







现有的关于水下图像的增强方法,常规的传统方法已不太适用于普通研究生做论文或是学习,基本上是基于深度学习的。本人做这个帖子主要是想帮助想从深度学习模型出发,但是又苦于不知道怎么选择模型的同学,作为一个模型科普。
首先,水下图像的深度模型主要分为三种:“基于CNN,基于GAN,基于Transformer”。现在的流行趋势是在Transformer的基础上进行改进,或是在CNN和GAN增加注意力机制。下面我将总结一些常见的网络模型。
1.基于CNN的模型
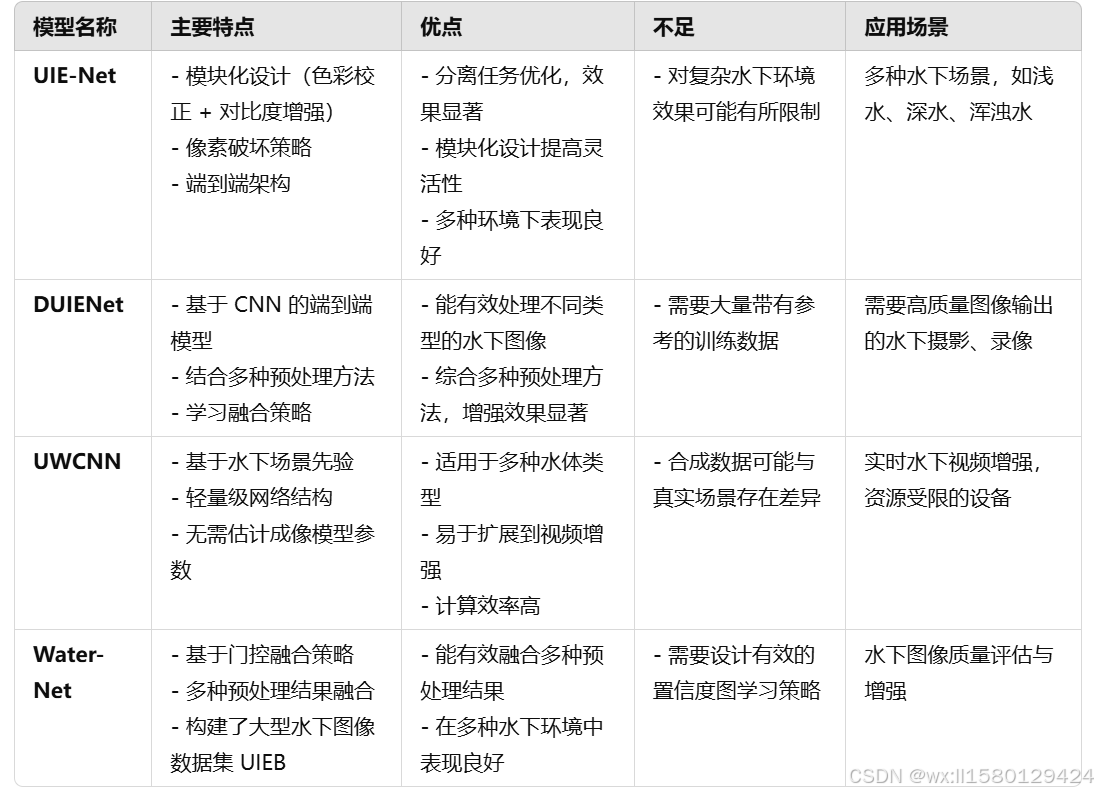
我列举了几种比较常见的CNN模型,其中,单一的CNN模型并没有一些很复杂的卷积结构,卷积操作通过局部感受野处理输入图像,这意味着网络只关注局部像素的相关性,而非全局,这样会导致模型能力不足,训练效率低下。所以现在多数CNN网络是基于一个网络框架来做的,或者是有一些针对性模块。
UIE-Net 是一种端到端的卷积神经网络,主要解决色彩失真、低对比度和模糊等问题。UIE-Net 使用模块化设计,将任务分为 色彩校正 和 去雾增强 两个部分,并通过联合优化实现整体增强。其中CC-Net (Color Correction Network): 负责校正颜色失真问题,如由于光吸收导致的红光衰减或蓝绿色偏移。HR-Net (Haze Removal Network): 用于去除雾化效应,同时提升图像的对比度。
DUIENet 采用了多任务学习的方式,将水下图像增强分为多个步骤,并通过 CNN 学习自动融合这些步骤的结果。DUIENet 将水下图像增强分解为多个子任务(如颜色校正、对比度提升和噪声去除)。每个子任务使用一个卷积模块,并最终通过融合模块整合各子任务的结果。
