀、笔记本电脑和杂波)分类;Dbf2和Dbf6用于检测[9]。
Full firearm vs. Operational Benign (FFOB) 数据集(参考文献[6,7])包括从国内筛选行动中获得的图像,其中包含巧妙隐藏的枪支。FFOB包含4680个正样本,是一个不平衡的数据集,有67672个负样本。
University Baggage Anomaly (UBA) 数据集,也称为Durham行李异常数据集,用于异常检测方法[6,7],由230,275张属于正常和异常类别的图像组成。采用滑动窗口机制从伪彩色,单一常规X射线扫描中获得正常图像块。异常图像由手工裁剪以及使用滑动窗口获得的图像块组成,包括三个主要威胁类别:刀具(63,496张图像)、枪支(45,855张图像)和枪支组件(13,452张图像)。
Passenger Baggage Object Database[62]由桑迪亚国家实验室收集,用于行李扫描中的爆炸威胁目标识别,由Rapiscan 620DV机器捕获的双能量、双视图(顶部和侧面视图)图像组成,分为含违禁品和不含违禁品。它由4,760次扫描组成,总计9,529张图像(每次扫描两张图像),其中41%的违禁品图像(3,920张图像)带有目标框标注。
3.2 评价指标
本节将对用于评估X射线行李危险品识别方法性能的各种评估指标进行概述。常用的度量标准基于下面定义的几个共享概念。
-
True Positive (TP):分类器把正例正确的分类/预测为正例
-
False positive (FP):分类器把负例错误的分类/预测为正例
-
False negative(FN):分类器把正例错误的分类/预测为负例
-
True Negatives(TN):分类器把负例正确的分类/预测为负例
然而,为了确定预测是否解释正确或不正确的结果,有必要评估预测和真实值(检测算法的边界框和分割技术的掩码)与它们覆盖的总面积之间的重叠比例,使用Jaccard指数(或交并比(IoU)度量)进行量化。平均IoU是分割方法中的一个流行指标,它是通过计算所有类别的平均IoU来获得的。其他的常用指标是精度(Pr)、召回率(Rec)、 F1分数(F1)。Precision(表示被正确分为正例在所有被分为例中的比例),recall(表示所有正例被分对的比例),F1分数表示为:
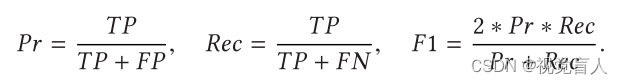
平均准确率(mAcc)是分类任务中使用的标准度量,用于计算不同类别的平均精度。用于目标检测和分割任务的其他指标包括平均精度(AP)和多个类别AP的平均值(mAP)。插值后的精度-召回图下的面积用于计算AP,对不同类别进行平均后,得到mAP。在不同阈值水平下,通过绘制召回率与假阳性率的关系获得的受试者操作员特征(ROC)曲线用于计算曲线下面积(AUC),这是用于评估这些算法有效性的另一个指标。Dice系数(DC),也称为Sorensen指数[43],公式如下,是一种常用的评价分割算法的指标。
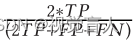


-
在2D X射线成像基础上进行行李安检的方法
之前在2D X射线安检危险品识别方面的工作主要集中在图像分析和传统的机器学习方法上。然而,尽管深度学习方法引入该领域较晚,但它为该领域带来了很大的成功。
行李危险品识别流程的总体流程如图4所示。由2D X射线描或3D CT重建组成的输入行李图像进行后处理,以克服特定领域的挑战(第2.3节)。不同的研究工作采用不同的预处理策略,包括去噪[234]、图像增强[184,233]、伪影减少[144]、采样(数据增强[221,236],或从每次扫描中生成一个建议框[75])或预分割[122,142]。行李危险品识别任务的核心是特征提取阶段[19,116,122,145,176,193],子任务有分类[9,135,204]、检测[8,41,203]、分割[70,199,207]。然而,随着深度学习模型[8]的出现,这些子任务已经合并到一个端到端框架中。少数作品[101,188]也结合了多视图信息来检测来自杂乱X射线图像的危险品。

图4
4.1 基于传统图像分析的方法
