






1. 使用while read line和/etc/passwd文件,计算用户id总和
#!/bin/bash
while read line ; do #进行循环读取每行的内容
id=`echo $line | cut -d: -f3` #将每行的ID的值赋给该变量
let sums+=$id #表示进行循环累加操作
done < /etc/passwd #传递的文件
echo '所有用户的ID之和为:'$sums #打印出最后累加的结果
2. 索引数组和关联数组,字符串处理,高级变量的使用及示例
索引数组是使用整数作为键(key)的数组。在索引数组中,元素的访问和存储都是通过其索引(通常是从0或1开始的整数)来实现的。自定义下标索引的数组就叫关联数组。
声明普通数组 declare -a
关联数组必须先声明才能使用,普通的索引数组可以不用先声明
声明关联数组 declare -A
声明关联数组要使用-A,声明普通数组使用-a
#声明数组
declare -a emp
#引用特定的数组元素
echo ${emp[0]}
#显示所有内容
echo ${emp[*]}或echo ${emp[@]}
#显示元素个数
echo ${#emp[*]}
#删除
unset emp
#数组的切片
${array[@]:3:4}
#循环遍历数组
for i in ${emp[*]};do echo $i;done
#例子同时遍历数组的key与value
for i in ${!emp[*]};do echo $i:${emp[$i]};done
#数组的字符串处理:
#取字符串的长度
echo ${#emp}
#offset偏移量
echo ${emp:2}
echo ${emp:2:2}
echo ${emp: -3:-1} #先留后三个在抛去最后一个
#高级变量的引用例子
n=10
echo {1..$n} #这样打印是不行的
#要使用eval高级遍历先把里面的变量进行替换,在进行打印
x=y
y=49
echo $x #不行
eval echo \$$x #这样才可以
3. 求10个随机数的最大值与最小值
第一种python写法
#!/bin/bash #安装python3.8.2环境脚本
version=3.8.2
wget https://www.python.org/ftp/python/$version/Python-$version.tgz
yum install gcc openssl-devel bzip2-devel libffi-devel -y
tar zxf Python$version.tgz
cd Python$version.tgz
./configure --enable-optimizations
make && make install
ln -s /usr/local/bin/python3.8 /usr/bin/python
#!/bin/python
import random
suzu=[]
for i in range (1,11):
suiji = random.randint(1,100)
suzu.append(suiji)
max_vaule = max(suzu)
min_value = min(suzu)
print("最大值为:"+str(max_vaule)+",最小值为:"+str(min_value))
EOF
chmod +x compare.py
python compare.py
第二种写法shell实现
#!/bin/bash
declare -a suzu # 初始化空数组来存储随机数
for i in {1..10}; do # 生成10个随机数并存储在数组中
suiji=$((RANDOM % 100 + 1)) # 生成1到100之间的随机数
suzu+=("$suiji") # 将随机数添加到数组中
done
# 初始化最大值和最小值为数组的第一个元素
max_value=${suzu[0]}
min_value=${suzu[0]}
# 遍历数组找到最大值和最小值
for num in "${suzu[@]}"; do #对数组中的元素进行遍历
if (( num > max_value )); then
max_value=$num
fi
if (( num < min_value )); then
min_value=$num
fi
done
# 输出最大值和最小值
echo "最大值为: $max_value, 最小值为: $min_value"
4. 递归调用,实现阶乘算法
#!/bin/bash
fac(){
if [ $1 -eq 1 -o $1 -eq 0];then
echo "$1"
else