UWCNN 是一种专为水下图像增强设计的轻量级卷积神经网络。该网络结合了水下成像的物理退化模型的方法,自动恢复图像的清晰度和色彩。UWCNN 不直接估计水下成像模型参数,而是使用水下物理模型生成大量合成数据(如颜色失真和雾化效应)。这些数据涵盖了不同水体类型(如清澈水、浑浊水)和退化程度,为网络提供丰富的训练样本。
Water-Net 采用了基于门控融合的策略。它将传统图像增强方法的结果(如白平衡、直方图均衡)与 CNN 特征进行融合 ,以生成质量更高的增强图像。Water-Net 会对输入图像进行三种传统预处理(白平衡、伽马校正、直方图均衡),然后通过 CNN 学习各预处理结果的重要性分布。最终通过门控机制融合这些结果,生成增强后的图像。
2.基于GAN的模型
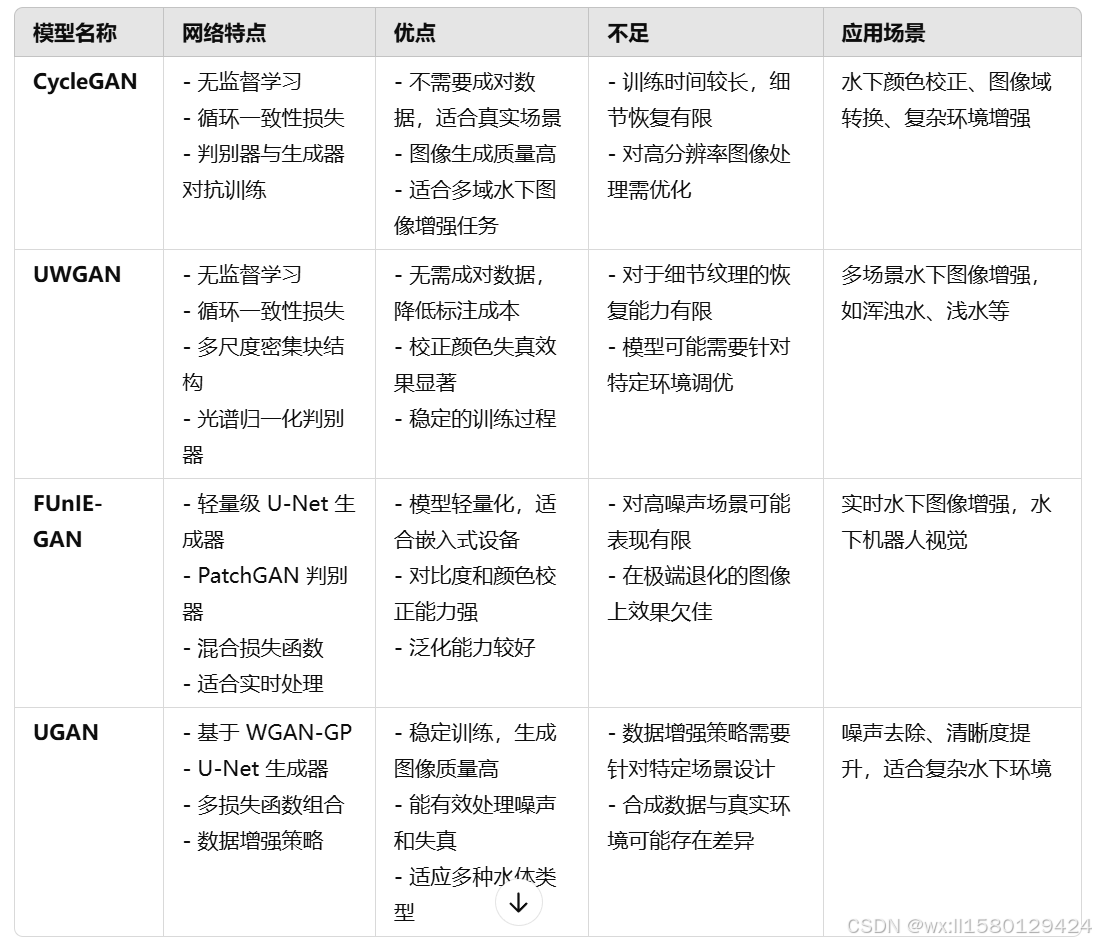
GAN是水下图像增强网络中比较常见的一种模型,因为其在图像生成和风格迁移方面的卓越能力,所以在水下图像增强应用较为广泛。同时,GAN模型中的生成器具备很好可修改性,可以增加各种网络结构作为GAN的生成器,因此也是学生们研究比较多的一种模型。
CycleGAN是一种无监督的水下图像增强网络,它是比较早的一批不需要清晰图像来训练的网络,CycleGAN设计了一种循环一致性损失,确保图像从域 A 到域 B 的转换后,能通过逆向转换还原到原始图像,来保证无监督的时候网络的效果。
