







1. 缓存雪崩的常见原因
缓存“雪崩”是指,因为部分缓存节点不可用,而导致整个缓存系统(甚至是整个服务系统)不可用。缓存“雪崩”主要分为以下两种情况:
- 因缓存不支持 rehash 而导致的缓存“雪崩”
- 缓存支持 rehash 时的缓存“雪崩”
1.1. 因缓存不支持 rehash 而导致的缓存“雪崩”
通常是由于缓存体系中有较多的缓存节点不可用,且不支持 rehash,所以请求会“穿透”到 DB,从而导致 DB 不可用,最终导致整个缓存系统不可用。

如图 7-24 所示,缓存节点不支持 rehash,当大量缓存节点不可用时会出现请求读取缓存失败的情况。根据读写缓存策略,这些读取缓存失败的请求会去访问 DB。但是,DB 是很难承载这么多请求的,很容易出现大量的慢查询,最终整个系统不可用。
1.2. 缓存支持 rehash 时的缓存“雪崩”
缓存支持 rehash 时产生的“雪崩”,一般跟瞬时流量洪峰有关。瞬时流量洪峰到达引发部分缓存节点过载,然后流量洪峰会扩散到其他缓存节点,最终整个缓存系统异常。
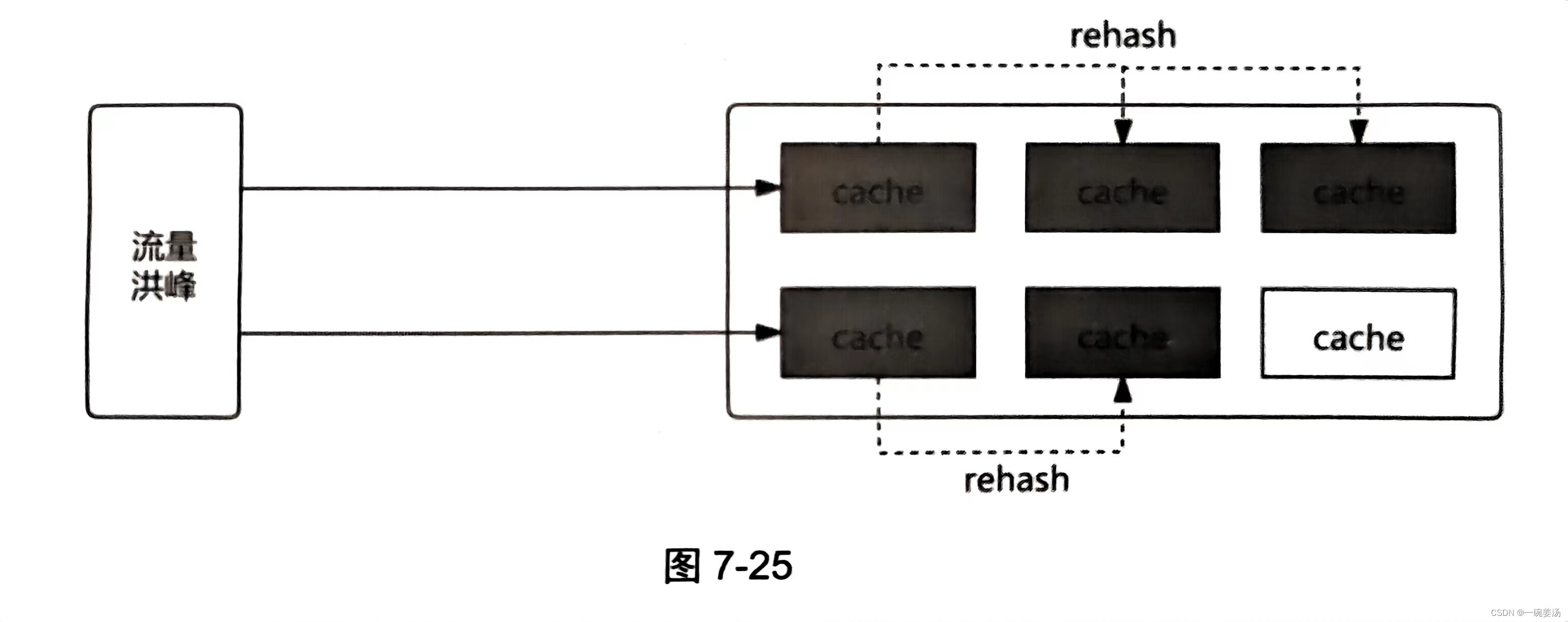
