






目前,几乎每个生物实验室都可以看到96孔板(也称为为微量滴定板)的存在,例如酶标仪和用于qRT-PCR的96孔板,通常这些96孔板能在较短的时间内得到大量数据,方便高效。需要注意的是96孔的格式可能是目前最常用的板,但也有很多其他布局的板,如果想让我们的代码具有较好的重复性,以便用于不同规格的板,我们就需要用到面向对象编程(OOP)。
现在让我们回顾一下96孔板的表示方法:
(1)坐标系位置1D(position1D):1,2,3,4,5,6,7,8,.......94,95,96;
(2)坐标系位置2D(position2D):(1,1), (1,2), (1,3),....... (8,10), (8,11), (8,12) ;
(3)坐标系统(wellID):'A01', 'A02', 'A03', ........'H10', 'H11', 'H12'。
代码的实现:
1.孔板类的构造
对于Plate类,我们有两个类变量rowLabels和mapPosition。
rowLabels变量定义了可用于板的行名。在这里,我们默认一块板永远不会超过26行,因此就用26个字母分别表示26行。
mapPosition中的position1D:0, position2D:1, wellID:2主要目的是后续可以利用字典的key所对应的value提取map()放回的元组中的值self.validate[key].append(m[Plate.mapPosition[key]]). 这样做的主要目的是代码具有较好的兼容性,即使我们更改了mapPosition的顺序,在提取元组时它也能精确提取,提取的顺序不会改变。
其他的一些解释详见代码中的注释部分。
import math,os,string,csv
import matplotlib as plt
class Plate():
#孔板的行名
rowLabels = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
#mapPosition中的position1D:0, position2D:1, wellID:2主要目的是后续可以利用字典的key所对应的value提取map()放回的元组中的值,self.validate[key].append(m[Plate.mapPosition[key]])
mapPosition = {'position1D':0, 'position2D':1, 'wellID':2}
def __init__(self,id, rows, columns):
self.id = id
self.rows = rows
self.columns = columns
self.size = self.rows*self.columns
#validate字典用于存储各个坐标系的映射关系,
# 例如{‘position1D’:[1,2,3,4,....], 'position2D':[(1,1),(1,2),(1,3),...], 'wellID':['A01','A02','A03',...]}
self.validate = {}
#data字典用于后续数据,比如酶标板读取出来的数值
self.data = {}
# 利用for循环将validate中的每个key(position1D,position2D,wellID)先定义为空列表
for key in Plate.mapPosition:
self.validate[key] = []
#利用for循环根据孔板大小构建三种不同坐标系的映射关系
for n in range(1, self.size+1):
self.data[n] = {}
#map()函数返回的是一个元组(1,(1,1),‘A01’)分别对应三种不同坐标系的表示方法;
#check=False是因为map()函数有双重功能,不仅提供输入坐标的坐标映射集(check=False),
# 而且检查输入坐标对当前的Plate示例是否有效(check=True)
m = self.map(n, check=False)
#利用for循环根据位置提取相应的映射关系,并添加到列表里面
for key in Plate.mapPosition:
self.validate[key].append(m[Plate.mapPosition[key]])2.孔板的遍历——Plate类中map()方法的构造
首先我们先看看map()方法的返回值(return (pos, (row+1,col+1), id)),返回的时一个包含三个值的元组,每个值表示一个坐标系,pos为position1D的坐标系、(row+1,col+1)为position2D的坐标系,id为wellID的坐标系。
代码中的if check是if check=True的一种简写。
其他的一些解释见代码中的注释。
def map(self, loc, check=True):
# 先利用type()初步检查是否为整数,若为整数则属于position1D,然后if check:检查输入的整数是否属于1-96之内
if type(loc) == type(15):
if check:
if not loc in self.validate['position1D']:
raise Exception('Invalid 1D PLate Position: %s' %str(loc))
#算出输入的整数所对应的行名和列名,但这里的行名和列名并不是真正,而是要用于计算最后的行名和列名的计算,所以会-1