图像分析是检测、分类和分割图像的基本工具,通常是计算机视觉应用的第一步。劣质图像导致行李图像的误检率较高[236]。图像分析的主要思想是使用去噪和增强等技术来提高视觉质量,以提取更好的特征,从而突出隐藏的违禁品。少数Threat Image Projection (TIP)技术还采用了传统的图像处理技术,如背景分离,以在X射线行李扫描上投射危险品。这些技术将在下面的小节中进一步详细介绍。文献[154]也对X射线图像中的图像增强方法进行了详细综述。
4.1.1 图像去噪和增强
Abidi等人[1,2]通过伪着色方案增强了可视化,与原始扫描相比,危险品检测成功率提高了97%。参考文献[29]中提出了一种临时的着色方案,以区分负样本有机材料和具有近距离有效原子序数的违禁物品。另一项尝试[236]采用小波变换融合低能和高能X射线图像,然后进行背景噪声减法和基于直方图的增强,采用模糊方法对文献[81]的结果进行了进一步的改进。在参考文献[101]中,基于氡变换的度量用于对低密度危险品的扫描进行整理,在机场筛查器评估期间,危险品检测提高到62%。
4.1.2 图像分类
加强安全措施以打击恐怖袭击的必然必要性引起了研究界对寻求更好的探测性能的先进方法的兴趣。参考文献[157]采用轮廓图像的特征,通过识别多个感兴趣的区域(锤子、扳机和弹簧)来定位9毫米柯尔特贝雷塔手枪。另一个早期的尝试[30]在没有明确研究对象分类的情况下评估了SIFT特征在特征匹配中的前景。Gesick等人[61]研究了在灰度X射线图像中检测隐藏手枪的三种不同方法。第一种方法是边缘检测(仅使用触发器保护),耗时长,不适合实时应用。第二种基于小波的方法由于训练集非常小而不确定。第三种方法基于最近邻匹配的SIFT[112],由于计算效率低,未纳入计算结果。参考文献[50]t采用基于区域的属性,将区域划分为不同的危险级别,提高了操作者的检测性能。文献[196]评价了Gabor滤波器以近距离吸收系数区分有机材料和爆炸物。
4.1.3 图像映射
Threat Image Projection(TIP)[178]是由国际航空安全条例授权的,使用生成的违禁物品X射线图像,有助于培训课程和提高操作员的警惕性。危险品被投射到不含危险品的图像上。最近,TIP也被用于增强训练数据。Mery等人[129]基于简单的线性技术研究了X射线危险品检测,包括对数图像的总和,他们还研究了基于稀疏表示的检测策略、基于前景字典和背景字典分离威胁项,在GDXray上实现了98.7%的整体准确率[131]。
4.2 基于机器学习的方法
机器学习方法在各个领域所取得的成功激励了研究人员将其用于X射线行李危险品识别。关于基于传统机器学习方法的危险品分类、检测和分割任务的文献将在后续子节中详细探讨。
4.2.1 图像增强
很少有研究工作在提高X射线扫描的视觉质量上使用机器学习方法去提高危险品识别,其中一项研究[185]提出了一种前馈多层感知器,该感知器使用几种质量度量(直方图面积、平均值、标准偏差、偏度和像素强度峰度)进行训练,用于预测最适合提高行李扫描质量的增强算法。
4.2.2 图像分类
在视觉词袋(BoVW)成功应用于图像分类、识别和检索[40]之后,Bastan等人[20]通过实验不同的关键点检测器[18](高斯差分(DoG)、Hessian-Laplace、Harris检测器[70]、加速段测试(FAST)[18]、STAR检测器[4])和描述子(尺度不变特征变换(SIFT)[112]、加速鲁棒特征(SURF)和二进制鲁棒独立基本特征[18])、词汇构建方法以及不同的SVM[35]内核,使用SIFT描述子的DoG和Harris检测器(mAP: 0.65)实现了最佳性能。
Tuscany等人[194]进一步改进了结果,将描述符基于类别聚类,增强了双视角单能X射线图像中正类和负类的区分。文献[232]研究了基于语义特征的BoVW模型,以提高安全操作人员的威胁识别性能。在文献[97]中,FAST - SURF组合(准确率94%,TP: 83%)在Dbp2数据集上的枪械分类效果最好。Mery等人[135]提出了稀疏表示技术,利用GDXray对枪械、飞镖、夹子和刀片进行分类[131]。测试图像使用自适应字典表示,在训练阶段学习,最终在重建过程中以最小的误差分配给类,达到95%的分类率。
在基于模糊的方法[152]在图像分类中取得成功的激励下,文献[107]通过在多层次框架中采用小模糊分类器聚合来探索X射线图像中的爆炸物分类。
4.2.3 图像检测