echo $[$1*$(fac $[$1-1])]
fi
}
fac $1
5. 进程和线程的区别
进程是一个具有一定独立功能的程序在一个数据集上的一次动态执行的过程,是操作系统进行资源分配和调度
的一个独立单位,是应用程序运行的载体。进程一般由程序、数据集合和进程控制块三部分组成。
进程具有的特征:
动态性:进程是程序的一次执行过程,是临时的,有生命期的,是动态产生,动态消亡的;
并发性:任何进程都可以同其他进程一起并发执行;
独立性:进程是系统进行资源分配和调度的一个独立单位;
结构性:进程由程序、数据和进程控制块三部分组成。
线程是程序执行中一个单一的顺序控制流程,是程序执行流的最小单元,是处理器调度和分派的基本单位。一
个进程可以有一个或多个线程,各个线程之间共享程序的内存空间(也就是所在进程的内存空间)。一个标准的
线程由线程ID、当前指令指针(PC)、寄存器和堆栈组成。而进程由内存空间(代码、数据、进程空间、打开的
文件)和一个或多个线程组成
进程是操作系统分配资源的最小单位,线程是程序执行的CPU调度的最小单位。一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线。
进程之间相互独立,但同一进程下的各个线程之间共享程序的内存空间(包括代码段、数据集、堆等)及一些进
程级的资源(如打开文件和信号),某进程内的线程在其它进程不可见;
调度和切换:线程上下文切换比进程上下文切换要快得多。
6.进程的结构
进程的结构主要由三个部分组成:程序代码、数据集和栈,以及进程控制块(PCB)。
1. 程序代码:这部分描述了进程需要完成的功能。它包含了程序执行所需的指令和逻辑。
2. 数据集和栈:数据集是程序在执行过程中所需的数据集合,而栈则用于存储程序执行时的临时数据和局部变量。这两部分共同构成了程序在执行时的工作区。
3. 进程控制块(PCB):PCB是进程存在的唯一标识,它包含了进程id、用户id和组id。PCB的内容可以包括进程标识符、进程状态、程序计数器、内存指针、上下文数据、I/O状态信息、记账信息等。PCB的作用有:使一个在多道程序环境下不能独立运行的程序(含数据),成为一个能独立运行的基本单位,一个能与其他进程并发执行的进程;能对进程进行管理和控制;能方便地实现进程切换。
内存溢出与内存泄露
内存泄露指的是程序中申请了一块内存,但是没有利用或删除将内存释放,导致了改内存一直处于占用状态。
内存溢出指程序申请了特定大小的空间,但是在该空间上写入了超过该特定大小空间的数据,就是内存溢出。就像一杯只能装100ML的水但是给其倒入了200ML的水。
7.进程管理命令,以及进程中的各种状态
pstree用来显示进程的父子关系,以树形结构显示。pstree工具来自于psmisc包若不能使用该命令则可能没有安装该psmisc包。
pstree的参数有很多以下仅列举出几个供参考,更多参数请使用–help进行查看
| 参数 | 表示 |
|---|---|
| -p | 显示进程的PID,同时也会把某个进程下的线程也输出到屏幕 |
| -T | 不显示线程 |
| -U | 显示用户切换 |
显示进程信息的工具为ps,linux系统各进程的相关信息均保存在/proc/PID目录下的各文件中
| 参数 | 表示 |
|---|---|
| -a | 选择除会话引导程序和与终端无关的进程之外的所有进程 |
| -u | 按有效的用户ID或名称进行选择。这将选择其有效用户名或ID在用户列表中的进程 |
| -x | 包括链接终端的进程 |
| e | 显示所有进程,相当于-A |
| f | 选项显示进程树,相当于–forest |
示例:ps aux

| 内容 | 表示 |
|---|---|
| USER | 表示哪个用户运行的 |
| PID | 表示进程的编号 |
| %CPU | 表示CPU的利用率 |
| %MEM | 表示内存的利用率 |
| VSZ | 表示虚拟内存 |
| RSS | 表示真实的物理内存 |
| TTY | 表示进程的控制终端 |
| STAT | 进程的状态 |
| STAT状态表 | 表示 |
|---|---|
| R | 表示运行 |
| S | 睡眠可中断 |
| D | 睡眠不可中断 |
| Z | 僵尸进程 |
| + | 前台进程 |
| L | 内存分页并带锁 |
| N | 优先级进程 |
| < | 高优先级进程 |
| s | 会话(子进程发起者) |
| l | centos8新特性 |
ps只能静态的查看各进程信息,若想动态的查看进程信息可以使用top命令
8.IPC通信和RPC通信实现的方式
IPC(进程间通信)和RPC(远程过程调用)是两种不同的通信机制,它们各自有不同的实现方式。
IPC通信的实现方式主要包括以下几种:
1. 共享内存:这是一种进程间通信的方式,它通过将某一块内存区域映射到多个进程的地址空间中,实现不同进程之间的数据共享。
2. 消息传递:进程间通过发送和接收消息进行通信。可以用于不同进程之间的异步通信。
3. 管道:数据只能单向流动,通常用于父子进程之间的通信。
4. 套接字:套接字是网络通信的基本单元,它不仅支持本地进程间的通信,还支持跨网络的进程间通信。
RPC通信的实现方式
RPC通过网络传输调用信息和数据,并接收返回结果,从而实现远程调用的功能。涉及到客户端和服务器端两个角色。客户端通过网络发送请求到服务器,服务器处理请求并返回结果给客户端。
9. Linux前台和后台作业的区别,在前台和后台中进行状态转换
前台作业是直接在终端上运行的命令或进程,它们与终端进行交互。用户可以在终端上直接看到它们的输出,并可以通过键盘输入与它们进行交互。前台作业受到终端的控制。如果终端被关闭或中断,前台作业通常会被终止。
后台作业是在后台运行的命令或进程,它们不与终端进行直接交互。即使终端被关闭或中断,后台作业仍然可以继续运行。后台作业不依赖于终端的会话。即使关闭了启动后台作业的终端窗口,后台作业仍会继续运行。
“n”是后台进程的编号
前台到后台:如果程序正在前台运行,可以使用Ctrl+z组合键将程序暂停前台工作。bg %n命令将暂停的作业放到后台运行。尚未启动的作业则直接在命令后面添加“&”字符,即可在后台启动。
后台到前台:使用fg %n命令可以将编号为n的后台进程调到前台来运行,
查看作业:使用jobs命令查看当前所有的前台和后台作业
10.内核设计流派及特点
微内核
特点:微内核设计强调内核的最小化和模块化。它只包含最基本的操作系统服务和功能,如进程间通信(IPC)机制、内存管理和基本的设备驱动程序接口。其他的都被设计为独立的用户空间进程或服务器,通过IPC机制与内核进行交互。
宏内核
特点:宏内核设计将尽可能多的系统服务和功能集成到内核中。它包含文件系统、设备驱动程序、网络协议栈等,以提供高性能的系统服务。
混合内核
特点:混合内核设计结合了微内核和宏内核的优点,既保持内核的简洁性,又将一些关键的系统服务集成到内核中以提高性能。
模块化内核
特点:模块化内核设计允许内核在运行时动态地加载和卸载模块。这些模块可以是设备驱动程序、文件系统、网络协议栈等。
11.rocky的启动流程和grub的工作流程
rocky启动流程:
1. 加电自检(POST):主板在接通电源后,系统首先由POST程序来对内部各个设备进行检查。如果发现严重故障(致命性故障),则系统会停机。对于非严重故障,POST会给出提示或声音报警信号,等待用户处理。
2. BIOS启动引导阶段:自检通过后,BIOS会按次序查找各引导设备,找到第一个有引导程序的设备作为本次启动的设备。通常,BIOS会读取设备中的MBR(Master
Boot Record)以查找并加载Bootloader。
3. GRUB引导阶段:一旦GRUB被加载,它将开始引导CentOS系统。尽管此阶段通常不需要用户干预,但GRUB会确保系统能够自动启动。
GRUB工作流程:
第一阶段:从MBR中加载。它运行Boot Loader主程序,该程序必须安装在启动区,即MBR中。
1.5阶段:加载于MBR之后的扇区。此阶段存储了stage2所在分区的驱动,帮助stage1中的bootloader识别stage2所在的分区上的文件系统。
第二阶段:提供菜单,加载内核和ramdisk至内存,并移交控制权。在这个阶段,GRUB会找到并加载合适的内核以及相关的初始化RAM磁盘(initrd或initramfs)
12.通过二进制安装http服务,并使用systemd实现http服务的开始、停止与重启
#!/bin/bash
version=2.4.59
install_dir=/servers/http
install_httpd() {
yum install pcre-devel gcc apr-devel apr-util-devel make rpm-build redhat-rpm-config -y
wget https://dlcdn.apache.org/httpd/httpd-${version}.tar.gz || { echo "下载失败!";exit 20; }
tar zxf httpd-${version}.tar.gz -C /root
cd /root/httpd-${version}
./configure --prefix=${install_dir}
make -j `grep -c processor /proc/cpuinfo`&& make install
if [ $? -ne 0 ];then
echo Install http is failed!