row = int(math.ceil(float(loc)/float(self.columns))) - 1
col = loc - (row * self.columns) - 1
#先利用type()初步检查是否为元组,若为元组则属于position2D,然后if check:检查输入的元组是否属于(1,1)---(8,12)里面
elif type(loc) == type((3,2)):
if check:
if not loc in self.validate['position2D']:
raise Exception('Invalid 2D PLate Position: %s' %str(loc))
#算出输入的元组所对应的行名和列名,但这里的行名和列名并不是真正,而是要用于计算最后的行名和列名的计算,所以会-1
row = loc[0] - 1
col = loc[1] - 1
# 先利用type()初步检查是否为字符串,若为字符串则属于wellID,然后if check:检查输入的字符串是否属于A01---H12里面
elif type(loc) == type('A07'):
if check:
if not loc in self.validate['wellID']:
raise Exception('Invalid Well ID : %s' % str(loc))
#算出输入的字符串所对应的行名和列名,但这里的行名和列名并不是真正,而是要用于计算最后的行名和列名的计算,所以会-1
row = Plate.rowLabels.index(loc[0])
col = int(loc[1:]) - 1
else:
raise Exception('Unrecignized Plate Location Type: %s' % str(loc))
#利用上面的row和col算出真正的行名和列名
pos = self.columns * row + col +1
id = '%s%02d' %(Plate.rowLabels[row], col+1)
#返回不同的坐标系所对应的值(1,(1,1),‘A01’)
return (pos, (row+1,col+1), id)#实例化对象,测试到目前为止的代码是否有效
p = Plate('My 96-well Plate', 8, 12)
print(p.map(1))
print(p.map('A01'))
print(p.map((1,1)))
=======================运行结果=======================
(1, (1, 1), 'A01')
(1, (1, 1), 'A01')
(1, (1, 1), 'A01')3.分配(set)和检索(get)孔板的数据
#定义set()方法以分配每个孔板所对应的值
def set(self, loc, propertyName, value):
m = self.map(loc)
pos = m[Plate.mapPosition['position1D']]
self.data[pos][propertyName] = value
#定义get()方法以查看每个空在set()时所设定的值
def get(self, loc, propertyName):
m = self.map(loc)
pos = m[Plate.mapPosition['position1D']]
if propertyName in self.data[pos]:
return self.data[pos][propertyName]
else:
#这里return后面没有东西,指的就是return None
return
#用法展示
p = Plate('My 96-well Plate', 8, 12)
p.set('B01', 'concentration', 0.87)
print(p.get(13,'concentration'))
print(p.get((2,1),'concentration'))
print(p.get('B01','concentration'))
==================运行结果====================
0.87
0.87
0.874.读取和写入CSV
CSV是一种纯文本格式,以逗号分隔。您也许知道可以通过某些应用程序(如Excel)导出CSV的格式的表格数据。如果您需要使表格数据更易于人类理解,或者将其输入到另一个无法处理Excel自身内部数据格式的应用程序时CSV格式特别有用。
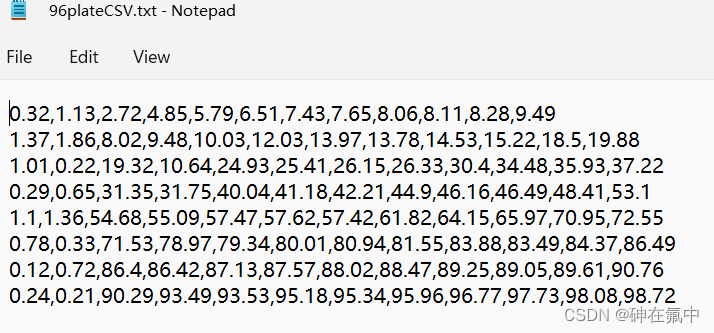
代码中96plateCSV.txt的内容如上图所示
#读取CSV文件,并将CSV文件里面对应的值利用set()方法填入孔板
def readCSV(self, filePath, propertyName):
try:
nWell = 1
#需要注意的是要根据自己的csv文件的编码方式来设施encoding
with open(filePath, mode='r',encoding='utf-8') as csvFile:
csvReader = csv.reader(csvFile)
for row in csvReader:
for wellData in row:
#利用上面的set()方法将csv文件的值填入相应的孔板
self.set(nWell, propertyName, float(wellData))
nWell += 1
except:
print('CSV data could not be correctly read from: %s' %filePath)
return
return
#用法展示
p = Plate('My 96-well Plate', 8, 12)
p.readCSV(r'D:\pycharm\pythonProject3\生命科学家的Python\mapping\96plateCSV.txt','concentration')
print(p.get(1,'concentration'))
===========================运行结果===================================
0.325.孔板中的数学
孔板中的网格布局很自然地适合使用板的行和列进行孔板测定实验的组织。例如将每个样品及其对照放置在同一行上,或在同一行上分析给定的样品连续稀释液,或垂直方向上进行上述操作。由于这个原因,多孔板的数据通常可以按行和列进行有用的组织和分析。考虑到这一点,我们在Plate类中添加了另外三个方法getRow、getColumn和average,它们可以在三个受支持坐标系中的任何一个定位单个孔的为止,并返回该位置所在的行或列的列表,并求出平均值。代码如下:
#定义getRow函数,来提取某个孔所在的行上的所有值,并添加到row[]列表里面
def getRow(self, loc):
here = self.map(loc)
row = []
for n in range(0, self.size):
there = self.map(n+1)
if there[1][0] == here[1][0]:
row.append(there)
return row
# 定义getColumn函数,来提取某个孔所在的列上的所有值,并添加到col[]列表里面
def getColumn(self, loc):
here = self.map(loc)
col = []
for n in range(0, self.size):
there = self.map(n+1)
if there[1][1] == here[1][1]:
col.append(there)
return col
#分别计算某一个孔所在的行或列的平均值
def average(self, propertyName, loc=None):
if loc == None:
total = 0
for pos in range(0, self.size):
total += self.get(pos+1, propertyName)
return total/self.size
row = self.getRow(loc)
col = self.getColumn(loc)
rowTotal = 0.0
colTotal = 0.0
for pos in row:
rowTotal += self.get(pos[1], propertyName)
rowMean = rowTotal/self.columns
for pos in col:
colTotal += self.get(pos[1], propertyName)
colMean = colTotal/self.rows
return (rowMean, colMean)
#用法展示
p = Plate('My 96-well Plate', 8, 12)
p.readCSV(r'D:\pycharm\pythonProject3\生命科学家的Python\mapping\96plateCSV.txt','concentration')
print(p.get(1,'concentration'))
print(p.getRow('B04'))
print(p.getColumn('B04'))
print(p.average('concentration','B04'))
print(p.average('concentration'))
==================================运行结果==================
0.32
[(13, (2, 1), 'B01'), (14, (2, 2), 'B02'), (15, (2, 3), 'B03'), (16, (2, 4), 'B04'), (17, (2, 5), 'B05'), (18, (2, 6), 'B06'), (19, (2, 7), 'B07'), (20, (2, 8), 'B08'), (21, (2, 9), 'B09'), (22, (2, 10), 'B10'), (23, (2, 11), 'B11'), (24, (2, 12), 'B12')]
[(4, (1, 4), 'A04'), (16, (2, 4), 'B04'), (28, (3, 4), 'C04'), (40, (4, 4), 'D04'), (52, (5, 4), 'E04'), (64, (6, 4), 'F04'), (76, (7, 4), 'G04'), (88, (8, 4), 'H04')]
(11.555833333333332, 46.33625)
43.52604166666666在上述的average()方法中,loc参数是可选的,因为提供了默认值loc=None,如果没有将loc的值传递给average()方法中,将使用该默认值,以计算整个板的平均值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