这一类别的早期工作主要集中在检测武器,特别是枪支,在9/11之后,人们对加强安全重新产生了兴趣。文献[153]探讨了基于边缘特征的支持向量机对手枪的实时检测。文献[117]中也使用从感兴趣的分割区域中提取的形状上下文描述符[21]和Zernike moments[93]研究了枪支的检测。Schmidt-Hackenberg等人[177]证明了视觉皮层启发的特征,如SLF-HMAX[168]和v1-like[162]在手枪检测方面优于BoVW模型。参考文献[172]中适用于单能X射线扫描危险品检测的隐式形状模型[99],使用SIFT描述符[112]构建的可视代码本,检测的刀片、飞镖和枪械的TPR分别为0.99、0.97和0.89。Glowacz等人[63]使用刀尖作为检测刀具的兴趣点。
使用多视图X射线图像在提高危险品检测性能方面的意义已在几项工作中进行了研究[130]。在文献[16]和[19]中深入研究了单视角和多视角X射线图像的BoVW模型,采用分支和定界搜索方法评估了不同探测器和描述子的性能。在具有SIFT和SPIN[98]特征的四视角双能X射线图像中,使用多视角获得的结果在检测笔记本电脑、手枪和瓶子方面表现更好。参考文献[19]研究了在多个视图中利用材料信息的描述符,将手枪和瓶子的平均精度提高了20.4%和10%。
参考文献[126]探索了一种通用方法,使用2D特征检测潜在区域,并在多个视图中跟踪它们以减少误报,并在四个应用程序中进行了测试(检测行李扫描中的笔尖、剃须刀片和大头针以及铝轮缺陷)。文献[128]通过在多视角图像中建立感兴趣区域之间的对应关系来提高检测性能,专注于多视角X射线的主动视觉框架[171]被用于检测剃须刀片,其中可疑物体的视点不断变化,以获得更好的姿态供机械臂检测。在文献[169]中对结果进行了改进,其中使用强化学习来估计当检测到可能的威胁项时的最佳视图。刀片和手枪的实验精度分别为100%和83%(各进行360次测试)。很少有研究[132,133]也研究了在多个视图中定位匹配感兴趣点的搜索技术,证明了其优于单视图识别。Franzel等[56]利用HOG特征[39]结合多视角预测结果检测手枪,AP提高14.8%(与单视角检测相比)。最近,Riffo等人[170]提出了利用特征描述符(基于直方图和3D形状先验)从多视图扫描中重建体积来检测手枪,并实现了0.97的精度。
4.2.4 图像分割
分割方法在传统的物体识别中起着突出的作用,分割感兴趣的区域,从中提取特征来检测潜在的威胁。少数文献[44,203,204]研究了基于属性关系图(ARG)的基于模糊相似距离度量的匹配在多能量X射线图像中重叠目标的分割问题。文献[184]探索了前馈神经网络来计算基于行李X射线图像计算的属性的最佳分割参数。Heitz等人[82]利用概率方法将重叠的物体分离到不同的层,以便根据其化学成分更好地推断出违禁物品。然而,这种方法仅限于对少量物体进行不那么杂乱的扫描。
4.3 基于深度学习的方法
关于基于深度学习方法的安检危险品的分类、检测和分割以及异常检测和TIP任务的文献将在后续小节中进行探讨。
4.3.1 图像分类
受到深度学习的启发,特别是CNN在视觉理解方面的进步,Akcay等人[10]通过冻结AlexNet的不同下层[95],对私有DBP2和DBP6数据集进行二进制和多类分类,研究了重用低级通用特征的范围。结果超过BoVW(即使所有权重都被冻结),达到98%的准确率。Mery等人[136]使用10种不同的方法(包括使用SIFT和LBP特征的BoVW、基于稀疏性的方法、隐式形状建模和深度学习)进行了详尽的调查,以评估GDXray中用于物体识别的传统手工特征的表示学习的能力[131]。GoogleNet[190]在四类(枪、飞镖、刀片等)分类问题上以96.3%的优势超过了其他模型。
原始图像(高能量和低能量图像及其日志扫描)首次用于文献[174],使用CNN定位货物图像中的小型隐藏金属危险品,准确率达到95%。Miao等[138]提出类平衡层次细化(CHR)方法,基于X射线图像由重叠层组成并从混合分布中采样的假设,使用改进的损失函数来解决类不平衡问题,他们利用来自中层的视觉线索来获取高层信息以消除非目标数据,并在SIXray10、SIXray100和SIXray1000上使用ResNet101骨干分别实现了79.37%、60.63%和38.14%的mAP。
