






一、transformer的总体结构
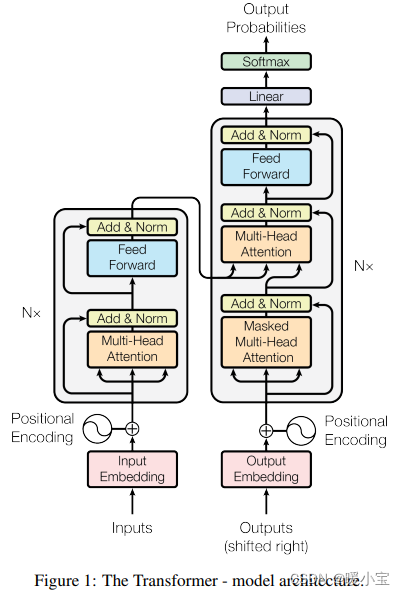
二、各部分详解
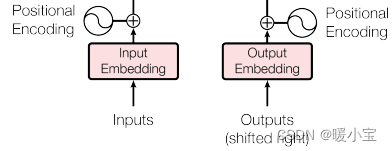
1、输入部分
- 源文本嵌入层及其位置编码器
- 目标文本嵌入层及其位置编码器
文本嵌入层的作用:将文本中词汇的数字表示转变为向量表示。(nn.Embedding)
位置编码器的作用:将词汇位置不同可能会产生的不同语义信息加入到词向量中,位置向量维度与词向量维度一致,以弥补位置信息的缺失。(Positional Encoding 论文中使用的是正余弦位置编码)
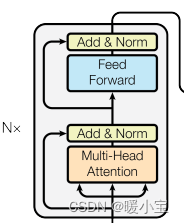
2、编码器部分
- 由N个编码器层堆叠而成
- 每个编码器层由两个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力层和归一化层以及一个残差连接
- 第二个子层连接结构包括一个前馈全连接层和归一化层以及一个残差连接
自注意力层:将输入序列中的每个位置与所有其他位置进行交互,以计算出每个位置的上下文表示向量。
前馈全连接层:将每个位置的上下文表示向量映射到另一个向量空间,以捕捉更高级别的特征。实际上就是两层线性映射并用激活函数激活。
3、解码器部分
- 由N个解码器层堆叠而成
- 每个编码器层由三个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力层和归一化层以及一个残差连接
- 第二个子层连接结构包括一个多头注意力层和归一化层以及一个残差连接
- 第三个子层连接结构包括一个前馈全连接层和归一化层以及一个残差连接
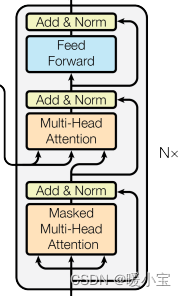
掩码张量mask:一般是0或1,它对某些值进行掩盖,使其在参数更新时不产生效果。
归一化层Layer Normalization:用每一列的每一个元素减去这列的均值,再除以这列的标准差(加上一个极小的值),从而得到归一化后的数值。(加一个极小的值为了防止分母为0)
