









23年10月来自国内清华大学、香港大学和加州伯克利分校的论文“LanguageMPC: Large Language Models As Decision Makers For Autonomous Driving“。
现有的基于学习的自动驾驶系统在理解高级信息、泛化到罕见事件和提供可解释性方面面临挑战。为了解决这些问题,该文将大语言模型(LLM)作为需要人类常识理解的复杂AD场景决策组件。设计了认知途径,实现LLM的全面推理,并开发了将LLM决策转化为可操作驾驶命令的算法。这种方法通过引导参数矩阵的自适应,把LLM决策与低级控制器无缝集成。
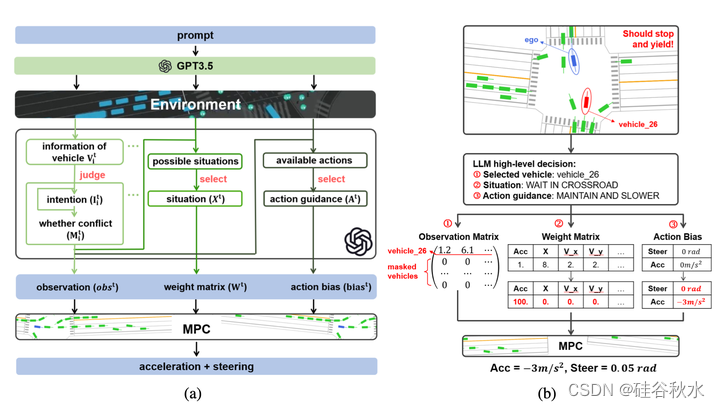
这个以LLM为核心的高级决策AD系统,如图所示(a)。LLM根据提供的提示启动对话,不断从环境中收集信息,进行推理并做出判断。如图(a)的中心所示,LLM从左到右依次进行:1)识别需要注意的车辆,2)评估情况,3)提供动作引导。然后,系统将这三个高级文本决策转换为数学表示,即观察矩阵、权重矩阵和动作偏差。这些元素充当底层控制器MPC的指令,指令其采取具体的驾驶行动。
以十字路口左转的情况为例,在图(b)展示了如何将上述三个高级文本决策转换为MPC所需的数学表示。LLM选择“车辆26”,用MPC的观测算子创建相应的向量,并将观测矩阵中的其他元素清零,仅关注“车辆26’”。根据LLM发信号的十字路口等待情况,调整权重矩阵,使减速指令优先于轨迹跟从,这促使MPC根据LLM的指令迅速减速。通过预定义的规则直接将LLM的动作引导转化为动作偏差。MPC在上述三个方面的数学形式的引导下,完成了停车和让行的驾驶动作。















 9811
9811











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