文献[142]首次尝试使用基于VGG19[183]的改进CNN模型对爆炸物进行分类定位,在PBOD[62]数据集上得到ROC的AUC为0.95。Caldwell和Griffin[28]使用Compass-XP数据集(随研究一起发布)研究了利用易于获取的摄影图像来增强行李图像威胁识别的可行性。然而,结果是有限的,因为只有40%的危险品图像与自然图像相似。Wang等人[208]使用一对条件变分自编码器[188](具有共享权重),使用从RGB图像和X射线图像中提取的特征生成了看不见的危险品的特征。然后使用合成特征和真实特征来训练分类器,以零次学习范式识别危险品,在私有数据集上评估时,在可见和不可见的危险品上比较性能。最近,Hu等人[84]提出了SXMNet,利用自底向上的空间线索识别高度杂乱的行李危险品,并自适应融合细化特征的多阶段预测。
4.3.2 图像检测
分类方面的显著结果鼓励了一些研究工作[9]探索深度学习模型来定位图像中感兴趣的对象,其中YOLOv2[165]在私有数据集中实现了0.974的枪支检测mAP。参考文献[9]中基于区域的框架(F-RCNN[167] 和 R-FCN[38])的性能在X射线行李筛查的背景下进行了评估。R-FCN[38]在Dbp2数据集中实现了0.963的mAP,而F-RCNN (mAP: 0.883)在六类检测任务上实现了最佳性能。
Xu等人[221]利用与识别目标相对应的激活神经元生成的注意图,通过进一步细化X射线图像来抑制来自良性物质的噪声和干扰,从而定位和检测X射线图像中的危险品。他们的方法在GDXray上实现了56.8%的平均IOU[131]。L i等人[108]在使用Faster RCNN之前,采用基于颜色的分割方法从X射线图像中提取前景,并在私有数据集上获得77%的mAP。Dhiraj和Jain[42]评估了F-RCNN[167]在GDXray[131]上的表现,优于Yolov2[165],总体准确率为98.4%。Liu等[110]利用YOLO9000[165]对2850张图像进行了剪刀和气溶胶的检测,得到AP分别为96.5%和92.4%。
目前用于X射线行李安检危险品识别的深度学习方法大多基于单视图检测框架。很少有研究[102,189]关注从多个角度利用信息来改进危险品识别。文献[102]使用单视角和多视角X射线图像测试了F-RCNN、R-FCN和SSD[109]等当代检测框架。在使用R-FCN(基于ResNet[80])进行多类对象检测时,结合多视点输出的结果比单视点输出的结果(79.8%)提高到93.8%,他们进一步将模型整合到Rapiscan中,并在文献[104]中评估了性能,单视图下mAP: 92.4%使用基于ResNet152的F-RCNN[167]检测私人收集的数据集,包括利器、火器、LAGs和钝器,合并多个视图进一步提高了每个危险品类别的结果,分别为14.9%、3.7%、1.8%和1.5%。文献[189]使用基于F-RCNN的危险品检测框架利用了多视图信息,该框架根据成像机制的几何形状将提取的2D特征池到3D空间中(不同于文献[86],其中2D语义被馈给全连接层)。然后,他们被馈送到一个区域建议网络,以获得针对危险品的建议框,获得了更好的结果(mAP: 95.6%)。
在参考文献[57]中使用YOLO[166]在私人数据集上检测简易爆炸物(IED)表明,与完全训练模型(mAP: 0.524)相比,迁移学习产生了较差的结果(mAP: 0.291)。Hassan等人[76]提出了一种两阶段框架,该框架基于在第一阶段迭代提取的大量离线生成区域建议上训练的单个CNN,用于在严重闭塞的行李扫描中检测禁止物品,同时克服固有的类别不平衡,在GDXray[131]和SIXray上分别实现了0.9343和0.959的mAP。
很少有研究集中在X射线安检危险品检测的具体漏洞上,包括极端遮挡、标记数据可用性有限以及对不同扫描仪特性的适应性差。Gaus等[59]探索了基于CNN的模型跨不同扫描仪属性泛化的能力,并评估了Dbf3和SIXray[138](由不同扫描仪捕获)上的危险品分类和检测,使用F-RCNN进行跨域评估时,在Dbf3和SIXray10上分别获得85%和91%的mAP。Hassan等人[77]在低能和高能扫描中利用强度转换来获得双张量,增强行李内物品的轮廓表示。然后将这些等高线地图传递给边界抑制模型,以过滤符合正常项目的无关信息,然后生成边界框并对其进行分类,该方法得到的mAP分别为0.9441 GDXray和0.6457 SIXray。
