






 文章介绍了交叉滞后模型用于分析变量间因果关系,特别是在研究暴力性电视节目爱好与攻击性,以及大学新生自我效能感与生活满意度的影响时。通过SPSSAMOS进行分析,结果显示自我效能感对生活满意度有显著影响,而生活满意度对自我效能感的影响不显著。
文章介绍了交叉滞后模型用于分析变量间因果关系,特别是在研究暴力性电视节目爱好与攻击性,以及大学新生自我效能感与生活满意度的影响时。通过SPSSAMOS进行分析,结果显示自我效能感对生活满意度有显著影响,而生活满意度对自我效能感的影响不显著。
模型理论:
概念:纵向追踪研究获得的多次数据进行分析以便确定哪个变量影响哪个变量,也就是确定变量之间因果关系的一种分析方法。交叉:既可研究A对B的影响,又可研究B对A的影响;滞后:研究不同时间点变量之间的关系;交叉滞后的结构图为:
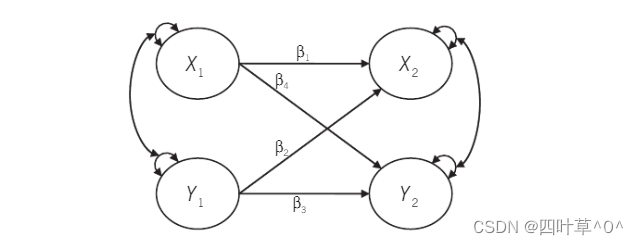
交叉滞后模型中包含了三种结构关系:(1)自回归:即多个时点之间相同变量之间的因果关系;(2)相关/协方差:即同一个时点之间不同变量之间的相关关系;(3)交叉滞后回归:多个时点之间不同变量的因果关系。
交叉滞后模型的优势在于可判断谁因谁果,以及每个路径的强度。比如我们在研究暴力性电视节目的爱好和攻击性之间的因果关系时,采用交叉滞后模型得到如下示意图:
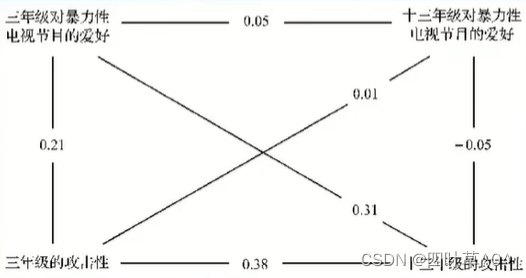
如上述,我们主要关注其交叉滞后关系的系数估计和显著性,即可推断出两个变量的因果关系,三年级对暴力性电视节目的爱好对十三年级的攻击性具显著影响力,则为青少年攻击性形成的果。
案例实现:
数据准备
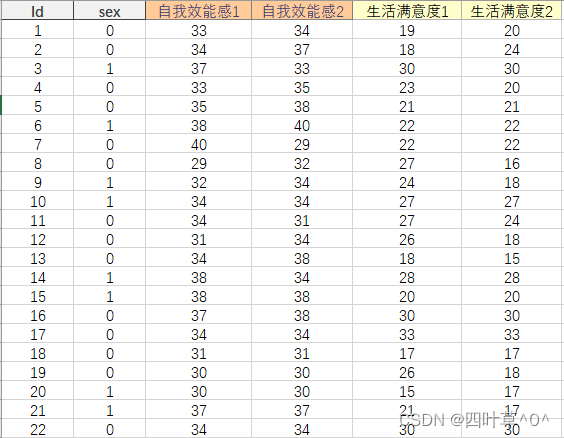
欲了解大学新生一般自我效能感是否影响生活满意度,抽取大学新生样本:在开学第一个月对其同时施测‘一般自我效能感量表’和‘生活满意度问卷’,间隔两个月后,再次施测。即交叉滞后模型要求数据必须是面板数据,数据表如下:
使用SPSS AMOS进行分析
设定模型结构如下,导入数据至AMOS板块
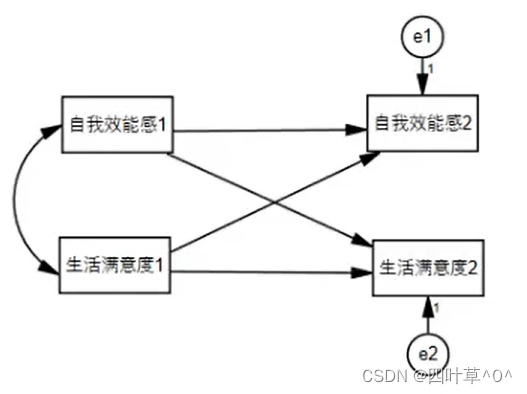
参数估计结果
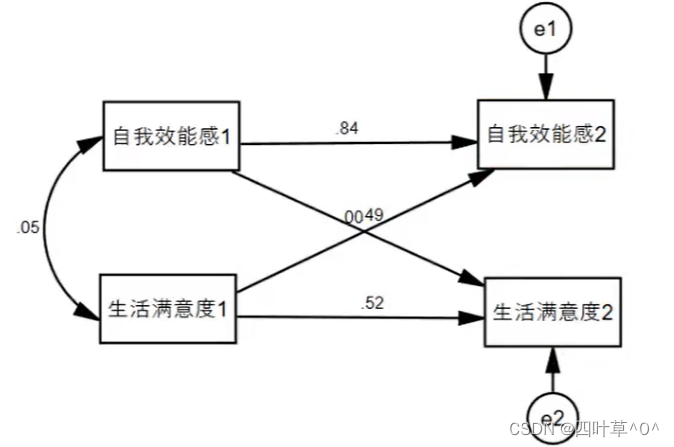
回归及检验结果
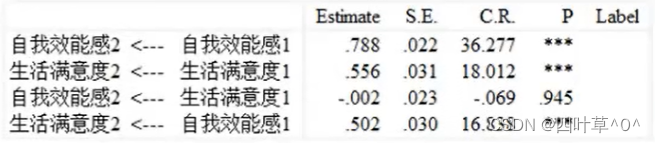
结果解释:生活满意度对自我效能感的影响不显著且回归系数趋近于0;自我效能感对生活满意度的回归系数非常显著:说明自我效能感是生活满意度的原因。

















 1708
1708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