UWGAN 是一种基于 CycleGAN 的无监督水下图像增强网络,它在CycleGAN所具有的优势的基础上,改进了生成器结构,在生成器中采用多尺度密集块结构,提高网络的特征提取能力,这种并行的密集结构极大的提升了网络的深度,增强了网络对图像细节特征的提取能力。
FUnIE-GAN网络是一个轻量化的生成对抗网络,它在生成器网络部分采用U-Net结构,U-Net 是一个经典的编码器-解码器结构模型,拥有出色的特征提取和重建能力。因此FUnIE-GAN网络在全局只使用普通卷积层,通过特征降维和升维实现高效的图像增强。并且判别器使用 PatchGAN 结构,使用类似下采样的卷积层来评估生成图像的局部真实性。
UGAN网络通过采用 WGAN-GP结构,改善训练过程中的梯度消失问题,提升模型稳性。它的生成器也是采用U-Net结构来提取图像特征,但是在特征图层面则是通过数据增强,提高模型对不同水下环境的适应性。
3.基于Transformer的模型
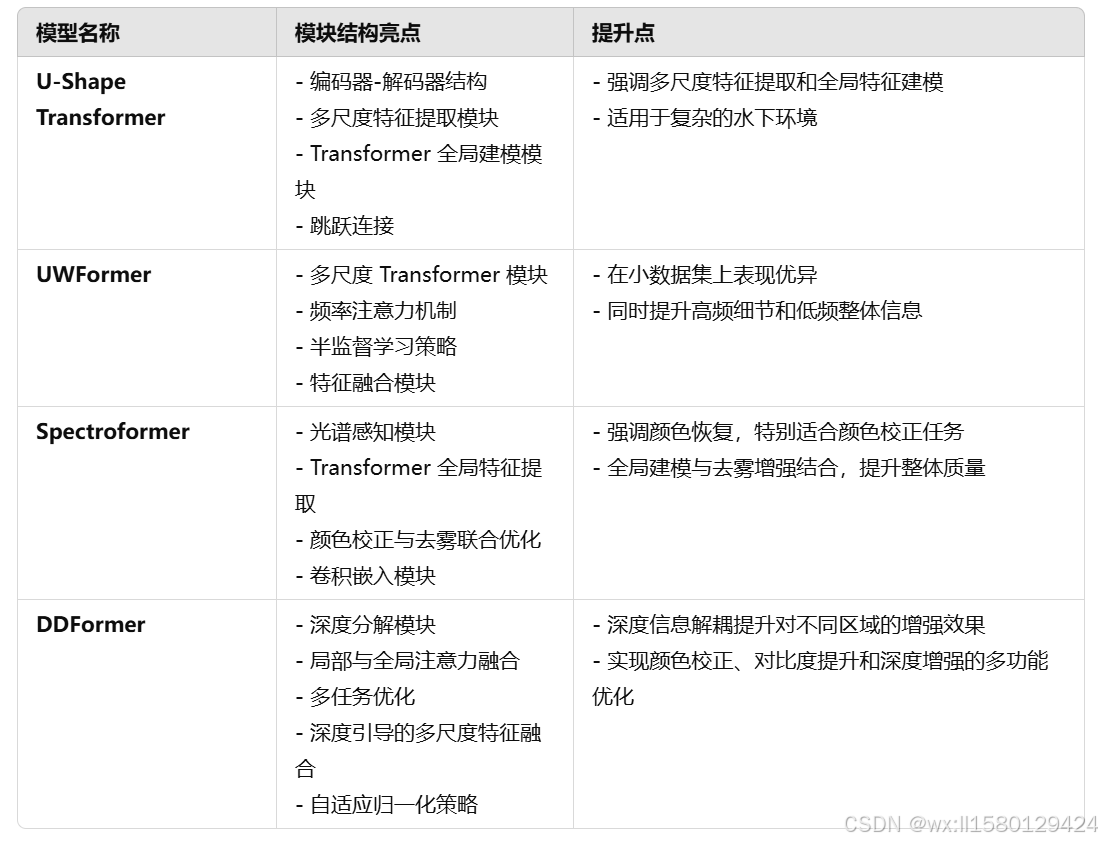
Transformer网路是现在深度学习模型种最主流网络模型,它不仅有很强的前沿性,并且它特有的多头注意力机制具有别的模型不具有的优越性,同时可以在此基础上做出很多的结构改动,帮助同学们进行研究。
U-Shape Transformer 是一种结合了 Transformer 和 U-Net 的网络架构,它是水下图像增强中第一篇将Transformer注意力机制和U-Net结构结合的很好的论文。U-Shape利用Transformer注意力机制捕捉远距离特征间的依赖关系的特点,将多尺度特征提取与全局建模的结合,提高了水下图像增强的效果。