Sigman等人[182]尝试使用较小的带有危险品的标记源数据集和较大的真实世界无标记域数据集来克服有限数据带来的限制。他们使用在对抗性设置中训练的鉴别器来最小化特定于域的数据编码。Zhang等人[233]采用两阶段方法中的高能量和低能量扫描,使用F-RCNN[167]来检测从材料类型分类器阶段获得的区域建议中的禁止项目,该阶段将图像分割为有机和无机条带。他们在私人数据集上对枪支和刀具的检出率分别为96.5%和95.8%。Wei等人[213]研究了柔性去遮挡模块(DOAM),该模块利用威胁项的边缘和物质信息来形成细化的特征图,有助于增强检测模型的性能。使用DOAM插入SSD的OPIXray基准的定量分析[109]超过了SSD上的初始结果3.12%。他们在文献[192]中进一步探讨了他们的工作,即结合过采样策略来给予复杂样本更多的优先级,从而提高高遮挡扫描的结果。最近,Velayudhan等人[198]提出了一个基于广泛学习系统的行李危险品检测框架,利用CNN主干提取的丰富、相关和低秩特征,这些特征是根据从X射线行李扫描中提取的区域建议进行训练的。
4.3.3 图像分割
早期的语义分割工作[13]在一个轻量级的编码器-解码器框架中追求通道和空间注意。在包含7类违禁物品的私有数据集上的结果表明,IoU的平均值为0.683。Gaus等人[60]探索了双CNN框架来隔离隐藏在电子或电气项目中的威胁,其中对象在第一阶段使用Mask RCNN进行本地化[79],然后如果它们包含任何威胁,则将其分类为异常。但是,F1的分数与基于CNN的没有预定位的分类相比较差。参考文献[22]使用对象级和子组件级分割进一步探讨了这一调查方向,然后使用二进制分类来检测隐藏的威胁。通过初始阶段Mask RCNN[79]分割的感兴趣区域,通过迭代聚类(SLICE)[3]进一步分解为超像素,最后使用细粒度CNN框架进行分类,准确率达到97.9%。
Hassan等人[71]在编码器-解码器框架内使用了基于行李扫描强度转换的等高线地图,以抑制正常物品的等高线并突出严重遮挡的威胁(结果如图6所示)。尽管扫描存在差异,但在统一数据集(GDXray、SIXray、OPIXray和COMPASS-XP)上的实验评估得出mAP为0.4657。Chouai等[33]提出了一种采用对抗性自编码器[114]进行特征提取的语义分割框架,旨在通过考虑有机和无机材料的重叠区域来区分扫描中的有机和无机材料,准确率达到80.17%。
Shafay等[179]利用多级特征对行李威胁进行分割,在SIXray上得到的IoU平均值为0.626,在OPIXray上得到的IoU平均值为0.671。在最近的工作中,文献[180]利用了时间信息,为编码器提供了三帧连续的帧来提高性能,并在GDXray上评估了结果。在前人工作[71,77]的鼓励下,Hassan等人[73]探索了多比例尺等高线地图,以突出即使对比度差的威胁(如叶片),并在GDXray、SIXray和OPIXray上分别获得了0.9779、0.9614和0.8396的mAP。Bhowmik等[24]探索了利用低和高能扫描以及有效扫描和彩色扫描来提取更好的区分特征以用于CARAFE[202]在内部数据集上的分割(mAP: 0.7)的影响。Hassan等人[72]通过修改损失函数的增量学习,将语义分割模型转化为实例感知框架,以保留先验知识并学习新旧信息之间的相关性。他们通过重复训练模型来迭代训练框架,这些样本包含单独标记的相同威胁类别的重叠实例,迫使模型在同一类别的不同实例之间进行区分。最近Wang等人[201]利用级联掩码RCNN提取的多尺度特征上的密集注意力模块对SDANet进行了研究,并在PIDray数据集上对其进行了评估。Tao等人[191]提出了横向抑制模块,通过自上而下和自下而上的方式传播多尺度特征,同时使用边界信息来增强它们,从而过滤掉噪声邻域对感兴趣区域的影响。Ahmed等[5]提出了一种新的平衡亲和损失函数来解决行李威胁识别中严重的类别不平衡问题。他们在SIXray、OPIXray和Compass-XP数据集上使用基于轮廓的实例分割模型评估了他们的方法。
