






论文题目:Dual Residual Attention Network for Image Denoising
案例:挑选一篇基于Transformer的水下图像增强模型,在此基础上加入RAB模块,以此提高SSIM与PSNR效果。
可插入模块:Residual attention block(残差注意力模块)
流程:DRANet模型采用双分支网络架构,主要包括两个功能互补的子网络。在上子网络中,五个RABS模块与一个卷积层协同工作,通过系统的降采样和上采样操作,有效提取多尺度特征并扩展感受野。下子网络则由五个HDRAB模块和一个卷积层构成,专注于处理更高维度的特征表示。值得注意的是,该模型在架构设计中采用了两个关键策略:其一是通过"-"符号表示的剩余学习机制,其二是使用"Concat"操作进行特征融合。特别地,模型在RAB和HDRAB模块之间实施了长跳跃连接,这种设计不仅促进了梯度的有效传播,还增强了特征的复用性。在特征融合方面,两个子网络提取的特征通过连接操作进行深度整合,从而能够全面捕捉图像的全局特征。从实现细节来看,模型中的所有卷积滤波器均统一采用3x3x128的核尺寸,这种一致性设计有助于保持特征提取的稳定性。通过上述架构设计,DRANet模型在加速网络训练的同时,也显著提升了整体性能表现。这种将多尺度特征提取、长跳跃连接和剩余学习相结合的创新设计,使得模型在图像处理任务中展现出优异的特征学习能力。
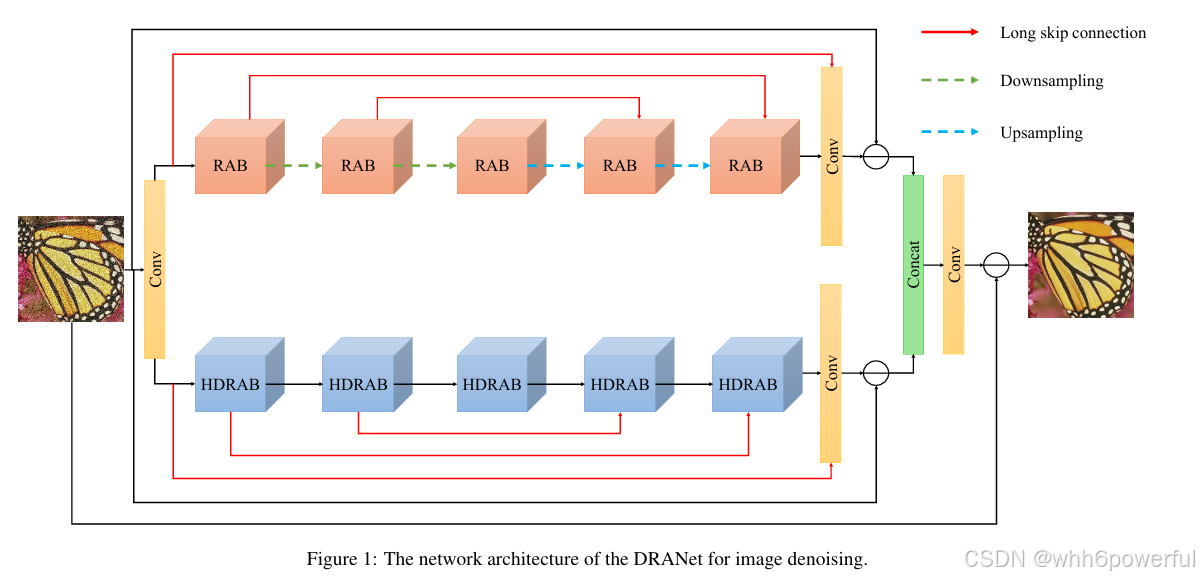
图1.该论文主流程图
模块创新点:通过多跳跃连接提取丰富的局部特征,结合空间注意力机制聚焦关键区域,并利用全局池化捕捉上下文信息,同时通过特征过滤提升效率,使其在图像去噪任务中兼具高性能与高效性。(该模块可以在后半部分的注意力机制进行替换达到创新的目的,以图3为例可以替换为最经典的CBAM等其他注意力机制模块)
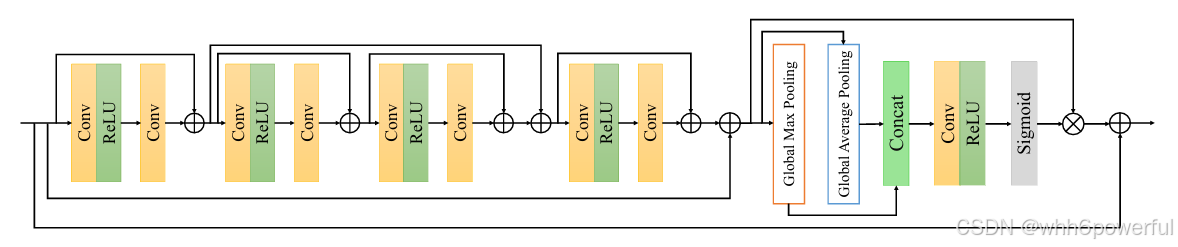
图2.RAB模块
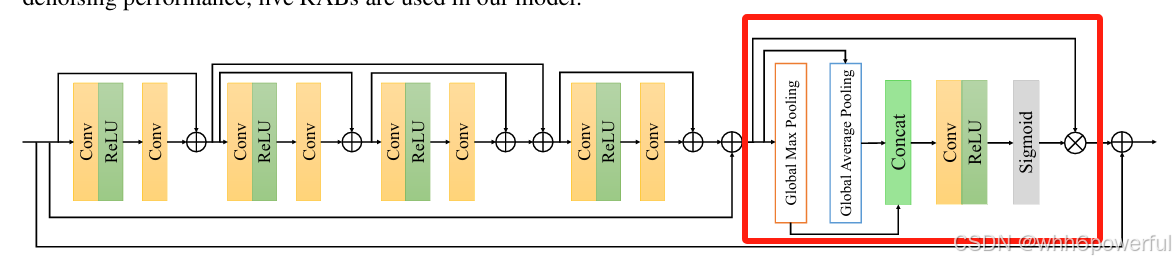
图3.RAB模块替换
例子:本文以该篇论文为base模型,UDAformer: Underwater image enhancement based on dual attention transformer ,我们分别在该模型的跳跃连接增加RAB模块。该模块其实也可以加在输入映射后面,都可以达到涨点效果。
效果对比:可以从主观图看出增强前后有明显的提升,第一个图可以看到黄色明显消除,第二幅图则对比度明显提升。其SSIM与原模型相比较+0.3,PSNR+2.
总结:该模块可以增加到任何图像处理任务中(图像去雨、图像去雾、低照度图像增强等)