exit 10
else
echo "Install http is finished!"
fi
cat > /lib/systemd/system/httpd.service <<EOF
[Unit]
Description=The Apache HTTP Server
After=network.target remote-fs.target nss-lookup.target httpd-init.service
[Service]
Environment=LANG=C
ExecStart=${install_dir}/bin/httpd $OPTIONS -DFOREGROUND
ExecReload=${install_dir}/bin/httpd $OPTIONS -k graceful
KillSignal=SIGWINCH
KillMode=mixed
PrivateTmp=true
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable --now httpd &> /dev/null
systemctl is-active httpd &> /dev/null
echo "<h1>This is my httpd website </h1>" > ${install_dir}/htdocs/index.html
}
install_httpd
systemctl stop httpd
echo "Binary installed HTTP services can be managed through Systemd" > /servers/http/htdocs/index.html
systemctl restart httpd
13 systemd服务配置文件
systemd服务配置文件是Linux系统中用于定义和管理服务的关键组成部分。这些文件通常位于特定的目录中,如/etc/systemd/system、/run/systemd/system和/usr/lib/systemd/system,它们分别对应着不同的优先级和用途。
systemd服务配置文件的主要组成部分包括:
Unit部分:这部分提供了与Unit类型无关的通用选项,用于描述Unit信息、定义Unit的行为以及指定Unit之间的依赖关系等。在Service Unit中,这通常包括服务的描述、执行路径以及与其他服务的依赖关系等信息。
Service部分:用于定义系统服务的特定属性,例如启动命令、重启策略、工作目录等。这些选项允许管理员精确地控制服务的运行方式和行为。
Install部分:定义了如何“安装”这个unit,即如何“启动”这个unit。分别表示该unit被哪个target所需要和该unit被哪个target所要求。
14.system启动流程
1.UEFI或者BIOS初始化,运行POST开机自检
2.选择启动设备
3.引导转载程序,加载转载程序的配置文件
/etc/grub.d/
/etc/default/grub
/boot/grub2/grub.cfg
4.加载initramfs驱动模块(实现根文件系统的挂载)
5.加载虚拟根中的内核
6.虚拟根的内核初始化,使用systemd代替init,第一个进程
7.执行initrd.target所有单元,包括挂载/etc/fatab
8. 从initramfs根文件系统切换到磁盘根目录
9. systemd执行默认target配置,配置文件/etc/systemd/system/default.target
10. systemd执行sysinit.target初始化系统及basic.target准备操作系统
11. systemd启动multi-user.target下的本机与服务器服务
12. systemd执行multi-user.target下的/etc/rc.d/rc.local
13. Systemd执行multi-user.target下的getty.target及登录服务
14. systemd执行graphical需要的服务
15.awk工作原理,awk命令、选项、awk的数组与函数示例