如 图7-25 所示,在缓存分布设计时,一般会选择一致性 Hash 分片,这样在节点出现异常时将采用 rehash 策略,即将对异常节点的请求平均分散到其他缓存节点上。
在一般情况下,“一致性Hash分布 + rehash 策略” 可以很好地应对瞬间流量洪峰。但在较大的瞬时流量洪峰到达时,如果流量比较集中,正好落在一两个缓存节点上,则这个节点很容易因为内存、网卡过载而出现异常,然后这些节点下线,之后大流量 key 请求被 rehash 到其他的缓存节点上,进而导致其他的缓存节点也过载,异常持续扩散,最终整个缓存系统无法对外提供服务。
2. 缓存雪崩的解决方案
合理有效地预防,能减小发生缓存“雪崩”的概率。可以从以下 3 个关键点来预防。
2.1. 对 DB 访问增加读开关
当发现 DB 请求变慢、出现阻塞,或者慢查询超过阈值时,会关闭读开关,部分或所有读 DB 的请求进行 failfast 立即返回,待 DB 恢复后再打开读开关。如 图7-26 所示。
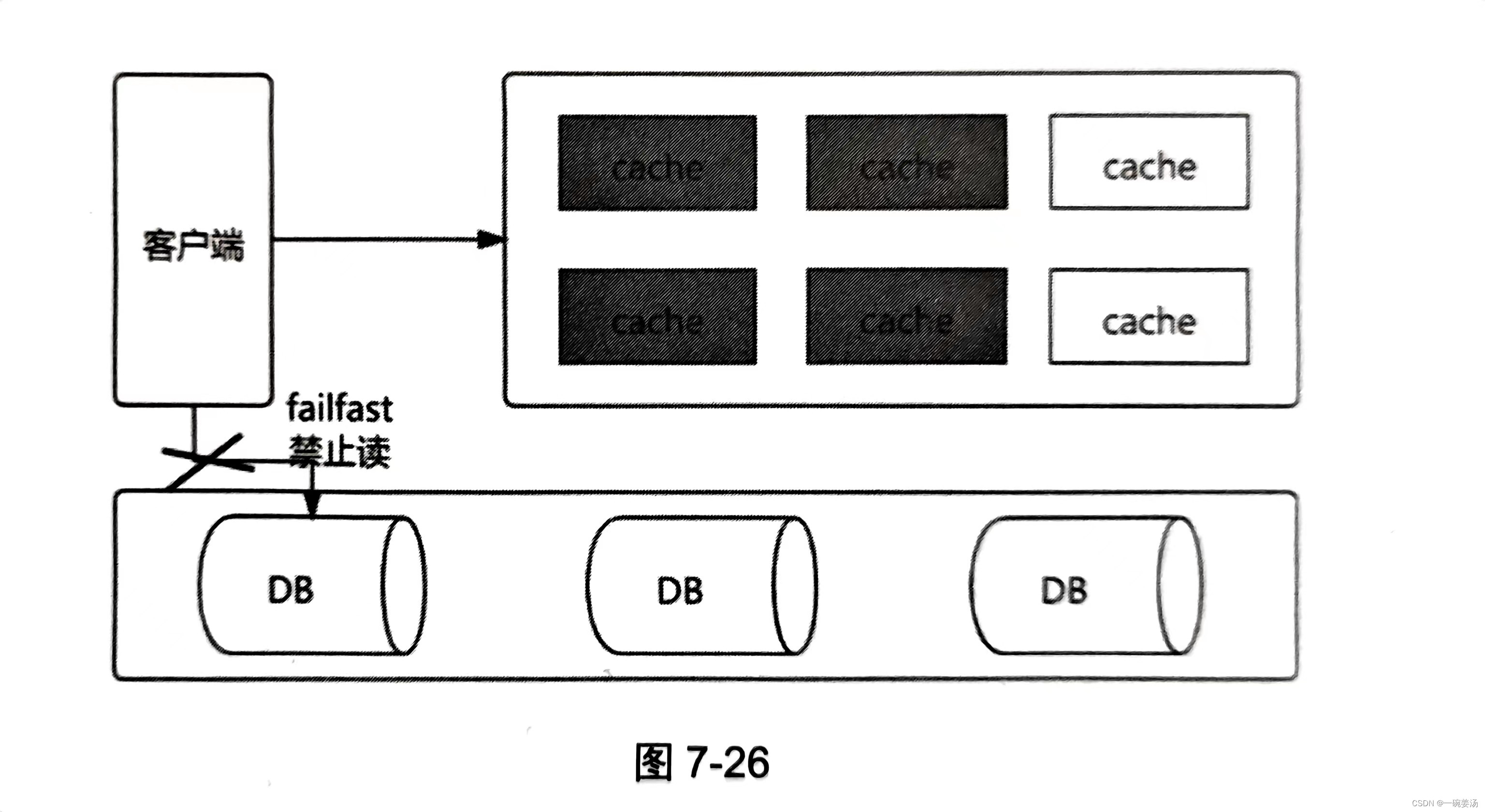
当 DB 负荷严重过载时,会出现 DB 请求严重变慢、阻塞,甚至是进程崩溃,最终导致整个系统丢数据、不可用。此时可以通过控制 DB 降低 DB压力,优先保证“写”,然后保证一部分“读”,从而再不丢数据的情况下尽可能服务更多的用户。部分用户请求的失败,比“整个系统不可用、所有用户请求失败”要好。
