







有同学问随机截距交叉滞后和传统交叉滞后的区别,随便记录一下,希望给到大家启发。
拟合随机截距交叉滞后模型RI-CLPM的时候我们需要将变量的观察分数分为3个部分:第一部分为总体均数grand means,就是每个变量在同一时间所有观测的均数;第二部分是因素间的稳定性stable between components,体现为变量的随机截距,就是说不同的个体在显变量的得分上有一个随机扰动,第三部分是因素内的波动性fluctuating within components,就是针对每个个体的每次测量和期望的得分的差异。
设定随机截距的操作就是在模型设定的时候额外设定一个重复测量的潜变量,然后将所有测量的载荷设定为1。
具体地看下面的例子,下图是一个研究睡眠问题和焦虑的随机截距交叉滞后模型,数据测了5波,其中Sit代表个体i在t时间的睡眠问题,Ait代表个体i在t时间的焦虑:
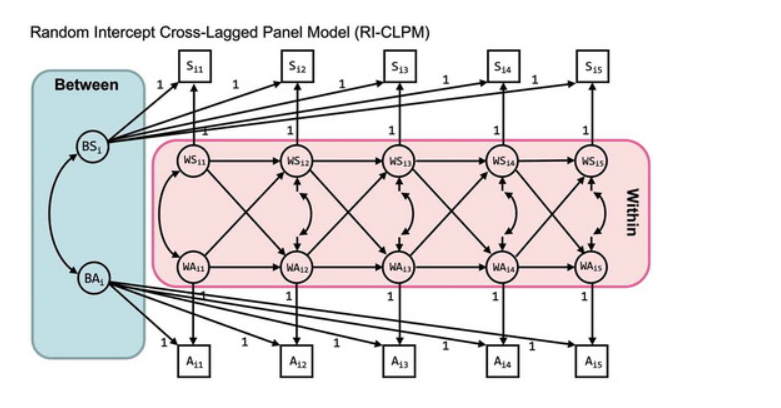
以上图为依据给大家讲讲随机截距交叉滞后的3个部分,首先总体均数就是说我观测的所有样本在某个时间点测得的这个变量的总体水平,比如睡眠的总体均数我就可以用μt表示,焦虑的总体均数就可以用πt表示,t就取1到5,当然了这个总体均数可以随着时间变化,作为一个验证性的方法我也可以选择验证不变性,都行,看你的理论考虑。
第二个部分就是因素间的稳定性,在上面的图中用B打头,这个主要是体现时间不变性条件下的得分与总体均数之间的差异性(同一时间点每个人之间的不同),用随机截距体现,就是个体差异。
第三部分是因素内的波动性,是用W表示的,表示一个个体观测的分数和基于随机截距和总体均数所期望出来的分数之间的差异(纵向波动)。
上面一段中的‘因素’这个词是我本人的翻译,不一定精准,英文是-unit或者component,就是如果你是随访的人,那么就是between person,或within-person,大家理解就好。
有了这三个部分后,我们具体的每一次观测的睡眠问题和焦虑水平就可以写出来方程:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2203
2203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