awk的工作原理:awk是一种强大的文本处理工具,其执行原理是通过读取输入文本的每一行,并按照指定的规则进行处理。对于每一行,awk会按照指定的模式进行匹配,如果模式匹配成功,则执行对应的操作。awk会根据指定的操作对每一行进行处理,直到处理完所有的行。
awk命令:awk命令用于模式扫描和处理语言。它允许您创建简短的程序,这些程序读取输入文件、为数据中的每个字段执行操作,并打印结果。基本语法为:awk ‘pattern { action }’ filename。其中,pattern是一个正则表达式,用于匹配文本中的行或字段;action是对匹配的行或字段执行的操作。
| 选项 | 描述 |
|---|---|
| -F | 指定分隔符 |
| FS | 输入字段的分割符,指定列的分割符 |
| OFS | 输出的列的变量分割符 |
| RS | 输入记录record分割符,指定输入时的分割符 |
| ORS | 输出记录record分割符,指定输出时的分割符 |
| NF | 列的个数 |
| NR | 记录的行号 |
awk -F':' '{print $1}' /etc/passwd
awk -v FS=":" '{print $1}' /etc/passwd
awk -v FS=":" -v OFS="@" '{print $1}' /etc/passwd
awk -F":" '{print NF}' /etc/passwd
awk也有数组表示,其数组为关联数组,同时awk分为内置函数和自定义函数
利用数组,实现key/value功能,下标可以使用任意字符串;但是字符串要使用双引号括起来
[10:08:29 root@rocky8 ~]$awk 'BEGIN{name[1]="lll";name[2]="www";name[3]="yyy";print name[1]}'
awk的内置函数
rand():返回0和1之间的一个随机数
srand():配合rand()函数,生成随机数的种子
int():返回整数
[10:09:01 root@rocky8 ~]$awk 'BEGIN{srand();print rand()}'
自定义函数格式:
function name( parameter){
statements
return expression
}
16.ca管理相关的工具、对称加密和非对称加密算法原理和openssl签发证书的步骤
OpenSSL是一个开源的程序套件,主要用于实现安全通信,由三个主要组件组成
libcrypto:用于实现加密和解密的库
libssl:用于安全地传输数据,保护通信的隐私和完整性。
openssl:用于执行与加密、解密、证书管理等相关的各种任务。
对称加密算法的步骤:
1.密钥生成:首先,需要生成一个密钥。这个密钥可以是随机生成的,也可以是通过某种算法计算得出的。密钥的长度和复杂性决定了加密的强度。
2.加密过程:将明文按照某种方式(如字节或比特)进行分割,得到一系列的明文块。对每一个明文块,使用密钥和加密算法进行加密运算,得到对应的密文块。将所有的密文块按顺序组合在一起,形成最终的密文。
3. 传输密文:加密后的密文可以通过不安全的通道进行传输,因为没有密钥,即使密文被截获,也无法解密得到原始的明文。
4.解密过程:接收方在收到密文后,使用与加密时相同的密钥和相同的解密算法(实际上是加密算法的逆运算)进行解密。将密文按照加密时的分割方式进行分割,得到一系列的密文块。对于每一个密文块,使用密钥进行解密运算,得到对应的明文块。将所有的明文块按顺序组合在一起,形成最终的明文。
| 加密算法名称 | 特点 |
|---|---|
| DES | 明文分为64位一组,密钥64位(实际是56位密钥和8位奇偶校验) |
| 3DES | 3DES是DES的扩展,是执行了三次的DES。其中,第一、第三次加密使用同一种密钥的方式下,密钥长度扩展到128位(112位有效);三次加密使用不同密钥,密钥长度扩展到192位(168位有效) |
| RC5 | RC5由RSA中的Ronald L .Rivest发明,是参数可变的分组密码算法,三个可变的参数是:分组大小、密钥长度和加密轮数 |
| IDEA | 明文、密文均为64位,密钥长度128位 |
| RC4 | 常用的流密码,密钥长度可变,用于SSL协议。曾经用于IEEE802.11 WEP协议中。也是Ronald L .Rivest发明的 |