4.3.4 异常检测
从更广泛的意义上讲,异常检测是指识别表现出与标准模式不同的行为的数据点或事件。因此,“异常数据”可能在不同的域之间变化[13]。因此,用于识别异常值的方法使用典型的数据表示来根据与学习分布的偏差对测试数据进行评分。
行李安检中的异常检测是具有挑战性的,因为我们需要识别很少出现的危险品(形状和材料各异),并检测拆卸和隐藏的违禁品。Andrews等人[14]使用稀疏自编码器的特征表示[226],训练SVM[35]来识别异常数据,并在货物数据集上评估他们的方法。Akcay等[6]采用了一种使用编码器-解码器-编码器模型的对抗框架来学习图像和潜在空间中的典型表示,并根据其与学习到的分布的差异对异常进行评分,在FFOB和UBA数据集上实现了88.2%和66%的AUC。作者在参考文献[7]中进一步提高了性能,使用跳过连接来保留细节,以改进重建。
Griffin等人[67]利用其外观(形状或纹理)、语义(作为一种奇怪的对象类型)和隐蔽性对安全图像中的异常进行了分类。使用预训练的CNN,从最终层提取的特征的可能性被计算为表征典型数据的多变量高斯分布,以检测视觉和语义偏差的对象,在FFOB数据集上达到90%的准确率。类不平衡场景中的异常检测在文献[49]中进行了探讨。他们提出了一个两模块系统,第一个由CNN组成,用于特征提取和分类,在平衡数据集上训练,第二个由Bi-GAN[45](在CNN的良性x射线特征上训练)和SVM组成,用于抑制CNN触发的虚假异常。使用DenseNet,在SIXray10、SIXray100和SIXray1000上的mAP分别为83.33%、62.4%和41.11%[85]。后续利用KNN剔除不必要信息的工作[48][68]在SIXray10、SIXray100和SIXray1000上分别提高了0.116、0.0289和0.56。
异常实例分割是由Hassan等人[74]提出的,以减轻对注解良好的数据的过度依赖。他们采用了在良性行李扫描上训练的编码器-解码器模型,并利用重建图像中的差异来识别威胁,而不考虑由于高斯加权傅里叶程式化方法而产生的扫描仪属性[74]。GDXray、SIXray、OPIXray、Compass-XP四种方法评价F1评分结果,分别以32.32%、67.37%、47.19%、45.18%的成绩优于以往工作[6,7]。
4.3.5 TIP和数据增强
CNN对大量标记训练数据的依赖一直是其在X射线安检成像应用中的瓶颈,直到最近该领域发布了一些基准[131,138]。然而,与其他大型存储库(如ImageNet[95])相比,这些数据集只占很小的一部分,这导致了该领域对数据增强方法[181]的探索。涉及旋转或平移的经典数据增强技术收效甚微,因为它们无法捕捉威胁对象类别的多样性,也无法通过行李[25]中的不同位置推断出遮挡。为了解决这些问题,许多研究工作都集中在生成包含不同姿势的危险品的X射线图像,以补充深度学习架构的训练以及TIP[178]。
Yang等人[223]研究了生成式对抗网络(GAN)[64],发现了由有限标记数据施加的约束。使用matting方案[31]对包含10种不同类型危险品的X射线图像的收集数据集进行分割,并根据其形状进行分类,以训练GAN,随后用于训练CNN模型。与仅在真实图像上训练时的97.8%相比,他们获得了98.37%的分类准确率。然而,文献[223]只研究了具有单一危险品的图像。Zhu等人[238]试图克服这一限制,研究了基于GAN的数据增强方法,利用违禁物品的自然图像信息生成X射线图像。X射线安检图像通常是由改进的Self-Attention GAN[231]生成的图像,以及违禁品的自然图像(包括七类:叉子、刀、枪、剪刀、钳子、打火机和充电电源)用于训练Cycle GAN[237],从而将光学领域的各种形状和对准信息传输到X射线领域。使用SSD[109]评估的增强数据集mAP提高了5.6%。
Kim等人[94]研究了使用GANs增强数据集对X射线危险品检测的影响,在使用F-RCNN的GDX-ray上产生了91.3%的mAP。Dumagpi和Jeong[47]分析了仿射变换和基于GAN的图像合成技术用于数据增强。他们使用DCGAN[164]生成违禁品的图像,并使用Cycle-GAN将威胁对象图像从光学域转换为X射线域,并将其注入负样本,保存原始威胁分布以扩大数据集,并使用带有ResNet50的F-RCNN进行评估。使用生成的图像进行增强,将FPR从SIXray100上的25.8%降低到10.5%,而合并转换后的图像将FPR进一步降低到5.9,取得了比文献[138]更好的结果。