UWFormer是一种利用半监督学习的多尺度 Transformer 网络,通过频域注意力机制,强调高频细节的恢复,提升图像的清晰度和纹理表现。同时在多尺度特征之间加入融合模块,实现不同分辨率特征的统一处理,确保增强后的图像在全局和局部都表现优秀。
Spectroformer是一种结合了光谱特性和 Transformer 模块的网络,它通过提取图像的光谱特性,分析各颜色通道的退化程度,针对性地进行校正。并且利用Transforme捕捉全局上下文信息的能力,在单一框架内同时解决颜色失真和雾化问题,提升整体图像质量。
DDformer是一个基于GAN模型的Transformer网络,通过将不同的信息进行深度分解,对高分辨率图像的细节和颜色进行优化。针对低分辨率图像捕捉全局特征和语义信息。再结合GAN模型的对抗机制,从而提升模型的增强能力。
4.总结
以上就是今天介绍的几种深度学习模型和他们的一些常见模型,如果是考虑比较好发论文的话,建议从Transformer方向去做,因为近几年正是Transformer火热的时段,我们有很多比较好的idea可以借用,同时追逐前沿的创新点是比较好中论文的,而CNN和GAN的模块的话,我建议是作为一个小的研究点去做创新,这样可以帮助我们快速出论文。家觉得我讲的通俗易懂的,可以给我一个免费的点赞吗,谢谢大家了!后续为大家讲解代码以及论文的阅读。最后,如果有需要深度学习网络模型辅导的,可以直接联系我!

















 1849
1849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