2.2. 给缓存系统增加多个副本
当数据出现缓存异常或请求失败后,客户端可以去读取缓存副本。多个缓存副本应尽量部署在不同的机架,如 图7-27 所示,这样可以确保在任何情况下缓存系统都可以正常对外提供服务。
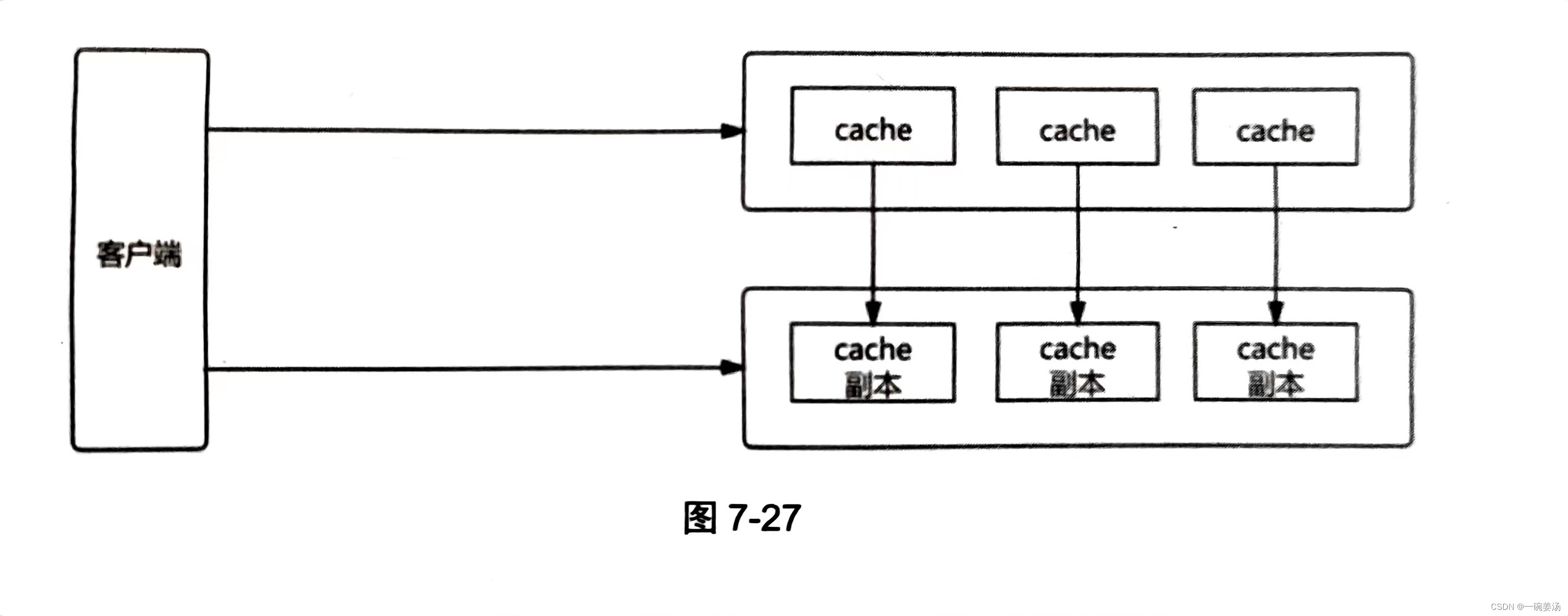
采用多个副本将流量分散到不同的副本中,或者没有足够资源就拒绝部分访问,可以确保系统对大部分用户可用或核心功能可用。
2.3. 对缓存系统进行实时监控
开发人员需要对缓存体系进行实时监控。当访问越来越慢超过阈值时,需要及时警报,并通过替换机器或服务进行及时处理。
也可以通过容错降级机制,通过自动关闭异常接口、停止边缘服务、停止部分非核心功能等措施,确保在极端场景下核心功能可以正常运行。
这三种方案,可根据自己业务特点进行选用。在一些大流量的项目(如大型社交系统)中,这三种方案都会被用到。















 259
259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