在参考文献[176]中,使用在增强数据集(使用PGGAN[89])上训练的YOLOv3[166]进行危险品检测,得到的mAP为0.80。同时,为了克服文献[234]只能生成一个禁止对象的局限性,文献[100]使用语义标签库和Pix2pixHD[212]以及改进的生成器(基于Res2Net[58])来生成包含多个威胁对象的更精细图像。Wei等[214]研究了基于行李大小的实时危险品预测。
一些研究工作通过补充有限的训练数据来提高合成图像的质量和多样性,从而提高CNN的危险品识别性能。然而,在参考文献[25]中发现,基于CNN的检测和分类模型的性能受到综合生成的扩展数据的不利影响,其中使用F-RCNN通过使用TIP增加Durham baggage 数据集的子集来研究性能。当模型仅在真实数据集上训练时,在真实X射线扫描上实现了最佳性能(mAP: 88%),在增强数据集上下降了7%。在复合数据集(真实数据集和合成数据集)上训练时,原始数据集上的性能下降被表征为域移位问题。
4.4 二维X射线行李安检危险品识别方法的基准测试
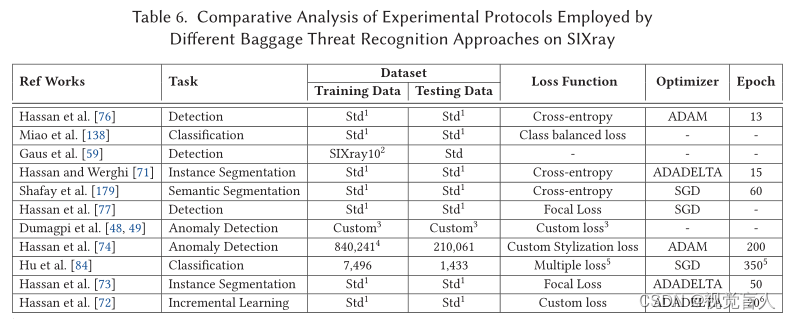
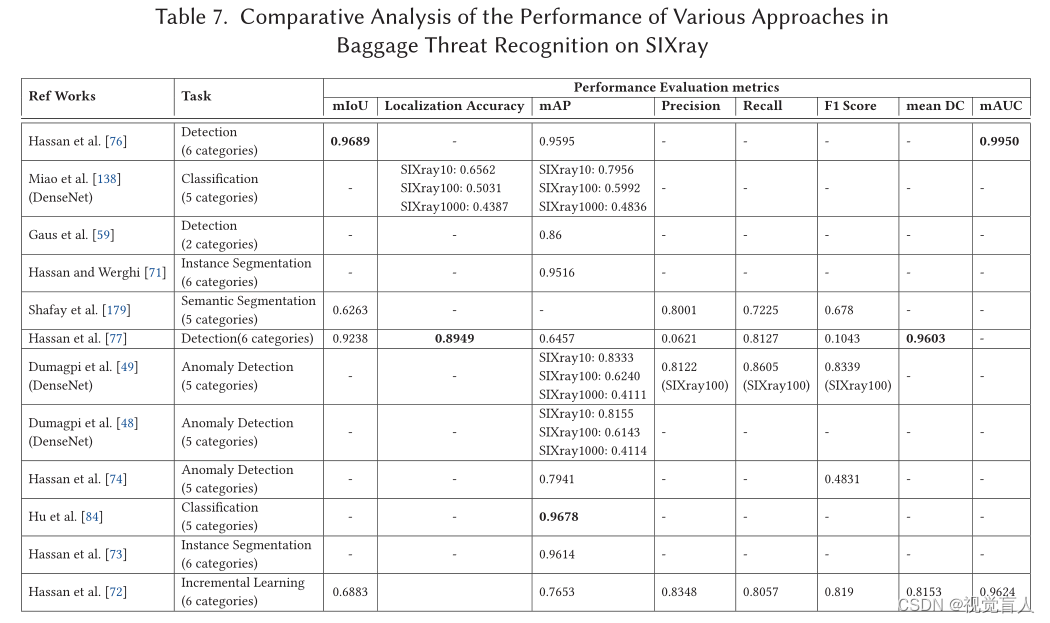
在二维X射线行李安检图像中提出的大多数危险品识别方法都是在私人收集的数据集或单一基准上进行评估的,这使得比较分析成为不可能。因此,在本节中,我们将从实验协议(分别为表4、表6、表8和表10)和性能评估(分别为表5、表7、表9和表10)的角度,全面比较在四个基准上评估的各种方法——GDXray[131]、SIXray[138]、OPIXray[213]和Compass-XP[28]。
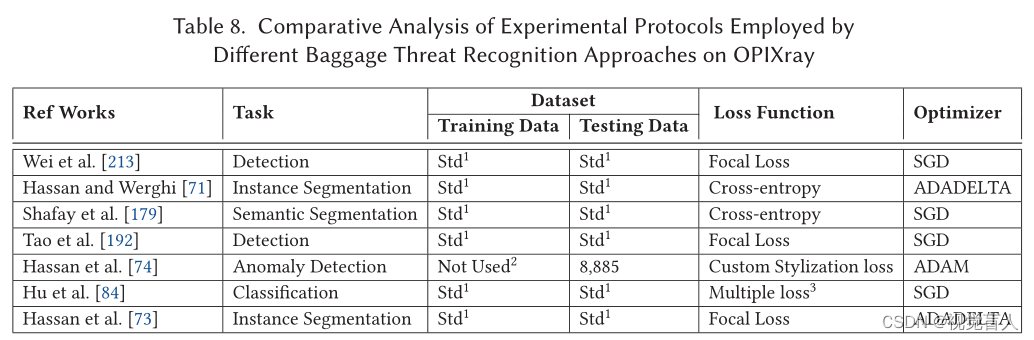
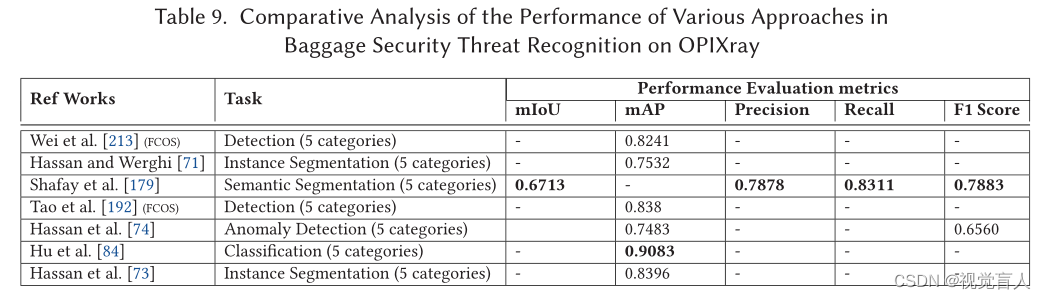
-
在3D CT成像基础上进行行李安检的方法
-
研究差距和未来趋势
最近在行李安检方面的研究取得了重大成果,这些成果源于机器学习方法,并开发了更好的表示和深度学习模型来解决特定领域的特定问题。尽管取得了进展,但这些模型还远远没有面对该领域中复杂的现实问题。因此,本节强调了研究差距,并为每个已确定的研究差距探索了有前途的未来研究方向。
类间差异大:与传统的物体检测不同,行李安全危险品的类别内变化不仅仅是由于视图或形状位置,它们在形状、结构和材料类型上差异很大(如形式多样的简易炸药),因此共享的特征数量较少[150]。目前的框架没有尝试解决每个危险品类别内的高度类内变化,从而导致在现实世界中部署时泛化性较差。仅靠大型数据集或单纯的增强方法无法捕捉到所有的变化,因此无法给出预期的结果。最近基于度量学习的研究主要集中在最小化分类内变异和最大化分类间变异方面。这些方法利用自适应边缘学习[69]在特征空间中加强边缘约束,使模型能够学习判别特征。因此,我们相信关注学习有效的数据表示可以为广义模型铺平道路。
异常检测:目前行李危险品识别中的异常检测方法仅利用训练时的正常图像,性能相对较差。我们认为,专注于少数镜头异常检测技术[193]可能有助于解决这一问题。目前行李危险品识别中的异常检测方法只尝试学习正常类。然而,最近发现异常感知深度学习模型可以提高性能。从属于不同流形的危险品类别的有限异常样本中学习,使模型能够学习可区分的特征,以识别与标记类型相似的实例,并推广到未见异常[159]。专注于未知异常检测的研究也可以证明有利于提高行李危险品检测框架的性能。
有意隐藏的威胁:目前很少有研究[23,60]探讨X射线行李图像中电子设备中隐藏威胁的检测。此外,大多数方法利用形状先验来检测X射线行李图像中的手枪或刀等威胁物体。这些策略适用于检测具有明确外观的已知威胁,但不适用于有意隐藏的威胁。严重依赖于形状或结构先验的算法在检测威胁项目的拆卸和隔离子部件时会失败。