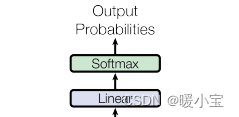
4、输出部分
- 线性层:通过对上一步的线性变化得到指定维度的输出,也就是转换维度的作用
- softmax层:使最后一维的向量中的数字缩放到0-1的概率值域内,并满足它们的和为1
三、最关键的自注意力机制
1、自注意力机制
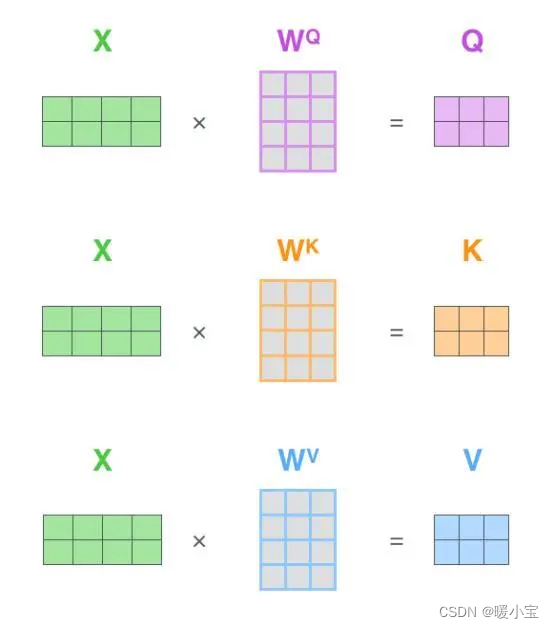
(1)自注意力层中有三个重要的矩阵:查询矩阵Q(query)、键矩阵K(key)和值矩阵V(value)。自注意力的输入是词向量(嵌入了位置信息),将词向量乘以三个训练过的权重矩阵,可得到Q、K、V三个矩阵,计算过程如下图所示。
比喻理解:
- Q是一段准备概括的文本,K是给出的提示,V是大脑中的对提示K的延伸。
- 当Q=K=V时,称作自注意力机制。
(2)计算注意力得分,用Q的每一个向量与K的每一个向量计算点积得到Score。
(3)将Score分别除以K向量维度的开方,这样做的目的是为了让梯度更加稳定。
(4)通过softmax函数,将Score标准化,使它们都是正数并且加起来等于1。
(5)将上述结果乘以V的每一个向量,为了保持想要关注单词的值不变,掩盖掉不相关的单词。
(6)将带权重的每一个V向量加起来,从而得到这个单词的自注意力层的输出。
(2)~(6)计算步骤的公式表达:
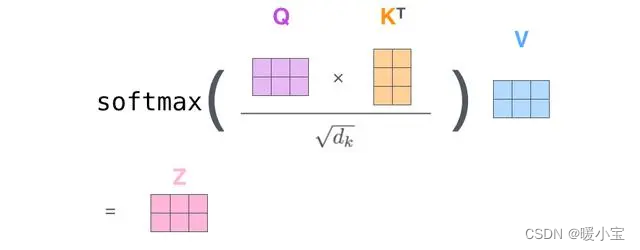
2、多头自注意力机制
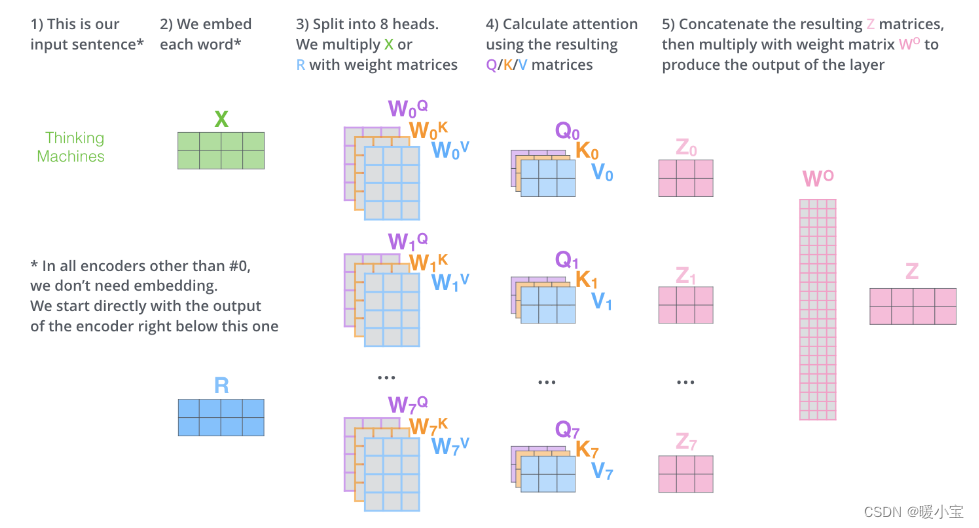
多头自注意力层在自注意力层的基础上,使用多组权重矩阵得到多组Q、K、V矩阵,每一组的Q、K、V都不相同,经过多个并行的自注意力层处理,每一个自注意力层分别计算得到一个Z矩阵,最后将得到的多个Z矩阵进行拼接,因为前馈全连接层的输入是1个矩阵而不是8个,所以需要用一个额外的权重矩阵
与拼接后的矩阵相乘得到前馈神经网络的输入。(论文中是8组)
图解步骤如下:
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