| AES | 明文分为128位一组,具有可变长度的密钥(128、192或256位) |
注:以上表格来源于《网络工程师5天修炼》第三版
非对称加密算法的步骤:
1.密钥生成:首先,用户(例如乙方)生成一对密钥,即公钥和私钥。公钥是公开的,可以分享给任何人;而私钥则是保密的,只有用户自己知道。
2.公钥分发:生成密钥对后,用户将公钥分发给其他需要与其进行安全通信的实体(例如甲方)。公钥的分发可以通过安全的渠道进行,例如通过数字证书或密钥分发中心(KDC)。
3.加密过程:当甲方需要向乙方发送机密信息时,甲方使用乙方的公钥对信息进行加密。这样,只有拥有对应私钥的乙方才能解密这条信息。加密确保了信息在传输过程中的安全性,即使信息被截获,攻击者也无法解密,因为他们没有私钥。
4.解密过程:乙方收到甲方加密的信息后,使用自己的私钥进行解密,从而获取原始信息。只有乙方的私钥才能解密用其公钥加密的信息,这保证了信息的保密性。
5.验证过程(可选):在某些情况下,为了验证信息的完整性和发送者的身份,还会使用数字签名。发送者(如甲方)使用自己的私钥对信息摘要进行加密,形成数字签名,并附加在原始信息上。接收者(如乙方)使用发送者的公钥对数字签名进行解密,并与自己计算的信息摘要进行比对。如果两者一致,说明信息在传输过程中未被篡改,且确实来自声称的发送者。
| 常见算法 | 特点 |
|---|---|
| RSA | 由 RSA 公司发明,是一个支持变长密钥的公共密钥算法,需要加密的文件块的长度也是可变的,可实现加密和数字签名 |
| DSA | 数字签名算法,是一种标准的 DSS(数字签名标准) |
| ECC | 椭圆曲线密码编码学,比RSA加密算法使用更小的密钥,提供相当的或更高等级的安全 |
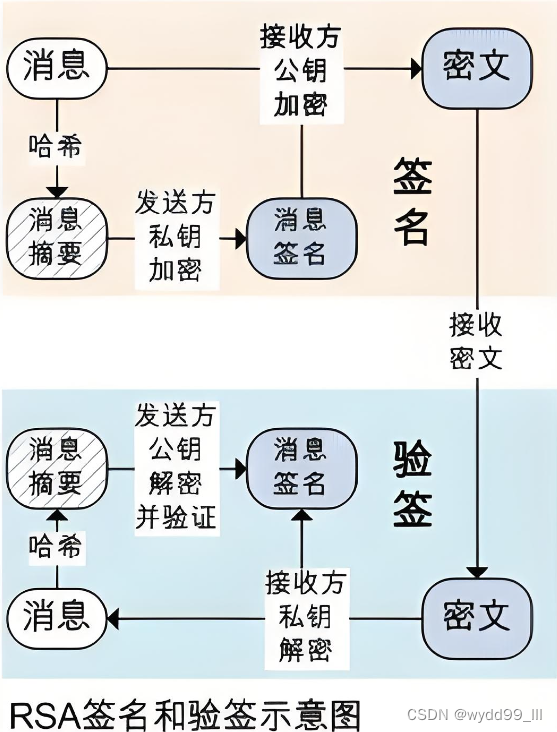
举例:RSA密钥生成的过程
选出两个大质数p和q,使得p不等于q
p*q=n
(p-1)*(q-1)
选择e,使得1<e<(p-q)<(q-1),并且(p-1)*(q-1)互为质数
计算解密密钥,使得ed=1mod(p-1)*(q-1)
公钥=(n,e)
私钥=d
例子:按照RSA算法,若选两个奇数p=5,q=3,公钥e=7,则私钥为7
n=p*q=15
(p-1)*(q-1)=8
根据ed=1mod8,即7d=1mod8,即d为7
openssl签发证书步骤
1.创建私有CA
#生成证书索引数据库文件
touch /etc/pki/CA/index.txt
#指定第一个颁发证书的序列号
echo 01 > /etc/pki/CA/serial
2.生成CA私钥
(umask 066;openssl genrsa -out private/cakey.pem 2048)
3.生成CA自签名证书
openssl req -new -x509 -key /etc/pki/CA/private/cakey.pem -days 3650 -out /etc/pki/CA/cacert.pem
#看证书
openssl x509 -in /etc/pki/CA/cacert.pem -noout -text
4.申请证书并颁发证书
4.1.为需要使用证书的主机生成私钥
(umask 066;openssl genrsa -out /data/test.key 2048)
4.2.为需要使用证书的主机生成证书申请文件
openssl req -new -key /data/test.key -out /data/test.csr
4.3.在CA签署证书并将证书颁发给请求者
openssl ca -in /data/test.csr -out /etc/pki/CA/certs/test.crt -days 100
4.4.查看证书中的信息
openssl x509 -in /PATH/FROM/CERT_FILE -noout -text|issuer|subject|serial|dates
#查看指定编号的证书状态
openssl ca -status SERIAL















 1661
1661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