合并图像范围和目标级别的上下文信息对于隐藏威胁检测至关重要。对无害物品和敏感违禁品之间的复杂关系进行建模也会有所帮助。目前很少有深度学习框架[103,189]利用2D X射线中的多个视图,必须进一步鼓励这种框架来解决隐藏的威胁。通过顺序扫描行李[180]从多帧中获得的空间信息[84]和时间信息最近已用于探测遮挡威胁,能够利用注意力机制自适应地利用空间和时间线索的模型也可以证明有利于解决这个问题。
类不平衡:尽管在该领域进行了广泛的研究,但很少有研究[75,138]涉及数据不平衡,并且通常在单个数据集上进行评估。此外,很少有公共数据集关注正常图像和含危险品图像之间的类别不平衡,而这种不平衡在现实生活中普遍存在。然而,类别不平衡使得设计适当的无偏见方法非常困难,从而导致更高的假阴性,这在行李危险品检测中尤其可能是灾难性的。因此,除了在特定问题框架内基于采样的方法外,探索算法[96]和混合方法[41]是必要的。此外,违禁品类别的分布也高度倾斜,与毒品相比,手枪和刀具等某些物品的比例更高。因此,在常见类别和罕见类别上表现同样出色的学习模型是一个挑战,需要进一步探索。
新型危险品:最近非法聚碳物品的激增(特别是3D打印)对目前行李筛查中的自动威胁检测方法提出了前所未有的挑战。3D打印枪支和陶瓷刀等危险品在X射线扫描中几乎看不见,导致当前算法无法检测到。此外,拆除和隐藏它们使其无法识别。我们相信需要设计一个能够有效检测金属和聚合物/碳基威胁的安全系统。一个潜在的方向是补充基于X射线的成像与其他非破坏性和非侵入性成像方式,如太赫兹成像[228]。这项技术已经用于个人筛查,因为它能够穿透塑料、纸张、陶瓷或木材等材料,允许通过几层衣服检测聚合物和碳基威胁。最近的研究还显示了它在区分不同类型的挥发性液体[17]方面的潜力,使乘客可以通过安检,而无需从行李中取出液体。
实时自适应危险品识别:目前的方法没有考虑到实时危险品识别和适应新威胁类别的灵活性。鲁棒性强的检测模型应该能够不断地自我调整,以适应新的信息,同时保留以前的知识。这种适应性可以包括已登记类别的新数据(数据增量学习)或全新的危险品类别(类增量学习)。最近Khan等人[91]尝试研究行李危险品分类中的持续学习,但其结果落后于迁移学习。然而,能够终身学习的多功能模型[160]能够稳定地积累知识,并为模仿人类学习的未来适应进行改进,这是在这种背景下的一个合适的研究。设计新的目标函数,约束当前系统以保留其先验知识,并加强先验信息和新信息之间的相互关系和结构相互依赖,这可能为未来解决问题铺平道路。
系统可解释性:当前的行李危险品框架使用评估指标来捕获它们的性能摘要,这些指标报告了测试集的汇总分数。虽然这很重要,但分析特性和实例的故障模式也很关键,尤其是在高风险应用程序中使用时。深度神经网络通常依赖于最表面和最明显的模式来进行预测。但是,通常,这些特定于类的模式在现实世界中要么是虚假的,要么是过度强调的(甚至与类不相关),导致模型的性能较差[187]。这一问题在行李检查中更加严重,危险品以多种形式出现,依赖特定线索可能导致误解。例如,一个训练用来检测刀具的模型可能会使用尖尖的尖端作为明显的线索,从而无法定位闭合的弹簧刀。因此,我们认为有必要找到几个语义上不同的线索,而不是依赖于最明显的特征。鼓励行李威胁框架的可解释性和透明度以可视化决策是至关重要的。设计超越基本显著性过滤的模型将允许识别影响决策的区域和识别陷阱,鼓励开发更健壮的模型。
-
结论
由深度学习开创的当代计算机视觉技术,凭借其在视觉理解方面令人印象深刻的表现,已经超越了先前最先进的方法,为2D X射线和3D CT 成像行李安检中的自动危险品识别算法的开发带来了新的见解。作为调查的一部分,我们强调并分析了其中几个在该领域内取得重大进展的算法,以及基于它们在危险品分类、检测和分割以及异常检测和威胁图像投影中的作用的结构分类法。还总结了在公共基准上评估的方法的性能,以便于对其实验方案和成果进行比较分析。
已经有几种方法试图解决该领域固有的问题,如视觉质量增强和伪影减少、极端杂波和遮挡、类别不平衡问题、有限的数据、对不同威胁的适应性问题以及对不同扫描仪的泛化能力差。尽管取得了进展,但这些模型还远远没有面对该领域中现实世界的复杂问题。我们理解了这些问题,并探索了未来研究的方向。我们希望这项调查能刺激新的研究,并使初学者有更好的领域理解。


















 1233
1233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