RAB模块代码
class Basic(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, padding=0, bias=False):
super(Basic, self).__init__()
self.out_channels = out_planes
groups = 1
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, padding=padding, groups=groups, bias=bias)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
class ChannelPool(nn.Module):
def __init__(self):
super(ChannelPool, self).__init__()
def forward(self, x):
return torch.cat((torch.max(x, 1)[0].unsqueeze(1), torch.mean(x, 1).unsqueeze(1)), dim=1)
class SAB(nn.Module):
def __init__(self):
super(SAB, self).__init__()
kernel_size = 5
self.compress = ChannelPool()
self.spatial = Basic(2, 1, kernel_size, padding=(kernel_size - 1) // 2, bias=False)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.spatial(x_compress)
scale = torch.sigmoid(x_out)
return x * scale
## Channel Attention Layer
class CAB(nn.Module):
def __init__(self, nc, reduction=8, bias=False):
super(CAB, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_du = nn.Sequential(
nn.Conv2d(nc, nc // reduction, kernel_size=1, padding=0, bias=bias),
nn.ReLU(inplace=True),
nn.Conv2d(nc // reduction, nc, kernel_size=1, padding=0, bias=bias),
nn.Sigmoid()
)
def forward(self, x):
y = self.avg_pool(x)
y = self.conv_du(y)
return x * y
class RAB(nn.Module):
def __init__(self, in_channels=64, out_channels=64, bias=True):
super(RAB, self).__init__()
kernel_size = 3
stride = 1
padding = 1
layers = []
layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias))
layers.append(nn.ReLU(inplace=True))
layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias))
self.res = nn.Sequential(*layers)
self.sab = SAB()
def forward(self, x):
x1 = x + self.res(x)
x2 = x1 + self.res(x1)
x3 = x2 + self.res(x2)
x3_1 = x1 + x3
x4 = x3_1 + self.res(x3_1)
x4_1 = x + x4
x5 = self.sab(x4_1)
x5_1 = x + x5
return x5_1

















 1885
1885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









